






初次接触AI与化学结合的赛道, 并且第一次接触机器学习和深度学习之类的内容,因此本篇笔记更多是对自己所了解的内容的记录与总结。
Task 1: 初次接触并学习baseline
1. baseline代码解析:
导入库:
1.pickle:用于序列化和反序列化对象,如保存和加载模型。
2.pandas:用于数据处理和分析,构建数据集。
3.tqdm:用于在循环中添加进度条,提高代码的可读性和用户体验。
4.sklearn.ensemble.RandomForestRegressor:用于构建随机森林回归模型,这是一种集成学习方法,用于预测连续值,5.rdkit.chem:用于处理化学结构数据,特别是分子的化学属性。
6.rdkit:RDKIT库本身,用于化学信息学和药物发现。
7.numpy:用于执行高效的数值计算。
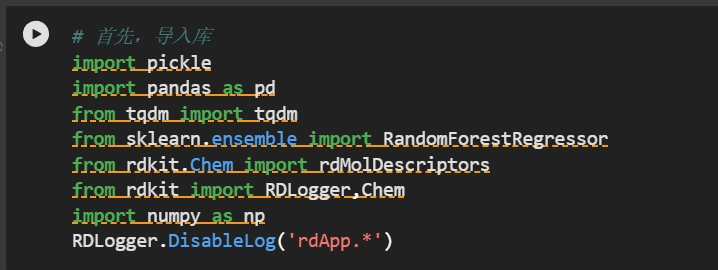
2. 特型提取:
官方发布的数据是对化学分子的SMILES表达式,具体来说,有rxnid,Reactant1,Reactant2,Product,Additive,Solvent,Yield字段。其中:
- rxnid 对数据的id标识,无实际意义
- Reactant1 反应物1
- Reactant2 反应物2
- Product 产物
- Additive 添加剂(包括催化剂catalyst等辅助反应物合成但是不对产物贡献原子的部分)
- Solvent 溶剂
- Yield 产率 其中Reactant1,Reactant2,Product,Additive,Solvent都是由SMILES表示。
(SMILES,全称是Simplified Molecular Input Line Entry System,是一种将化学分子用ASCII字符表示的方法,是化学信息学领域非常重要的工具。)
由于Reactant1,Reactant2,Product,Additive,Solvent都是由SMILES表示。所以,可以使用rdkit工具直接提取SMILES的分子指纹(向量),作为特征。
Morgan fingerprint :
位向量(bit ector)形式的特征,即由0,1组成的向量。
RDKit :
化学信息学中主要的工具,开源。网址:http://www.rdkit.org,支持WIN\MAC\Linux,可以被python、Java、C调用。几乎所有的与化学信息学相关的内容都可以在上面找到。
代码解析 :
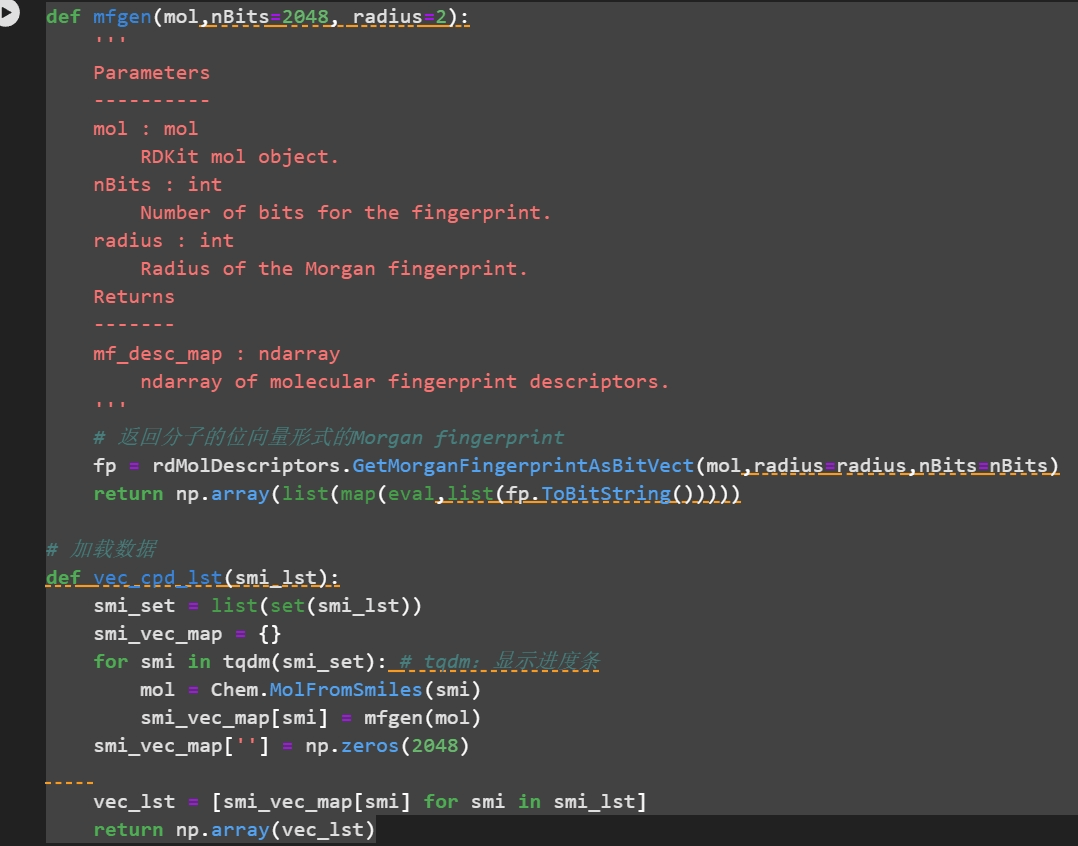
这段代码定义了两个函数, mfgen 和 vec_cpd 1st,用于生成分子的 Morgan 指纹,并将这些指纹转换为向量形式,以便于计算机处理和分析。
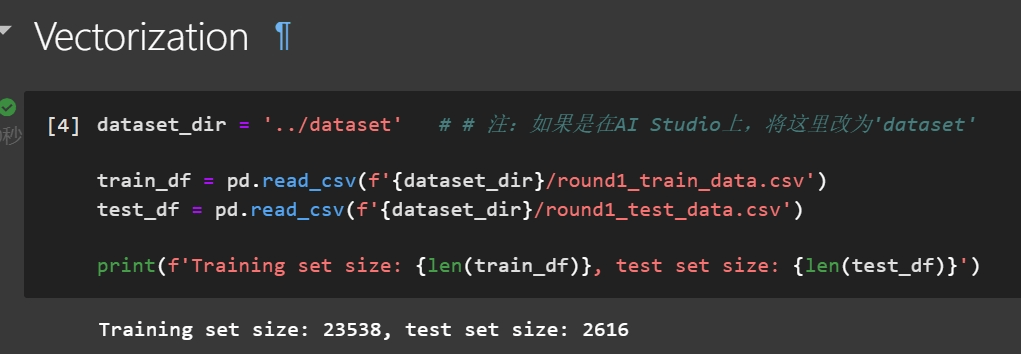
读取数据 (dataset_dir路径不同在线平台不同)
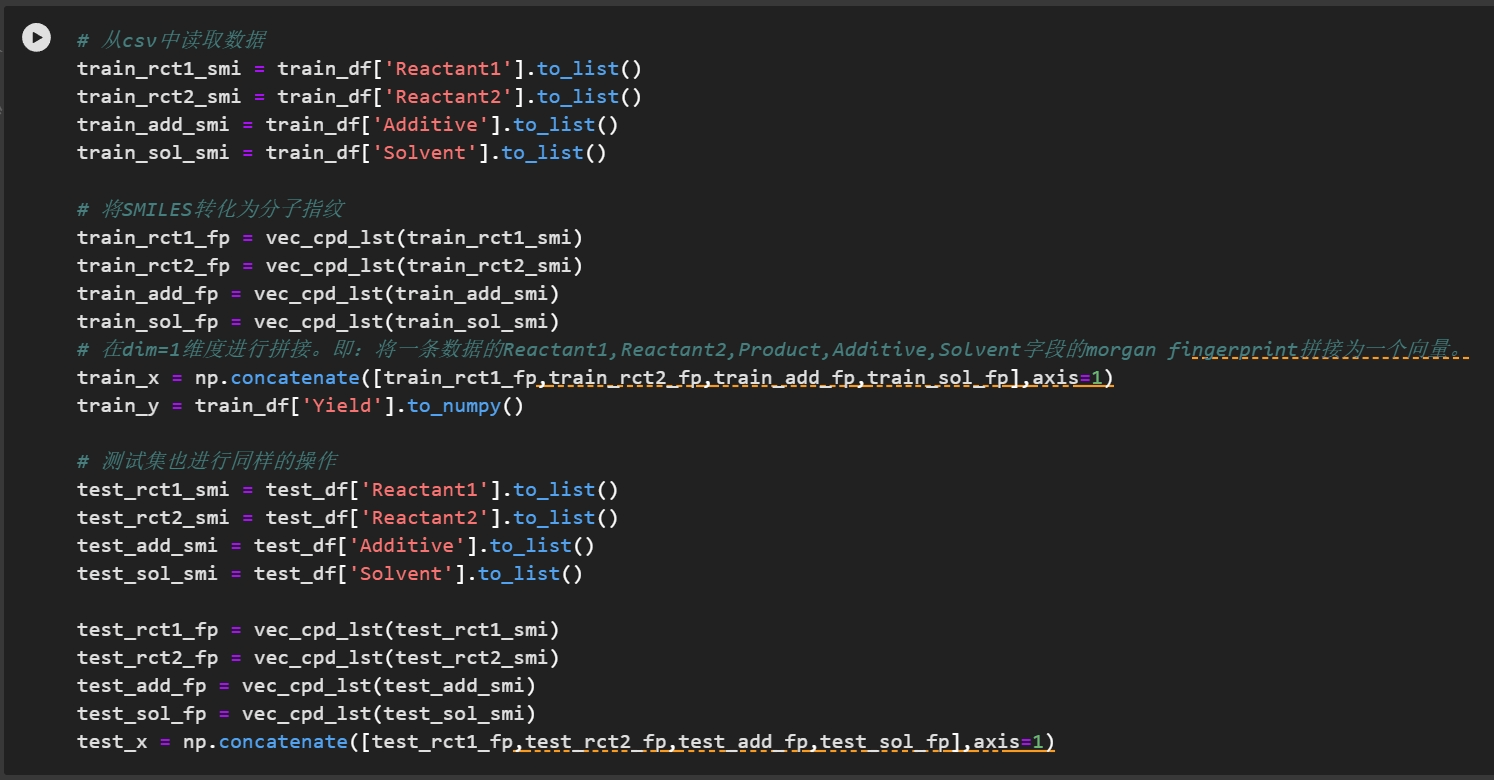
对数据进行转化
使用随机森林进行建模。
sklearn (scikit-learn)
是一个非常广泛使用的开源机器学习库,基于Python,建立在NumPy、SciPy、Pandas和Matplotlib等数据处理和分析的库之上。
它涵盖了几乎所有主流机器学习算法,包括分类、回归、聚类、降维等。API设计亲民,整个使用简单易上手,非常适合作为机器学习入门的工具。 官网:https://scikit-learn.org/stable/index.html
在sklearn中,几乎所有的机器学习的流程是:
- 实例化模型(并指定重要参数);
- model.fit(x, y) 训练模型;
随机森林
参数解释:
- n_estimators=10: 决策树的个数,越多越好;但是越多意味着计算开销越大;
- max_depth: (default=None)设置树的最大深度,默认为None;
- min_samples_split: 根据属性划分节点时,最少的样本数;
- min_samples_leaf: 叶子节点最少的样本数;
- n_jobs=1: 并行job个数,-1表示使用所有cpu进行并行计算。
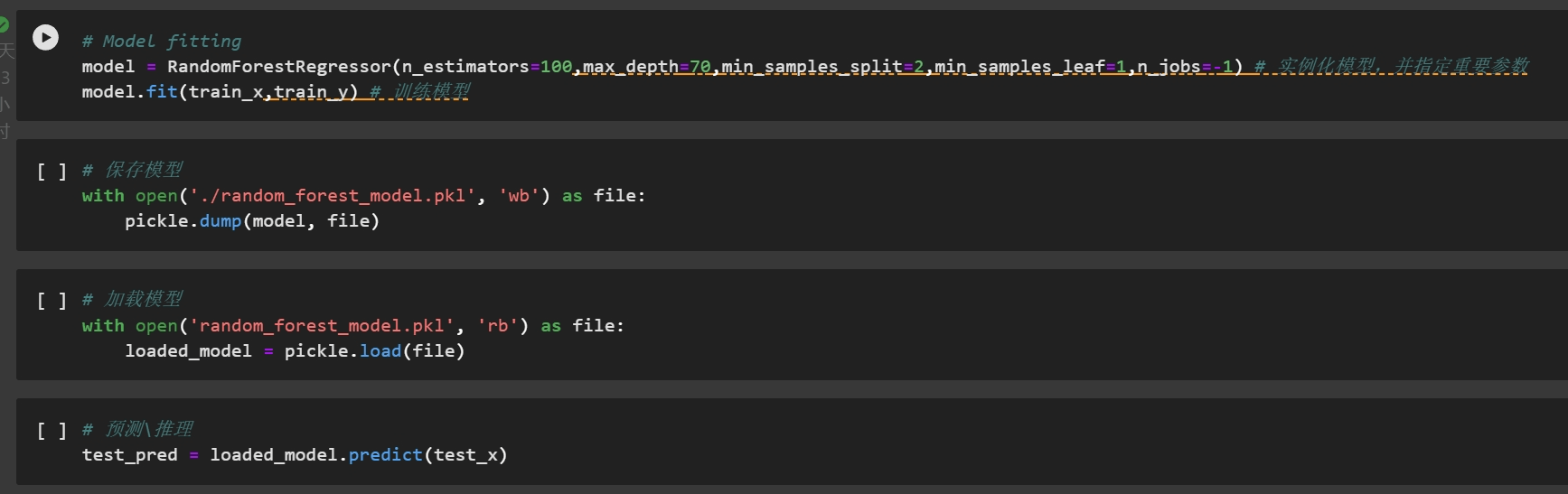
入群相对较晚,但是得以成功运行代码:
Task2:RNN建模SMILES进行反应产率预测
1. AI4Science的早期历史(概要)
AI4Science的发展历史大致也经历这三个阶段:
-
将化学知识以计算机形式存储,并构建数据库;
-
机器学习;
-
深度学习。
在第一个阶段中,人们主要做的事情就是尝试使用不同的方法,尽可能地将化学知识和信息以计算机的形式进行存储,并以此为基础开始构建数据库。例如,用一些字符表示分子或者其他化学符号,如何保存一个具有空间结构的分子的原子、键的位置信息等等。
在第二阶段,大家开始使用一些手动的特征工程对已有数据进行编码、特征提取等操作。例如,在baseline中我们使用了分子指纹(molecule fingerprint)作为我们的编码方式。再辅以传统的机器学习的方法,做一些预测。
在第三阶段,各种各样的深度神经网络也开始被广泛使用。这些网络不仅仅开始学习各种特征,也像word2vec那样,非常多的网络也被拿来对分子进行向量化。这也导致后来又非常多的新型的分子指纹出现。基于seq2seq模型学习表示为序列类型的化学数据、基于diffusion重建分子三维空间结构等等,都是当今的潮流方向。
SMILES —— 最流行的将分子表示为序列类型数据的方法
SMILES,提出者Weininger et al[1],全称是Simplified Molecular Input Line Entry System,是一种将化学分子用ASCII字符表示的方法,在化学信息学领域有着举足轻重的作用。当前对于分子和化学式的储存形式,几乎都是由SMILES(或者它的一些手足兄弟)完成的。使用非常广泛的分子/反应数据库,例如ZINC[2],ChemBL[3],USPTO[4]等,都是采用这种形式存储。SMILES将化学分子中涉及的原子、键、电荷等信息,用对应的ASCII字符表示;环、侧链等化学结构信息,用特定的书写规范表达。以此,几乎所有的分子都可以用特定的SMILES表示,且SMILES的表示还算比较直观。
在SMILES中,原子由他们的化学符号表示,=表示双键、#表示三键、[]里面的内容表示侧基或者特殊原子(例如[Cu+2]表示带电+2电荷的Cu离子)。通过SMLIES,就可以把分子表示为序列类型的数据了。
(注:SMILES有自己的局限性:例如选择不同的起始原子,写出来的SMILES不同;它无法表示空间信息。)
拓展:事实上,使用图数据(grpah)表示分子是非常合适的。图网络相比于基于SMILES的序列网络,在某些方面会更胜一筹。感兴趣的同学可以自行探索。
SMILES的缺点:
-
无法表达充分的空间信息。eg. 对映异构
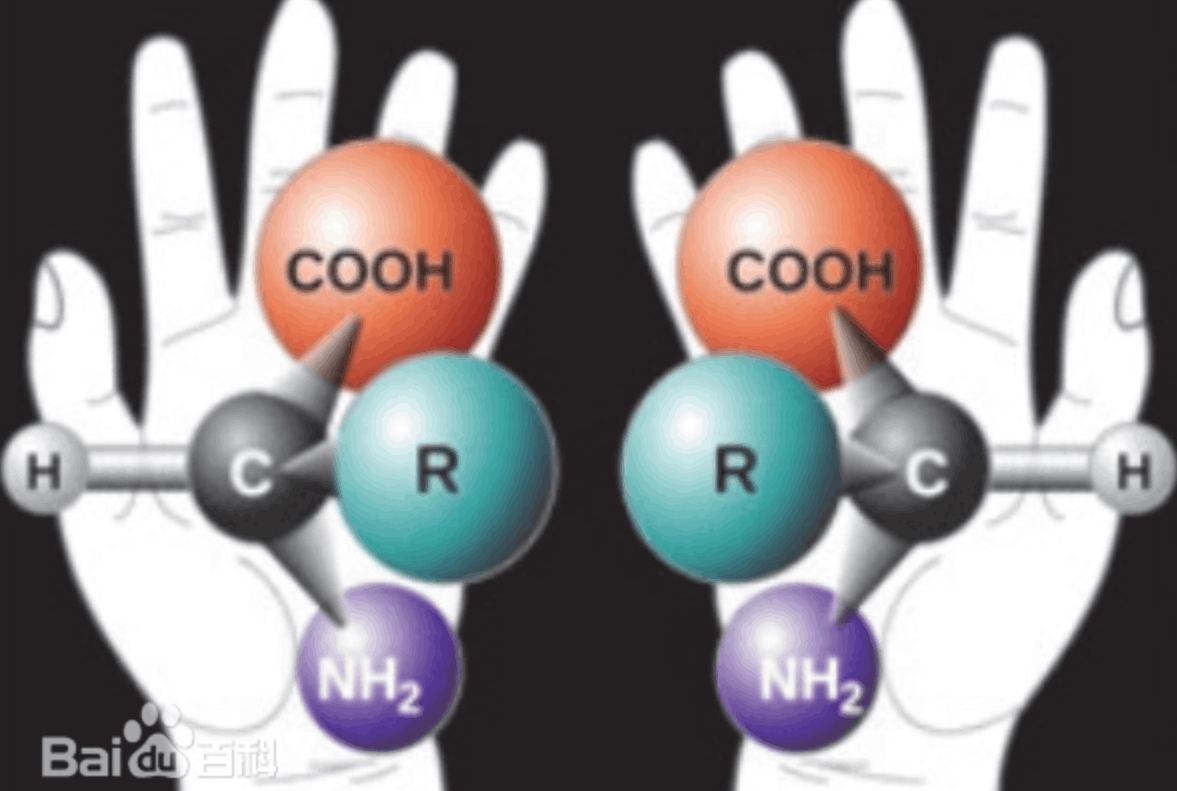
2. 一个分子起始原子不同等因素,有多个SMILES。(不一一对应)—— SMILES规范化。
分子指纹 —— 分子向量化
分子的指纹就像人的指纹一样,用于表示特定的分子。分子指纹是一个具有固定长度的位向量(即由0,1组成),其中,每个为1的值表示这个分子具有某些特定的化学结构。例如,对于一个只有长度为2的分子指纹,我们可以设定第一个值表示分子是否有甲基,第二个位置的值表示分子是都有苯环,那么[0,1]的分子指纹表示的就是一个有苯环而没有甲基的分子。通常,分子指纹的维度都是上千的,也即记录了上千个子结构是否出现在分子中。
[ 补充:
Morgan指纹(Morgan fingerprint)是一种用于描述分子结构信息的量化方法,它由美国化学家Hobart M. Morgan在1968年提出。这种指纹是一种图形化的分子描述符,它通过一系列的圆形节点和连接这些节点的线来表示分子的拓扑结构。
以下是Morgan指纹的一些关键特点:
-
拓扑结构:Morgan指纹不依赖于分子的化学键类型,而是基于原子的连接方式,即分子中原子之间的拓扑关系。
-
图形表示:每个原子用一个圆圈表示,圆圈的大小通常与原子类型有关(例如,碳原子通常比氢原子大)。原子之间的连接用线来表示。
-
特征位:每个连接线代表一个特征位,特征位的大小与连接的两个原子类型有关。例如,碳-碳键的特征位比碳-氢键的特征位要大。
-
指纹大小:Morgan指纹的大小通常由一个参数决定,称为“半径”,它决定了指纹中包含的特征位的数量。半径越大,指纹越详细,但也会变得越复杂。
-
相似性比较:Morgan指纹可以用于比较分子之间的相似性。通常,通过计算两个指纹之间的相似度(如Tanimoto系数)来评估分子的化学相似性。
-
应用:Morgan指纹在化学信息学、药物发现和生物信息学等领域有广泛的应用。例如,它可以用于虚拟筛选、分子对接、生物活性预测等。]
RDkit —— 强大、丰富且高效的化学信息工具
RDkit是化学信息学中主要的工具,是开源的。网址:http://www.rdkit.org,支持WIN\MAC\Linux,可以被python、Java、C调用。几乎所有的与化学信息学相关的内容都可以在上面找到。常用的功能包括但不限于:
-
读和写分子;
-
循环获取分子中原子、键、环的信息;
-
修饰分子;
-
获取分子指纹;
-
计算分子相似性;
-
将分子绘制为图片;
-
子结构匹配和搜索;
-
生成和优化3D结构。
机器学习
机器学习按照目标可以分为分类任务(classification)和回归(regression)任务两大类。所谓分类任务,就是模型预测的结果是离散的值,例如类别;那么,回归任务中,模型预测的结果就是连续的值,例如房价等等。在本次竞赛中,我们需要预测的目标是反应的产率,是0-1之间的一个连续的数值,所以是一个回归任务。(注:离散值通过一些处理可以近似认为是连续值,所以不要被连续值和离散值限制了自己的思维)。
传统的机器学习需要需要经历特征工程这一步骤,即将原始数据转化为向量形式。然后通过SVM、Random Forest等算法学习数据的规律。这些方法在处理简单的任务时是比较有效的。

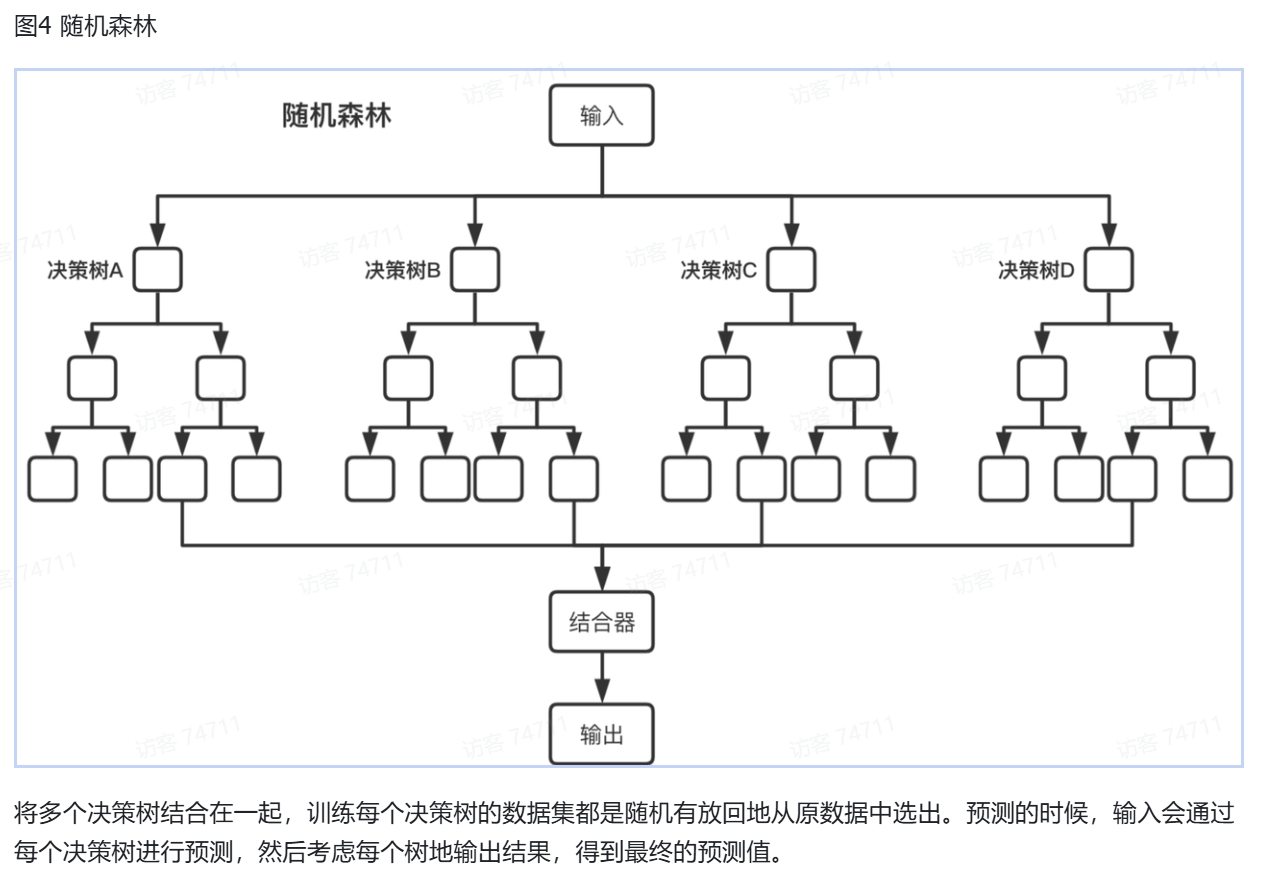
深度学习
深度学习可以归为机器学习的一个子集,主要通过神经网络学习数据的特征和分布。深度学习的一个重要进化是不再需要繁琐的特征工程,让神经网络自己从里面学习特征。
SMILES是一种以ASCII组成的序列,可以被理解为一种“化学语言”。既然是一种语言,那么很自然地想到了可以使用NLP中的方法对SMILES进行建模。
使用RNN对SMILES建模是早期的一个主要方法。RNN(Recurrent Neural Network)是处理序列数据的一把好手。RNN的网络每层除了会有自己的输出以外,还会输出一个隐向量到下一层。
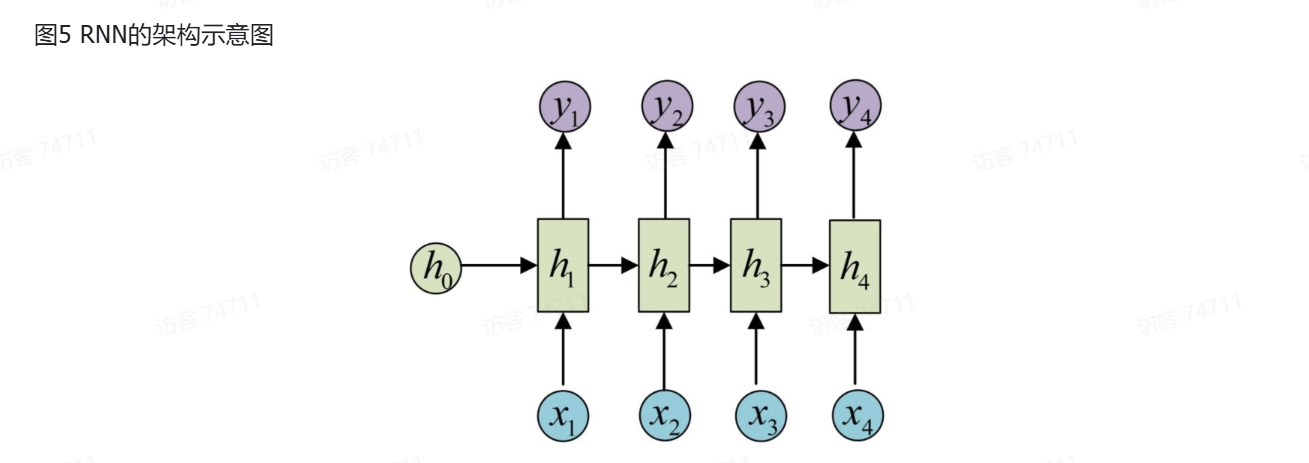

但是RNN也有缺点:如果序列太长,那么两个相距比较远的字符之间的联系需要通过多个隐藏向量。这就像人和人之间传话一样,传递的人多了,很容易导致信息的损失或者扭曲。因此,它对长序列的记忆能力较弱。
同时,RNN需要一层一层地传递,所以并行能力差,同时也比较容易出现梯度消失或梯度爆炸问题。
2. 代码解析:

定义了一个双向循环神经网络(RNN)模型,用于处理序列数据。
构造函数 __init__{
参数:
1.num embed:词汇表的大小,即可能的输入符号数量,
2.input size:每个输入符号的嵌入维度。
3.hidden size:RNN隐藏层的大小。
4.output size:最终输出层的维度,通常与任务相关,例如二分类任务可能为1。
5.num layers:RNN的层数,增加层数可以提高模型的复杂性和性能。
6.dropout:在RNN的输出层应用的dropout比例,用于防止过拟合,7.device:模型运行的设备,例如'cpu'或'cuda'(如果可用)。}
前向传播函数 forward {
参数:
1.输入:x是一个张量,形状为[bs,seqlen],表示批量中的序列数据。
2.嵌入:x通过 self.embed 层进行嵌入,将整数索引转换为向量表示。
3.RNN:序列输入通过RNN层处理, self.rmn 执行循环操作。 batch first=True 表示输入和输出的形状为[batch,seq len,feature]。
4.序列输出: self.rn(x)返回序列输出和最后一个隐藏状态 hn。 hn是一个形状为[numn layers*2,bs,hidden size]的张量,其中2表示双向RNN。
5.隐藏状态重塑: hn 被转置和重塑,以便将其转换为一个形状适合全连接层输入的张量。
6.输出层:通过 self.fc层(包括线性转换和激活函数)对重塑后的隐藏状态进行处理,最后输出一个形状为[bs,1]的张量。}
Smiles_tokenizer(原代码较长,因此将只保留分析部分。):
这个类用于将SMILES字符串(结构简式)转换为数值序列,以便于在机器学习模型中处理。它包括以下功能:1.初始化:接受参数如填充标记(pad_token)、正则表达式(regex)、词汇表文件路径(vocab _file)和最大序列长度(max_length)。2.正则匹配:使用正则表达式(regex)对输入的SMILES字符串进行分词。
3.添加开始和结束标记:将每个分词的序列开始和结束标记添加为<CLS>和<SEP>
4.填充序列:将序列填充到最大长度(如果序列长度小于最大长度)。
5.转换为索引:将序列转换为词汇表中的索引列表。
数据读取函数 read_data :
这个函数用于读取CSV文件,并将数据预处理为可用于模型训练的格式。它接收文件路径和一个布尔值(train),用于确定是否为训练集,处理过程包括。
1.读取CSV文件并提取列数据。
2.将反应物(Reactant1、Reactant2)和产物(Product)拼接成一个字符串。
3.如果是训练集,则提取反应产率(yield)。
4.返回处理后的数据对列表(反应物和反应产率)。
数据集类 ReactionDataset:
这个类用于构建数据集,支持快速访问数据集中的样本。它包括:
1.初始化:接受数据列表作为参数。
2.长度:返回数据集的长度(样本数量)
3.获取样本:根据索引返回数据集中的一个样本。
批处理函数 collate_fn :
这个函数用于将数据集中的样本打包成一个批次,以便于模型训练。它执行以下操作:
1.初始化一个自定义的tokenizer实例:
2.对批次中的所有SMILES字符串进行序列化处理.
3.将序列化后的序列和对应的反应产率转换为张量,
4.返回一个包含序列和反应产率的张量对。
3. 调试结果:
(调了几次参数,但跳到最后,第一次的愤分反而是最高的 【流汗】)
Task3:Transformer建模SMILES进行反应产率预测
1. transformer诞生的由来
循环神经网络的序列到序列建模方法,在建模文本长程依赖方面都存在一定的局限性。
循环神经网络:由于所有的前文信息都蕴含在一个隐向量里面,这会导致随着序列长度的增加,编码在隐藏状态中的序列早期的上下文信息被逐渐遗忘。
卷积神经网络:受限的上下文窗口在建模长文本方面天然地存在不足。如果需要关注长文本,就需要多层的卷积操作。
循环神经网络中,每个词都会依赖上一个词:
![]()
优势
完全通过注意力机制完成对序列的全局依赖的建模。并且,这是一种可以高并行的结构,大大增加了计算效率。
基本架构示意图
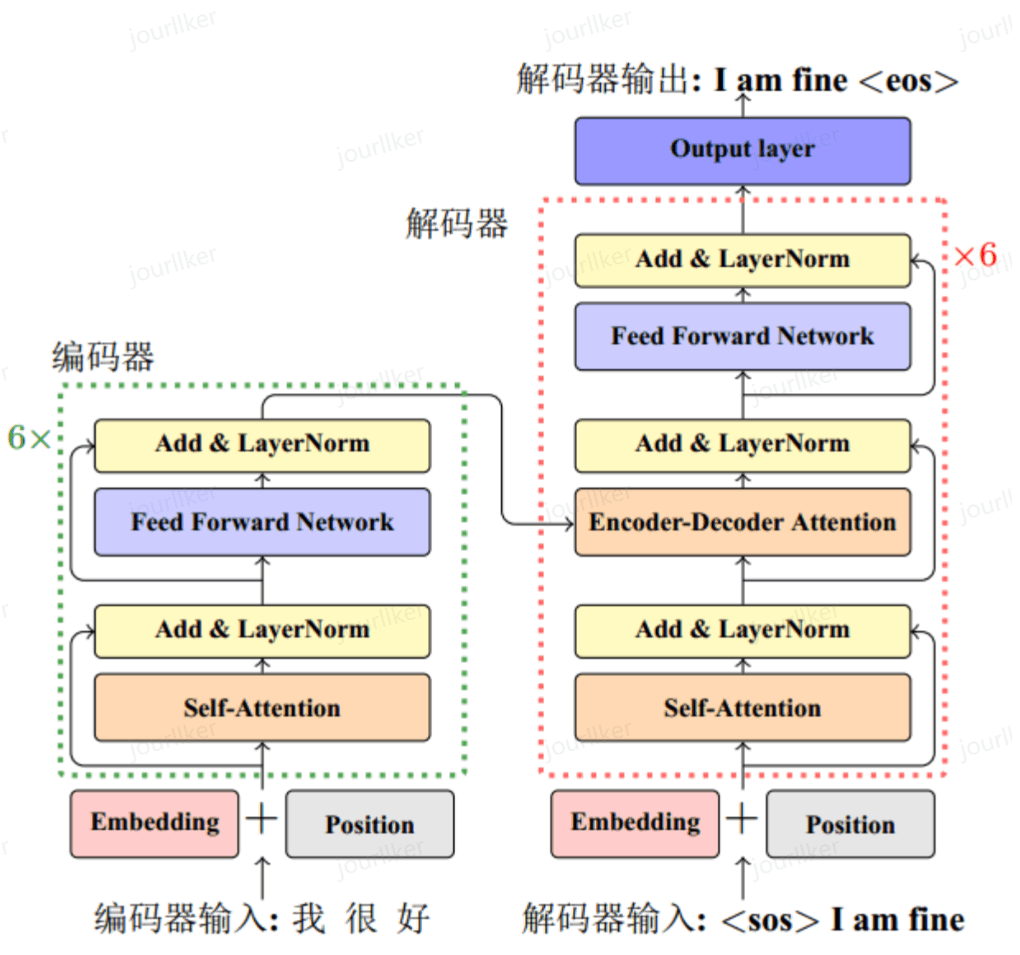
-
嵌入层 (embedding layer)
将token转化为向量表示。模型认识的只是向量,所以需要将每个切分好的token转化为向量。
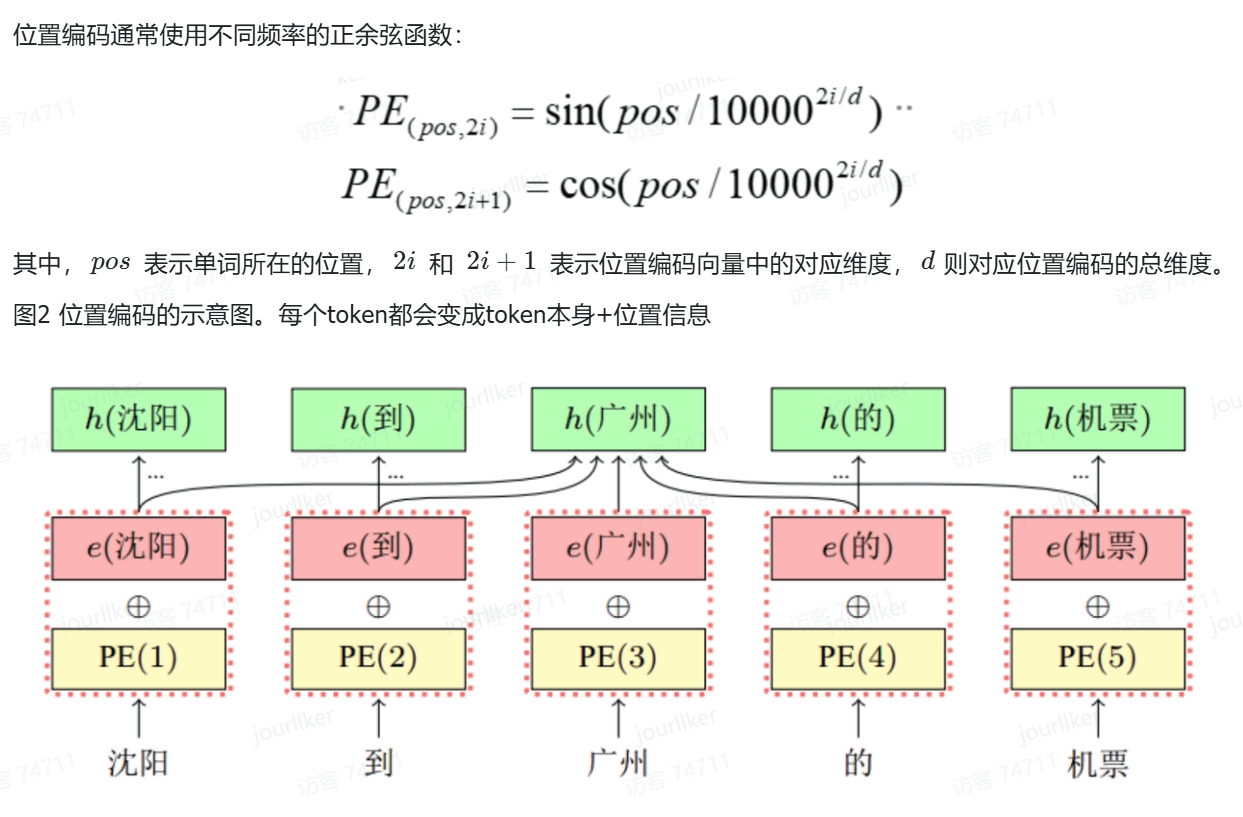
这个过程中,与RNN不同的是,我们在Transformer的嵌入层,会在词嵌入中加入位置编码(Positional Encoding)。
-
自注意力层 (self-attention layer):

-
前馈层 (Feed Forward layer):

- 残差连接:从基本架构图中我们可以看到,每个(LayerNorm layer)都有一个(Add),这就是一个残差连接。它的作用是用一条直连通道直接将对应子层的输入连接到输出上去,从而避免由于网络过深在优化过程中潜在的梯度消失问题。
-
层归一化 (Layernorm)我们直到,在神经网络中,我们经常对每一层的输出数据进行归一化,以使得模型更快达到收敛。只不过,前面的归一化方式几乎都是batch normalization,即对不同的batch进行归一化。Transformer在最开始被提出来的时候,采用的也是batch normalization。但是在人们后续的实践中发现,对于transformer而言,每一层间的归一化效果都要更好。归一化操作的计算表达式:

利用Transformer的Encoder作为编码器编码
Transformer也是一个经典的编码器-解码器模型(encoder-decoder model)。从基本架构图中也可以看到,编码器部分将输入转化为一个向量之后,再传递到了解码器部分。既然这样,我们完全可以把Transformer的Encoder和Decoder部分拆开,分别拿来使用。其实,在大语言模型中非常具有代表性的BERT和GPT就是这样干的,它俩分别使用了Transformer的Encoder部分和Decoder部分。
既然Encoder部分输出的本身就是一个向量(我们这里称之为向量$$$$),那么只要模型学习得够好,那么这个向量就一定包含了重要得输入序列得信息。这就是为什么我们可以把Encoder单独拿出来并看作是一个编码器得原因。因此,我们可以将这个代表输入序列的向量$$$$,再作为其他模型的输入(例如全连接网络等),从而进行我们想要的分类或者回归任务。这样的思路被广泛应用在AI领域的研究和工程中。
在这里,我们使用Transformer的Encoder部分,编码我们的SMILES表达式。然后,再将等到的向量$z$通过一个线性层,输出一个值。我们期望通过模型的学习,这个输出的值就是该化学反应的产率。
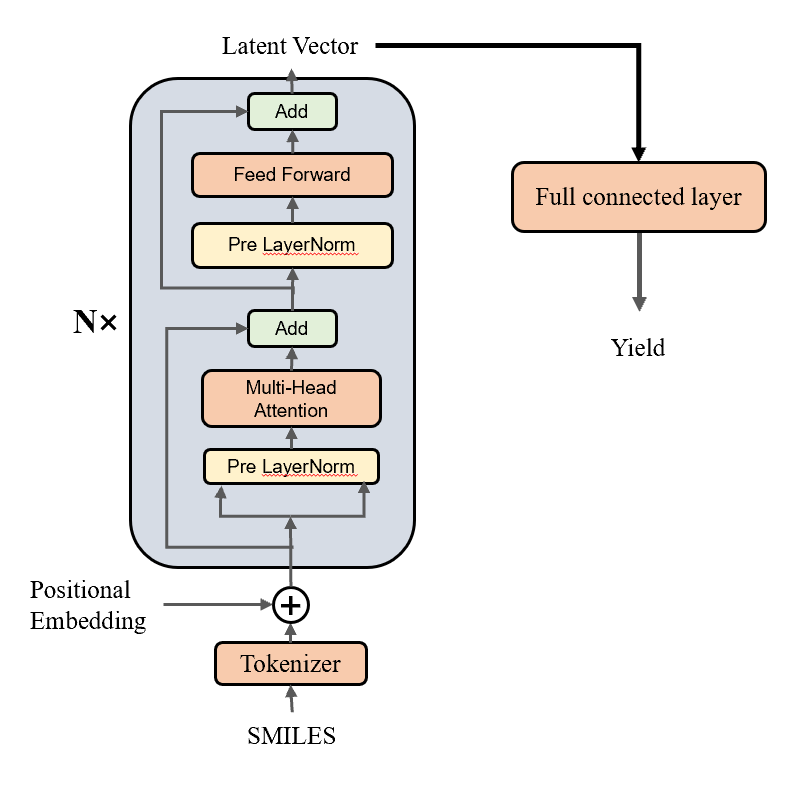
2. 代码解析:
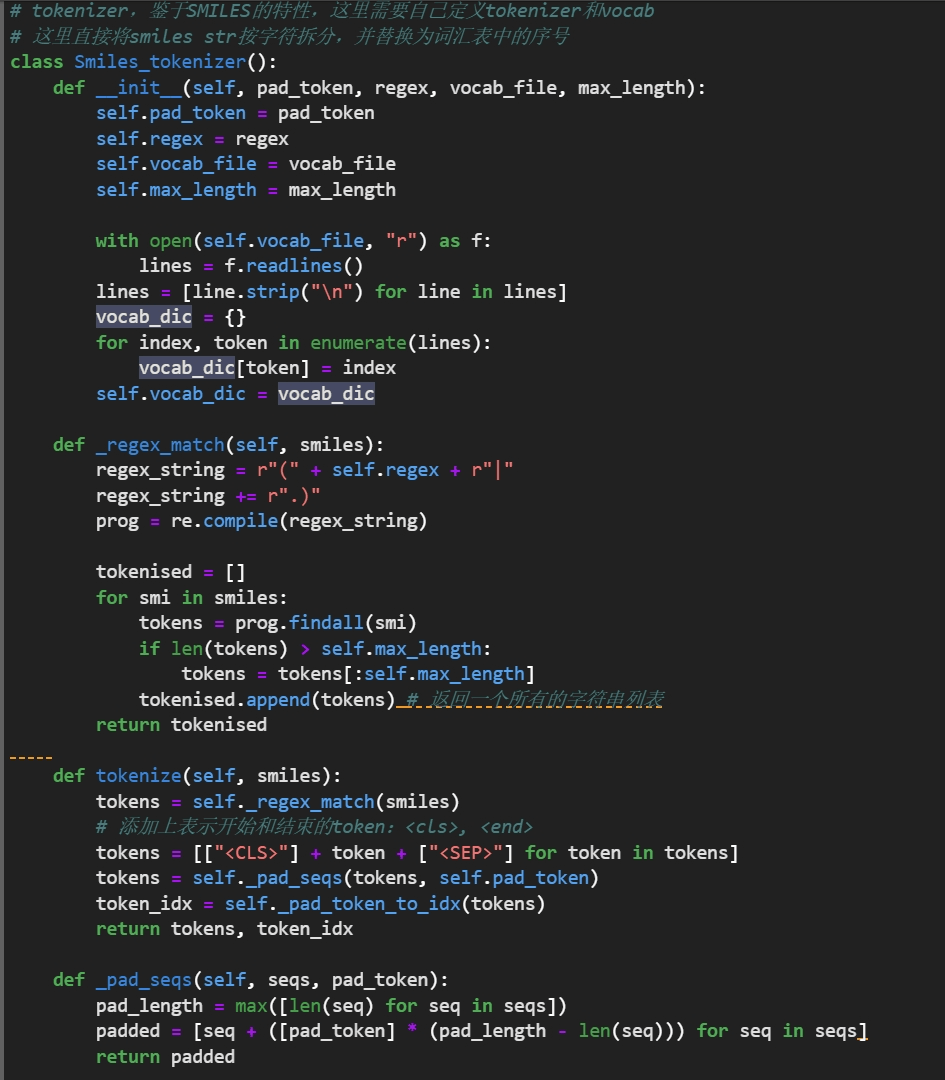
Smiles_tokenizer 类初始化时加载一个词汇表文件,并创建一个词汇字典,其中包含每个token及其对应的索引。
_regex_math 方法将SMILES字符串转换为token序列,并添加开始和结束标记,然后进行填充和索引转换。
_pad_seqs方法将所有序列填充到相同的长度,使用pad_token作为填充。
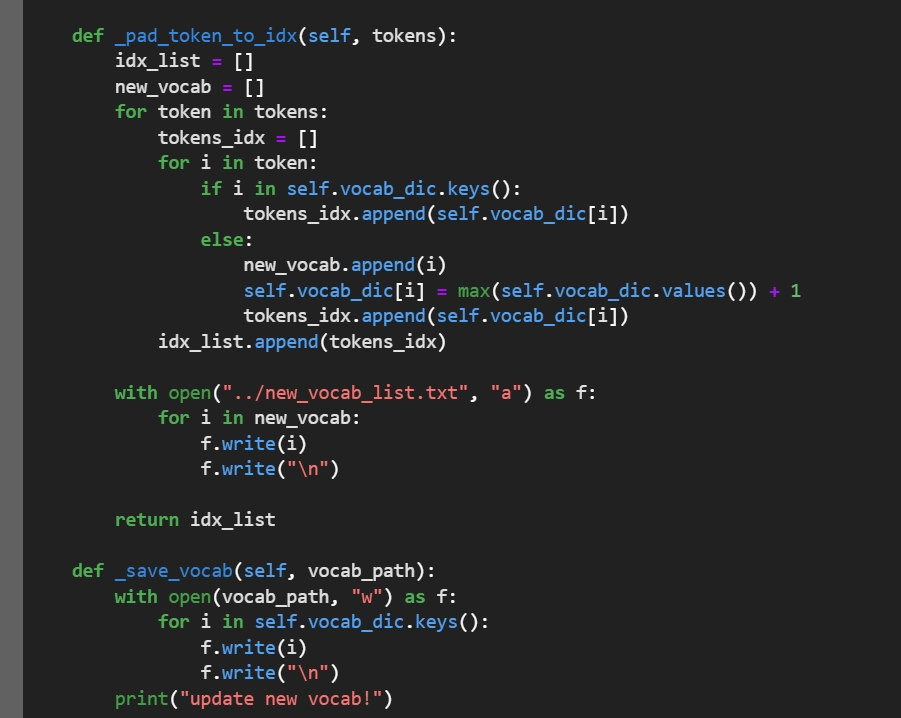
_pad_token_to_idx 方法将token序列转换为索引序列,并记录遇到的新token,更新词汇表。
_save_vocab 方法将更新后的词汇表保存到文件。

1.嵌入层(Embedding Layer):
.nn.Embeding(input dim,d model):将输入的索引(如单词索引)转换为嵌入向量。 input dim是词汇表的大小,d mode1 是嵌入向量的维度
2.层归一化(Layer Normalization):
.nn.LayerNorm(d model):对嵌入向量进行层归一化,有助于稳定训练过程。
3.Transformer编码器层(TransformerEncoderLayer): 1.多头自注意力 (Multi-head self-Attention):允许多个注意力头并行处理序列信息,提高模型的表达能力。
2.前馈神经网络(Feed Forward Neural Network): 对注意力层的输出进行非线性变换。
3.nhead:注意力头的数量。
4.dim feedforward:前馈神经网络的隐藏层维度,
5.dropout:在注意力层和前馈神经网络后应用的dropout比例。
6.batch first:是否将序列长度放在第一个维度。
7.norm first:是否在多头自注意力之前应用层归一化。
4.Transformer编码器(TransformerEncoder):
1.nn.TransformerEncoder(self.encoder_layer, num layers=num layers,norm=self.layerNorm):包含多个编码器层的堆叠,num_layers 是层数。
2.norm:用于编码器层的层归一化层。
5. Dropout:
1.nn.Dropout(dropout):在嵌入层和编码器层之后应用dropout,以减少过拟合.。
6. 线性层(Linear Layers):
1.mn.segwential(mn.Linear(d motel,256),mn.stgmoid(),m.linear(256,96),mn.sigmoid(0),mn.Limnear(96,1):用于将编码器的输出转换为最终的预测,这里使用了Sigmoid激活函数,可能用于生成废率值。
前向传播
forward 方法定义了模型的前向传播过程:
1.src:输入序列,形状为[batch size,src len]。
2.embedded:经过嵌入层处理后的序列,形状为[batch size,src len,d model]. 3.outputs:经过Transformer编码器处理后的序列,形状为[batch size,src len,d model]
4.z:从编码器输出中提取的第一个token的表示,形状为[batch size,d model]。
5.outputs:经过线性层和Sigmoid激活函数处理后的输出,形状为[batch_size,1]。
3. 调试结果:
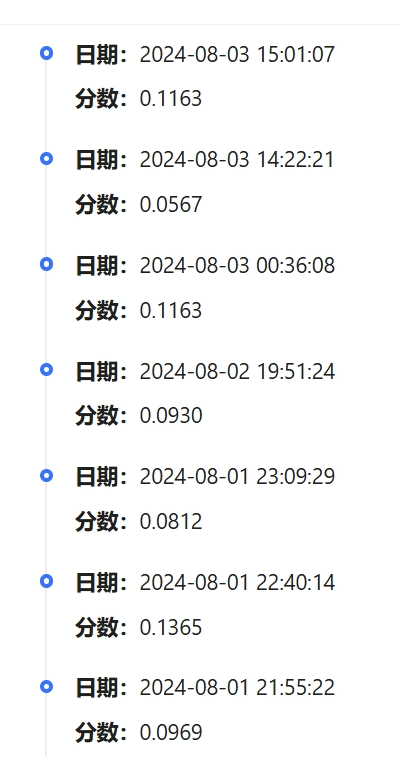
做了一定的尝试,也有所提升。
但是突然出现了一个output文件夹消失的错误,没能保存一开始的更改。
改了一天才得到一开始的成果。
希望在后续的参与中能更好的提升自己的学习能力和对深度学习的理解。















 613
613

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









