






在之前文章中,我们已经介绍过腾讯开源最新视频模型如何使用ComfyUI,目前腾讯混元视频模型已经支持LORA训练了,这也意味着混元视频模型逐步成熟。LORA的训练意味着LORA训练作者可以根据需求训练增强视频素材,包括画面风格、主体人物、视频镜头控制或者是场景故事等。这样将极大增强视频生成过程的控制,从而简化视频生成和创作。我们这次将介绍一下如何在无阶未来训练混元LoRA,本次以图片的形式作为素材训练,介绍如何使用素材进行混元丹炉训练的基本方法。
我们登录后选择下图中的腾讯混元LoRA训练丹炉,点击立即启动,创建一个实例。

来到控制台,点击刚建好实例的Jupyter。无阶未来平台的混元丹炉需要进入jupyter去操作,无法自启动直接操作。
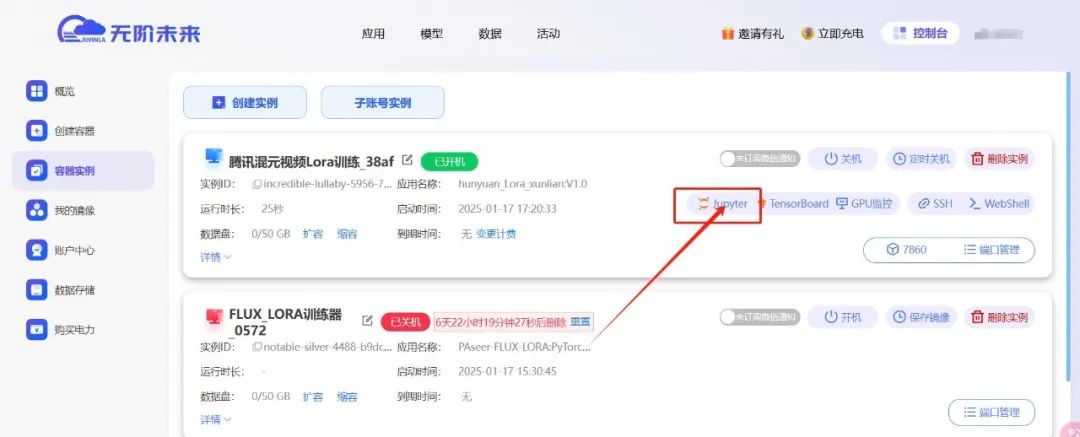
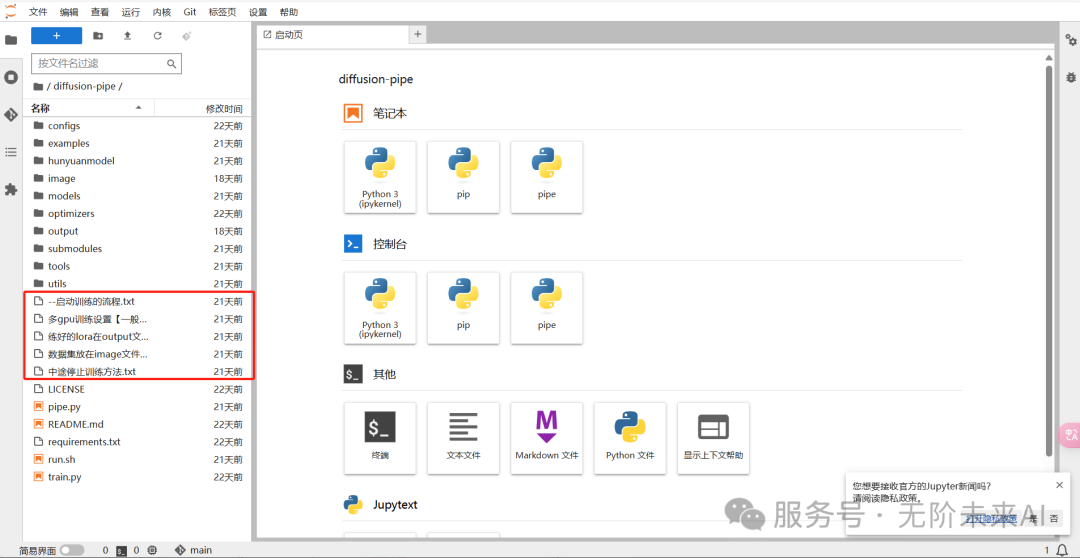
进入jupyter后我们可以看到,左侧有使用方法的txt文件供你查看。使用教程包含启动训练流程、多GPU训练教程(市面上默认的混元训练大部分仅支持单卡,但在无阶未来,我们支持多GPU训练!这样你的训练精度将大大提升!)以及如何中途停止训练方法。
要注意的是:素材需要放在image文件夹中,而训练好的内容及预览则都在output文件夹中!记住这俩文件夹,方便随时找到自己训练的内容!
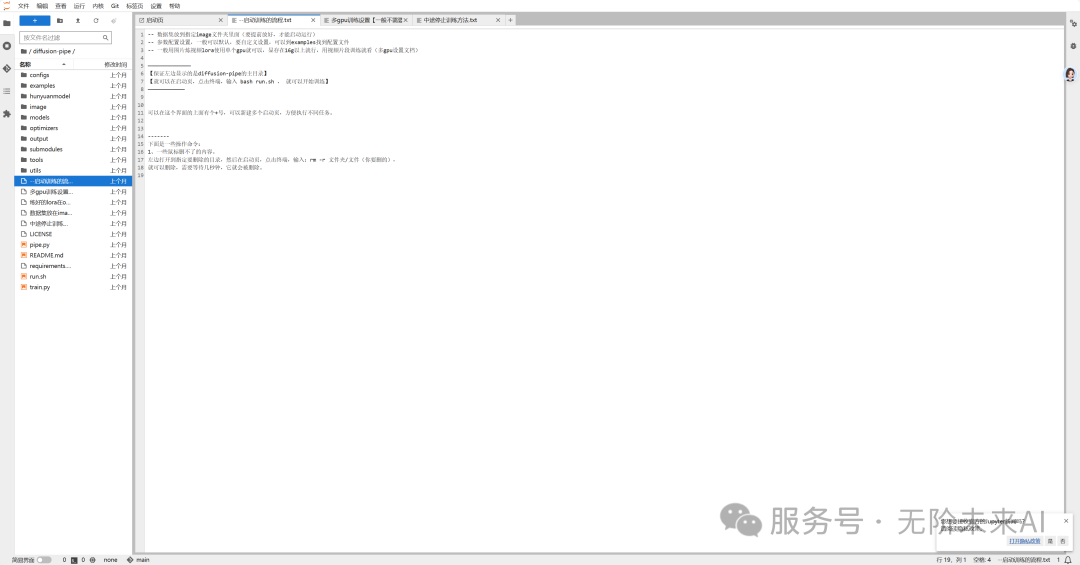
目前该镜像没有内置打标器,因此需要我们处理好图片训练集后再进行上传,我们需要按照教学的txt流程将打好标的训练集传入image文件夹中。市面上常见的DW打标器在平台-秋叶镜像内也有,也可以先启用秋叶LoRA训练器进行打标后保存训练集,再上传至混元丹炉。
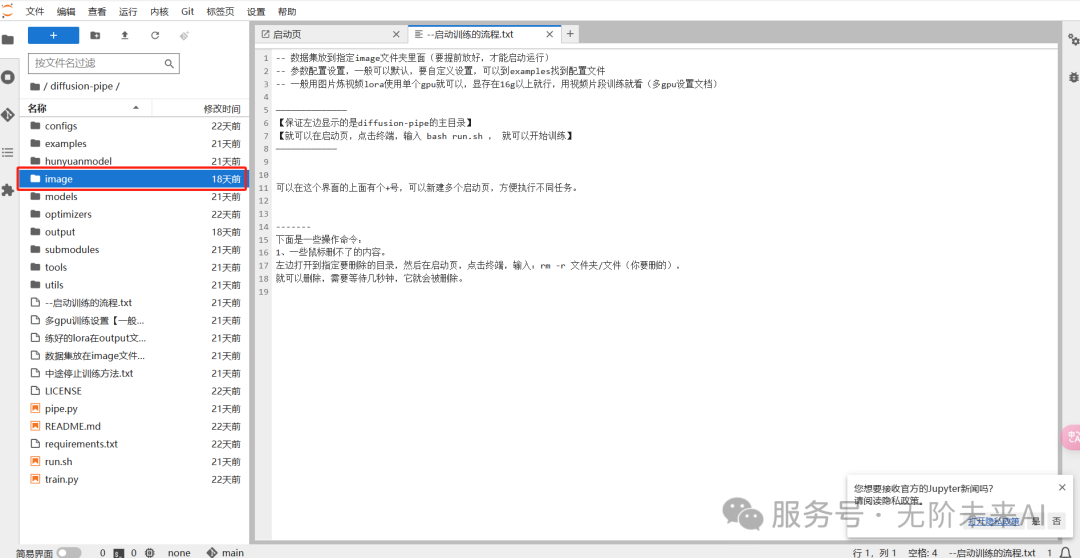
回到启动页,再点击下面的终端。
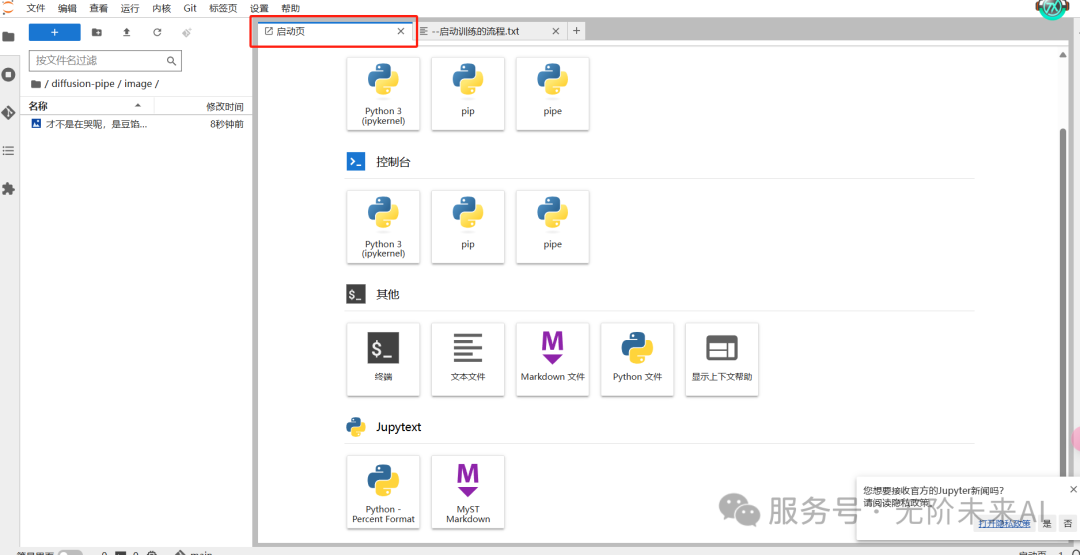
此时页面如下图所示,所处路径如图中所框选。
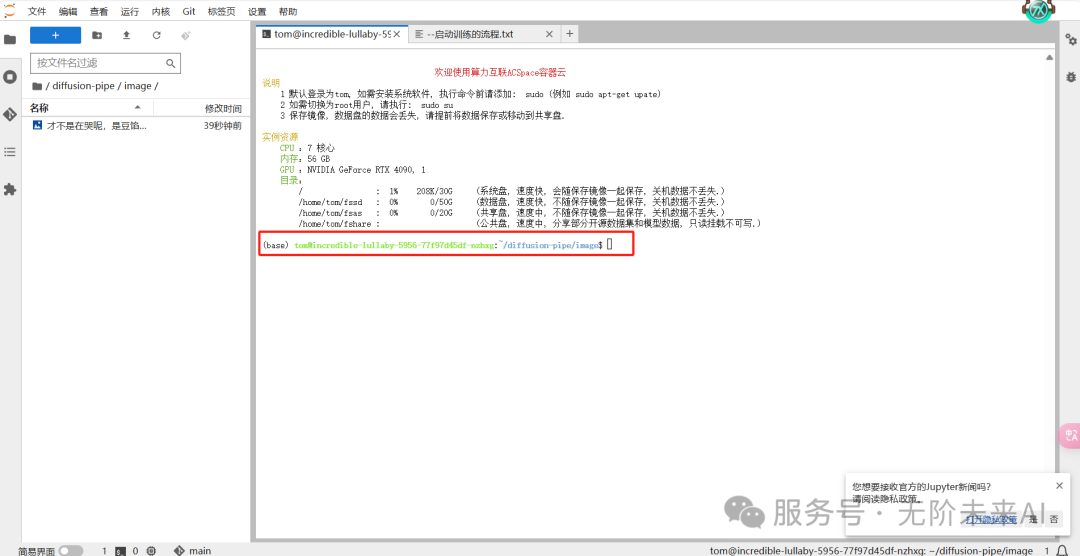
我们输入“cd”并点击回车回到根目录,如下图所示。
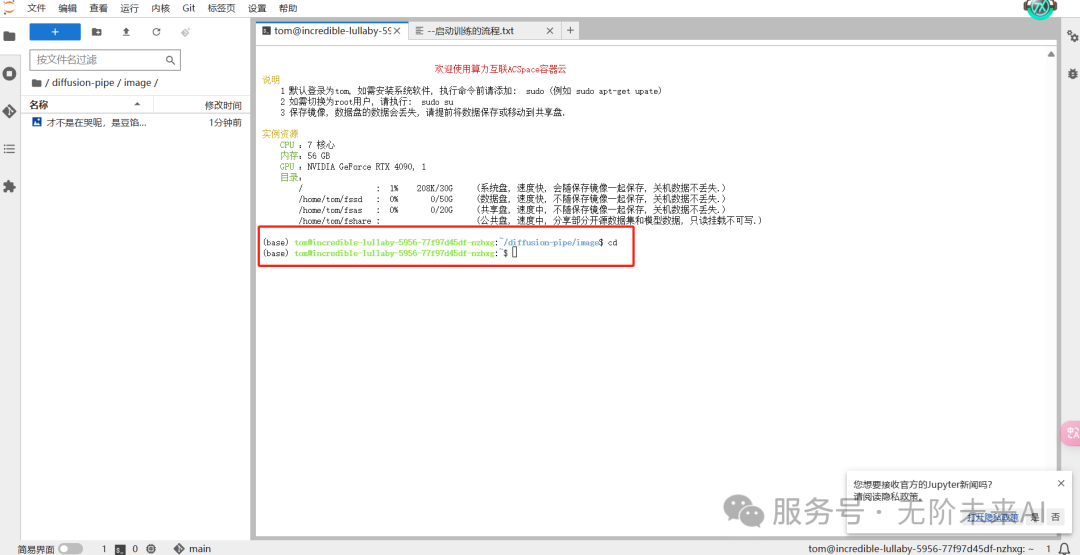
我们输入bash run.sh命令,再点击回车即可开始训练,等待output中的输出即可。
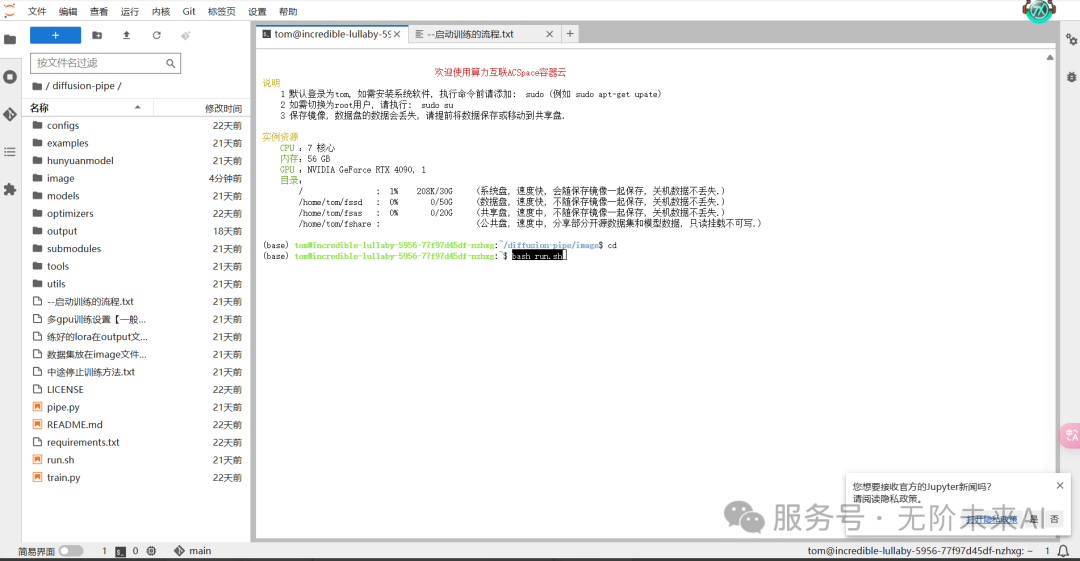
训练参数先使用默认即可,这就是训练的基本默认方法了。采用图片进行训练后的lora可大大提升混元AI视频的内容精度,比如人脸固定识别等。后续我们在介绍如何使用视频作为素材时将再详细介绍相关参数,请大家敬请等待。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









