







Problem Set 2
Camelcase

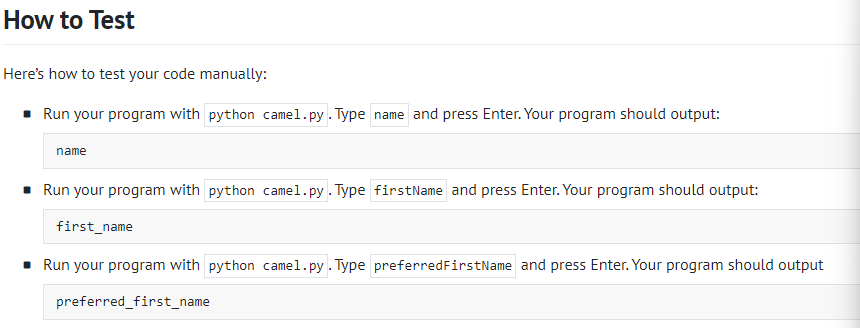
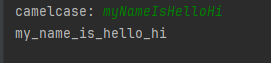
注意点:添加 _ 之后,会使得整体列表的数据和索引位置变化
def main():
camelcase = list(input("camelcase: "))
snakecase = change_to_snake_case(camelcase)
print(snakecase)
def change_to_snake_case(list_camel):
length = len(list_camel)
# 用于记录大写字母的位置
tmp = []
# 循环找出大写字母,并将大写字母转化成小写字母
# 记录下大写字母的位置,方便后续添加
for i in range(length):
if list_camel[i].isupper():
tmp.append(i)
list_camel[i] = list_camel[i].lower()
# 添加函数
add(tmp, list_camel)
return "".join(list_camel)
def add(list_tmp, list_camel):
# 用于记录前面添加了几个,添加几个后面的需要整体往后移动
count = 0
for index in list_tmp:
list_camel.insert(index + count, "_")
count += 1
return list_camel
if __name__ == '__main__':
main()
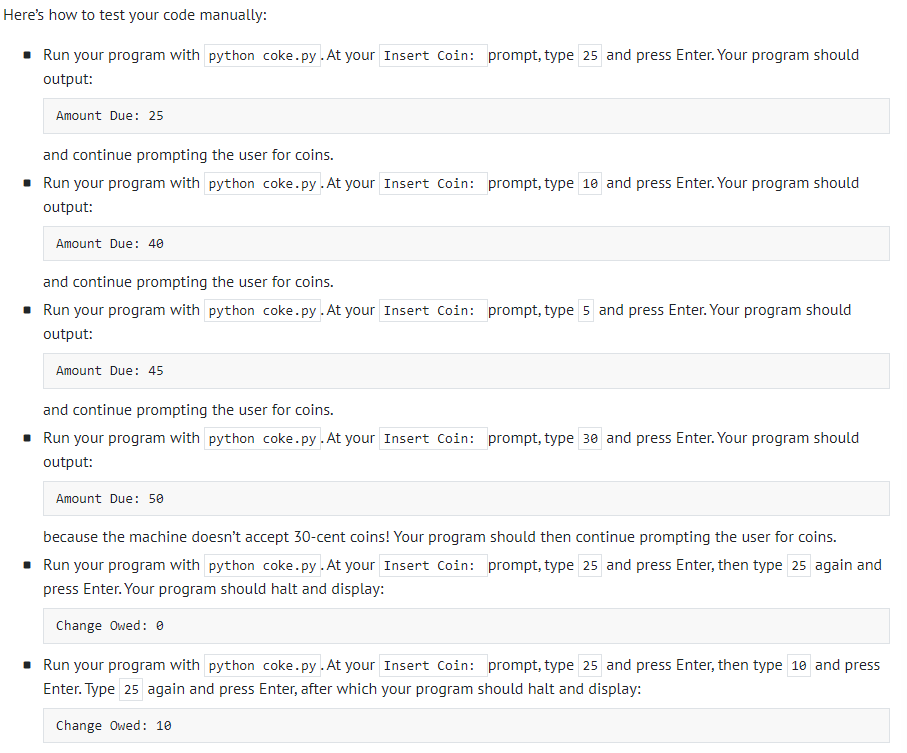
Coke Machine
def main():
# 总价格
price = 50
# 投入的硬币总量
amount = 0
# 投入硬币总量不足就一直循环
while amount < 50:
coin = int(input("Insert Coin: "))
# 计算投入硬币总量
amount = cal_amount(amount, coin)
# 还差多少
due = price - amount
# 投入多了需要找零
if due <= 0:
print(f"Change Owed: {-due}")
# 不够需要继续投入硬币
else:
print(f"Amount Due: {due}")
# 计算投入硬币总量
def cal_amount(total, coin):
# 投入的硬币符合要求
if coin == 25 or coin == 10 or coin == 5:
total += coin
return total
# 投入的硬币不符合要求则忽略
else:
return total
if __name__ == '__main__':
main()
Just setting up my twttr

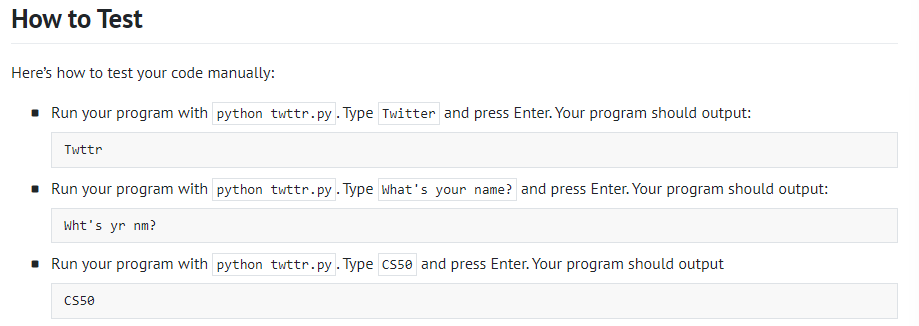
def main():
# 接受输入,并转化成列表
original = list(input("Input: "))
length = len(original)
# 存放要删除的元音字母
vowels = ["A", "E", "I", "O", "U", "a", "e", "i", "o", "u"]
# 记录 索引 的列表
record_list = []
for i in range(length):
if original[i] in vowels:
record_list.append(i)
# 通过记录的索引进行删除
result = del_vowel(record_list, original)
# 将列表还原成字符串
print("".join(result))
def del_vowel(record, original_list):
# 记录删除了几个,删除之后后面的索引需要变化
count = 0
for i in record:
# 通过索引进行删除
original_list.pop(i - count)
count += 1
return original_list
if __name__ == '__main__':
main()
Vanity Plates

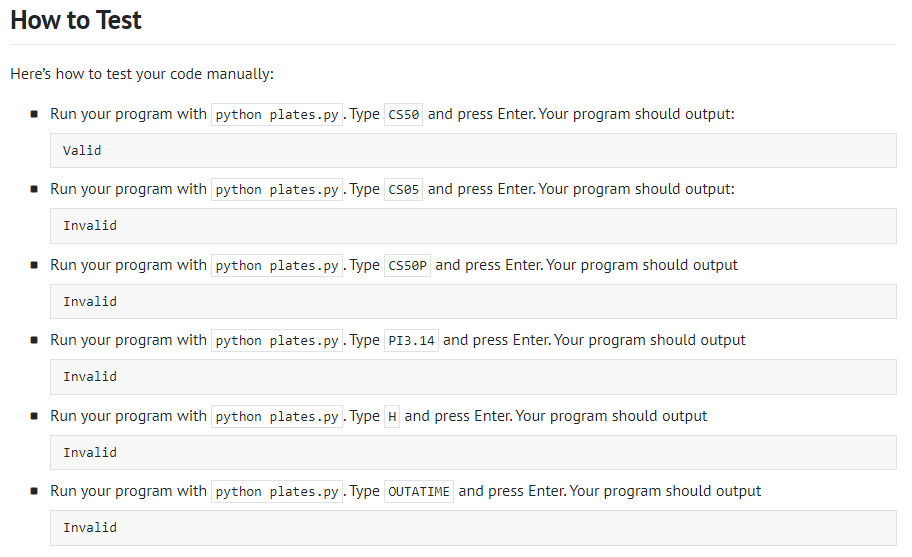
# 这里有个新的知识点需要注意
# 字符串切片操作
s[0:2] # s[0] s[1]
s[2:] # s[2] 到最后
# 即左闭右开
def main():
plate = input("Plate: ")
if is_valid(plate):
print("Valid")
else:
print("Invalid")
def is_valid(s):
length = len(s)
# 长度不符合
if length < 2 or length > 6:
return False
# 不是仅包含数字和字母
elif not s.isalnum():
return False
# 不是以两个字母开头
elif (not s[0].isalpha()) or (not s[1].isalpha()):
return False
# 再讨论后面 4 位
subs = s[2:]
# 每一位都是两种情况:字母或者非零数字
# 第一位为非零数字,且后面都必须是数字
if subs.isnumeric() and subs[0] != "0":
return True
# 第一位是字母,第二位为非零数字且后面全都是数字
elif subs[0].isalpha() and subs[1:].isnumeric() and subs[1] != "0":
return True
# 第一、二位是字母,第三位为非零数字且后面全都是数字
elif subs[0:2].isalpha() and subs[2:].isnumeric() and subs[2] != "0":
return True
# 第一、二、三位是字母,第四位是字母或者,第四位是非零数字
# 第四位是字母
elif subs.isalpha():
return True
# 第四位是数字
elif subs[0:3].isalpha() and subs[3].isnumeric() and subs[3] != "0":
return True
else:
return False
if __name__ == '__main__':
main()
Nutrition Facts

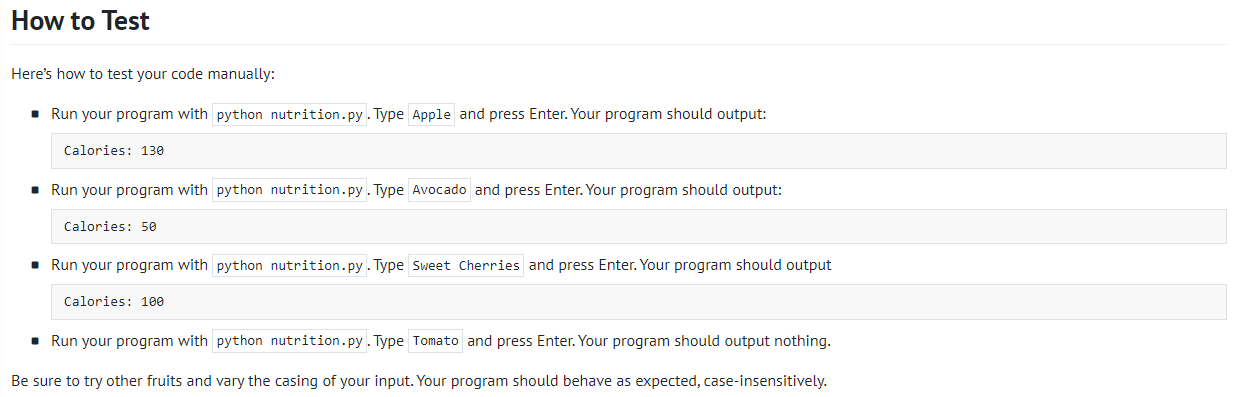
def main():
# 接收输入
fruit = input("Item: ")
# 将输入全部转化成小写,方便后续判断
check_calories(fruit.lower())
def check_calories(fruit):
# 字典类型存放数据
calories = {
"apple": 130,
"avocado": 50,
"banana": 110,
"cantaloupe": 50,
"grapefruit": 60,
"grapes": 90,
"honeydew": 50,
"kiwifruit": 90,
"lemon": 15,
"lime": 20,
"nectarine": 60,
"orange": 80,
"peach": 60,
"pear": 100,
"pineapple": 50,
"plums": 70,
"strawberries": 50,
"sweet cherries": 100,
"tangerine": 50,
"watermelon": 80
}
# 循环判断输入的键是否在字典中
for i in calories.keys():
# 找到之后直接跳出循环,结束函数
if i == fruit:
print(f"Calories: {calories[i]}")
break
if __name__ == '__main__':
main()















 1222
1222











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









