







文章目录
前言
因为忙着期末考试,以及2D需要大部分的代码重构…这一篇对于上一篇其实拖得比较久。
一、日志压缩(Log compaction)的背景
首先我们要搞懂日志压缩的背景是什么,为什么需要日志压缩?
来看看paper中的描述:
Raft’s log grows during normal operation to incorporate more client requests, but in a practical system, it cannot grow without bound. As the log grows longer, it occupies more space and takes more time to replay. Thiswill eventually cause availability problems without some
mechanism to discard obsolete information that has accumulated in the log。
这段的意思是:Raft 的日志在正常运行时会增长,以容纳更多的客户端请求,但在实际系统中,它不能无限制地增长。 随着日志变长,它会占用更多空间并需要更多时间来重播。 如果没有某种机制来丢弃日志中积累的过时信息,这最终会导致可用性问题。
也因此我们使用Snapshot(快照)来简单的实现日志压缩。
二、Snapshot的解读
2.1、Snapshot的方式
在Paper的figure12中有这样一张图可以很好的说明快照的作用:
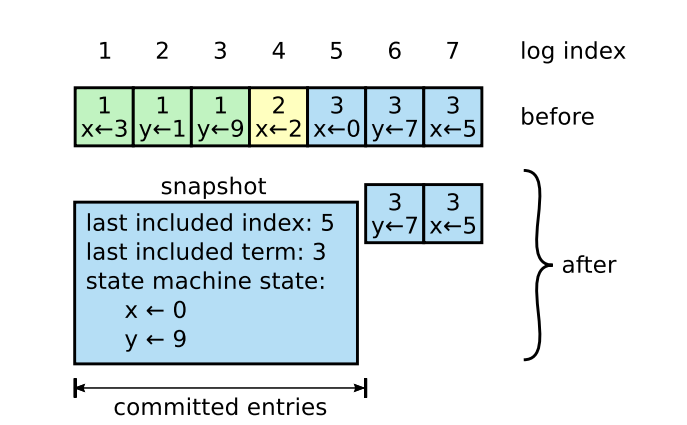
这幅图其实也很好理解,现在让笔试简单解释下:假设现在log中存储了x、y的更新信息。x的更新信息依次是3、2、0、5。y的更新信息依次是1、9、7。且日志下标1~5的日志被commit了,说明这段日志已经不再需要对当前节点来说已经不再需要。那么我们就存取这段日志的最后存储信息当做日志也就是x=0,y=9的时候并记录最后的快照存储的日志下标(last included index)以及其对应的任期。此时我们新的日志就只需要6、7未提交的部分,log的长度也从7变为了2。
也因此可以看出快照存储是根据raft节点的个数决定。每个节点都会存取自身的快照,快照的信息就相当于commit过后的日志。。
2.2、Snapshot与AppendEntries的联系
回到raft的日志增量中,其实我们可以发现,commit更新的流程其实是,Leader发送给各个节点进行同步日志,然后返回给leader同步RPC的结果,更新matchIndex。如果超过半数节点已经同步成功后的日志,那么leader会把超过半数,且最新的matchIndex设为commitIndex,然后再由提交ticker进行提交。然后在下一次发送日志心跳时再更新followers的commitIndex下标。
也因此就会可能有半数的节点,又或是网络分区,crash的节点没有更新到已提交的节点,而这段已提交的日志已经被leader提交而抛弃了。那么这个时候就需要leader发送自身的快照,安装给这些followers。
2.3、Snapshot的优缺点
首先提供出原文描述:
There are two more issues that impact snapshotting performance. First, servers must decide when to snapshot. If a server snapshots too often, it wastes disk bandwidth and energy; if it snapshots too infrequently, it risks exhausting its storage capacity, and it increases the time required to replay the log during restarts. One simple strategy is to take a snapshot when the log reaches a fixed size in
bytes. If this size is set to be significantly larger than the
expected size of a snapshot, then the disk bandwidth overhead for snapshotting will be small.
The second performance issue is that writing a snapshot can take a significant amount of time, and we do not want this to delay normal operations. The solution is to use copy-on-write techniques so that new updates can be accepted without impacting the snapshot being written. For example, state machines built with functional data
structures naturally support this. Alternatively, the operating system’s copy-on-write support (e.g., fork on Linux) can be used to create an in-memory snapshot of the entire state machine (our implementation uses this approach).
可以看出Snapshot会有两个问题:
- 快照设置频繁下带来的浪费磁盘带宽和能源问题。当然快照设置不过与频繁也会导致存储问题。因此合理的安装快照才是正确的解决办法。 Paper中提到的策略就是对Log设置一个合理的大小,超过这个大小就进行日志快照的更新。
- 另外的就是在写入快照时进行的时间开销。因为可能在写入快照时会有竞争,并加锁。paper中提到的也是经典copy-on-write方法,在更新快照时,先临时储存一份log的备份。
三、lab2D
3.1、交互过程
对2D来说其实并不要求解决性能方面带来的开销,这里从官方的实验指南提供的交互图开始进入实验。
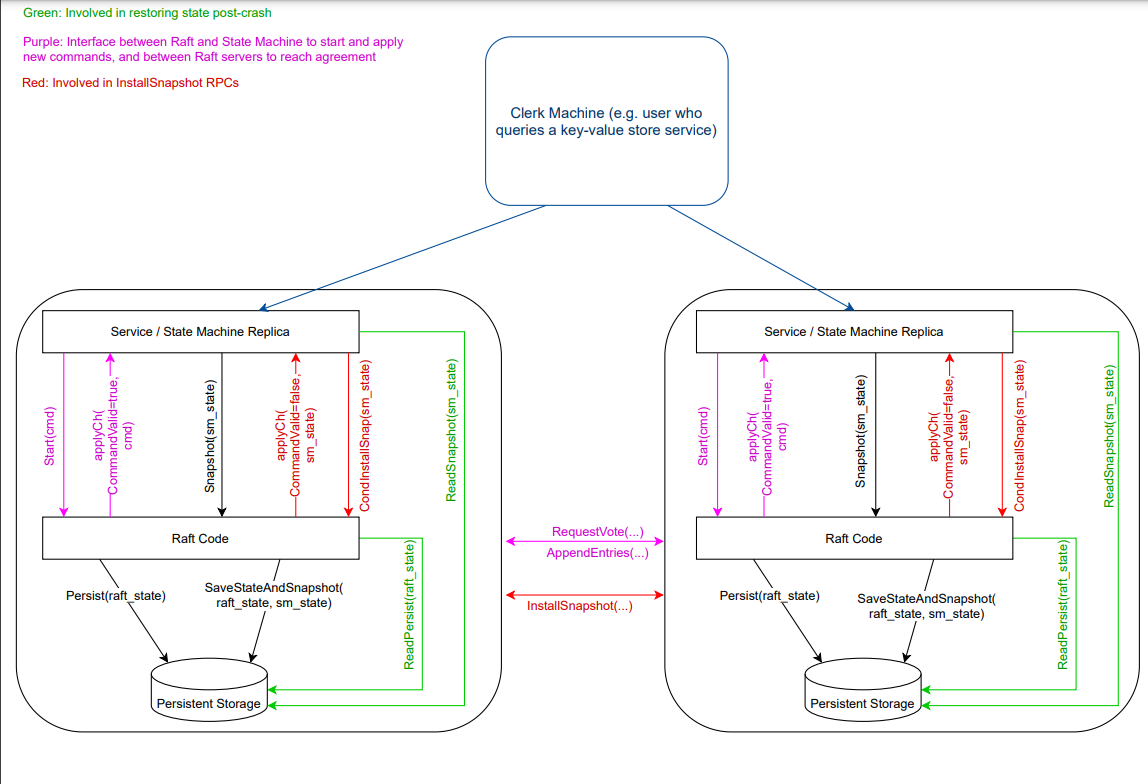
通过这张图其实可以很好的复习一下整个lab2的全貌。具体的过程我后面会再出一篇进行总体的概述复习,这里针对快照部分进行描述。
从图中可以看出在单个节点中的Service层会对Raft节点调用Snapshot、与CondInstallSnap两个函数,这也是实验室中需要我们去编写的。对于自身的Raft节点来说需要对快照信息进行持久化的保存,也就是SaveStateAndSnapshot函数,这一部分的持久化信息会通过Service用ReadSnapshot进行调用。这两个关于持久化的函数,则实验室已经为我们在持久化persist.go中提供好了。
而对于节点之间的快照联系的话则是通过InstallSnapshot进行节点之间的沟通。这就取决于谁是leader了。
3.2、Snapshot与CondInstallSnap
- lab2中为我们提供了这两个函数需要我们自己去实现,现在来讲讲这两个函数的作用以及实现。
首先是Snapshot函数,对于Snapshot函数其实paper中也有提到过一段:
This snapshotting approach departs from Raft’s strongleader principle, since followers can take snapshots without the knowledge of the leader. However, we think thisdeparture is justified. While having a leader helps avoid conflicting decisions in reaching consensus, consensus has already been reached when snapshotting, so no decisions conflict. Data still only flows from leaders to followers, just followers can now reorganize their data。
因为snapshot其实就是service对rf调用的,使rf节点更新自身的快照信息。这样有的人可能会认为这样违反了Raft的强领导者原则。 因为跟随者可以在领导者不知情的情况下更新自己的快照。但是其实这种情况其实是合理的,更新快照只是为了更新数据,与达成共识并不冲突。数据仍然只是从领导者流向下层,followers只是通过快照去减轻它们的存储负担。
接着我们来看看具体的代码实现:
// Snapshot the service says it has created a snapshot that has
// all info up to and including index. this means the
// service no longer needs the log through (and including)
// that index. Raft should now trim its log as much as possible.
// index代表是快照apply应用的index,而snapshot代表的是上层service传来的快照字节流,包括了Index之前的数据
// 这个函数的目的是把安装到快照里的日志抛弃,并安装快照数据,同时更新快照下标,属于peers自身主动更新,与leader发送快照不冲突
func (rf *Raft) Snapshot(index int, snapshot []byte) {
// Your code here (2D).
if rf.killed() {
return
}
rf.mu.Lock()
defer rf.mu.Unlock()
// 如果下标大于自身的提交,说明没被提交不能安装快照,如果自身快照点大于index说明不需要安装
//fmt.Println("[Snapshot] commintIndex", rf.commitIndex)
if rf.lastIncludeIndex >= index || index > rf.commitIndex {
return
}
// 更新快照日志
sLogs := make([]LogEntry, 0)
sLogs = append(sLogs, LogEntry{})
for i := index + 1; i <= rf.getLastIndex(); i++ {
sLogs = append(sLogs, rf.restoreLog(i))
}
//fmt.Printf("[Snapshot-Rf(%v)]rf.commitIndex:%v,index:%v\n", rf.me, rf.commitIndex, index)
// 更新快照下标/任期
if index == rf.getLastIndex()+1 {
rf.lastIncludeTerm = rf.getLastTerm()
} else {
rf.lastIncludeTerm = rf.restoreLogTerm(index)
}
rf.lastIncludeIndex = index
rf.logs = sLogs
// apply了快照就应该重置commitIndex、lastApplied
if index > rf.commitIndex {
rf.commitIndex = index
}
if index > rf.lastApplied {
rf.lastApplied = index
}
// 持久化快照信息
rf.persister.SaveStateAndSnapshot(rf.persistData(), snapshot)
}
具体的解释留存在代码中,只要明白这个函数做的是什么其实就并不困难。值得一提的是persister.SaveStateAndSnapshot()的函数的解释在introduce中也有,其实就是如果节点被killed导致crash情况,然后重新启动后,其需要的持久化数据。
- CondInstallSnap函数:对于这个函数结合introduction中的解释其实也很好理解,对于这个函数的背景其实就是你发送了快照,那么你发送的快照就要上传到applyCh,而同时你的appendEntries也需要进行上传日志,可能会导致冲突。所以原文是这样描述的:
to avoid the requirement that snapshots and log entries sent on applyCh are coordinated。
可实际上,只要你在applied的时候做好同步,加上互斥锁。那么就可以避免这个问题,所以因此实验室中也提到这个api已经是废弃的,不鼓励去实现,简单的返回一个true,就行。
// CondInstallSnapshot
// A service wants to switch to snapshot. Only do so if Raft hasn't
// have more recent info since it communicate the snapshot on applyChan.
//
func (rf *Raft) CondInstallSnapshot(lastIncludedTerm int, lastIncludedIndex int, snapshot []byte) bool {
// Your code here (2D).
return true
}
3.3、InstallSnapshot RPC
这部分就是交互图中leader用来更新的。也像lab2a、lab2b中给了个表格自己去实现就行。

这里简单的再提一下什么时候需要快照。
之前也提到了,发送快照的时机其实就是,就是leader发送给follower时的日志已经被抛弃了。那么此时需要发送快照。那么因此发送快照的调用入口应该在进行日志增量时的日志检查。而查询的条件就是rf.nextIndex[server]-1 < rf.lastIncludeIndex比自身的快照还低。
//installSnapshot,如果rf.nextIndex[i]-1小于等lastIncludeIndex,说明followers的日志小于自身的快照状态,将自己的快照发过去
// 同时要注意的是比快照还小时,已经算是比较落后
if rf.nextIndex[server]-1 < rf.lastIncludeIndex {
go rf.leaderSendSnapShot(server)
rf.mu.Unlock()
return
}
- RPC结构体:
type InstallSnapshotArgs struct {
Term int // 发送请求方的任期
LeaderId int // 请求方的LeaderId
LastIncludeIndex int // 快照最后applied的日志下标
LastIncludeTerm int // 快照最后applied时的当前任期
Data []byte // 快照区块的原始字节流数据
//Done bool
}
type InstallSnapshotReply struct {
Term int
}
对于参数设计可以看看introduction对于有些字段offset通过偏移来拆分快照本次实验并不要求。
- RPC函数实现:
// InstallSnapShot RPC Handler
func (rf *Raft) InstallSnapShot(args *InstallSnapshotArgs, reply *InstallSnapshotReply) {
rf.mu.Lock()
if rf.currentTerm > args.Term {
reply.Term = rf.currentTerm
rf.mu.Unlock()
return
}
rf.currentTerm = args.Term
reply.Term = args.Term
rf.status = Follower
rf.votedFor = -1
rf.voteNum = 0
rf.persist()
rf.votedTimer = time.Now()
if rf.lastIncludeIndex >= args.LastIncludeIndex {
rf.mu.Unlock()
return
}
// 将快照后的logs切割,快照前的直接applied
index := args.LastIncludeIndex
tempLog := make([]LogEntry, 0)
tempLog = append(tempLog, LogEntry{})
for i := index + 1; i <= rf.getLastIndex(); i++ {
tempLog = append(tempLog, rf.restoreLog(i))
}
rf.lastIncludeTerm = args.LastIncludeTerm
rf.lastIncludeIndex = args.LastIncludeIndex
rf.logs = tempLog
if index > rf.commitIndex {
rf.commitIndex = index
}
if index > rf.lastApplied {
rf.lastApplied = index
}
rf.persister.SaveStateAndSnapshot(rf.persistData(), args.Data)
msg := ApplyMsg{
SnapshotValid: true,
Snapshot: args.Data,
SnapshotTerm: rf.lastIncludeTerm,
SnapshotIndex: rf.lastIncludeIndex,
}
rf.mu.Unlock()
rf.applyChan <- msg
}
对于这一部分其实传进的Dataj就是为了直接applied,当然原来数组中可能有快照意外的log,那么这些就进行拆分就好,要注意的是每次进行快照安装时,要进行持久化,如交互图当中所示。
3.5、下标Tips
其实对于2D下标更新的动作才是最繁琐的,每次进行更新日志的时候都要算上快照的下标,因为对于真实的下标例如我上面所示,1~ 7的日志中 截取了到5的快照,那么这个时候真实的日志下标并没有7,而是2,这个时候就得通过快照的偏移,去restore还原真实下标,对于这一部分,推荐使用工具类封装起来,这样对2D的修改时可读性就会比较高。
三、DEBUG杂谈
- 做完lab2D其实比较久,虽然2D下标修改做的事情是整个lab2中最繁琐的,但是它最难的不是因为这个。而是2D需要对2A,2B,2C去进行回归测试,最终达到几个测试通过。笔者也是经历了很多bug,但是经过期末考一些事,写这篇博客也算是有一段时间了,就简单的回忆下还记得的bug。
- 因为笔者前面ABC用的是select来进行异步。但是发现select其实会有很多隐性的阻塞、死锁问题、资源泄露问题,且对于多个ticker竞争之间,不仅会导致代码可读性变差,也可能会导致时间过长test失败。至于怎么发现的还是耐心的打印日志,发现没通过的test地方,最后一直在send a election,发现后是两个rf节点一直没收到另外一个节点的回复。然后两个节点各自持有一票,导致无法选举出来,一查那个节点卡在了apply chan部分,最后追根溯源就发现锁一直持有在发送ticker的select的地方。对于这个部分就是后面对整体的ticker进行了修改,分离出了提交日志、选举日志、日志增量三个ticker。
- 还有一个问题就是2C的figure8以及2B的RPC counts aren’t too high之间如果想要兼容,一定要注意三个ticker之间的休眠时间,进行协调,如果协调不一致,很容易导致原本就不好过的test直接失败,又或者一个通过另一个失败。
- 如果能够成功兼容前面三个实验,那么第4个实验主要注意的点其实就是发送快照的时机,下标的更改,然后以及持久化有没有进去。例如lab2C时的Persist此时要多持久化快照的下标以及任期两个参数。
总结
其实完全坚持下来还是不容易,对于2C其实也是有点侥幸,2D其实做了比较多的修改,包括三个RPC写下来,发现其实很多地方根本没那么多case,paper中的success才是最简洁的。接下来可能会写写写了lab2后分布式的总结与心得。然后六月也会收收心,刷刷算法,重新沉淀java去了。
- 关于test:
关于gitee:
gitee6.824-2022-lab2D















 507
507











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











