






点击蓝字

关注我们
AI TIME欢迎每一位AI爱好者的加入!

点击 阅读原文 观看作者讲解回放!
个人信息
作者:周展鹏,上海交通大学博士生
研究概述
理解深度神经网络的良好泛化(generalization)能力是现代深度学习的核心问题之一。最近的研究表明神经网络的泛化能力和损失图景(loss landscape)的平坦度(flatness),或者陡峭度(sharpness)有关。很多研究尝试设计新的梯度更新算法来显式/隐式地调节最终收敛到的解(minima/solution)的 sharpness。其中,Foret et al. (2021) 提出了Sharpness-Aware Minimization(SAM)。SAM在CV和NLP等领域都能显著提升模型的泛化能力和鲁棒性(robustness)。
尽管SAM在实际应用中取得了不错的成绩,但是我们仍然不能完全理解SAM的有效性。有研究指出Foret et al. (2021)原文中根据 PAC-Bayes 理论给出的SAM泛化界(Bound)并不能充分解释SAM的有效性。最近很多研究尝试对SAM的动力学进行渐进分析,然而和实际中的SAM仍有差距。理解SAM有效性的背后机理仍然是一个开放问题。
最近的研究指出基于梯度更新的优化算法的成功可以归结于其隐式偏差(implicit bias):倾向于寻找具有良好性质的minima。一个比较经典的例子是,Stochastic Gradient Descent(SGD)相比于full-batch GD会倾向于选择更加平坦(flat)的minima。这是由SGD中mini-batch所带来的noise决定的。类似地,尽管SAM的设计灵感来自于landscape的flatness/sharpness,其具体实现(见公式2-3)并没有显式地优化solution的flatness/sharpness。理解SAM的隐式偏差对于我们理解SAM的有效性是非常重要的。

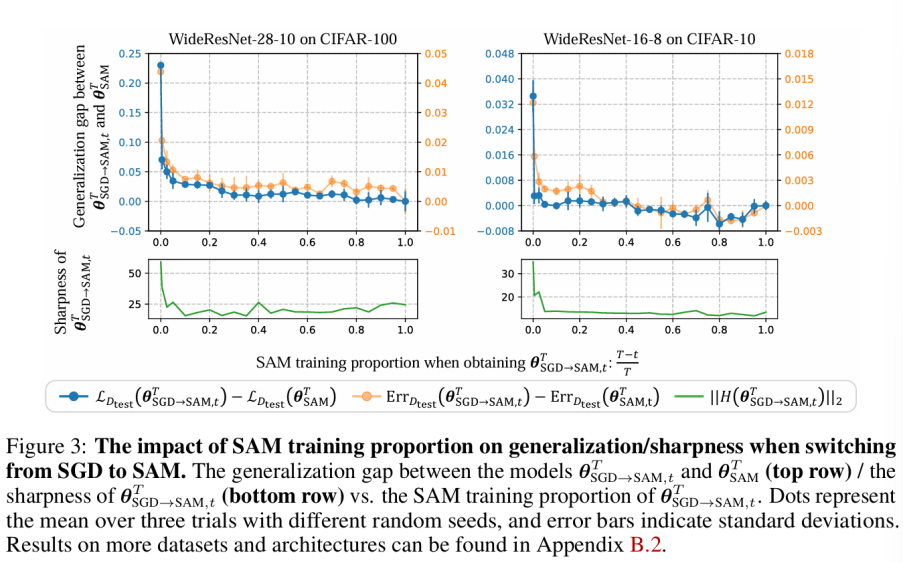
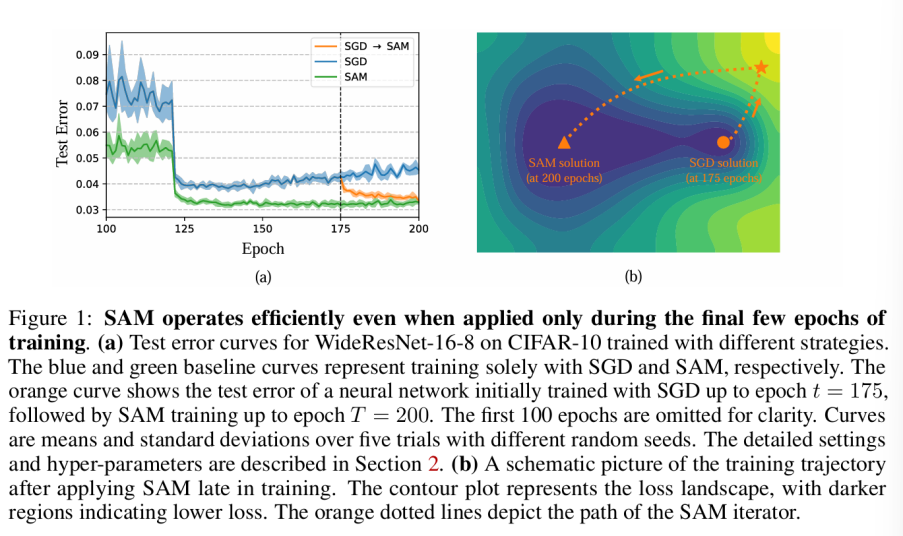
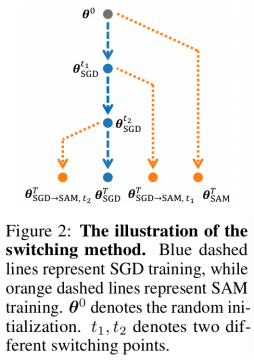
我们的工作发现了SAM优化动力学(training dynamics)中一个有趣的现象:即使在训练的最后几个epoch使用SAM,SAM一样可以找到平坦的解。具体而言,我们使用SGD训练模型并且在最后几个epoch切换到SAM继续训练。更进一步地,我们测算了这种switching method所找到的solution的sharpness。我们发现从sharpness的角度而言switching method和全程SAM也具有相似的表现(如图三所示)。因此,我们将发现总结为:SAM在网络训练后期也能找到比SGD更加平坦的解。相比于前人研究中“训练早期的dynamics更加重要”的观点,我们的发现强调了训练后期dynamics对泛化能力的重要性。

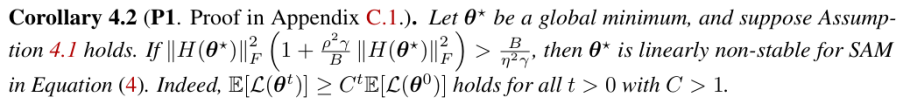
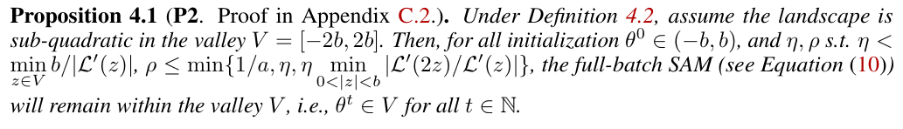

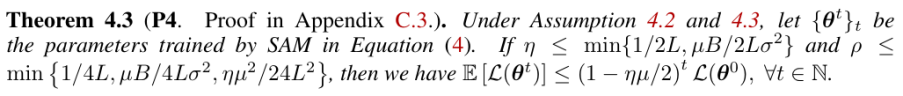
理解我们的发现对于我们解释SAM的隐式偏差非常重要。接下来,我们从理论角度构建了训练后期SAM的动力学图景(picture)。具体而言,我们将SAM在后期的优化分成了两个阶段(Phase)。在第一个阶段,SAM会从相对sharp的解中逃离(例如,前期使用SGD所找到的相对sharp的解),但仍然停留在当前的山谷(valley)中。第二个阶段,SAM会以指数快的速度收敛到一个更加flat的解。见图1b的示意图。在表1中,我们把这样一个动力学图景拆分成4个claim,并且每一个claim对应一个定理。这样一个Picture解释了SAM在后期选择更加flat的minima的原因,为我们解释SAM的有效性提供了新的视角。
值得一提的是,我们还探索了从SAM切换到SGD的训练方法。实验发现,仅仅在训练早期使用SAM对模型最终的泛化能力的影响甚微。因此,我们猜想:训练后期使用的优化算法对模型的最终性能拥有更加重要的影响。基于这个猜想,我们将发现从SAM推广到了Adversarial Training(AT)。类似地,我们发现,仅在最后几个epoch使用AT训练模型,一样可以达到和全程使用AT训练模型类似的对抗鲁棒的模型。
总结一下,我们的研究专注于SAM后期的隐式偏差。我们的理论图景推动了学界对SAM的背后原理的理解。
本期文章由陈研整理
近期精彩活动推荐

CVPR 2025一作讲者招募中,欢迎新老朋友来预讲会相聚!
关于AI TIME
AI TIME源起于2019年,旨在发扬科学思辨精神,邀请各界人士对人工智能理论、算法和场景应用的本质问题进行探索,加强思想碰撞,链接全球AI学者、行业专家和爱好者,希望以辩论的形式,探讨人工智能和人类未来之间的矛盾,探索人工智能领域的未来。
迄今为止,AI TIME已经邀请了2000多位海内外讲者,举办了逾700场活动,超800万人次观看。

我知道你
在看
提出观点,表达想法,欢迎
留言

点击 阅读原文 观看作者讲解回放!


















 482
482

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









