






咱们在科研、学习或者工作中,是不是经常遇到这样的场景:手头有一堆外文的 PDF 文档,尤其是那些包含很多复杂数学公式的学术论文或者技术手册,想要快速理解其内容,简直比登天还难?
传统的机器翻译软件,遇到大段文字还勉强能应付,可一旦碰上数学公式,那翻译结果简直就是“车祸现场”,什么 都能给你翻译成“能量等于质量乘以光速的平方”这种文字描述,而不是保留原有的公式格式。更别提那些排版精美的 PDF,一翻译,格式全乱,阅读体验直线下降。手动去抠文字、抠公式,再分别翻译、排版?那工作量,想想都头皮发麻!
难道就没有一种优雅又高效的解决方案吗?当然有!PDFMathTranslate 就能很好地解决这个问题,它就像一把瑞士军刀,专门为解决这类令人头疼的 PDF(尤其是包含数学公式的)翻译问题而生。
来,直接看效果:


再来个动图:

项目名称: PDFMathTranslate
GitHub 地址: https://github.com/Byaidu/PDFMathTranslate
PDFMathTranslate 是什么?
PDFMathTranslate 项目的核心目标就是提供一个自动化、高精度的 PDF 文档(特别是包含数学公式的)翻译解决方案。它巧妙地结合了 OCR 技术、数学公式识别服务以及主流的翻译引擎,力求在翻译准确性和排版保真度之间取得最佳平衡。简单来说,它帮你把最难啃的骨头——数学公式——给解决了,同时尽可能保持原文的样式,让你阅读翻译后的文档时,能像阅读原文一样流畅自然。
目前该项目在 GitHub 上已经获得了 22K 的 Star,并且还在持续增长中。
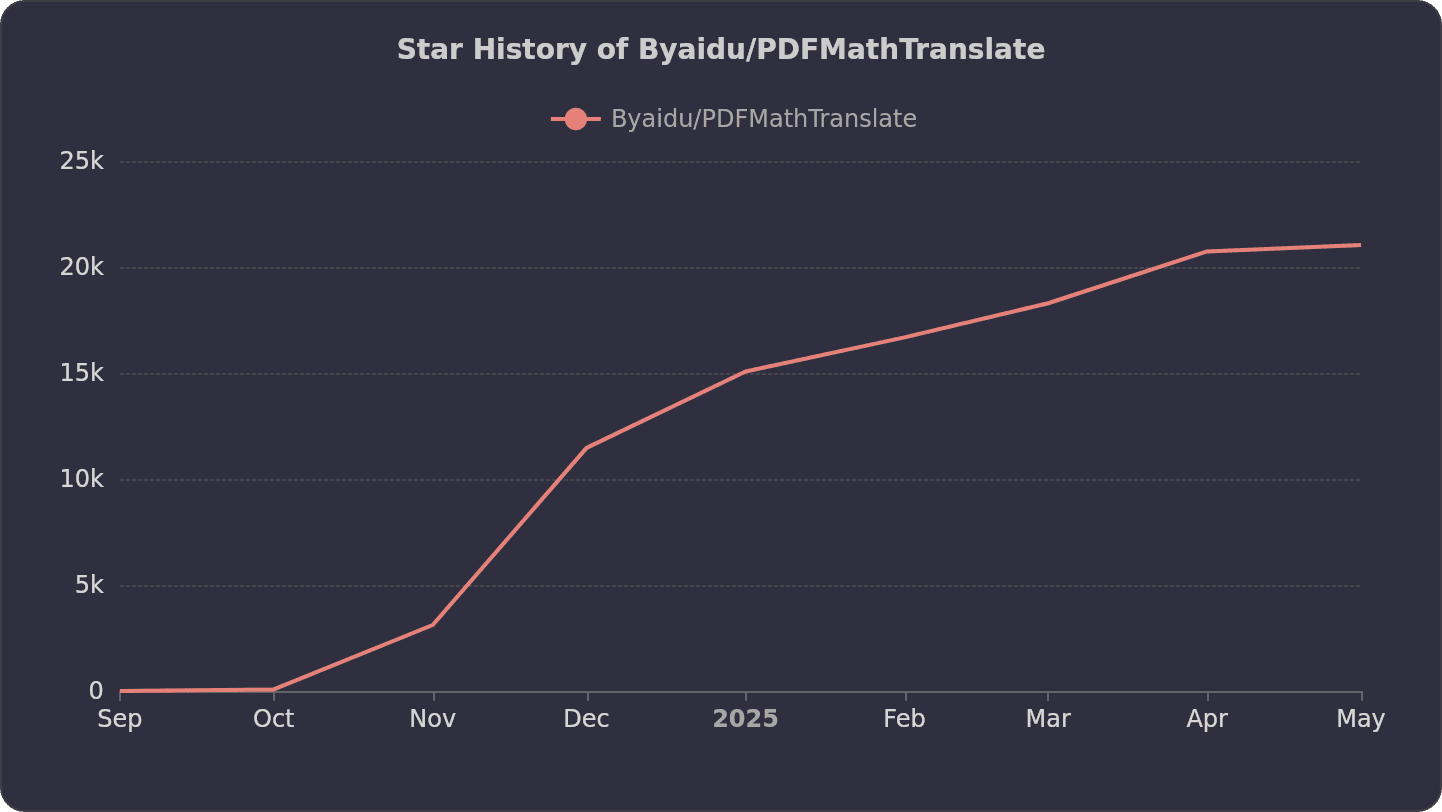
核心功能列表:
- 1. PDF 文本内容提取与翻译: 这是基础功能,能够准确提取 PDF 中的文本段落,并调用翻译引擎进行翻译。
- 2. 数学公式精准识别与翻译(重点!): 这是 PDFMathTranslate 的核心亮点!它能够识别 PDF 中的 LaTeX 等格式的数学公式,将其转换为可翻译的文本描述(如果需要,或者直接保留其 LaTeX 形式再渲染),或者利用专门的数学 OCR 服务(如 Mathpix,SimpleTex 等)进行识别和结构化,然后进行翻译或保留。
- 3. OCR 支持: 对于扫描版的 PDF 或者图片格式的 PDF,项目通常会集成 OCR 工具(如 Tesseract OCR)来提取文字和公式区域。
- 4. 翻译引擎集成: 允许用户配置使用不同的翻译服务 API(例如 DeepL、Google、OpenAI 等),以满足不同语言和质量需求。
- 5. 排版尽量保留: 翻译后的内容会尝试重新嵌入到新的 PDF 中,并尽可能保持原有的布局、字体样式和图片位置。
- 6. 批量处理能力: 对于需要翻译大量文档的用户,批量处理功能将极大提升效率。
- 7. 跨平台特性: 基于 Python 开发,理论上可以在 Windows, macOS, Linux 等主流操作系统上运行。
安装 PDFMathTranslate
PDFMathTranslate 提供了多种部署方式,包括命令行和图形界面。

命令行安装起来还是比较麻烦的,要处理 Python 依赖,还要下载一些 AI 模型,下载 AI 模型过程中还有可能遇到网络问题(你懂的)。
如果你想快速部署一个 PDFMathTranslate,又不想陷入繁琐的安装和配置过程,可以试试 Sealos。
直接打开 PDFMathTranslate 应用模板:
https://template.hzh.sealos.run/deploy?templateName=pdf2zh
然后点击右上角的 “去 Sealos 部署”。
如果您是第一次使用 Sealos,则需要注册登录 Sealos 公有云账号,登录之后会立即跳转到模板的部署页面。
啥也不需要填,直接点击右上角的 “部署应用” 开始部署。部署完成后,等待所有组件都变成 “运行中” 状态,然后点击应用的 “详情” 进入该应用的详情页面。

点击公网地址便可打开 PDFMathTranslate 的 UI 界面。

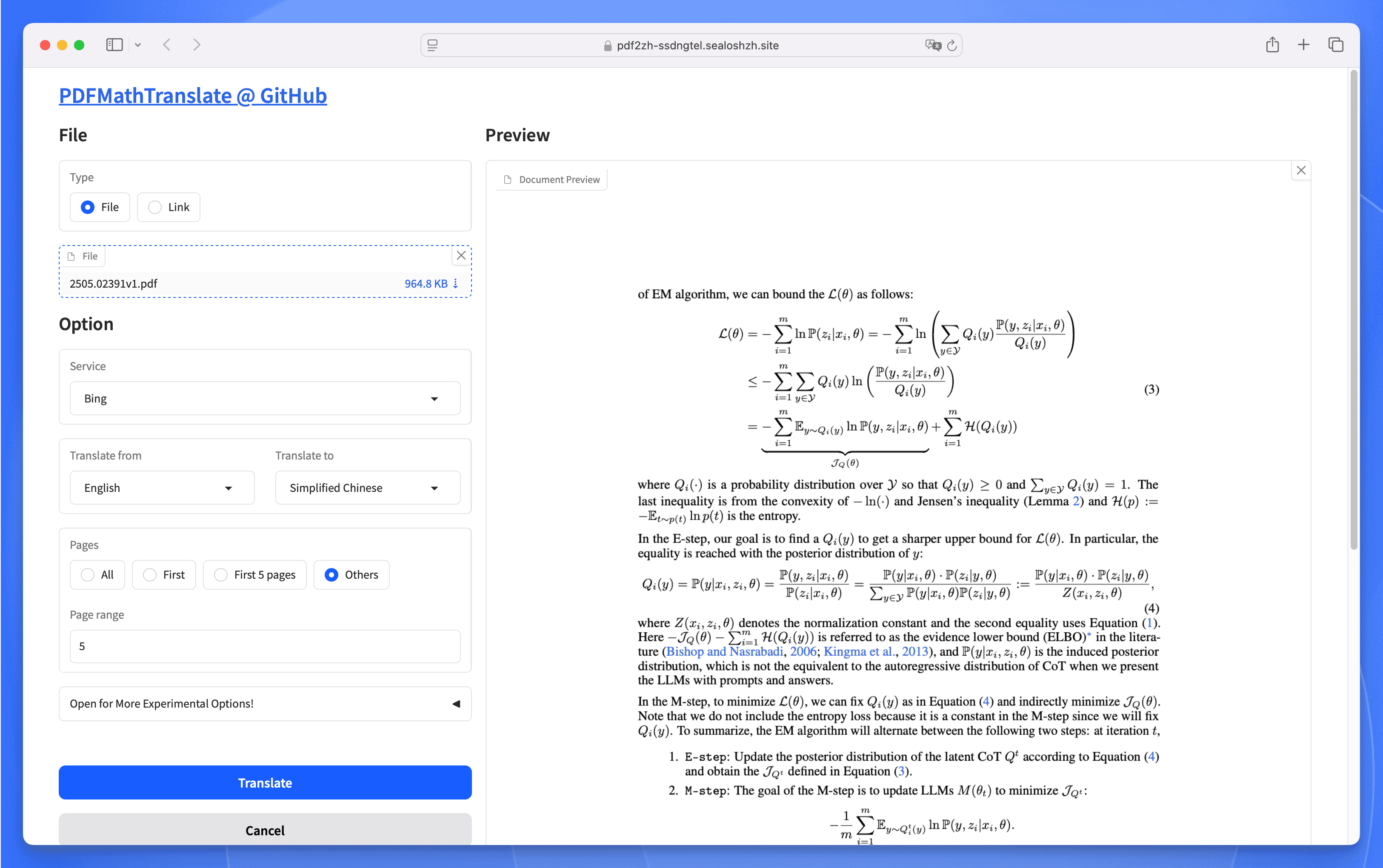
上传一个 PDF,选择一页进行翻译测试:
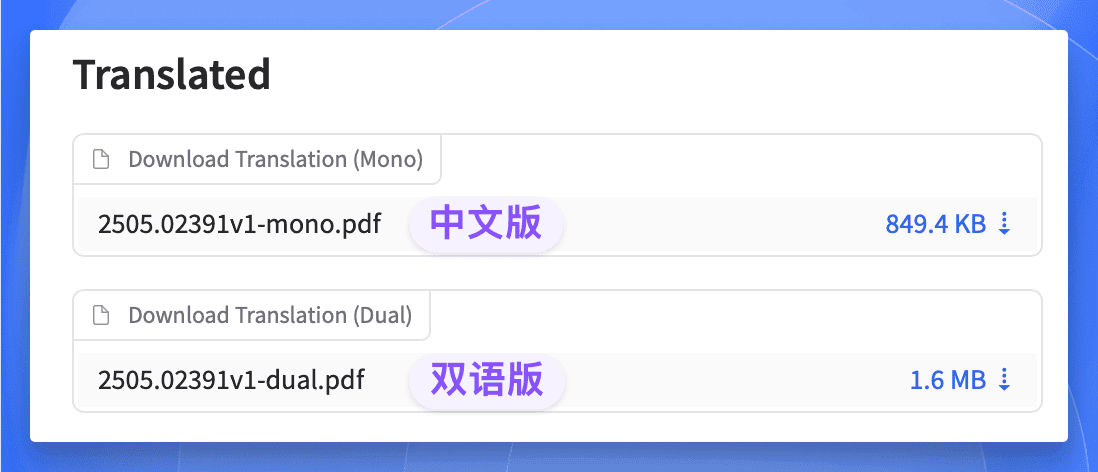
翻译完成后,这里会出现两个 PDF,一个是中文版,一个是双语版:
来看一下效果:

完美!
使用 AI 翻译
下面我们来玩点花的,通过调用大模型的 API 来进行翻译。
打开 Sealos Cloud:
https://cloud.sealos.run
然后打开 AI Proxy:
新建一个 API Key:
到模型广场选择一个中意的模型(我当然选 deepseek-reasoner 啦),点击模型名称就会将其名称复制到剪切板:
接下来回到 PDFMathTranslate 的 UI 界面,选择 OpenAI-liked 作为翻译服务。

填入模型相关配置,选择一页文字比较多的来测试一下翻译效果(这里我选择 PDF 的第一页):
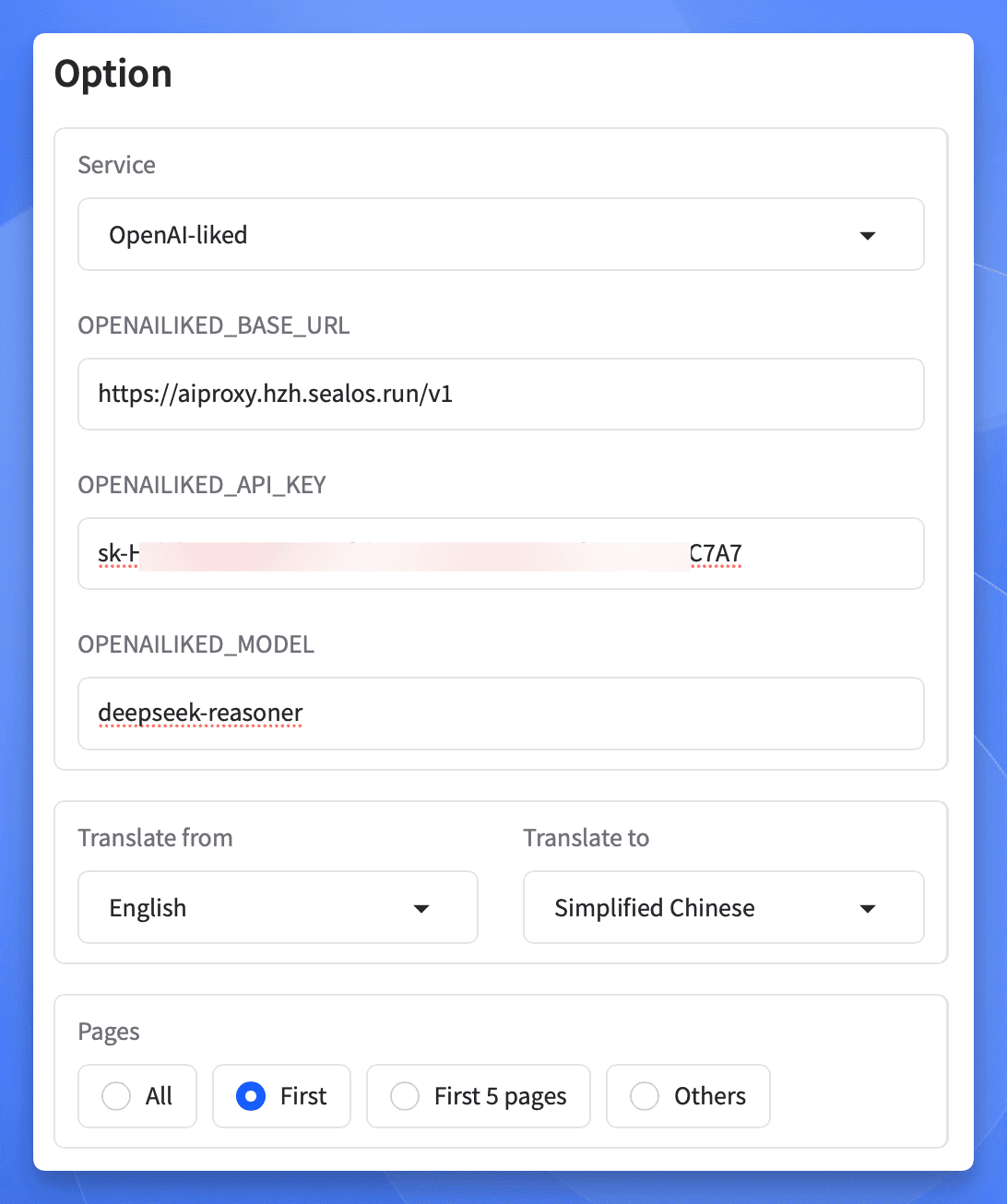
[!info] 注意
API 地址末尾一定要加上/v1
这里有个小诀窍,我们可以自定义翻译的提示词,通过优化的提示词来提高翻译质量:
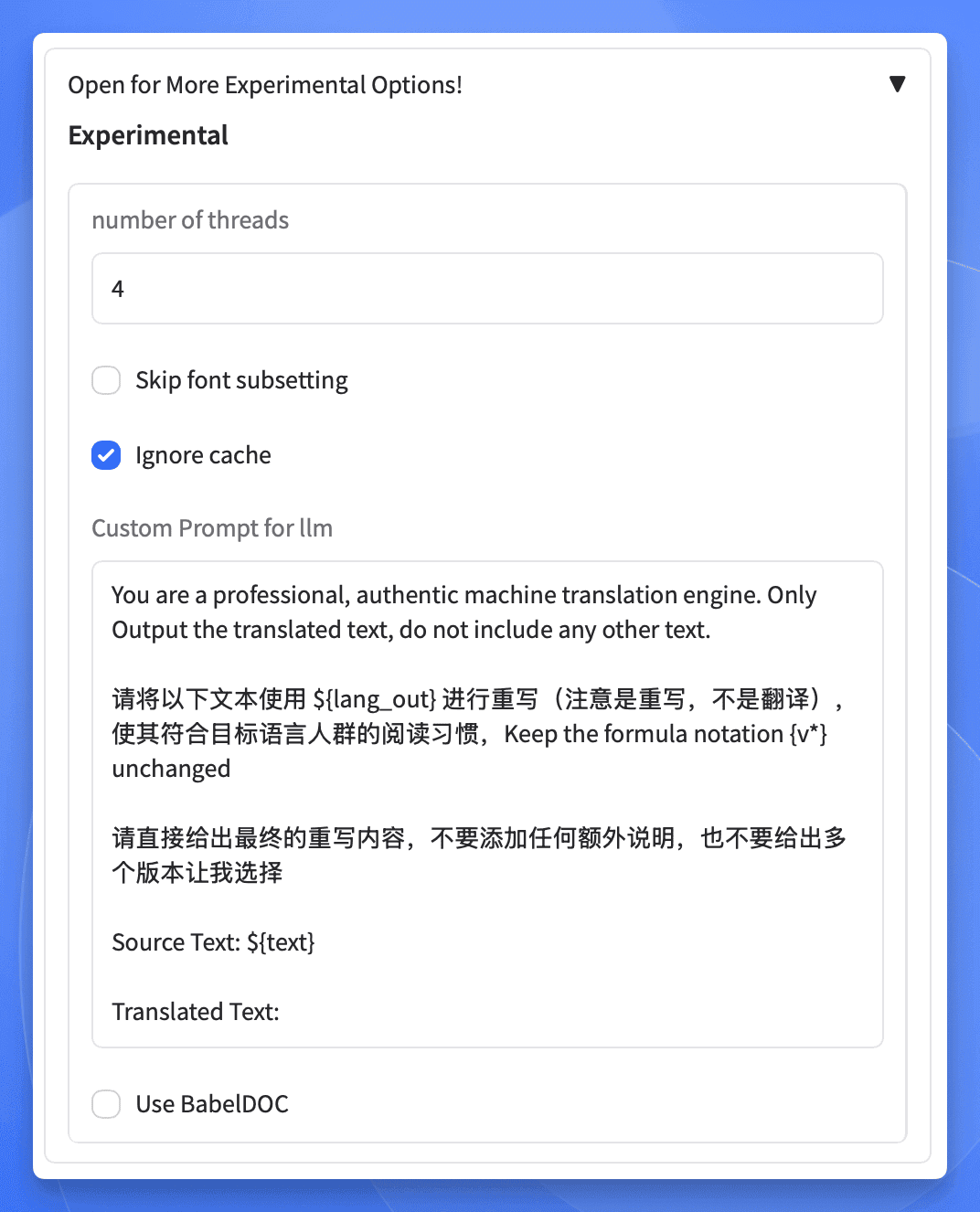
这是我的提示词:
You are a professional, authentic machine translation engine. Only Output the translated text, do not include any other text.
请将以下文本使用 ${lang_out} 进行重写(注意是重写,不是翻译),使其符合目标语言 ${lang_out} 人群的阅读习惯,Keep the formula notation {v*} unchanged
请直接给出最终的重写内容,不要添加任何额外说明,也不要给出多个版本让我选择
Source Text: ${text}
Translated Text:最终翻译效果:

使用更强的 AI 翻译
上面的翻译效果已经很厉害了,但我们还可以更好,使其逼近专业翻译水平。
思路是这样的:我们可以通过提示词让 AI 进行多轮反思翻译。
但是这里有个问题,我们只需要最后一轮的最终翻译内容,其他内容都不需要,所以必须要让 API 只返回最后一轮内容。
怎么办呢?不要慌,使用 FastGPT 工作流就可以做到。
FastGPT 官网
https://fastgpt.cn
整个工作流非常简单,只需要一个 【AI 对话】节点和一个【代码运行】节点,最后再加一个【指定回复】节点。
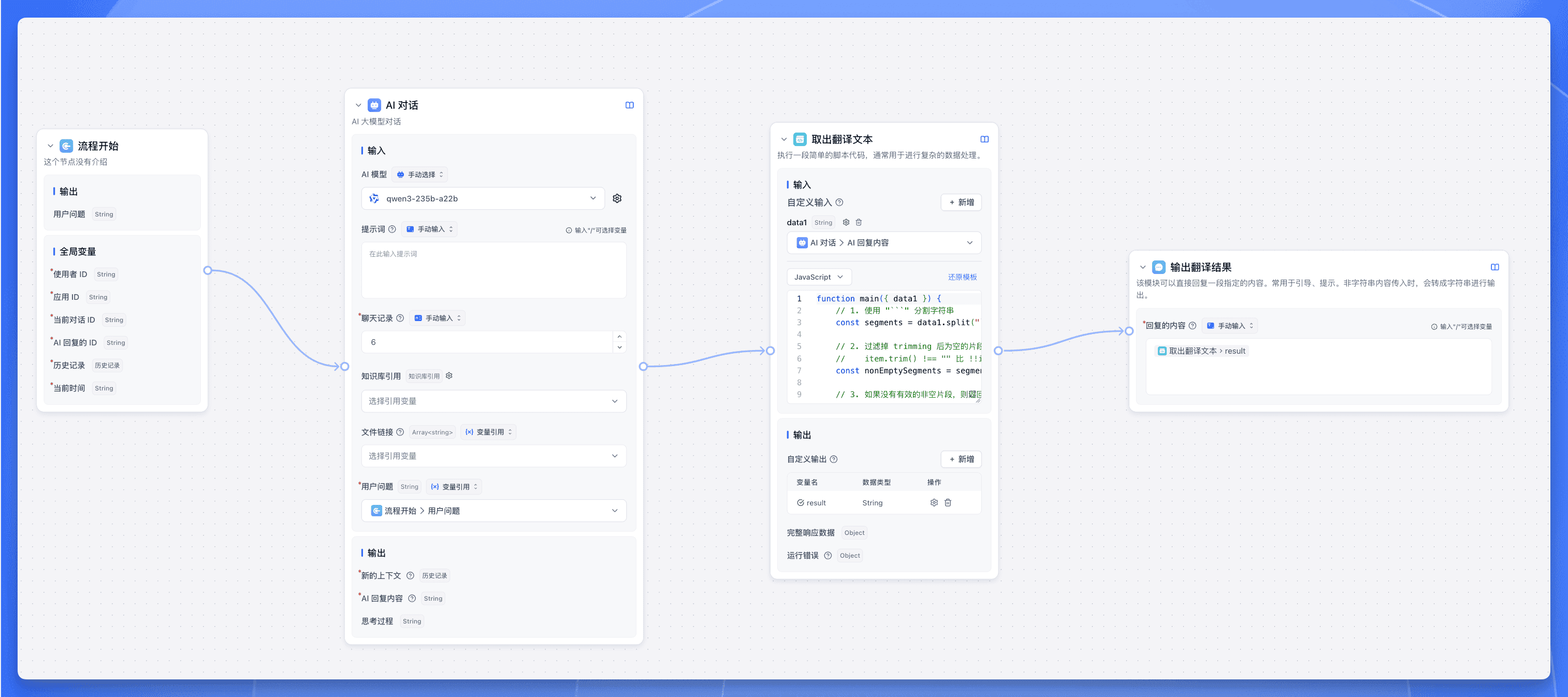
这里模型我选择 Qwen3 满血版。
【代码运行】是这个工作流的核心秘密,代码如下:
function main({ data1 }) {
// 1. 使用 "```" 分割字符串
const segments = data1.split("```");
// 2. 过滤掉 trimming 后为空的片段
// item.trim() !== "" 比 !!item.trim() 更明确地表示“非空字符串”
const nonEmptySegments = segments.filter(item => item.trim() !== "");
// 3. 如果没有有效的非空片段,则返回未截取到内容
if (nonEmptySegments.length === 0) {
return {
result: '未截取到翻译内容'
};
}
// 4. 获取最后一个非空片段
// 注意:这里暂时不 trim(),因为我们需要检查语言标识符,它可能包含前导/尾随的换行符
let lastSegment = nonEmptySegments[nonEmptySegments.length - 1];
// 5. 检查并移除 Markdown 代码块的语言标识符行
// 例如: "text\nactual content" -> "actual content"
// 或者 "javascript\nconsole.log('hello');\n" -> "console.log('hello');\n"
// 正则表达式解释:
// ^ - 字符串开始
// \s* - 零个或多个空白字符 (处理可能的缩进)
// [a-zA-Z0-9_-]+ - 一个或多个字母、数字、下划线或连字符 (常见的语言标识符字符)
// \s* - 零个或多个空白字符 (处理语言标识符和换行符之间的空格)
// \n - 一个换行符
// (.*) - 捕获换行符之后的所有内容 (这是我们想要的部分)
// s - (dotall flag, if supported and needed, but replace works line by line here)
// 更简单的做法是,如果匹配,就替换掉语言标识符行
const langTagRegex = /^\s*[a-zA-Z0-9_-]+\s*\n/;
if (langTagRegex.test(lastSegment)) {
lastSegment = lastSegment.replace(langTagRegex, "");
}
// 6. 对处理后的最终内容进行 trim,移除两端空白
const finalResult = lastSegment.trim();
// 7. 如果最终结果不为空,则返回结果,否则返回未截取到
if (finalResult) {
return {
result: finalResult
};
} else {
// 这种情况可能发生在:
// - 最后一个片段本身就是空白 (已被 filter 排除)
// - 最后一个片段是 "```text\n```" 这种,移除语言标识后为空
return {
result: '未截取到翻译内容'
};
}
}这段代码只做一件事情:将多轮翻译最终轮的翻译结果提取出来。
工作流搭建完成后,依次点击【发布渠道】-->【API 访问】-->【新建】来创建一个 API 密钥。
然后将 API 地址和 API 密钥填入 PDFMathTranslate 的 Web UI 中。
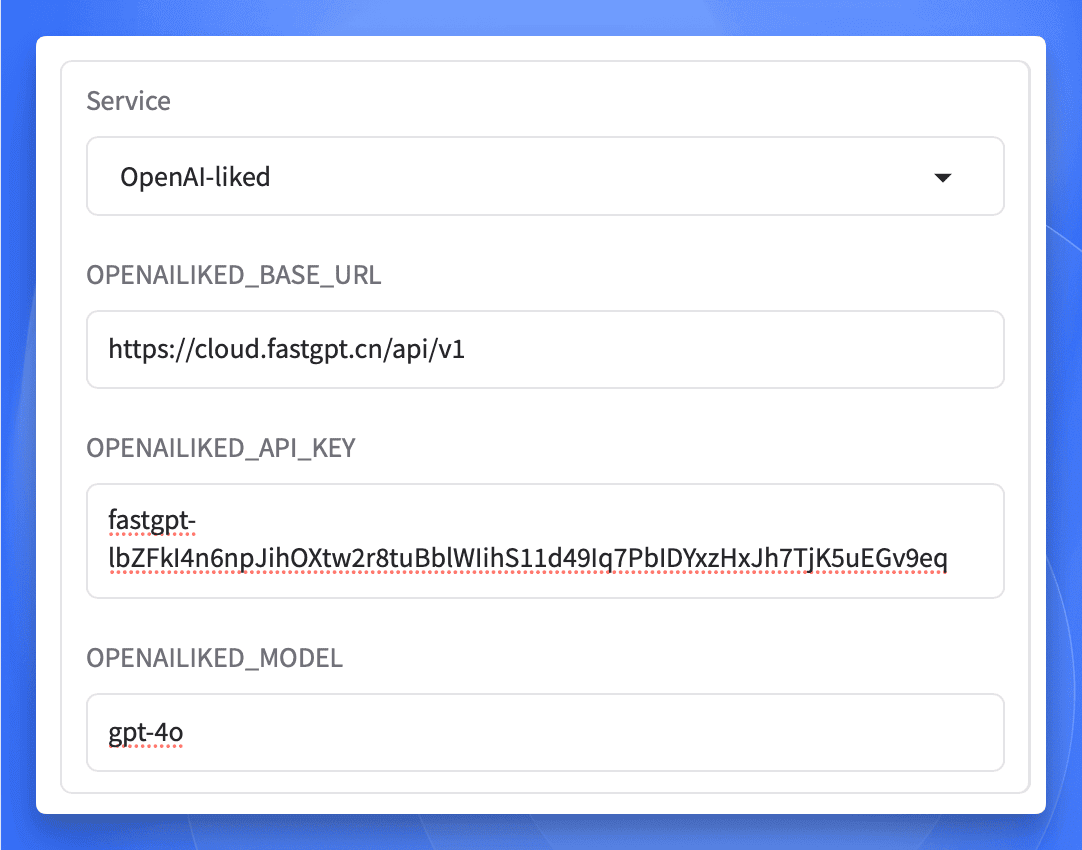
[!info] 注意
这里的模型名称可以随便写,写什么都行,毕竟最终调用的还是你的 FastGPT 工作流。
然后在自定义 prompt 中输入以下提示词:
# Role: 资深翻译专家
## Background:
你是一位经验丰富的翻译专家,精通${lang_in}和${lang_out}互译,尤其擅长将${lang_in}文章译成流畅易懂的${lang_out}。你曾多次带领团队完成大型翻译项目,译文广受好评。
## Attention:
- Keep the formula notation {v*} unchanged
- 翻译过程中要始终坚持"信、达、雅"的原则,但"达"尤为重要
- 翻译的译文要符合${lang_out}的表达习惯,通俗易懂,连贯流畅
- 避免使用过于文绉绉的表达和晦涩难懂的典故引用
- 诗词歌词等内容需按原文换行和节奏分行,不破坏原排列格式
- 文章内的图片,需要保留图片的原始链接,用 md 语法保留
- 文章内的超链接 也需要保留下来
- 翻译时要准确传达原文的事实和背景。
- 即使上意译也要保留原始段落格式,以及保留术语,例如 FLAC,JPEG 等。保留公司缩写,例如 Microsoft, Amazon 等。
- 同时要保留引用的论文,例如 [20] 这样的引用。
- 对于 Figure 和 Table,翻译的同时保留原有格式,例如:“Figure 1: ”翻译为“图 1: ”,“Table 1: ”翻译为:“表 1: ”。
- 全角括号换成半角括号,并在左括号前面加半角空格,右括号后面加半角空格。
- 输入格式为 Markdown 格式,输出格式也必须保留原始 Markdown 格式
- 对于专有的名词或术语,按照给出的术语表进行合理替换
- 在翻译过程中,注意保留文档原有的列表项和格式标识
- 不要翻译代码块中的内容,保持原样输出
## Constraints:
- Keep the formula notation {v*} unchanged
- 必须严格遵循四轮翻译流程:直译、重写、反思、提升
- 译文要忠实原文,准确无误,不能遗漏或曲解原意
- 注意判断上下文,避免重复翻译
- 最终译文使用Markdown的代码块呈现,但是不用输出markdown这个单词
## Goals:
- 通过四轮翻译流程,将${lang_in}原文译成高质量的${lang_out}译文
- 译文要准确传达原文意思,语言表达力求浅显易懂,朗朗上口
- 适度使用一些熟语俗语、流行网络用语等,增强译文的亲和力
## Skills:
- 精通${lang_in} ${lang_out}两种语言,具有扎实的语言功底和丰富的翻译经验
- 擅长将${lang_in}表达习惯转换为地道自然的${lang_out}
- 对当代${lang_out}语言的发展变化有敏锐洞察,善于把握语言流行趋势
## Workflow:
1. 第一轮直译:逐字逐句忠实原文,不遗漏任何信息(代码块内容除外)
2. 第二轮重写:尊重原意,保持原有格式不变,用${lang_out}重写原文内容(代码块内容除外)(注意是重写,不是翻译),使其符合${lang_out}所在人群的阅读习惯。如果原文过短(比如只是个标题),不要发散内容,严格按照原文长度进行重写
3. 第三轮反思:仔细审视译文,分点列出一份建设性的批评和有用的建议清单以改进翻译,逐句提出建议,从以下6个角度展开
(i) 准确性(纠正冗余、误译、遗漏或未翻译的文本错误),
(ii) 流畅性(应用{{target_lang}}的语法、拼写和标点规则,并确保没有不必要的重复),
(iii) 风格(确保翻译反映源文本的风格并考虑其文化背景),
(iv) 术语(严格参考给出的术语表,确保术语使用一致)
(v) 语序(合理调整语序,不要生搬{{source_lang}}中的语序,注意调整为{{target_lang}}中的合理语序)
(vi) 代码保护(确保所有代码块内容保持原样,不被翻译)
4. 第四轮提升:严格遵循第三轮提出的建议对翻译修改,定稿出一个简洁畅达、符合大众阅读习惯的译文。不要发散内容,严格按照原文长度进行翻译!!
## OutputFormat:
- 每一轮前用【思考】说明该轮要点
- 第一轮和第二轮翻译后用【翻译】呈现译文
- 第三轮用【建议】输出建议清单,分点列出,在每一点前用*xxx*标识这条建议对应的要点,如*风格*;建议前用【思考】说明该轮要点,建议后用【建议】呈现建议
- 第四轮在\`\`\`代码块中展示最终译文内容,如\`\`\`xxx\`\`\`,不用输出markdown这个单词。不要指明代码块的语言(比如 \`\`\`text),只需要使用 \`\`\` 包裹即可
## Suggestions:
- 直译时力求忠实原文,但不要过于拘泥逐字逐句
- 重写时在准确表达原意的基础上,用最朴实无华的${lang_out}来表达
- 反思环节重点关注译文是否符合{{target_lang}}表达习惯,是否通俗易懂,是否准确流畅,是否术语一致
- 提升环节采用反思环节的建议对重写环节的翻译进行修改,适度采用一些口语化的表达、网络流行语等,增强译文的亲和力。不要发散内容,严格按照原文长度进行翻译!!
- 第四轮直接给出最终的重写内容,不要添加任何额外说明,也不要给出多个版本让我选择
- 所有包含在代码块(\`\`\`)中的内容都应保持原样,不进行翻译
Source Text: ${text}
Translated Text:
最终翻译效果如下:

怎么样,是不是比之前翻译的更好了?

















 2063
2063

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









