






基于Raft共识算法和快照的KV数据库
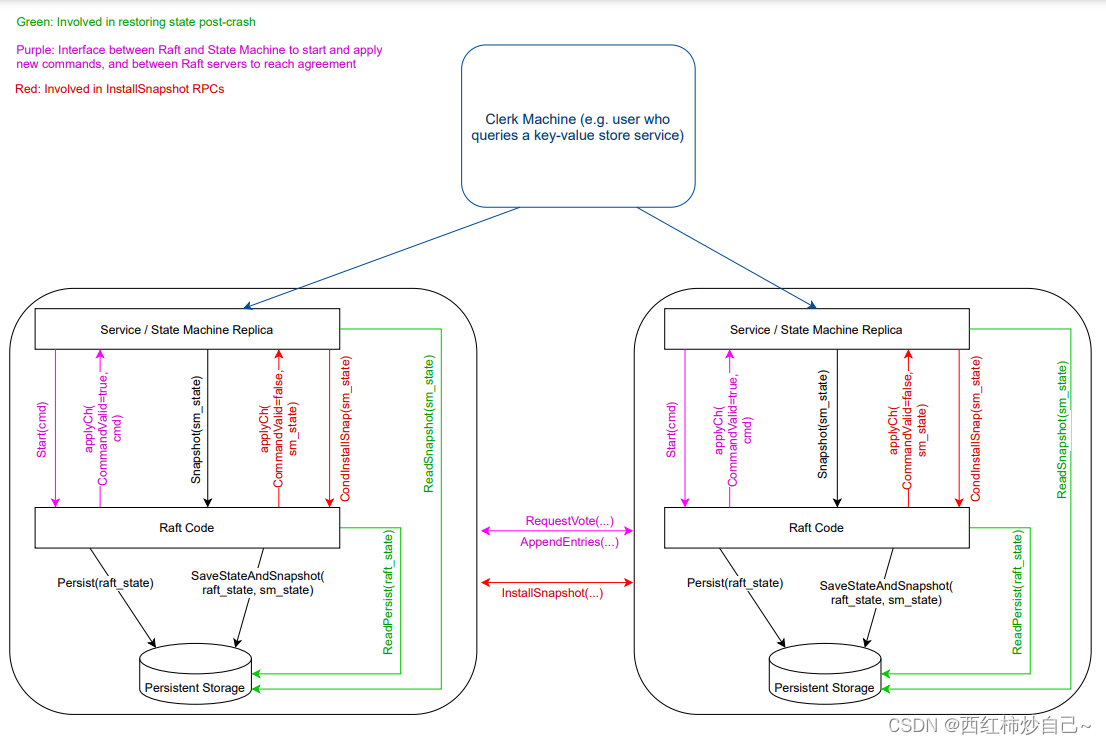
复制状态机
相同的初始状态+相同的输入=相同的结束状态
Persister+ KVsever + Raft 就构成了一个复制状态机
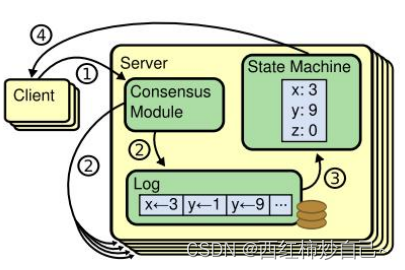
RAFT 共识算法
分布式场景下的多个备份节点,需满足一致性,即满足复制状态机。
在Raft中,leader将客户端请求(command)封装到一个个log entry中,将这些log entries复制到所有follower节点,然后大家按相同顺序应用log entries中的command,根据复制状态机的理论,大家的结束状态肯定是一致的。
状态简化:
Leader Candidate Follower
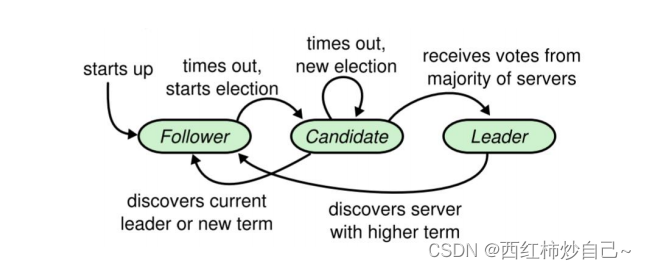
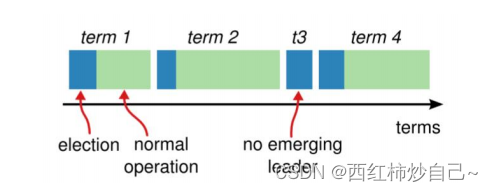
Raft 将时间分为任意长度的周期(term),每个Leader每次领导一个周期。
多数投票法则保证每个周期只有一个实际Leader
三种RPC通信:
RequestVote RPC
AppendEntries RPC
InstallSnapshot RPC
Go语言编程和并发编程的几种模式:
计时器实现:
维护last_time变量。
go func{
for {
检查 now_time-last_time 是否超时
time.Sleep(1 * time.Millisecond)
}
}
cond模式实现多协程 合作某个进程变量
func {
cond:=sync.Newcond(&mu)
for p:=range servers{
go func (sever) {
rpc(sever)
mu.Lock()
修改变量x
cond.Broadcast()
mu.Unlock()
}(p)
mu.Lock()
for !x {
cond.Wait()
}
.......
mu.Unlock()
}
}
领导人选举:
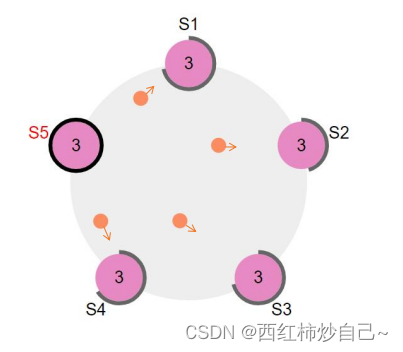
最终会有三种结果:
• ①它获得超过半数选票赢得了选举 -> 成为主并开始发送心跳
• ②其他节点赢得了选举 -> 收到新leader的心跳后,如果新leader的任期号不小于自己 当前的任期号,那么就从candidate回到follower状态。
• ③一段时间之后没有任何获胜者 -> 每个candidate都在一个自己的随机选举超时时间后 增加任期号开始新一轮投票。
**节点循环进程,时刻检测超时竞选计时器**
func (rf *Raft) ticker() {
for rf.killed() == false{
Electiontimeout:=Electioninterval +rand.Intn(150)
rf.mu.Lock()
//心跳超时
start_time:=time.Now().UnixNano() / int64(time.Millisecond)
delt_time:=int(start_time-rf.lastreceive)
if( (delt_time>Electiontimeout) && (rf.state!="leader") ){
go rf.attempeletion()
}
rf.mu.Unlock()
time.Sleep(1 * time.Millisecond)
}
}
**竞选Leader**
func (rf *Raft) attempeletion() {
更改为Candidate状态,增加term,为自己投票
利用**cond模式**并行申票并检查投票结果{
若自身状态(state,currentterm)发生变化:
(发送RPC需要解锁,会导致自身状态变化)
(比如此时的选举过程是一个**已经超时的选举过程**)
回归Follower,退出选举
若收到更新term的回复:
回归Follower,退出选举
}
半数通过:
当选Leader,开始心跳协程,重置nextindex和matchindex
未通过:
回归Follower
}
**Handle RequestVote RPC**
func (rf *Raft) RequestVote(args *RequestVoteArgs, reply *RequestVoteReply) {
如果竞选者周期过期,拒绝投票
若收到更新term的回复:
回归Follower
(若Leader崩溃后又重连,或者落后的Candidate,需要这条判定为新的Candidate投票,**保证多数分区一定可以选出Leader**)
只会在未投票的前提下,投票给日志更新的节点
(日志更新:更新Term,或者相同Term更长的Index)
}
**Leader发送心跳,节点收到心跳,验证RPC后重置选举计时器**
**实际设计上,心跳还负责一致性检查**
func (rf *Raft) heart(term int) {
Hearttimeout:=Heartinterval
for rf.killed() == false {
rf.mu.Lock()
if rf.state!="leader"{
停止发送心跳
rf.mu.Unlock()
return
}
rf.mu.Unlock()
rf.attempappend(term)
time.Sleep(time.Duration(Hearttimeout) * time.Millisecond)
}
}
日志复制
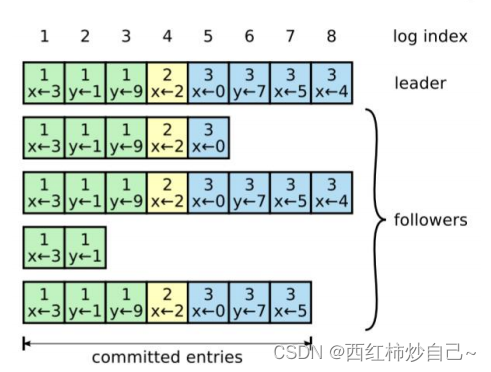
**Leader服务器接受下层Kv数据库传来的命令,在所有的节点达成共识**
**收到命令后,Leader向各节点追加日志**
func (rf *Raft) Start(command interface{}) (int, int, bool) {
index := -1
term := -1
isLeader := true
// Your code here (2B).
if rf.killed()==true {
return index, term, false
}
rf.mu.Lock()
defer rf.mu.Unlock()
defer rf.persist()
if rf.state!="leader"{
return index,rf.currentTerm,false
}
newEntry:=Entry{
Term: rf.currentTerm,
Index:rf.lastlog().Index+1,
Command: command,
}
index=rf.lastlog().Index+1
rf.log=append(rf.log,newEntry)
term=rf.currentTerm
go rf.attempappend(term)
return index, term, isLeader
}
**一致性检查、追加日志**
func (rf *Raft) attempappend(term int) {
并行向各节点追加日志(顺带一致性检查):
如果nextindex[i]在快照中:{
发送快照RPC
如果RPC解锁期间,自身状态发生变化:
退出
如果收到更新的Term:
转为Follwer
修改matchindex 和 nextindex
退出
}
发送日志:
将[prelogindex,lastindex]的日志打包
发送日志RPC
如果RPC解锁期间,自身状态发生变化:
退出
如果收到更新的Term:
转为Follwer
append 成功:{
更新 matchindex 和 nextindex
}
append 失败:{
快速回滚{
1:x.term==-1 :
//Follower 日志少,下一次从 XLen 开始
i: 1 2 3 4 5
XLen
F: 4
L: 4 6 6 6
Pre Next
2:Leader中存在x.term:
i: 1 2 3 4 5
F: 4 4 4
L: 4 6 6 6
Last Pre Next
//意味着x.term周期传输正确
//从leader中x.term周期最后一个log下一个开始传输
3:Leader中不存在x.term:
//即该x.term所有log不合法
//将答案逼近至x.index开始传输
i: 1 2 3 4 5
F: 4 5 5
XIndex
L: 4 6 6 6
Pre Next
}
}
每次心跳,Leader开始尝试检查有没有任务需要提交
}
**Handle AppendEntries RPC**
func (rf *Raft) AppendEntries(args *AppendEntriesArgs,reply *AppendEntriesReply){
如果RPC过期,丢弃并提醒
如果收到更新的Term:
转为Follwer
如果自己是Candidate:
转为Follwer
(Leader可以通过请求投票RPC放弃自身身份)
更新周期,重置选举计时器
回复一致性检查:
失败{
1:如果自己的log更短,返回XLen=lastlogIndex+1
如果Prelogindex在自己的快照里,让 leader 下次从快照外面发,XLen=lastinclude+1
2:如果Prelogindex处有log,但周期不同
返回当前Xterm=prelogindex的周期,Xindex=此周期的第一个index
}
成功(即正常配对){
只截取RPC日志多余的且周期不一致的部分:
~~rf.log=rf.log[0:args.Prelogindex+1]~~ 错误
if entry.Index <= rf.lastlog().Index && rf.log[entry.Index-rf.log[0].Index].Term != entry.Term {
rf.log=rf.log[0:entry.Index-rf.log[0].Index]
}
(否则会被错序的心跳嘎掉,比如之前的空包心跳延迟,带数据的Append包先到来追加日志,结果被心跳包全部截取)
根据RPC中的LeaderCommitindex 更新自己的 Commitindex
}
}
**提交日志与应用日志协程 用cond/Broadcast联系**
func (rf *Raft) Leadercommit(){
//只能提交自己周期的任务,其他周期的任务顺带提交
rf.mu.Lock()
defer rf.mu.Unlock()
for i:=rf.commitindex+1;i<=rf.lastlog().Index;i++ {
if rf.log[i-rf.log[0].Index].Term!=rf.currentTerm {
continue
}
count:=1;
for j:=0;j<len(rf.peers);j++ {
if j==rf.me {
continue
}
if rf.matchindex[j]>=i{
count++;
}
}
if count>len(rf.peers)/2 {
rf.commitindex=i
}
}
rf.applyCond.Broadcast()
}
**应用协程睡眠,更新commitindex唤醒**
func (rf *Raft) apply(){
rf.applyCond=sync.NewCond(&rf.mu)
for !rf.killed() {
rf.mu.Lock()
for rf.lastapplied >= rf.commitindex {
rf.applyCond.Wait()
}
if rf.log[0].Index > rf.lastapplied+1 {
rf.mu.Unlock()
return
}
commitIndex := rf.commitindex
lastApplied := rf.lastapplied
applyEntries:=rf.log[lastApplied+1-rf.log[0].Index:commitIndex+1-rf.log[0].Index])
rf.mu.Unlock()
//解锁后进行apply
for _, entry := range applyEntries {
rf.applyChan <- ApplyMsg{
CommandValid: true,
Command: entry.Command,
CommandIndex: entry.Index,
Term : entry.Term,
}
}
rf.mu.Lock()
**rf.lastapplied = max(rf.lastapplied, commitIndex)
(因为应用过程中解锁,需要加max函数确保单调递增)**
rf.mu.Unlock()
}
}
持久化
持久化是指将数据存放在磁盘、SSD、闪存等,以备节点重启后可以凭借持久化数据重建状态。
需要持久化:
VoteFor:确保一个周期内只有一个Leader,即节点不能重复投票。
CurrentTerm:确保一个周期内只有一个Leader,若节点重启后term为0,则收到任意term的请求投票都会使其VoteFor重置并转换为Follower,所以有可能重复投票。
Log:当系统重启后,需要依靠日志重建,重新提交应用Entry
不需要持久化:
CommitIndex/LastApplied/NextIndex / MatchIndex:
,因为基本的Raft算法假定了服务(如键-值数据库)不会保存任何持久化状态(快照优化),当重启后,Leader可以使用一致性检查,重新调整NextIndex/MatchIndex,然后从头(0/lastIncludeIndex)提交Entry,并在KVsever上重新应用
日志压缩——快照
随着raft集群的不断运行,各状态机上的log也在不断地累积,总会有一个时间会把状态机的内存打爆,所以我们需要一个机制来安全地清理状态机上的log
Raft采用的是一种快照技术,每个节点在达到一定条件之后,可以把当前日志中的命令都写入自 己的快照,然后就可以把已经并入快照的日志都删除了。
快照中一个key只会留有最新的一份value,占用空间比日志小得多。
优点:
Ⅰ:节省状态机上的内存
Ⅱ:状态机重启后,由于快照是持久化的,只需要重新部署LastIncludeIndex之后的数据,节省时间
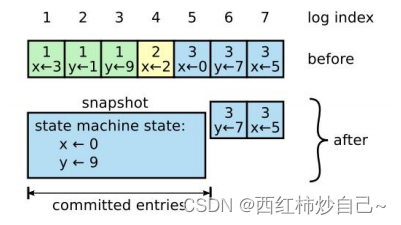
**当KV服务器从applychan提取新的Index命令发现持久化的数据长度>阈值后,
将当前的数据库、客户端的最大SEQ 拍成快照,快照传到Raft,通知Raft[:Index]已生成快照**
func (rf *Raft) Snapshot(index int, snapshot []byte) {
如果快照超出日志范围 || 快照Index还未提交:
返回
裁剪日志
持久化快照
}
func (rf *Raft) attempappend(term int) {
并行向各节点追加日志(顺带一致性检查):
如果nextindex[i]在快照中:{
发送快照RPC
如果RPC解锁期间,自身状态发生变化:
退出
如果收到更新的Term:
转为Follwer
修改matchindex 和 nextindex
退出
}
Handle InstallSnapshot RPC
func (rf *Raft) InstallSnapshot(args *InstallSnapshotArgs,reply *InstallSnapshotReply){
{
如果RPC过期,丢弃
如果收到更新的Term:
转为Follwer
重置选举计时器
如果快照的内容已经提交(args.LastIncludedIndex<=rf.commitindex)
退出
开启新协程等待解锁后应用快照
}
**当KVsever会不断从applychan中提取共识成功的命令,
取出快照后,调用CondInstallSnapshot在raft中安装,
只有在raft安装成功后才会在KVsever中安装快照**
func (rf *Raft) CondInstallSnapshot(lastIncludedTerm int, lastIncludedIndex int, snapshot []byte) bool {
如果快照过期(lastIncludedIndex <= rf.commitindex):
返回raft安装快照失败
如果快照包含所有日志:
日志全覆盖
否则:
留下[lastIncludeIndex:]的日志
持久化快照,更新CommitIndex和Lastapplied为LastIncludeIndex
}
基于Raft的KV数据库
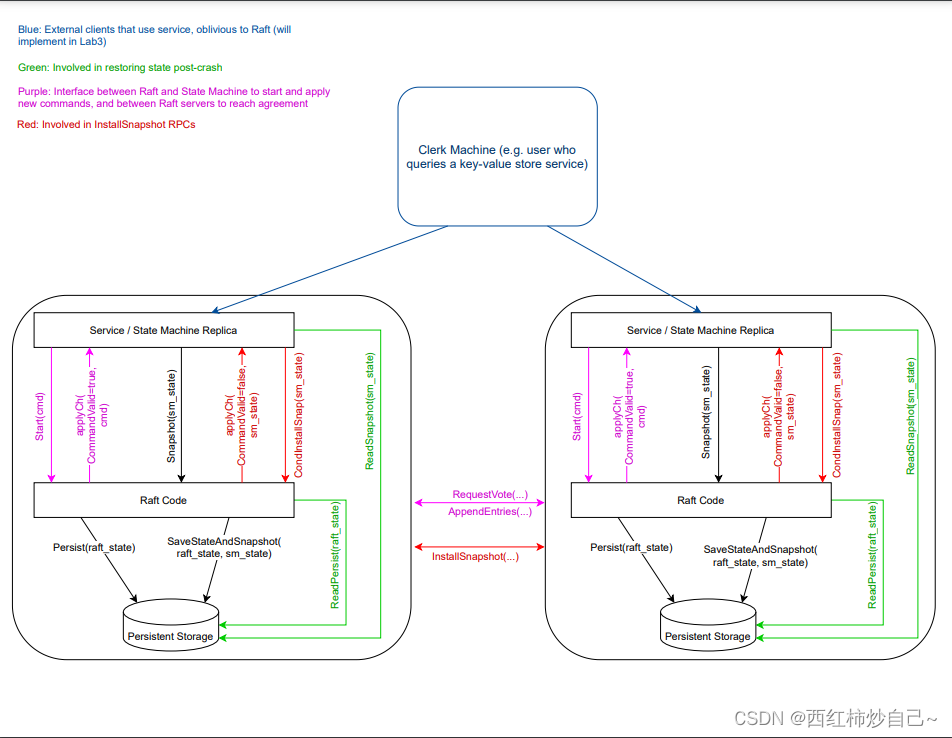
client
轮询所有Sever,一切交给Sever层,保证最终给用户答案!
seqid int //单调递增的命令ID
clientid int64 //Sever通过clientid和seqid保证来自一个客户端的命令不重复
**轮询Sever,直到得到正确答案**
func (ck *Clerk) Get(key string) string {
ck.seqid++
args:=GetArgs{Key:key,Clientid:ck.clientid,Seqid:ck.seqid}
serverId:=ck.leaderid
for {
reply := GetReply{}
ok := ck.servers[serverId].Call("KVServer.Get", &args, &reply)
if ok {
if reply.Err == ErrNoKey {
ck.leaderid = serverId
return ""
} else if reply.Err == OK {
ck.leaderid = serverId
return reply.Value
} else if reply.Err == ErrWrongLeader {
serverId = (serverId + 1) % len(ck.servers)
continue
}
}
serverId = (serverId + 1) % len(ck.servers)
}
}
**轮询Sever,直到得到正确答案**
func (ck *Clerk) PutAppend(key string, value string, op string) {
ck.seqid++
serverId := ck.leaderid
args := PutAppendArgs{Key: key, Value: value, Op: op, Clientid: ck.clientid, Seqid: ck.seqid}
for {
reply := PutAppendReply{}
ok := ck.servers[serverId].Call("KVServer.PutAppend", &args, &reply)
if ok {
if reply.Err == OK {
ck.leaderid = serverId
return
} else if reply.Err == ErrWrongLeader {
serverId = (serverId + 1) % len(ck.servers)
continue
}
}
serverId = (serverId + 1) % len(ck.servers)
}
}
Sever
**与Raft层交互**
rf *raft.Raft
applyCh chan raft.ApplyMsg
clientmaxseq map[int64]int //保证命令不重复执行,单调递增
waitAnswer map[int]chan Op //实现等候Raft共识之后再返回结果的异步操作
DataBase map[string]string //数据库
func (kv *KVServer) Get/PutAppend (args *GetArgs, reply *GetReply) {
如果Raft崩溃 || 不是Leader:
返回ErrwrongLeader
index,_,_:=kv.rf.Start(op)//通知raft共识,返回命令Index
创建kv.waitRaft[Index]通道,等待Raft共识
...
如果Index位置共识成功(从apllychan提取):
(Index + ClientId + SeqId 唯一确定之前的命令)
如果Index不是之前的命令:
返回ErrwrongLeader
否则:
返回OK,Value
如果共识超时:
返回ErrwrongLeader
删除通道
}
**循环协程,时刻监听和Raft的通道applych**
func (kv *KVServer) Listen (){
**监听到共识成功的日志命令(在Index):**
如果命令过期(msg.CommandIndex <= kv.lastIncludeIndex):
丢弃
如果命令重复(不满足Client的SeqId单调递增)
丢弃
(该命令应该被执行)
如果是Put/Append操作:
操作数据库
监测到持久化的数据超过阈值:
将当前的数据库、客户端的最大SEQ 拍成快照,快照传到Raft,通知Raft[:Index]已生成快照
汇报给Get/PutAppend正在等待Index阻塞的协程:Index位置已经共识成功
**监听到共识成功的快照:**
调用CondInstallSnapshot在raft中安装,只有在raft安装成功后才会在KVsever中安装快照
}
个人理解
当收到更新Term的RPC后,修改自身Term和转变为Follower的目的:
若Leader崩溃后又重连,或者落后的Candidate,由于需要多数当选,需要这条判定让过期的Leader和多余的Candidate为新的Candidate投票,保证多数分区一定可以选出Leader
投票时,只投给 日志更新的结点 和 多数当选 的目的:
由于脑裂后,多数分区的结点的日志才可以提交并被client应用,所以我们需要保证Commitindex是单调递增的,当愈合后,多数分区的节点不会给少数分区的节点投票(少数分区的日志更旧),所以只有多数分区的节点才有可能获得超过半数的投票。保证日志始终往前推进!
MatchIndex 和 NextIndex的作用:
Leader当选后,需重置NextIndex为lastlogIndex+1,MatchIndex为0,在下一个日志来临前,随后通过一致性检查不断减小nextindex增加matchindex,直到一致性检查成功,此时刚好两个数值碰头(nextindex=matchindex+1)。
通俗来讲,nextindex表示Leader对于当前节点日志的最高期望,matchindex表示最低期望(保守期望),所以也根据matchindex来判断是否提交日志。
为什么CommitIndex一定会单调递增:
因为大多数原则决定了一定至少有一只具有最新(最大)commitIndex的节点在当前的多数分区内,又因为更新投票原则决定了它一定会当选(若只有它),故单调递增
如果两个节点中的两个条目有相同的 log index 和 term,则它们之前的所有日志也一定相同:
因为相同周期的日志都是由一个Leader在term的周期,且一定是满足一致性检查后才追加的。
而一致性检查要求当前index之前的日志都=Leader的日志,所以两个节点index之前的日志也一定相同,都等于term下的Leader在index之前的日志。(但是并不代表两个节点index之前的日志是被提交的,因为他们和Leader可能当时在少数分区,该部分日志还没有被删除)。
Raft共识协议会丢弃命令吗:
不会!它只会丢弃KV数据库服务器从下层给它发的共识请求(ErrLeader,ErrTimeout),但是如果共识失败,来自客户端的命令还是会被Client发给其他的KV数据库服务器,然后给它上层的Raft共识。
CondInstallSnapshot函数的必要性:
存在快照不会被安装的情况:先发送一个[nextIndex,lastlogindex]的Entryies被网络延迟了还没有被提交,Raft被提醒快照,nextIndex进入了快照范围内。
下次AppendEntrie则会发送快照,Follower首先收到快照,然后应用快照,在安装快照之前(应用快照会解锁),收到了Entries并提交成功,则快照的LastIncludeIndex<=CommitIndex.不应该被安装(raft不应该安装,但此时没法通知KVsever不能安装)
加入CondInstallSnapshot后,KVsever收到快照后判断CondInstallSnapshot可以安装后再进行安装,不能安装后则不安装。将KVsever和Raft的快照安装原子性。
快照安装逻辑:Raft发送快照->kvsever取出快照->调用CondInstallSnapshot->Raft判断安装成功->KVsever安装快照
为什么Index不能唯一确定一个命令:
当前Leader不能保证当前Index的命令一定可以共识成功(可能在少数分区或崩溃…),在Sever还未等待超时前,当前Raft在Index的位置接受了来自新Leader的一致性检查并提交到通道。Sever从通道取出后应通过唯一标志[ClientId && SeqId]判定它不是之前的命令,然后回复给Client错误ErrwrongLeader,让其继续轮询发送该命令,直到该命令可以被成功执行。
















 251
251











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









