







 超级会员免费看
超级会员免费看
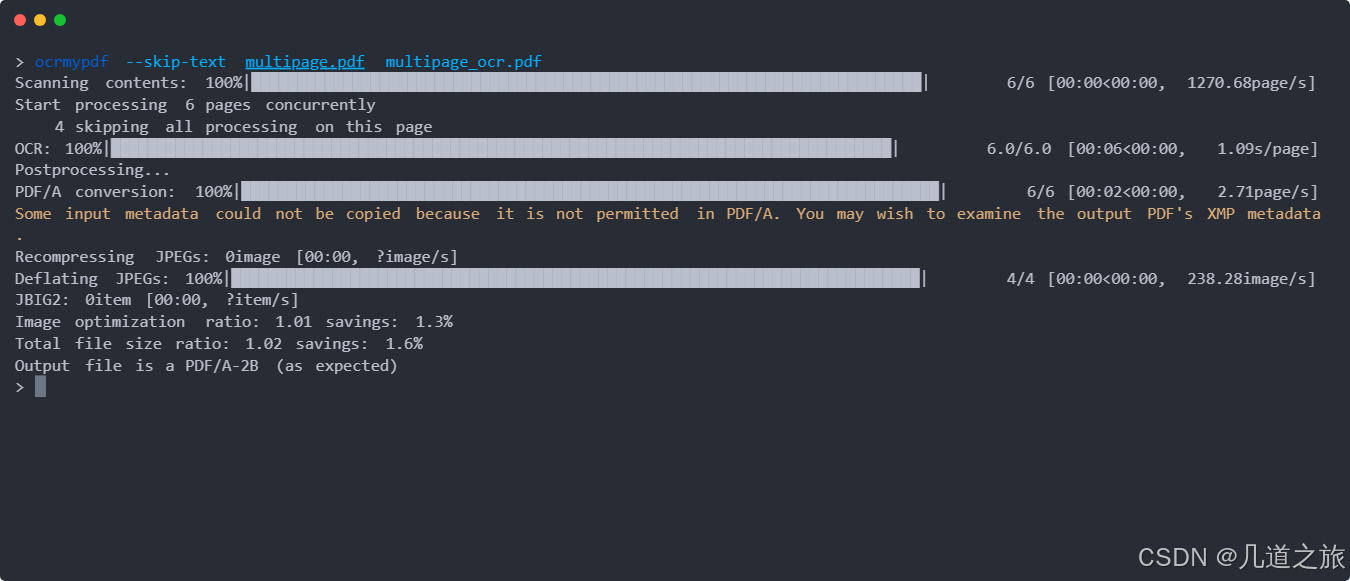
在数字化办公与知识管理的浪潮中,PDF文件因其格式稳定性被广泛使用。然而,扫描版PDF中的文字无法直接搜索或复制的问题,一直是用户的痛点。本文将介绍一款基于Tesseract OCR引擎的开源工具 OCRmyPDF,它通过添加OCR文本层,将扫描版PDF转化为可搜索、可编辑的智能文档,同时保留原始文件的完整性和质量。
一、OCRmyPDF的核心功能
-
OCR文本层嵌入
OCRmyPDF的核心功能是通过光学字符识别(OCR)技术,在扫描PDF的图像下方精准嵌入文本层。这使得用户既能保留原始图像的高分辨率,又能通过搜索或复制粘贴提取文字。例如,对于合同或历史文献的扫描件,OCRmyPDF可显著提升信息检索效率。 -
生成标准PDF/A格式
工具默认输出符合PDF/A标准的文件,专为长期存档设计,确保文档在未来仍可访问且格式不丢失。用户也可通过参数--output-type pdf生成普通PDF文件。 -
图像优化与预处理

 订阅专栏 解锁全文
订阅专栏 解锁全文



















 659
659

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











