







 本文深入探讨了机器学习中公平性问题,指出算法在处理涉及敏感属性如性别、种族时可能引入歧视。为了消除差别影响,提出了提高数据集质量、改进算法设计和定义公平性指标等方法。文章强调,算法公平性不仅是技术问题,还需要考虑数据收集和分析过程中的偏见。此外,还介绍了统计均等、机会均等等公平性指标及其局限性,提倡人机共生和算法透明度来增强公平性。
本文深入探讨了机器学习中公平性问题,指出算法在处理涉及敏感属性如性别、种族时可能引入歧视。为了消除差别影响,提出了提高数据集质量、改进算法设计和定义公平性指标等方法。文章强调,算法公平性不仅是技术问题,还需要考虑数据收集和分析过程中的偏见。此外,还介绍了统计均等、机会均等等公平性指标及其局限性,提倡人机共生和算法透明度来增强公平性。

机器学习的公平性问题近几年受到越来越多的关注,该领域出现了一些新的进展。机器学习训练在涉及到性别、种族等与人相关的敏感属性时,常常会由于统计性偏差、算法本身甚至是人为偏见而引入歧视性行为。由此,为消除差别影响,改进机器学习公平性,主要途径包括提高训练数据集质量、改进算法降低对敏感属性的依赖以及定义指标量化和衡量歧视程度。本文分析了算法歧视的致因,侧重于数据问题给出了公平性的定义,介绍了统计均等等度量指标。文章也指出,各种算法公平性定义指标法都有其优缺点,并无法就公平性达成共识。因此,算法公平性并不能直观看成一种数学或计算机科学问题。本文的目的是使广大读者切身理解根植于机器学习算法中的不公平性。为此,作者力图以易于理解的方式阐释概念,避免使用数学表达。希望每位读者都能从阅读本文受益。
“做好人容易,但做到公正不易”——维克多·雨果,法国文学家
“我们需要捍卫那些我们从未谋面、甚至永远不会谋面的人的利益。”——Jeffrey D. Sachs,美国经济学家
有监督机器学习算法在本质上是判别性的。这种判别性的根源,在于算法是根据嵌入在数据中的特征信息进行实例分类的。的确,现实中此类算法就是设计用于分类的。判别性同样体现在算法的命名上。有别于根据特定类别生成数据的“生成算法”,此类对数据分门别类的算法通常称为“判别算法”。使用有监督的机器学习时,这种“判别”(discrimination,也可表述为“歧视”、“区别对待”)有助于按不同分布将数据划分为不同类别,如下图所示。
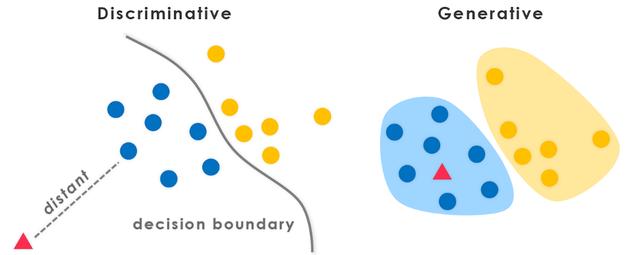
对任一数据集应用任何一种判别算法,无论是支持向量机、普通线性回归等参数回归算法,还是随机森林、神经网络、Boosting 等无参数回归算法,输出结果本身在道德上并不存在任何问题。例如,可以使用上周的天气数据去预测明天的天气,这在道德上毫无问题。然而,一旦数据集涉及对人类相关信息的描述时,无论是直接的还是间接的,都可能无意中导致特定于群组从属关系的某种歧视性。
人们已经认识到,有监督学习算法是一把双刃剑。它可以迎合人们的利益,例如提供天气预报等信息服务,或是通过分析计算机网络,检测攻击和恶意软件进而起到防护作用。但从另一方面看,它在本质上也会成为在某一层面上实施歧视的武器。这并不是说算法的所做所为是邪恶的,它们仅仅学习了数据中的表示,但这些表示本身可能融入了历史偏见的某种具体呈现,或是某个人的好恶和倾向性。数据科学中常说的一句习语就是:“垃圾入,垃圾出”,意思是模型高度依赖于所提供的数据质量。在算法公平性的场景中,可类似地表述为:“输入有偏差,则输出有偏差”。
数据原教旨主义
数据原教旨主义(data fundamentalism)拥趸者甚众。他们认为,通过对数据的经验观察,可以反映出世界的客观真相。
“数据足量,其义自见。”——Chris Anderson,《Wired》前主编,也是一位数据原教旨主义者。
“数据和数据集并非客观的,而是人类设计的产物。人们赋予数据以表达,从中推理,并以自身的解释去定义数据的内涵。隐藏在收集和分析阶段的偏见带来了很大的风险,它们对大数据等式的影响和数字本身是一样的。”——Kate Crawford,微软研究院社会媒体组首席研究员
原教旨主义者的假设从表面看似乎合情合理。但 Kate Crawford 在《哈佛商业评论》( Harvard Business Review ) 撰文给出了一个很好的反驳:
“波士顿市存在着坑洞的问题,每年需修补约两万个坑洞。为有效地配置资源,波士顿市政府发布了一款很好用的智能手机应用 StreetBump。该应用利用智能设备的加速度计和 GPS 数据,以非主动方式探测坑洞,然后立即上报市政府。虽然该应用的理念非常好,但存在一个明显的问题。美国低收入人群拥有智能手机的可能性较小,尤其是一些老年居民。此类人群的智能手机普及率可低至 16%。对于波士顿这样的城市而言,意味着智能手机数据集中缺少了一部分重要人群,通常是那些底层生活者。”——Kate Crawford
从本质上看,StreetBump 应用获取的数据主要来自相对富裕社区,来自相对贫困社区的数据则较少。这会导致人们的第一感觉是,相对富裕的社区存在更多的坑洞。但事实上,是因为来自于相对贫困社区的数据不足,社区居民不太可能具有智能手机去下载 SmartBump 应用。通常情况下,对结果产生影响最大的,正是数据集中缺失部分的数据。上面的例子很好地展示了一种基于收入的歧视。因此,在基于数据给出结论时,我们需要谨慎,因为数据中可能存在着“信号问题”。这种信号问题常被称为“采样偏差”。
另一个很好的例子是“替代制裁的罪犯矫正管理分析”算法(Correctional Offender Management Profiling for Alternative Sanctions),简称为 COMAS。COMAS 算法被美国许多州采用去预测累犯,即曾经犯过罪的人再次犯罪的可能性。但调查新闻机构
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









