






前提:
上一篇博客已经介绍了如何搭建高可用的HDFS集群系统。在上一篇博客的基础上,继续搭建高可用的Maoreduce集群。上一篇博客的链接:http://blog.csdn.net/aizhenshi/article/details/72838670
1.先来看一下Mapreduce的集群搭建图
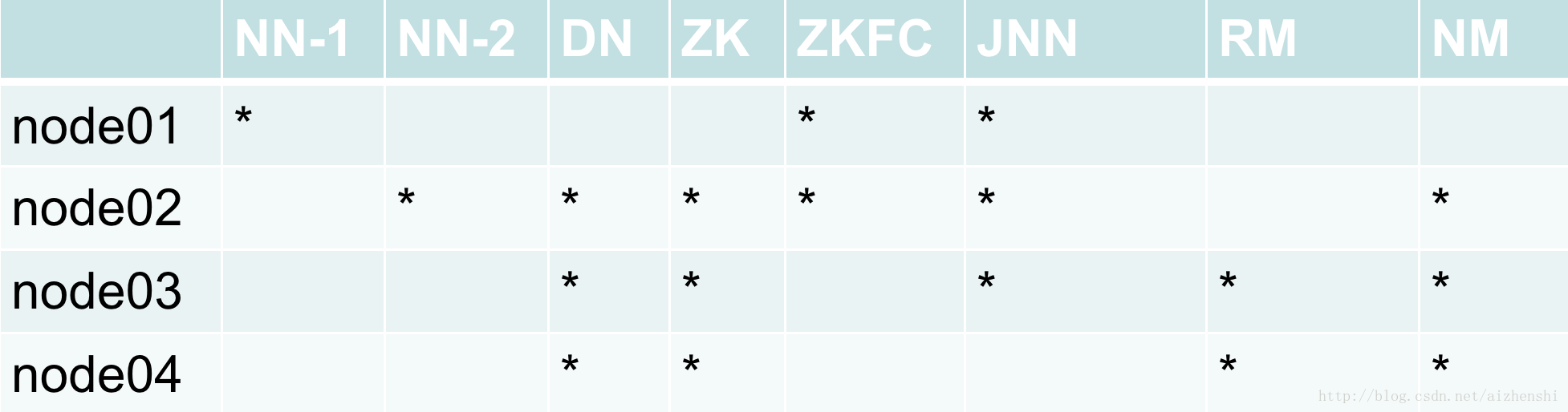
2.文件配置
1)配置mapped-site.xml
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>2)配置yarn-site.xml
<!--
Licensed under the Apache License, Version 2.0 (the "License");
you may not use this file except in compliance with the License.
You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software
distributed under the License is distributed on an "AS IS" BASIS,
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
See the License for the specific language governing permissions and
limitations under the License. See accompanying LICENSE file.
-->
<configuration>
<!-- Site specific YARN configuration properties -->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.resourcemanager.ha.enabled</name>
<value>true</value>
</property>
<property>
<name>yarn.resourcemanager.cluster-id</name>
<value>cluster1</value>
</property>
<property>
<name>yarn.resourcemanager.ha.rm-ids</name>
<value>rm1,rm2</value>
</property>
<property>
<name>yarn.resourcemanager.hostname.rm1</name>
<value>node3</value>
</property>
<property>
<name>yarn.resourcemanager.hostname.rm2</name>
<value>node4</value>
</property>
<property>
<name>yarn.resourcemanager.zk-address</name>
<value>node2:2181,node3:2181,node4:2181</value>
</property>
</configuration>3.启动集群系统
1)启动Zookeeper
在每个配置了Zookeeper的节点上执行命令:
zkServer.sh start2)启动hdfs分布式集群
在节点1执行命令:
./start-dfs.sh 3)启动ResourceManager
在配置了resourcemanager的节点3和4执行命令:
./yarn-daemon.sh start resourcemanager4.检查集群系统是否正常启动
1)浏览器打开:node1:50070,node2:50070,node3:8088
如果三个网页都正常的话,就证明集群已经正确配置了。














 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









