




 本文介绍了通过rotational、iostat和top命令检查磁盘类型、利用率及CPU使用情况的方法。并详细解释了不同磁盘调度算法如NOOP、CFQ、DEADLINE和ANTICIPATORY的特点及其适用场景。
本文介绍了通过rotational、iostat和top命令检查磁盘类型、利用率及CPU使用情况的方法。并详细解释了不同磁盘调度算法如NOOP、CFQ、DEADLINE和ANTICIPATORY的特点及其适用场景。
该文章非原创内容摘自不同博客,仅作个人笔记用,博客地址见引用部分
利用rotational 查看磁盘类型以及调度方式
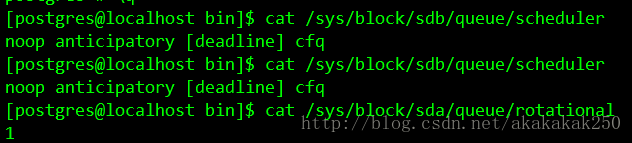
前两行查看磁盘调度方式:
当前方式为cfg,调度方式见底部引用
最后一行查看磁盘类型:
返回值0即为SSD,
返回1即为HDD。
利用iostat查看磁盘利用率

rrqm/s:每秒合并读操作的次数,针对相邻的数据块
wrqm/s:每秒合并写操作的次数,同上。
r/s:每秒读操作的次数
w/s:每秒写操作的次数
rkB/s:每秒读取多少kb,rMB:每秒读多少MB
wkB/s:每秒写入多少kb,wMB:每秒写多少MB
avgrq-sz:每个I/O的平均扇区数
avgqu-sz:平均I/O队列长度。
await:每个I/O平均所需的等待时间,包括IO时间和等待时间。
r_await:每个读操作平均所需的时间,包括IO时间和等待时间。
w_await:每个写操作平均所需的时间,包括IO时间和等待时间。
%util:该硬盘设备的繁忙比率。(见磁盘介绍)利用top查看cpu利用率

第三行
Cpu(s):表示这一行显示CPU总体信息
%us:用户态进程占用CPU时间百分比,不包含renice值为负的任务占用的CPU的时间。
%sy:内核占用CPU时间百分比
%ni:改变过优先级的进程占用CPU的百分比
%id:空闲CPU时间百分比
%wa:等待I/O的CPU时间百分比
%hi:CPU硬中断时间百分比
%st:虚拟机占用百分比第四行
Men:内存的意思
total:物理内存总量
used:使用的物理内存量
free:空闲的物理内存量
buffers:用作内核缓存的物理内存量
第五行
Swap:交换空间
total:交换区总量
used:使用的交换区量
free:空闲的交换区量
cached:缓冲交换区总量
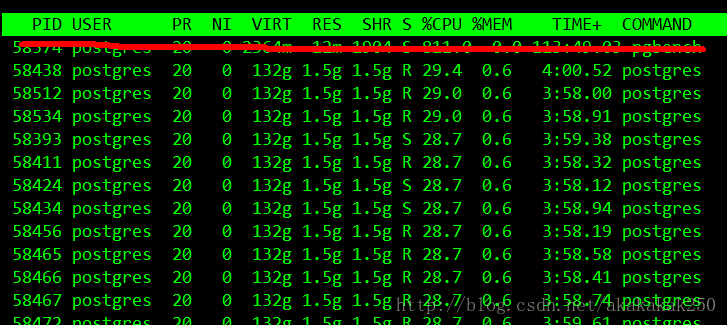
进程信息
再下面就是进程信息: PID:进程的ID
USER:进程所有者
PR:进程的优先级别,越小越优先被执行
NInice:值
VIRT:进程占用的虚拟内存
RES:进程占用的物理内存
SHR:进程使用的共享内存
%CPU:进程占用CPU的使用率
%MEM:进程使用的物理内存和总内存的百分比 TIME+:该进程启动后占用的总的CPU时间,即占用CPU使用时间的累加值。
COMMAND:进程启动命令名称
调度算法的不同
**NOOP算法**的全写为No Operation。
该算法实现了最最简单的FIFO队列,所有IO请求大致按照先来后到的顺序进行操作。之所以说“大致”,原因是NOOP在FIFO的基础上还做了相邻IO请求的合并,并不是完完全全按照先进先出的规则满足IO请求。NOOP假定I/O请求由驱动程序或者设备做了优化或者重排了顺序(就像一个智能控制器完成的工作那样)。在有些SAN环境下,这个选择可能是最好选择。Noop 对于 IO 不那么操心,对所有的 IO请求都用 FIFO 队列形式处理,默认认为 IO 不会存在性能问题。这也使得 CPU 也不用那么操心。当然,对于复杂一点的应用类型,使用这个调度器,用户自己就会非常操心。
NOOP对于闪存设备,RAM,嵌入式系统是最好的选择.
CFQ和DEADLINE考虑的焦点在于满足零散IO请求上。
对于连续的IO请求,比如顺序读,并没有做优化。为了满足随机IO和顺序IO混合的场景,Linux还支持ANTICIPATORY调度算法。ANTICIPATORY的在DEADLINE的基础上,为每个读IO都设置了6ms 的等待时间窗口。如果在这6ms内OS收到了相邻位置的读IO请求,就可以立即满足 Anticipatory scheduler(as) 曾经一度是 Linux 2.6 Kernel 的 IO scheduler 。Anticipatory 的中文含义是”预料的, 预想的”, 这个词的确揭示了这个算法的特点,简单的说,有个 IO 发生的时候,如果又有进程请求 IO 操作,则将产生一个默认的 6 毫秒猜测时间,猜测下一个 进程请求 IO 是要干什么的。这对于随即读取会造成比较大的延时,对数据库应用很糟糕,而对于 Web Server 等则会表现的不错。这个算法也可以简单理解为面向低速磁盘的,因为那个”猜测”实际上的目的是为了减少磁头移动时间。
DEADLINE在CFQ的基础上,解决了IO请求饿死的极端情况。除了CFQ本身具有的IO排序队列之外,DEADLINE额外分别为读IO和写IO提供了FIFO队列。读FIFO队列的最大等待时间为500ms,写FIFO队列的最大等待时间为5s。FIFO队列内的IO请求优先级要比CFQ队列中的高,,而读FIFO队列的优先级又比写FIFO队列的优先级高。
优先级可以表示如下:
FIFO(Read) > FIFO(Write) > CFQ
deadline 算法保证对于既定的 IO 请求以最小的延迟时间,从这一点理解,对于 DSS 应用应该会是很适合的。
CFQ算法的全写为Completely Fair Queuing。该算法的特点是按照IO请求的地址进行排序,而不是按照先来后到的顺序来进行响应。
在传统的SAS盘上,磁盘寻道花去了绝大多数的IO响应时间。CFQ的出发点是对IO地址进行排序,以尽量少的磁盘旋转次数来满足尽可能多的IO请求。在CFQ算法下,SAS盘的吞吐量大大提高了。但是相比于NOOP的缺点是:先来的IO请求并不一定能被满足,可能会出现饿死的情况。
Completely Fair Queuing (cfq, 完全公平队列) 在 2.6.18 取代了 Anticipatory scheduler 成为 Linux Kernel 默认的 IO scheduler 。cfq 对每个进程维护一个 IO 队列,各个进程发来的 IO 请求会被 cfq 以轮循方式处理。也就是对每一个 IO 请求都是公平的。这使得 cfq 很适合离散读的应用(eg: OLTP DB)。我所知道的企业级 Linux 发行版中,SuSE Linux 好像是最先默认用 cfq 的. 磁盘介绍
%util与硬盘设备饱和度
%util表示该设备有I/O(即非空闲)的时间比率,不考虑I/O有多少,只考虑有没有。由于现代硬盘设备都有并行处理多个I/O请求的能力,所以%util即使达到100%也不意味着设备饱和了。举个简化的例子:某硬盘处理单个I/O需要0.1秒,有能力同时处理10个I/O请求,那么当10个I/O请求依次顺序提交的时候,需要1秒才能全部完成,在1秒的采样周期里%util达到100%;而如果10个I/O请求一次性提交的话,0.1秒就全部完成,在1秒的采样周期里%util只有10%。可见,即使%util高达100%,硬盘也仍然有可能还有余力处理更多的I/O请求,即没有达到饱和状态。那么iostat(1)有没有哪个指标可以衡量硬盘设备的饱和程度呢?很遗憾,没有await多大才算有问题
await是单个I/O所消耗的时间,包括硬盘设备处理I/O的时间和I/O请求在kernel队列中等待的时间,正常情况下队列等待时间可以忽略不计,姑且把await当作衡量硬盘速度的指标吧,那么多大算是正常呢?
对于SSD,从0.0x毫秒到1.x毫秒不等,具体看产品手册;
对于机械硬盘,可以参考以下文档中的计算方法:
http://cseweb.ucsd.edu/classes/wi01/cse102/sol2.pdf
在实践中,要根据应用场景来判断await是否正常,如果I/O模式很随机、I/O负载比较高,会导致磁头乱跑,寻道时间长,那么相应地await要估算得大一些;如果I/O模式是顺序读写,只有单一进程产生I/O负载,那么寻道时间和旋转延迟都可以忽略不计,主要考虑传输时间,相应地await就应该很小,甚至不到1毫秒。在以下实例中,await是7.50毫秒,似乎并不大,但考虑到这是一个dd测试,属于顺序读操作,而且只有单一任务在该硬盘上,这里的await应该不到1毫秒才算正常:
文章出处: http://linuxperf.com/?p=156

















 317
317

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









