






 文章提出了一种名为DIF(DeepIsolationForest)的新方法,它利用神经网络的表示学习能力改进随机森林的异常检测性能。DIF通过CERE(计算高效的深度表示集成方法)创建新的数据空间,并使用DEAS(偏差增强的异常评分函数)提高异常评分质量,解决了传统方法在处理高维非线性数据时的局限性。这种方法依赖于随机初始化的神经网络表示,以保持隔离过程的多样性和随机性。
文章提出了一种名为DIF(DeepIsolationForest)的新方法,它利用神经网络的表示学习能力改进随机森林的异常检测性能。DIF通过CERE(计算高效的深度表示集成方法)创建新的数据空间,并使用DEAS(偏差增强的异常评分函数)提高异常评分质量,解决了传统方法在处理高维非线性数据时的局限性。这种方法依赖于随机初始化的神经网络表示,以保持隔离过程的多样性和随机性。
motivation
- 随机森林中线性轴平行隔离方法经常导致:
(i)在检测高维/非线性可分离数据空间中难以隔离的硬异常时失败
(ii)臭名昭著的算法偏差,该算法将意外较低的异常分数分配给伪影区域 - 无法简单的通过x轴和y轴来切分环形分布的数据(高维非线性可分数据集)
创新点
- 利用神经网络的强大表示能力将原始数据映射到一组新的数据空间中,通过对这些新创建的数据空间执行简单的轴平行划分(相当于原始数据空间中不同大小的子空间上的非线性划分),可以很容易地实现非线性隔离。
- 提出了表示集成方法CERE,以确保DIF能够继承iForest的良好可扩展性。引入了异常评分函数DEAS,以利用映射密集表示中包含的额外定量信息,提高DIF的异常评分质量
方法
iTree τ 本质上是一个二叉树,树中的每个节点都对应于一个数据对象池。使用包含n个数据对象的子集作为根节点的数据池,根节点是从整个数据集中随机抽取的。iTree τ 通过以自上而下的方式递归隔离叶节点中的数据对象(即,将数据对象不相交地划分为两个子节点)来增长,直到节点中保留一个数据对象或达到最大深度限制。每个数据对象再树中都有一个遍历路径p(路径长度越短,异常往往容易隔离)
DIF(deep in forest)有两个重要的组件一个是随机表示集成函数和基于隔离的异常评分函数。
CERE:Computation-efficient Deep Representation Ensemble Method
在给定的小批量中同时计算所有集合成员。
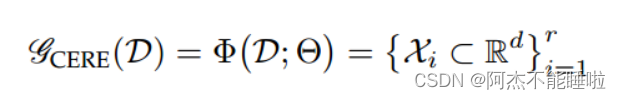
DEAS: Deviation-enhanced Anomaly Scoring Function
iForest中的标准异常评分过程只使用遍历路径的长度,即所有节点都被认为具有相同的重要性。路径长度仅提供有限的信息,这可能不能充分描述数据对象的隔离难度。除了在每个节点中进行定性比较外,还可以随时利用额外的定量信息,例如数据对象的特征值和分支阈值之间的关系.
受此启发,我们利用特征值与分支阈值的偏差程度作为额外的加权信息,以进一步改进隔离难度的测量。这些偏差程度是隔离难度的重要指标,因为新创建的数据空间中的特征值通常是密集分布的。
我们的偏差增强隔离异常评分函数如下:
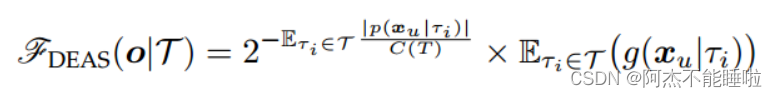
第一项是iForest中异常分数的平均深度,第二项是我们引入的基于偏差的异常分数。
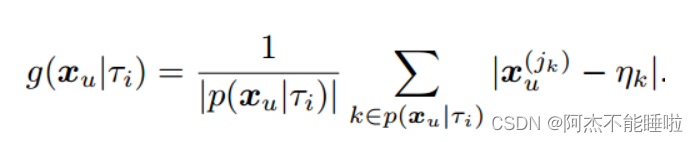
DIF的能力主要取决于:
- 神经网络强大的表示能力
非线性激活函数可以有效地调整和折叠划分边界,将非线性嵌入到隔离过程中,即使网络根本没有优化。另一方面针对各种数据类型开发了不同的深度学习架构,因此,DIF能够通过插入数据特定的网络主干(例如,多感知器网络、递归网络或图神经网络)来处理不同的数据类型,以产生表示。个人感觉更像一种数据空间的映射,通过神经网络使数据空间更好的分割。 - 优化表示的丢弃
有许多专门为异常检测涉及的表示学习网络,以获得优化良好的特征表示。如果优化目标很好地拟合输入数据,则这些表示比随机初始化的表示更有表现力。然而,由于以下两个主要原因,DIF没有使用优化的表示,而是使用随意初始化的表示。(i) 这些损失函数不是通用的。很难设计出一种能够适应具有多样化特征的不同数据的表示学习损失。(ii)下游数据分区可能受到优化过程的严格控制。这种方式削弱了特征表示的随机性和多样性,这是基于隔离的异常评分方法所要求的。 - 随机表示和基于随即划分的隔离之间的协同作用
DIF采用了一种新的表示方案,即通过优化自由神经网络产生的随机表示集合。这些网络的参数可以通过从广泛使用的初始化分布(例如,正态或均匀分布)中随机采样来初始化,从而容易地产生一组具有良好随机性和多样性的特征表示。给定一组足够大的此类随机表示,我们可以在很大程度上提高随机数据分区中的隔离能力,从而有可能有效地隔离这些表示的某些子集上的一些真正困难的异常。
论文:H. Xu, G. Pang, Y. Wang and Y. Wang, “Deep Isolation Forest for Anomaly Detection,” in IEEE Transactions on Knowledge and Data Engineering, doi: 10.1109/TKDE.2023.3270293.


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









