






需求:
1、需要从一张mysql数据表中获取并筛选数据
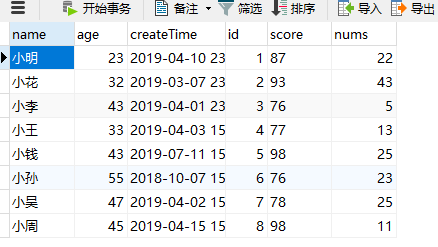
2、通过spark将该表读进来,形成一个df:DataFrame,有一个集合
val list = List[String]("小李", "小王", "4", "5", "7")
3、需要从df中进行筛选出来name在list中的值
df.where('name.isin(list)).show()
结果:

然而,isin(),看源码:

里面需要的是一个可边长参数,我们想当然的把它当成了一个集合,此时不能将整个list传进去,但是我又要实现包含查询,但是又不想通过for循环遍历进行union的方式(这种方式是可以实现的,也就是说根据条件匹配list中的第一个值,然后将其定义成var,然后在遍历list中的每一个值作为条件,最后将其union起来,很笨,我一开始就这么干的),此时有一个新的办法,就是讲list改为list:_*
df.where('name.isin(list:_*)).show()
结果:

搞定!!!
记录一下。














 2072
2072











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









