






目录
插入排序
直接插入排序
每次将一个待排序的数据按照大小插入到前面已经排好序的适当位置,直到全部数据插入完成为止。(通俗的讲就是将所要排序的数,与前面已经排完序的元素进行比较),我们将数组下标为0的位置空出来进行储存待排序元素(称为哨兵),你也可以从下标0开始,只要定义一个变量储存就行
1.1、建立一个哨兵(即临时变量),把要插入的数据赋给它。
1.2、插入数据从后面开始比较,如果大于前面的就记录下标,并将数据后移,直到插入数据碰到比它小的。
1.3、将临时变量赋值给当前记录下标。
1.4、for循环即完成全部数据插入。
如下面的图所示 (按照数据的输入顺序,依次取出来与前面的进行比较,先拿出第一个2,一个有序,后面与2比较后存入.....)
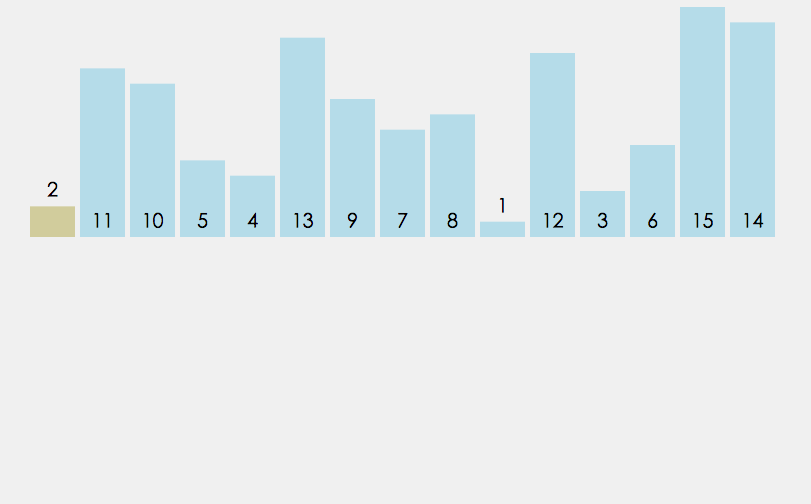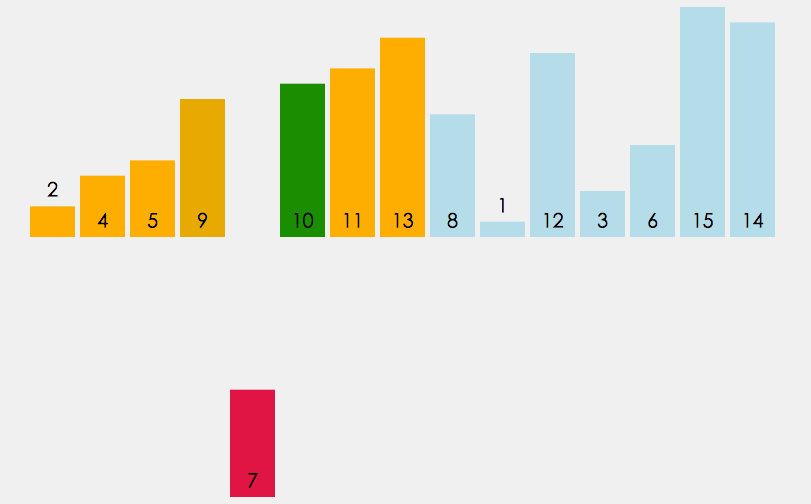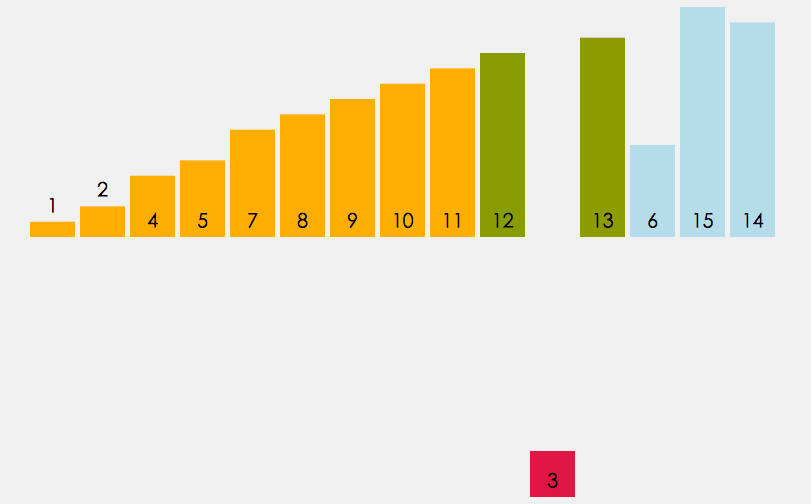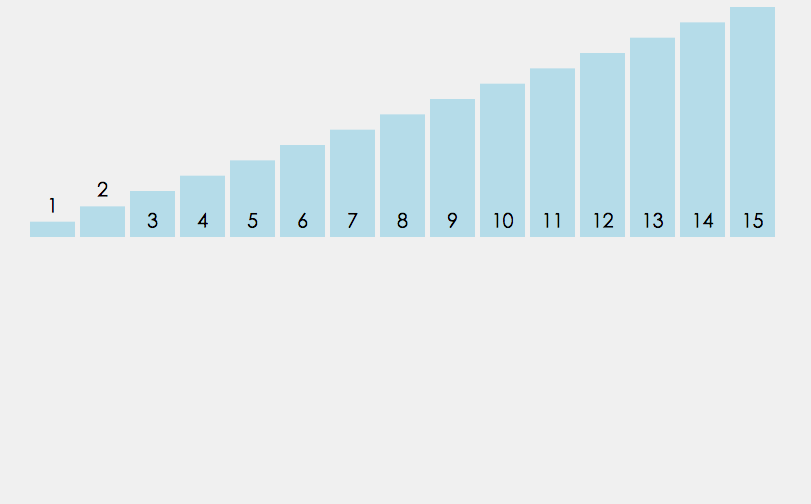
实现的功能代码如下:
void insertsort(int arr[],int n)
{
int j ;
for(int i = 2 ; i <= n ; i++) // 从第二个元素开始,因为第一个只有一个元素一定有序
{
arr[0] = arr[i];
j = i - 1; // 初始化为i- 1 的原因是 arr[i] 是待排元素 所以要从它前面的 数据中检索
while(arr[0] < a[j]) // 寻找比他小的位置
{
arr[j+1] = arr[j]; // 向后移动元素
j = j - 1; // 向前检索
}
arr[j+1] = arr[0];// 插入
}
} 希尔排序
百度官方给出的解释是:希尔排序是把记录按下标的一定增量分组,对每组使用直接插入排序算法排序;随着增量逐渐减少,每组包含的关键词越来越多,当增量减至 1 时,整个文件恰被分成一组,算法便终止。”
增量的确定方法是:d = n / 2 后面依次减半,最后为1的时候就和原来的插入排序差不多。
但我感觉不用那么麻烦,说到底他还是一个插入排序,只不过是在原来的插入排序的基础上,在元素之间加了距离,实际上还是待排元素和前面的元素进行比较,比它大我就进行交换:下面给出动态图片可以参考
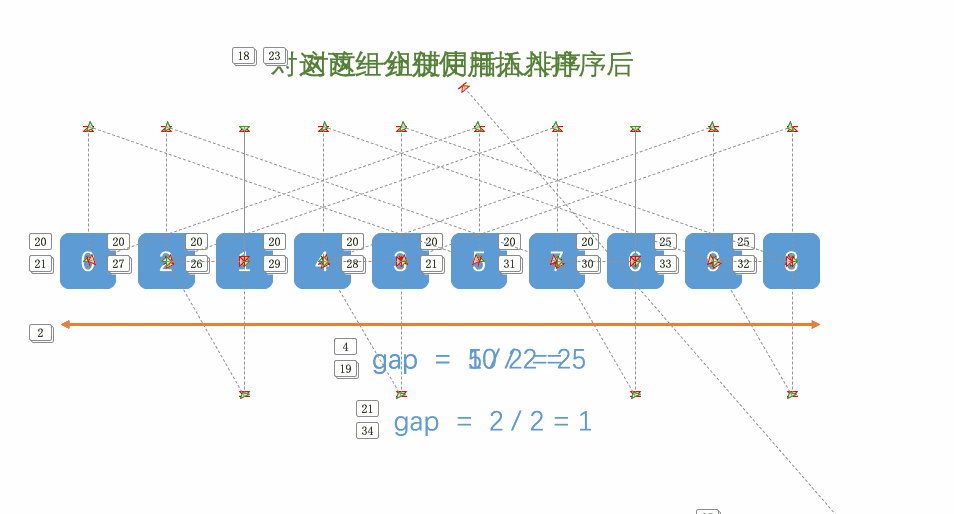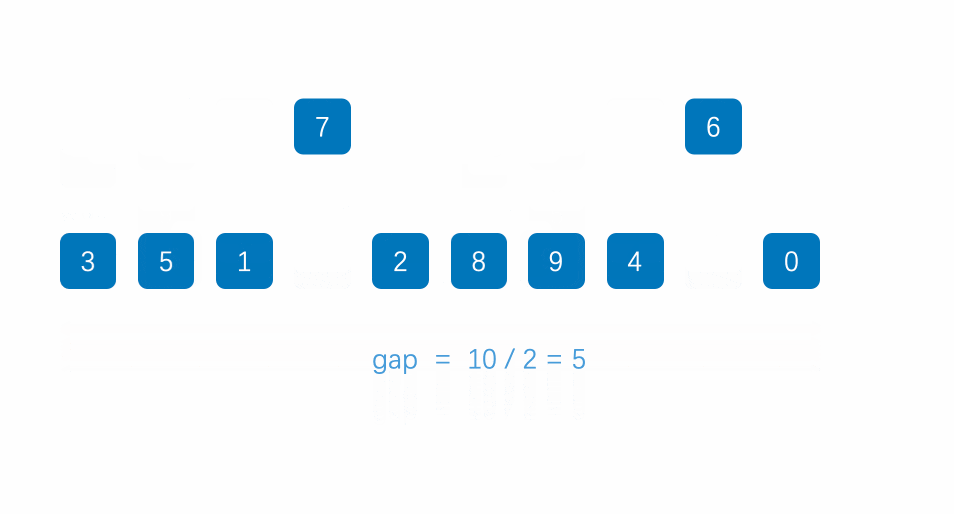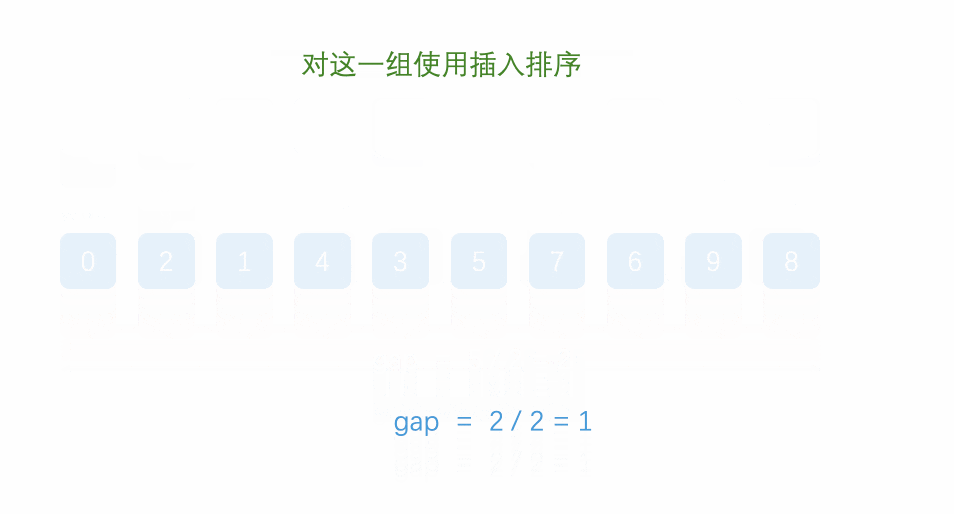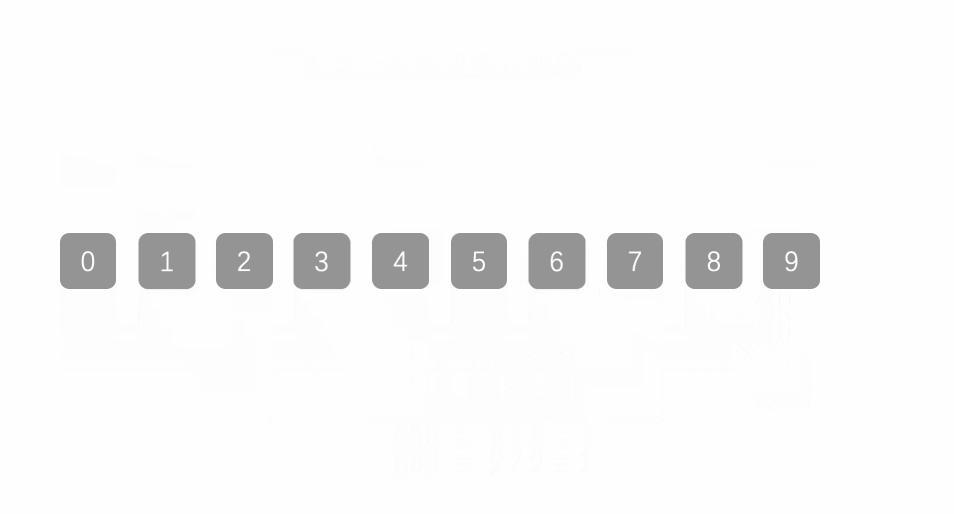
相信也许有同学们看这个动态图片没有看懂,小编为了不让我的粉丝烦恼呢 就手绘了一下这个排序方法 :
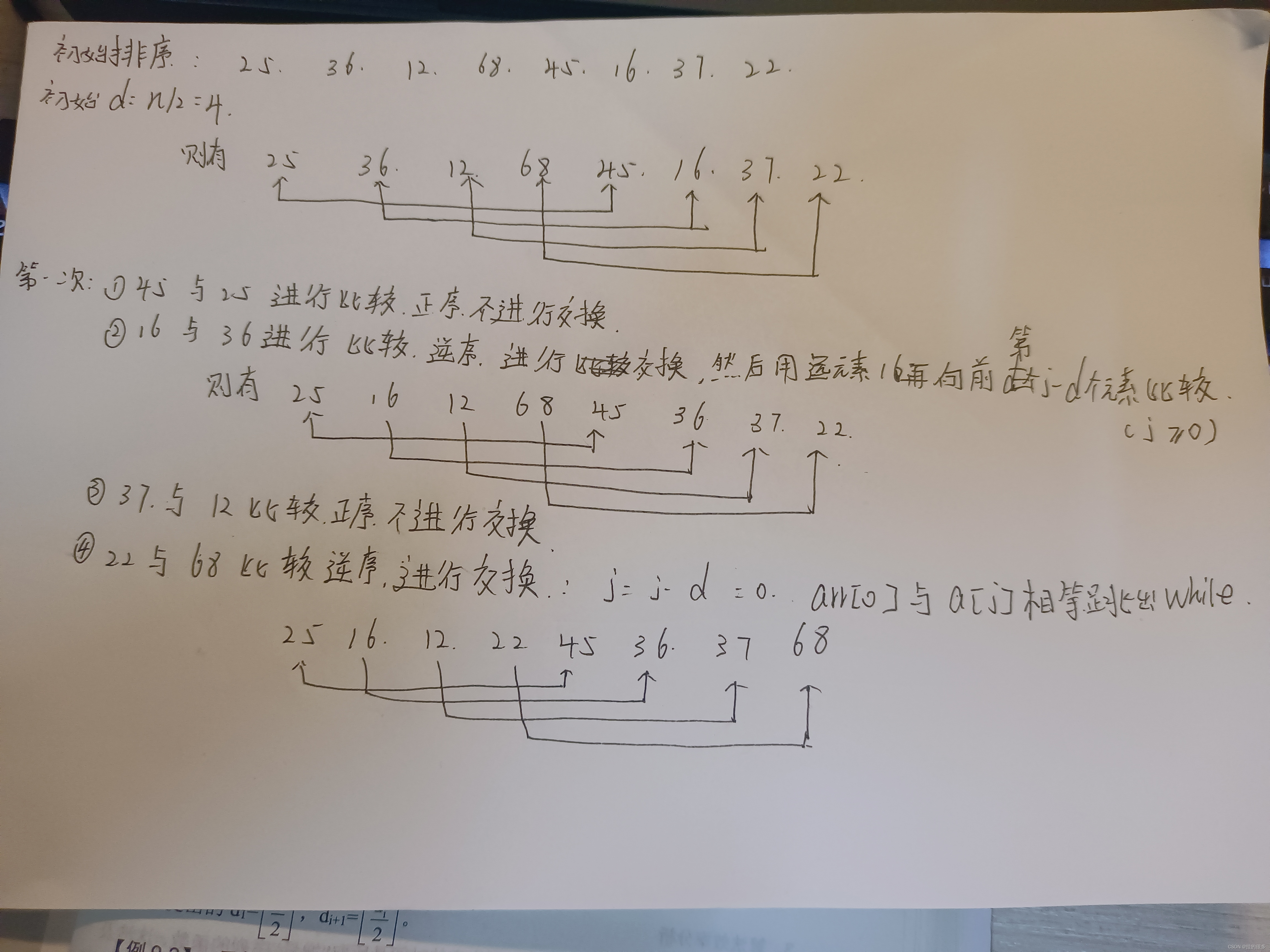
其实小编的的用词不是很准确 ,他其实并不是直接交换(实际上就是移动元素),而是将第j - d 个元素进行覆盖 第 j 个元素,在用arr[0](就是存储的排元素和前面间隔d的元素进行比较,满足条件再进行覆盖,再向前面检索。找不到后就将待排元素,覆盖最近的比它大的值的位置)
void insertsort(int arr[],int n)
{
int j , d;
d = n / 2;
while(d)
{
for(int i = d ; i <= n ; i++) // 从第d个元素开始,依次往后
{
arr[0] = arr[i]; // 记录待排元素
j = i - d; // 初始化为i- d 的原因是 arr[i] 是待排元素 所以要从它间隔d的 数据中检索
while( j >= 0 && arr[0] < a[j]) // 寻找比他小的位置 j >= 0 的原因是 j - d 的值必须大于0
{
arr[j+d] = arr[j]; // 向后覆盖元素
j = j - d; // 向前检索
}
arr[j+d] = arr[0];// 将待排元素放入
}
d /= 2;
}
} 交换排序
冒泡排序
官方解释:
冒泡排序算法的原理如下:
-
比较相邻的元素。如果第一个比第二个大,就交换他们两个。
-
对每一对相邻元素做同样的工作,从开始第一对到结尾的最后一对。在这一点,最后的元素应该会是最大的数。
-
针对所有的元素重复以上的步骤,除了最后一个。
-
持续每次对越来越少的元素重复上面的步骤,直到没有任何一对数字需要比较。
其实在小编看来呀,就是将两个元素进行比较将较大的元素往后丢,然后用这个较大的元素再往后进行比较,最后的肯定是最大的; 上图:
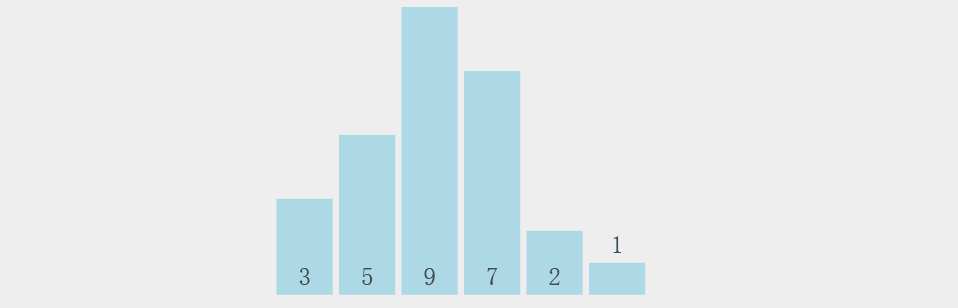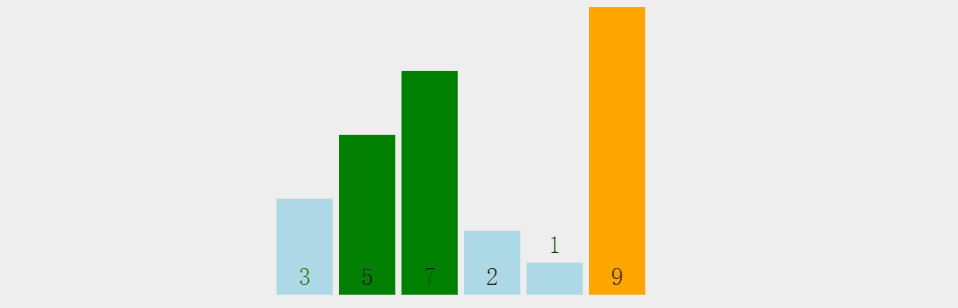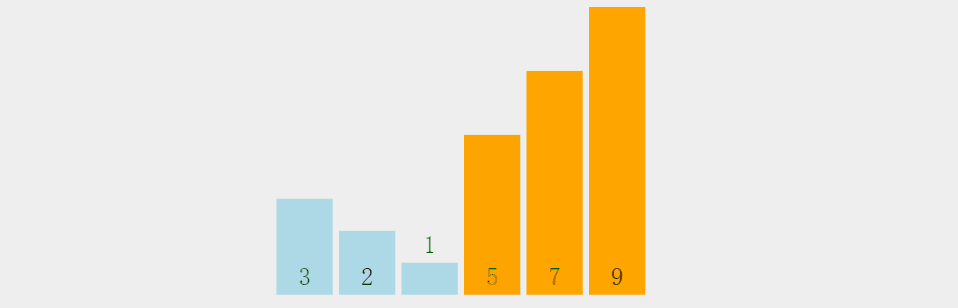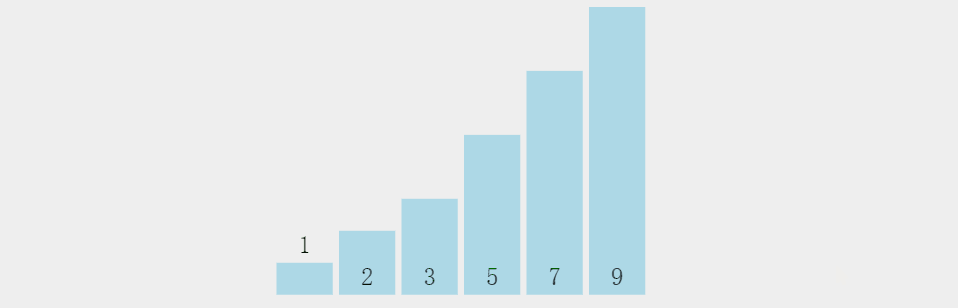
上代码:
void sort(int arr[], int n)
{
int t;
for(int i = 1 ; i <= n - 1 ; i++) // 控制循环次数,只需要n-1次就行了
{
for(int j = 1 ; j <= n - i ; j++) // 这里的 n - i 的意思是最后一个一定是最大的一个不用比较了,其实你写n也行
{
if(arr[j] > arr[j+1]) // 设置第三变量进行交换
{
t = arr[j+1];
arr[j+1] = arr[j];
arr[j] = t;
}
}
}
}快速排序
官方解释:
1)设置两个变量i、j,排序开始的时候:i=0,j=N-1;
2)以第一个数组元素作为关键数据,赋值给key,即key=A[0];
3)从j开始向前搜索,即由后开始向前搜索(j--),找到第一个小于key的值A[j],将A[j]和A[i]的值交换;
4)从i开始向后搜索,即由前开始向后搜索(i++),找到第一个大于key的A[i],将A[i]和A[j]的值交换;
5)重复第3、4步,直到i==j; (3,4步中,没找到符合条件的值,即3中A[j]不小于key,4中A[i]不大于key的时候改变j、i的值,使得j=j-1,i=i+1,直至找到为止。找到符合条件的值,进行交换的时候i, j指针位置不变。另外,i==j这一过程一定正好是i+或j-完成的时候,此时令循环结束)。
没看懂吧,欸,还得小编我来给你们缕一缕:简单的说就是选取一个参照物,将所有小于这个数的元素放在它的左边,将所有大于它的数放在右边,然后不断执行这个操作就可以实现,还有点懵,那小编只好动手给你们将例子了
用 19 97 9 17 1 8 给你举例吧,初始如图所示,通常以左侧的为基准,即19
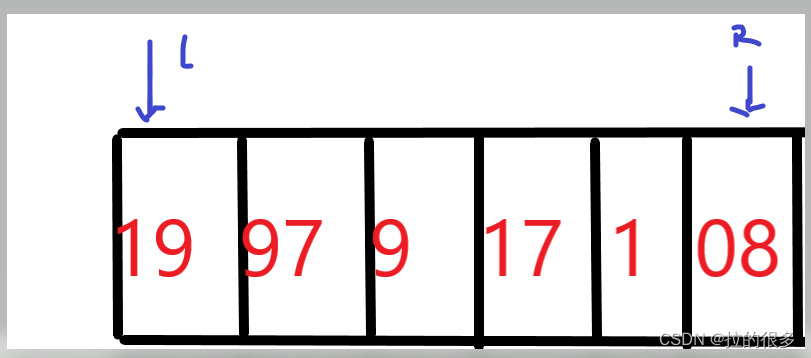
右侧的指针先向左检索(等一下解释为什么不是左侧的指针先动)检索到 8 < 19 将L指向的位置覆盖 如图
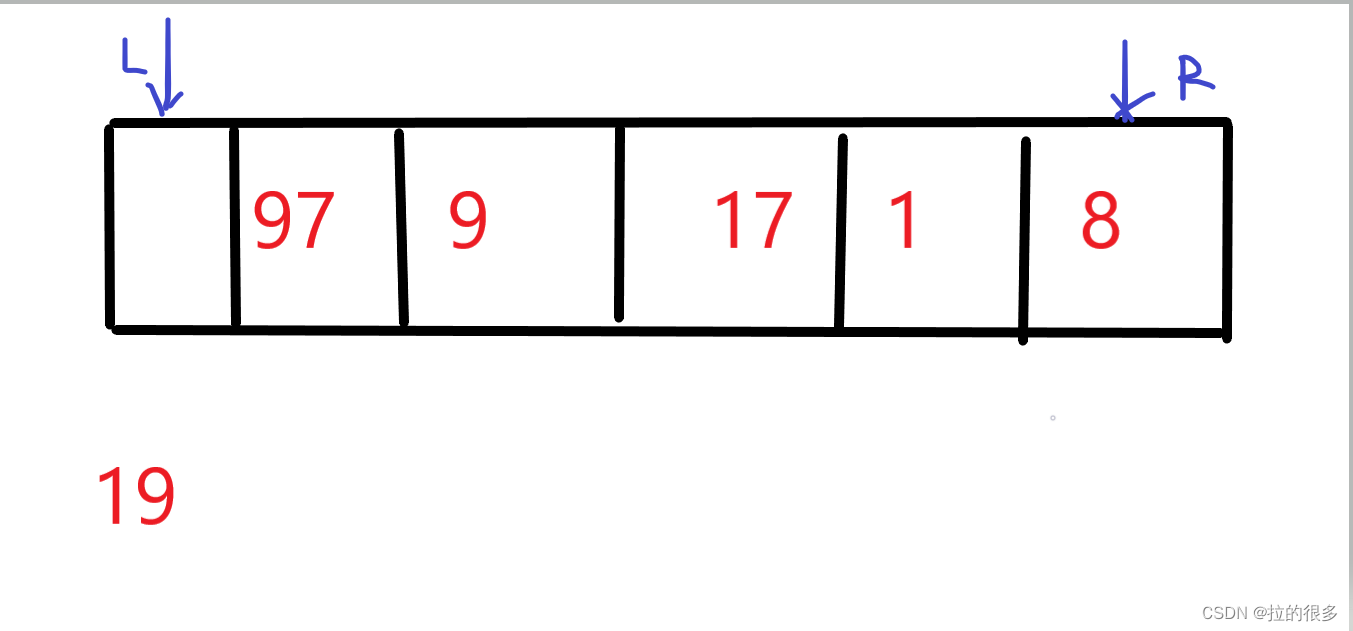
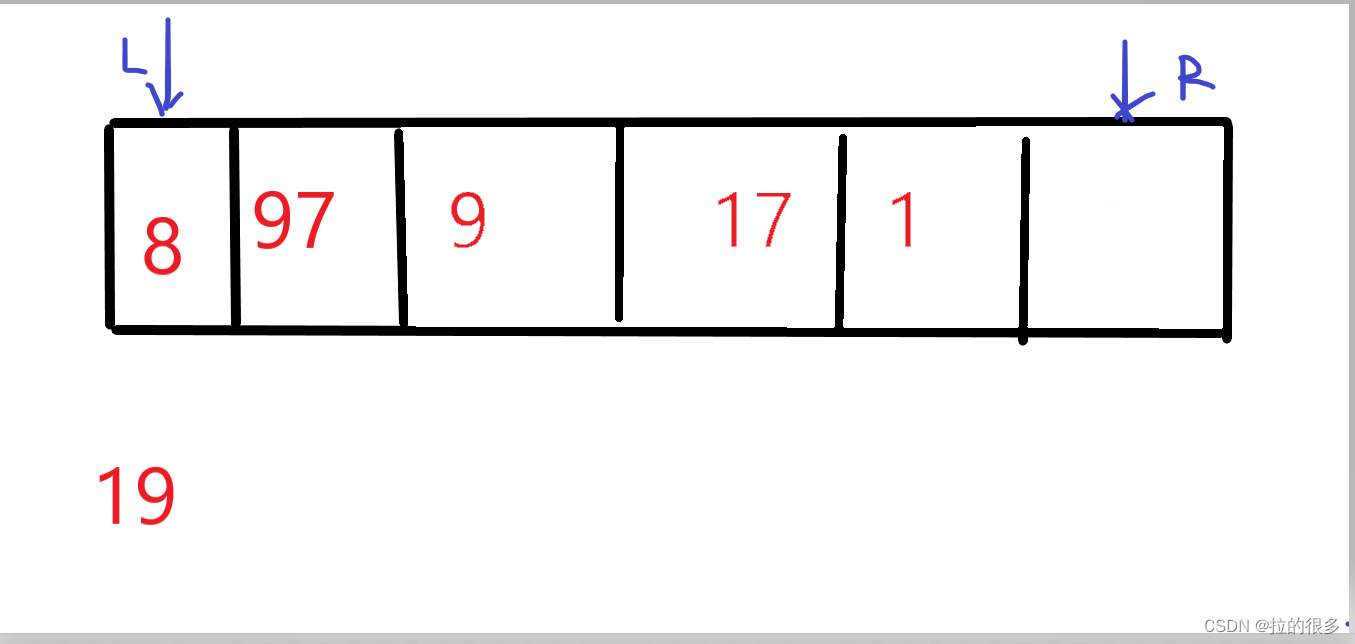
右侧已经检索了,现在开始检索从左向右 97 > 19 将R指向的位置覆盖 如图

左侧已经检索了,现在开始检索从右往左 1 < 19 将L指向的位置覆盖 ,如图
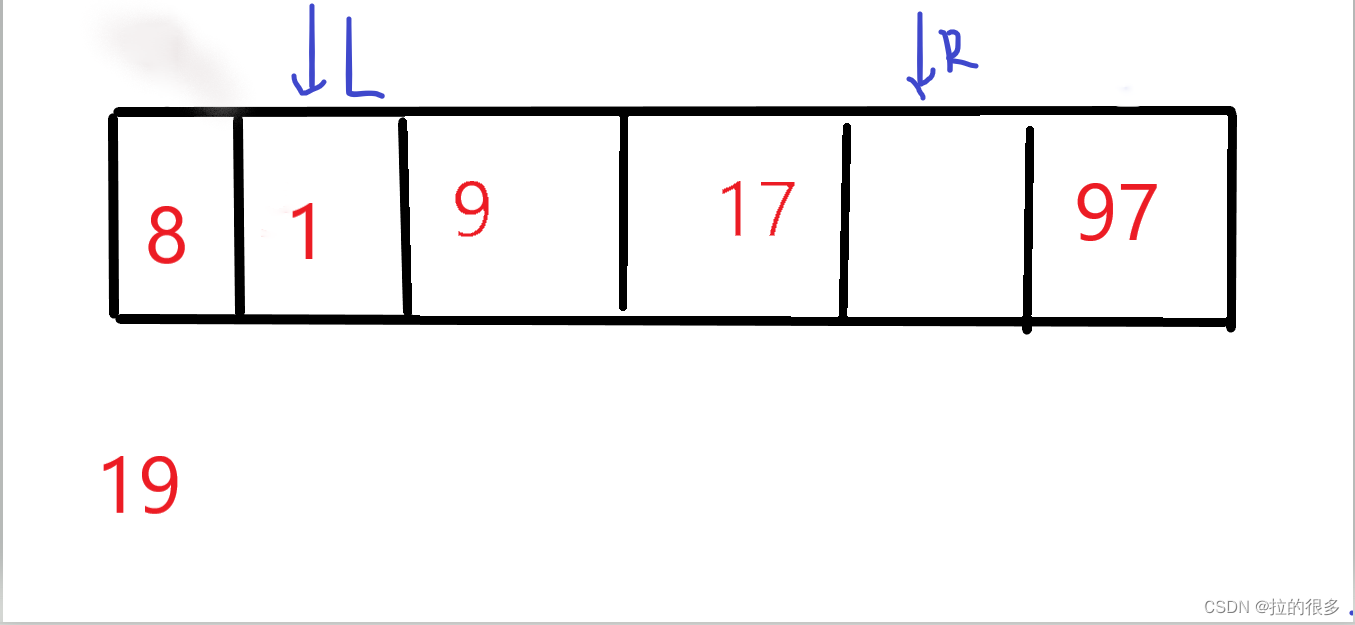
右侧已经检索了,现在开始检索从左向右9 < 19 ,L再向右移 17 < 19 右移 L和R指向的位置一样则将 19 填入 如图
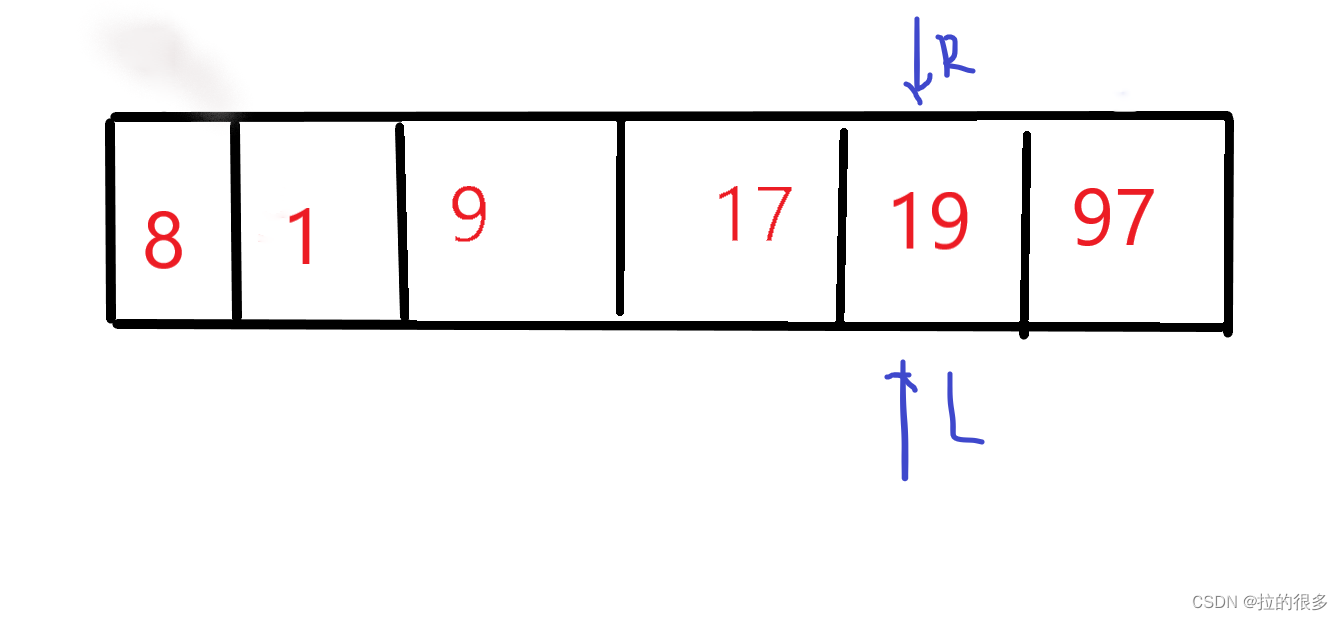
而后的操作就是再将19的左侧和右侧进行上面一样的操作,即采用递归
注意!注意!:确定左右指针那边先动
在贴入代码之前跟大家解释上面的问题,为什么在选取左侧的元素为基准时要先让右边的指针先进行检索呢,其实我讲个例子大家就会很好理解 :3 1 2 5 4 在L进行右移的时候,L会在5的位置停下,R也将在5的位置停下 得到一下序列 : 5 1 2 3 4 , 可以看到在3基准数的左侧有大于3的数就是5,所以进行遍历的顺序是不能颠倒。(因为小编是取左侧为基准,所以右侧先动,如果取右侧的话,左侧先动就行了)
上代码:
void qsort(int r[] , int L , int R)
{
int i , j;
i = L , j = R;
int flage = r[i]; // 确定基准
while(i < j)
{
while(i < j && r[j] >= flage)
j--;
r[i] = r[j]; // 进行覆盖
while( i < j && r[i] <= flage)
i++;
r[j] = r[i];
}
// 将基准填入i 和 j 指向的地方
r[i] = flage;
if(L < i - 1)qsort(r,L,i-1); // 判断是否为1个元素,如果是一个元素的话就不用排了
if(i + 1 < R) qsort(r,i+1,R);//上同
} 选择排序
堆排序
官方解释:
堆是一个近似完全二叉树的结构,并同时满足堆积的性质:即子结点的键值或索引总是小于(或者大于)它的父节点。
小编看来听起来简单但是实现这个代码是真的难呀(奋笔疾书),它可以利用大顶堆和小顶堆来实现。
大顶堆:每个父节点都会满足,parent > lson && parent > rson
小顶堆:每个父节点都会满足,parent < lson && parent < rson
但是为了然我的粉丝们少受痛苦呢,小编还是忍痛吃透了这个算法,接下来的理解采用大顶堆来为大家普及其实在我看来它的本质就是利用类似完全二叉树的性质(等一下小编会在下方答疑里面为大家解释类似体现在哪),让它整体上由大往下,可以知道最后根节点一定是最大的。
步骤:
-
最大堆调整(Max Heapify):将堆的末端子节点作调整,使得子节点永远小于父节点
-
创建最大堆(Build Max Heap):将堆中的所有数据重新排序
-
堆排序(HeapSort):移除位在第一个数据的根节点,并做最大堆调整的递归运算
其中实现创建堆和维持堆的状态的是难点,接下来会拆分进行讲解:
维持堆的状态
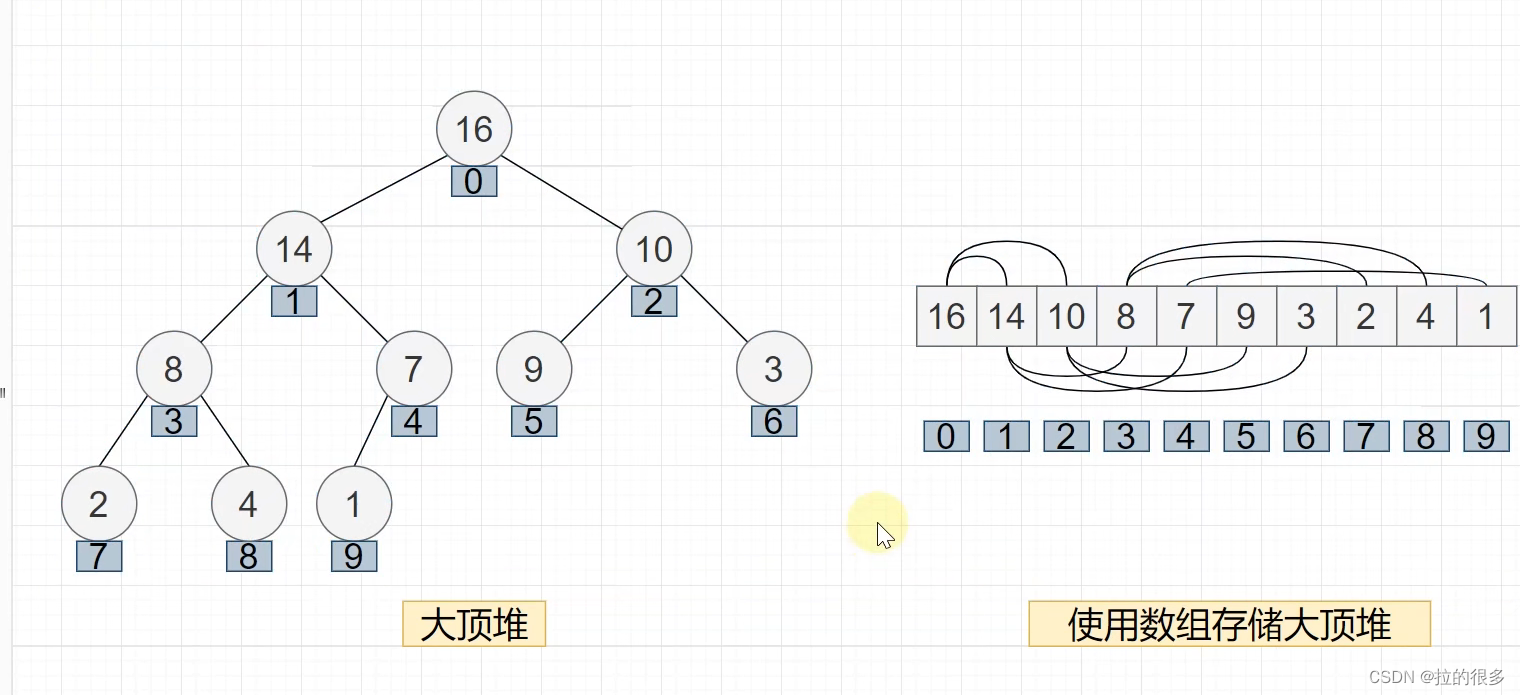
在上述中可以了解,堆的性质就是子节点始终小于(或大于)父节点,所以这里的维持堆的状态实际上就是始终保持父节点最大就行,在实现这个代码之前,我们必须了解到父节点和子节点之间的关系 父节点: k 左子节点 2 * k 右子节点 2 * k + 1 ,子节点的父节点为:i / 2 (数组小下标从1开始,从零开始的话加个1就行了,小编用的是下标从0开始) , 看下图(引用的b站的图片,侵权请联系删除)可以对着数组来理解一下。
实现代码:
void heapify(int arr[] , int n , int i) // 维护堆的状态
{
int lson = 2 * i + 1;
int rson = 2 * i + 2;
int max = i;// 父节点和儿子节点之间最大元素的数组下标
if(lson < n && arr[max] < arr[lson])
max = lson;
if(rson < n && arr[max] < arr[rson])
max = rson;
if(max != i ) // max的值改变,说明最大值不是i 进行交换
{
swap(arr[max],arr[i]);
heapify(arr, n , max);
}
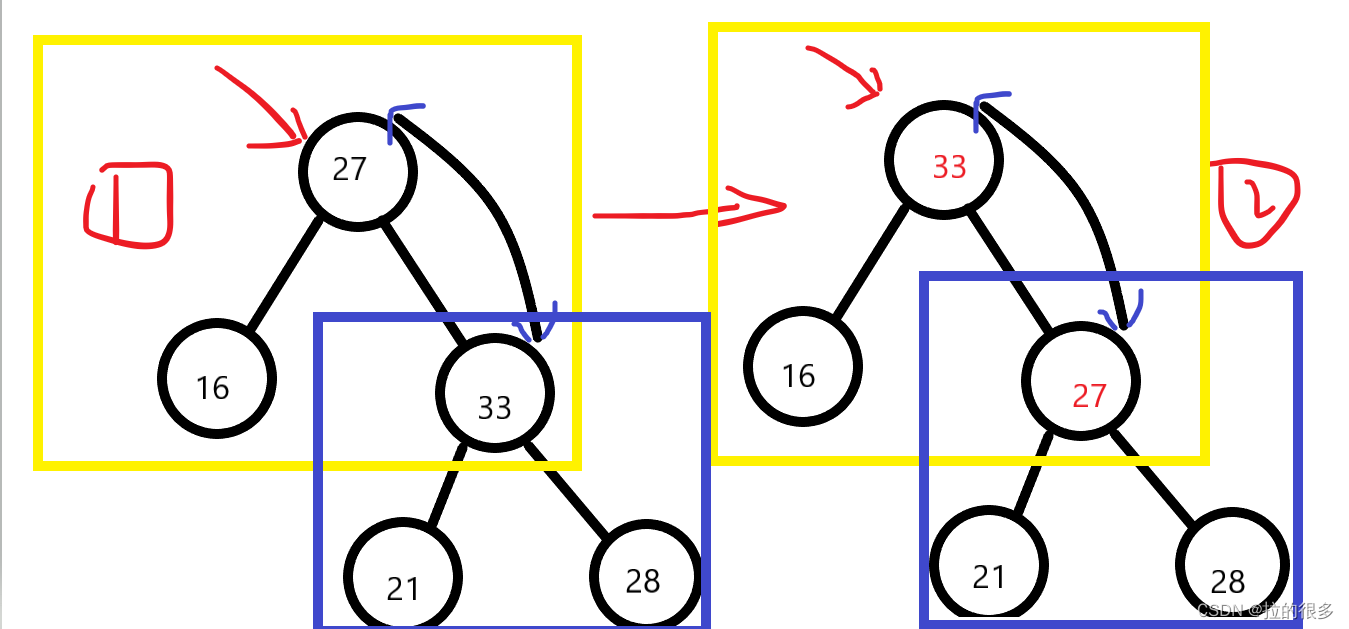
}给大家解释一下为什么下面还要对下标为max的元素进行状态维持:
可以看出在 27 和 33 进行交换的时候的时候(黄色框),下面的原本满足堆的性质的堆变得不满足(蓝色框),所以要对下面的也进行维持(此时的max指向的是②里面的27)
创建堆
不知道你有没有发现,上面的维持堆排序的代码会有一个局限性,那就是只能维持根的左子树的那部分,对根的右子树无法进行维持,所以有没有一种方法可以去解决这个问题,我们可以利用上面介绍的子节点的父节点为:i / 2 :去遍历堆里面的所有父节点 , i 指向的就是父节点
可以参考下面的图片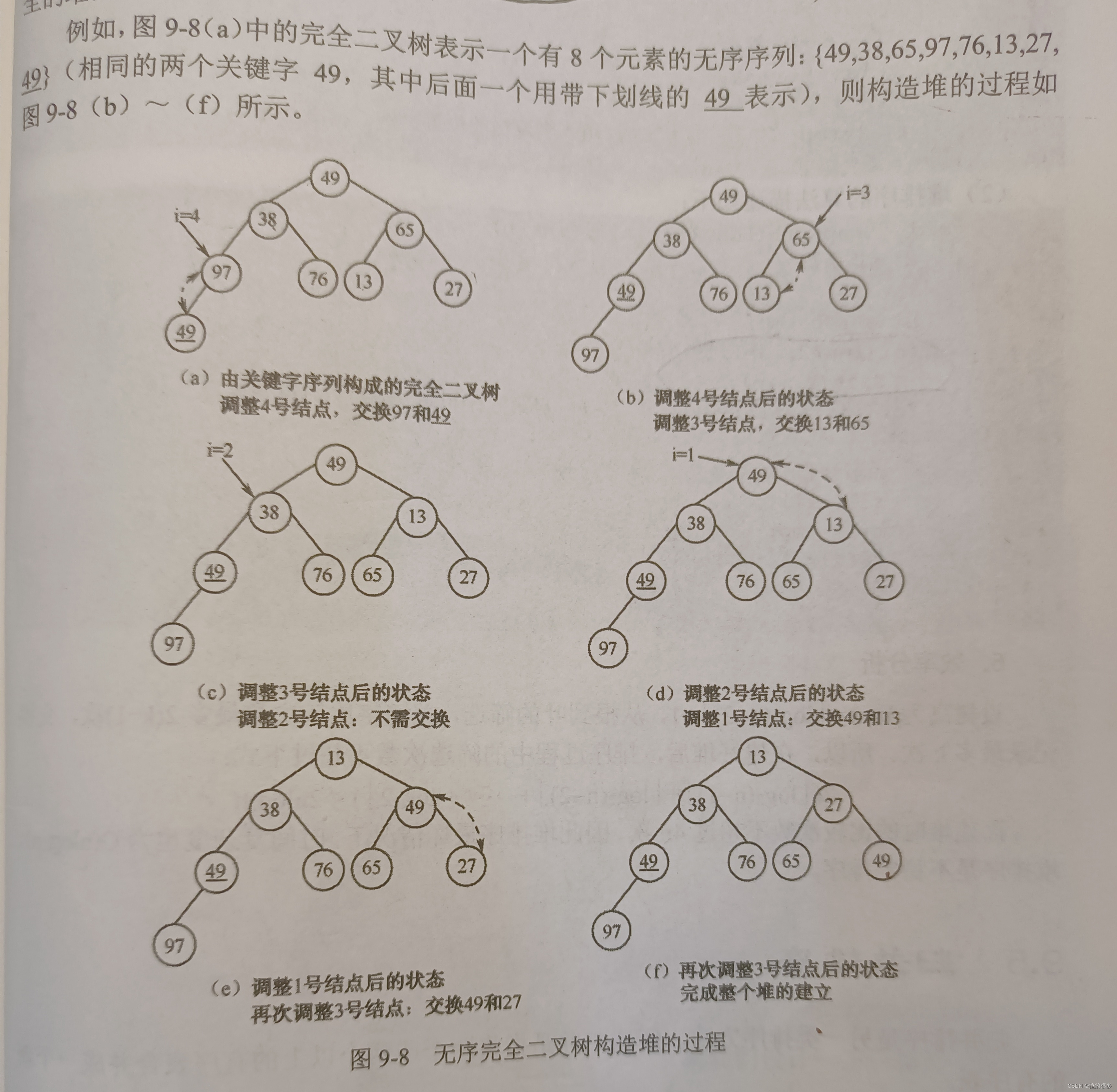
功能代码如下:
void build_heap(int arr[],int n)
{
int last_node = n - 1;// 最后的一个根节点
int parent = (last_node - 1) / 2;// 下标由0开始,求出最大的那个父节点
for(int i = parent ; i >= 0 ; i--)// 从下向上进行不断的维护堆
{
heapify(arr,n, i);
}
}有序输出
根据上面的描述可以知道根是最大的数值,我们可以让根节点和最靠右边的叶子节点进行交换(为什么是最右边的,因为你要满足完全二叉树的性质,只能右侧具有空缺)后面截取将这个叶子节点进行减除(取出),老规矩上图: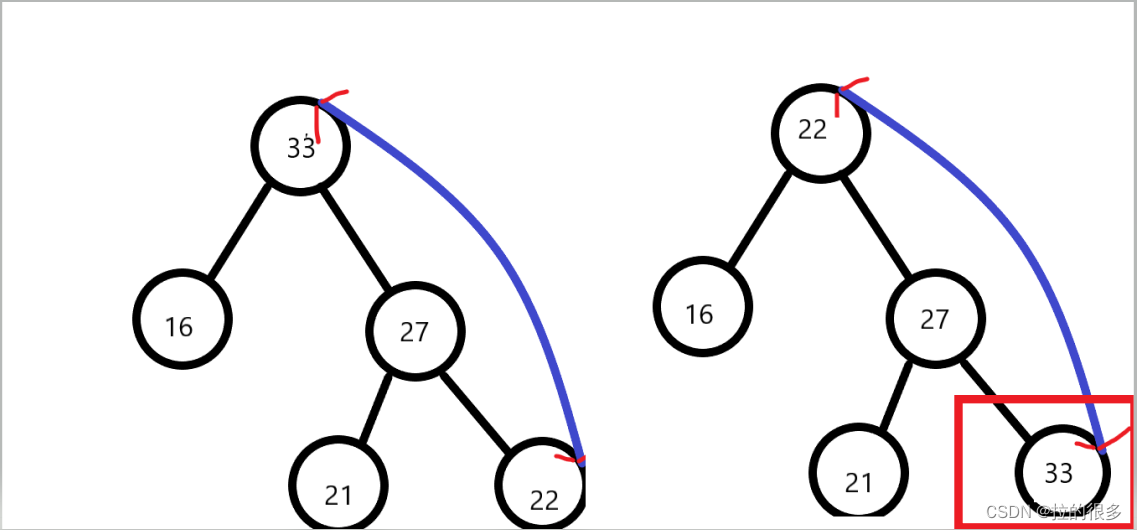
以这个图为例,33 和 22 进行交换后将 33进行截取 ,这个截取代码不用单独编写删除函数,等同于元素的个数进行减一就行
void heapsort(int arr[],int n)
{
build_heap(arr,n);
for(int i = n - 1 ; i>= 0 ; i--){// 遍历所有的叶子节点 ,为输出做准备
swap(arr[i],arr[0]);// 不断用最后一个和第一个数进行交换
heapify(arr,i,0); // 不断的由顶向下进行堆维护
// 传入 i 的原因是因为,i的值就是不断减小,等同于元素截取(截取后它的父节点就相当于没有子节点)
}
}实现了这几个步骤后就可以贴入完整代码了:
#include<iostream>
#include<algorithm>
using namespace std;
void heapify(int arr[] , int n , int i) // 维护堆的状态
{
int lson = 2 * i + 1;
int rson = 2 * i + 2;
int max = i;// 父节点和儿子节点之间最大元素的数组下标
if(lson < n && arr[max] < arr[lson])
max = lson;
if(rson < n && arr[max] < arr[rson])
max = rson;
if(max != i ) // max的值改变,说明最大值不是i 进行交换
{
swap(arr[max],arr[i]);
heapify(arr, n , max);
}
}
void build_heap(int arr[],int n)
{
int last_node = n - 1;// 最后的一个根节点
int parent = (last_node - 1) / 2;// 下标由0开始,求出最大的那个父节点
for(int i = parent ; i >= 0 ; i--)// 从下向上进行不断的维护堆
{
heapify(arr,n, i);
}
}
void heapsort(int arr[],int n)
{
build_heap(arr,n);
for(int i = n - 1 ; i>= 0 ; i--){// 遍历所有的叶子节点 ,为输出做准备
swap(arr[i],arr[0]);
heapify(arr,i,0); // 不断用最后一个和第一个数进行交换
// 传入 i 的原因是因为,i的值就是不断减小,等同于元素截取(截取后它的父节点就相当于没有子节点)
}
}
int main()
{
int arr[] = {2,5 , 3 , 1, 10 , 4};
heapsort(arr,6);
for(int i = 0 ; i < 6 ; i++)
{
cout << arr[i]<<endl;
}
return 0;
} 答疑
大家肯定会想为什么只要满足父节点大于子节点就行了,两个子节点之间为什么不用进行比较,其是大家会发现,上面提到,堆只是和完全二叉树的性质相似,它不需要满足左节点大于右节点,大家也不必要纠结用大顶堆还是小顶堆,它两其实差不多,改一下heapify里面的比较语句,找出三者中最小就可以了。
归并排序
官方解释:
归并排序是建立在归并操作上的一种有效,稳定的排序算法,该算法是采用分治法(Divide and Conquer)的一个非常典型的应用。将已有序的子序列合并,得到完全有序的序列;即先使每个子序列有序,再使子序列段间有序。若将两个有序表合并成一个有序表,称为二路归并。
这个在小编看来,这个就是将一个总问题不断拆分成小问题,直到不能再拆分,这个就是分治思想,然后实现这个思想的方法就是递归方法,所以本质上就是分治+递归,所以可以得出以下步骤
第一步:不断进行对半拆分,直到只有一个元素
第二步:设定两个指针,最初位置分别为两个已经排序序列的起始位置
第三步:比较两个指针所指向的元素,选择相对小的元素放入到合并空间,并移动指针到下一位置
重复步骤3直到某一指针超出序列尾
将另一序列剩下的所有元素直接复制到合并序列尾
这样说也许会有点晕,我们可以看下图对着理解一下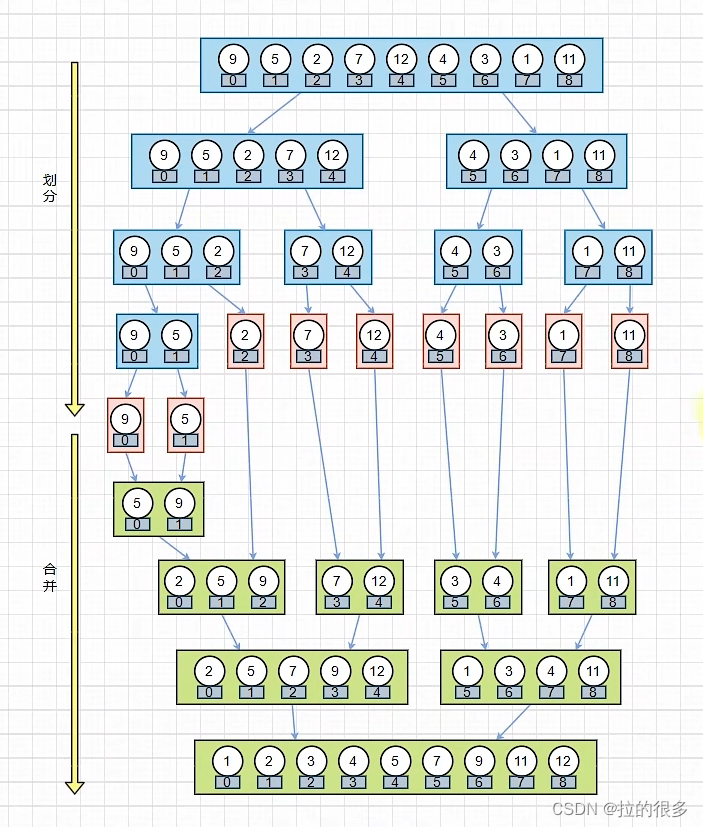
所以我将从两个方面进行讲解;
在此之前我们需要一个临时的数组进行存储,变化过后的数据,即合并过程的数据,所以我们只要开辟一个临时空间就行(c++里面使用new,C语言里面用的是malloc)
void mersort(int arr[],int low,int high,int n)
{
int *temparr = new int[n];
msort(arr,temparr,low,high);
//释放数组
delete [] temparr;
}合并
我们将两个子序列里面的元素不断进行比较,将较小的那个放入临时数组里面 ,直到一个序列里面的元素为空,后面再将子序列剩余的部分直接复制到临时数组的后面就行了(如果没有看懂代码可以结合上面的图理解)
void merge(int arr[], int temparr[],int low,int mid,int high)
{
//标记左侧的第一个元素
int l_pose = low;
//标记右侧的第一个元素
int r_pose = mid+1;
//合并
int left = low;
while(l_pose <= mid && r_pose <= high)
{
if(arr[l_pose] < arr[r_pose])
temparr[left++] = arr[l_pose++];
else
temparr[left++] = arr[r_pose++];
}
//左侧剩余
while(l_pose <= mid) temparr[left++] = arr[l_pose++];
//右侧剩余
while(r_pose <= high) temparr[left++] = arr[r_pose++];
//将元素复制回原数组
while(low <= high)
{
arr[low] = temparr[low];
low++;
}
}拆分
这个因为是不断的执行一个重复的步骤:不断进行对半拆分。满足递归的性质,所以我们这题将会用递归来实现拆分:
void msort(int arr[],int temparr[],int low,int high)
{
if(low == high) return ;
else
{
int mid = (low + high) / 2;
msort(arr,temparr,low,mid);
msort(arr,temparr,mid+1,high);
merge(arr, temparr,low, mid,high);
}
}相信有些同学对这个递归的过程并不是很理解,小编提供一个方法就是,将它的调用过程用栈的形式进行画出来,这样你就能理解它执行到了那一步,如果单单看的话,也许会不好理解
完整代码
#include<iostream>
using namespace std;
const int maxn = 100;
// 合并
void merge(int arr[], int temparr[],int low,int mid,int high)
{
//标记左侧的第一个元素
int l_pose = low;
//标记右侧的第一个元素
int r_pose = mid+1;
//合并
int left = low;
while(l_pose <= mid && r_pose <= high)
{
if(arr[l_pose] < arr[r_pose])
temparr[left++] = arr[l_pose++];
else
temparr[left++] = arr[r_pose++];
}
//左侧剩余
while(l_pose <= mid) temparr[left++] = arr[l_pose++];
//右侧剩余
while(r_pose <= high) temparr[left++] = arr[r_pose++];
//将元素复制回原数组
while(low <= high)
{
arr[low] = temparr[low];
low++;
}
}
// 分解成单个元素的区间
void msort(int arr[],int temparr[],int low,int high)
{
if(low == high) return ;
else
{
int mid = (low + high) / 2;
msort(arr,temparr,low,mid);
msort(arr,temparr,mid+1,high);
merge(arr, temparr,low, mid,high);
}
}
void mersort(int arr[],int low,int high,int n)
{
int *temparr = new int[n];
msort(arr,temparr,low,high);
//释放数组
delete [] temparr;
}
int main()
{
int arr[maxn];
int n;
cout << "请输入数据个数:" << endl;
cin >> n;
cout << "请输入:"<<endl;
for(int i = 0 ; i < n ; i++)
cin >> arr[i];
mersort(arr,0,n-1,n);
for(int i = 0 ; i < n ; i++)
{
cout << arr[i] << " ";
}
return 0;
}关于排序的算法,已经基本讲解完毕了,如果有同学感兴趣的可以去看看桶排序,基数排序,折半排序,没看懂的可以给我留言,我会补充一下,恭喜大家在今天充实了自己,一起加油,最后希望大家快乐的学习算法。欢迎点评。















 148
148











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









