







第 8 章 文件与文件系统的压缩
8.1 压缩文件的用途与技术
压缩比:压缩后与压缩的文件所占用的磁盘空间大小
8.2 Linux 系统常见的压缩命令
常见的压缩文件扩展名:
| 压缩文件扩展名 | 压缩方式 |
|---|---|
| *.z | compress 程序压缩的文件 |
| *.zip | zip 程序压缩的文件 |
| *.gz | gzip 程序压缩的文件 |
| *.bz2 | bzip2 程序压缩的文件 |
| *.xz | xz 程序压缩的文件 |
| *.tar | tar 程序打包的文件,并没有压缩过 |
| *.tar.gz | tar 程序打包的文件,并且经过 gzip 的压缩 |
| *.tar.bz2 | tar 程序打包的文件,并且经过 bzip2 的压缩 |
| *.tar.xz | tar 程序打包的文件,并且经过 xz的压缩 |
8.2.1 gzip,zcat/zmore/zless/zgrep
gzip 可以说是应用最广的压缩命令,目前 gzp 可以解开 compress、zip 与 gzip 等软件所压缩的文件。
语法:
gzip [-cdtv#] 文件名
zcat 文件名.gz
选项与参数:
-c:将压缩数据输出到屏幕上,可通过数据流重定向来处理
-d:解压缩的参数
-t:可以用来检验一个压缩文件的一致性,看看文件有无错误
-v:可以显示出原文件/压缩文件的压缩比信息
-#:# 为数字的意思,代表压缩等级,-1 最快,但压缩比最差,-9 最慢,但是压缩比最好,默认为6
范例一:找出 /etc 下面(不含子目录)容量最大的文件,并将它复制到 /tmp,然后 gzip 压缩
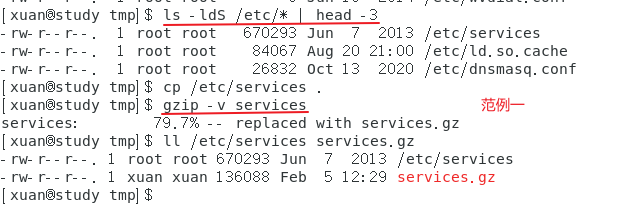
当使用 gzip 压缩时,在默认的状态下,原本的文件会被压缩成 .gz 后缀的文件,源文件就不再存在了。此外,使用 gzip 压缩的文件在 windows 系统中,可以被 winrar 或 7zip 这些软件解压缩。
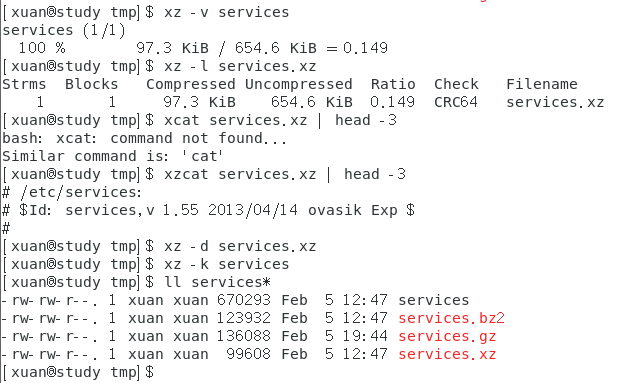
范例二:由于 services 是文本文件,请将范例一的压缩文件内容读出来
# 此时屏幕上会显示 services.gz 解压缩之后的原始文件内容
zcat/zmore/zless services.gz
范例三:将范例一的文件解压缩
gzip -d services.gz
# 与 gzip 相反,gzip -d 会将原本的压缩文件删除,恢复到原本的文件
范例四:将范例三解开的文件用最佳压缩比压缩,并保留原文件
gzip -9 -c services > services.gz
范例五:由范例四再次建立的压缩文件中,找出 http 这个关键词在哪几行
zgrep -n 'http' services.gz
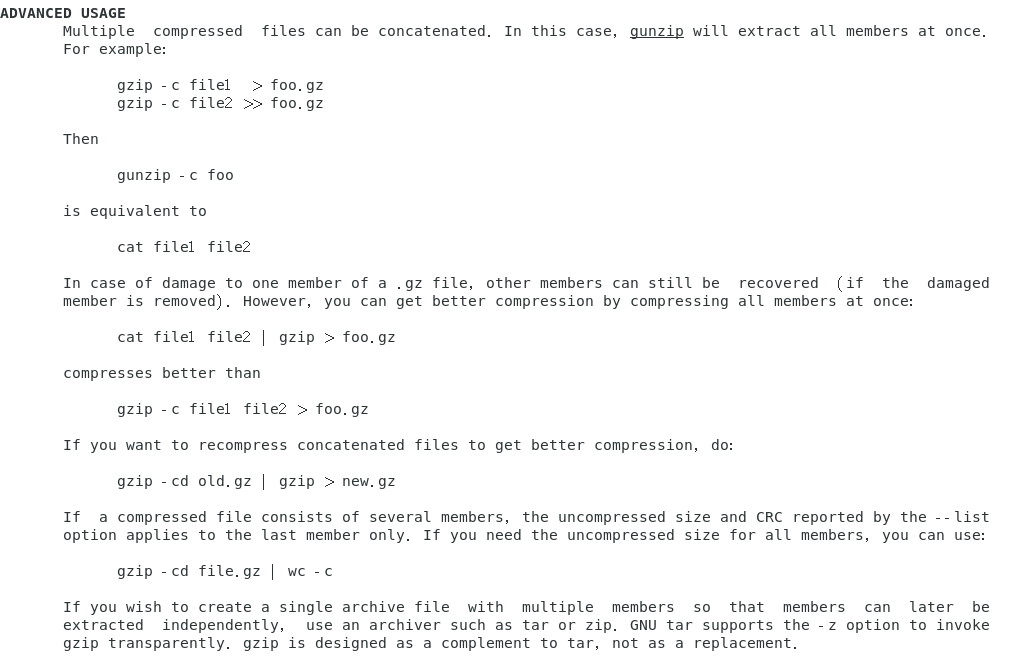
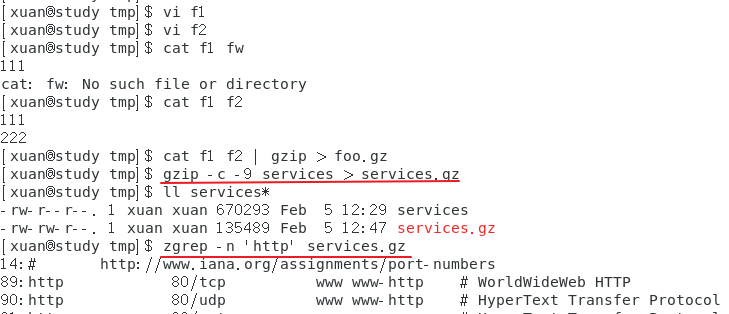
范例四的重点在 【-c】 与 【>】 的应用,【-c】 可以将原本要转成压缩文件的数据内容,将它变成文字类型从屏幕输出,然后我们可以通过【>】这个符号,将原本应该由屏幕输出的数据,转成输出到文件而不是屏幕,所以就能够建立起压缩文件了,只是文件名还是需要自己起,当然最好还是遵循 gzip 的压缩文件名要求较佳。
至于 zcat/zmore/zless 则可以对应于 cat/more/less 的方式来读取纯文本文件被压缩后的压缩文件;zgrep 可以直接从文字压缩文件中找数据,而不需要解压缩
8.2.2 bzip2,bzcat/bzmor/bzless/bzgrep
bzip2 是为了替换 gzip 并提供更佳的压缩比而来,用法基本和 gzip 一致:
语法:
bzip2 [-cdkzv#] 文件名
bzcat 文件名.bz2
选项与参数:
-c:将压缩数据输出到屏幕上,可通过数据流重定向来处理
-d:解压缩的参数
-k:保留原始文件,而不会删除原文件
-z:压缩的参数(默认值,可以不加)
-v:可以显示出原文件/压缩文件的压缩比信息
-#:# 为数字的意思,代表压缩等级,-1 最快,但压缩比最差,-9 最慢,但是压缩比最好,默认为6
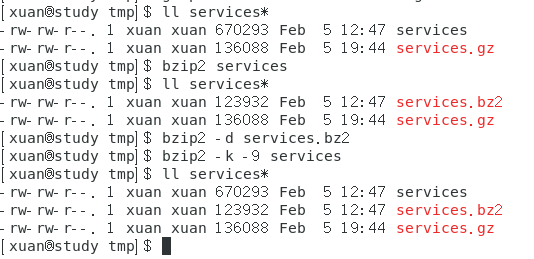
范例一:将上面复制的 /tmp/services 以 bzip2 方式压缩
范例二:将范例一的文件读出来
bzcat services.bz2
范例三:解压缩
范例四:将上述文件用最佳压缩比压缩,并保留原本文件
8.2.3 xz,xzcat/xzmore/xzless/xzgrep
语法:
xz [-cdkzv#] 文件名
xzcat 文件名.xz
选项与参数:
-c:将压缩数据输出到屏幕上,可通过数据流重定向来处理
-d:解压缩的参数
-t:可以用来检验一个压缩文件的一致性,看看文件有无错误
-k:保留原始文件,而不会删除原文件
-l:列出压缩文件的相关信息
-v:可以显示出原文件/压缩文件的压缩比信息
-#:# 为数字的意思,代表压缩等级,-1 最快,但压缩比最差,-9 最慢,但是压缩比最好,默认为6
范例一:压缩
范例二:列出压缩文件的信息,然后读取内容
范例三:解压缩
范例四:保留原文件的文件名,并建立压缩文件
8.3 打包命令:tar
前面提到的命令也可以对目录压缩,不过,这两个命令对目录的压缩指的是将目录内的所有文件【分别】进行压缩的操作。
这种将多个文件或目录包成一个大文件的命令功能,我们可以称它是一种打包命令。在 Linux 中的打包命令就是 tar,tar 可以将多个目录或文件打包成一个大文件,同时还可以通过 gzip、bzip2、xz 的支持,将文件同时进行压缩。
tar 的选项和参数非常多,这里只讲几个常用的选项:
语法:
打包与压缩:tar [-z|-j|-J] [cv] [-f 待建立的新文件名] filename
查看文件名:tar [-z|-j|-J] [tv] [-f 既有的 tar文件名]
解压缩:tar [-z|-j|-J] [xv] [-f 既有的 tar文件名] [-C 目录]
选项与参数:
-c:建立打包文件,看搭配 -v 来查看过程中被打包的文件名
-t:查看打包文件的内容含有哪些文件名,重点在查看文件名
-x:解包或解压缩的功能,可搭配 -C 在指定目录解压
注意:-c -t -x 不可能同时出现在同一命令行中
-z:通过 gzip 的支持进行压缩/解压缩,文件名最好为 *.tar.gz
-j:通过 bzip2 的支持进行压缩/解压缩,文件名最好为 *.tar.bz2
-J:通过 xz 的支持进行压缩/解压缩,文件名最好为 *.tar.xz
注意:-z -j -J 不可能同时出现在同一命令行中
-v:在压缩/解压缩的过程中,将正在处理的文件名显示出来
-f filename:-f 后面要立刻接要被处理的文件名,建议 -f 单独写一个选项
-C 目录:这个可以解压缩到指定的目录
后续练习会使用到的选项介绍:
-p(小写):保留备份数据的原本权限与属性,常用于备份重要的配置文件
-P(大写):保留绝对路径,即允许备份数据中含有根目录存在
--exclude=FILE:在压缩过程中,不要将 FILE 打包
其实最简单的使用 tar 就只要记住下面的命令即可:
- 压缩:tar -jcv -f filename.tar.bz2 要被压缩的文件或目录名称
- 查询:tar -jtv -f filename.tar.bz2
- 接压缩:tar -jxv -f filename.tar.bz2 -C 欲解压的目录
其中 filename.tar.bz2 是我们自己取的文件名,tar 并不会主动的产生建立的文件名,需要自定义,这时扩展名就显得很重要。如果不加 [-z|-j|-J] 的话,文件名最好为 *.tar 即可。如果是 -z 选项,代表有 gzip 的支持,因此文件名最好取为 *.tar.gz。
另外,由于 【-f filename】是紧接在一起的,过去很多文章会写成【-jcvf filename】,这样是没错的,但由于选项的顺序理论上是可以变换的,所以很多读者会误认为 【-jvfc filename】也可以,事实上这样会导致产生的文件名变为 c。
-
使用 tar 备份 /etc 目录
命令如下:
time tar -zcvp -f /root/etc.tar.gz /etc time tar -jcvp -f /root/etc.tar.bz2 /etc time tar -Jcvp -f /root/etc.tar.xz /etc



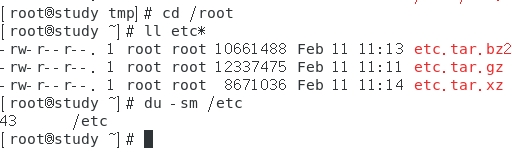
这个文件的大小只有【43MB】,在使用 xz 压缩时就已经花费了 29 s,所以如果备份数据很大,就需要考虑一下时间成本才行。
加上【-p】这个选项的原因是为了保存原本文件的权限和属性
-
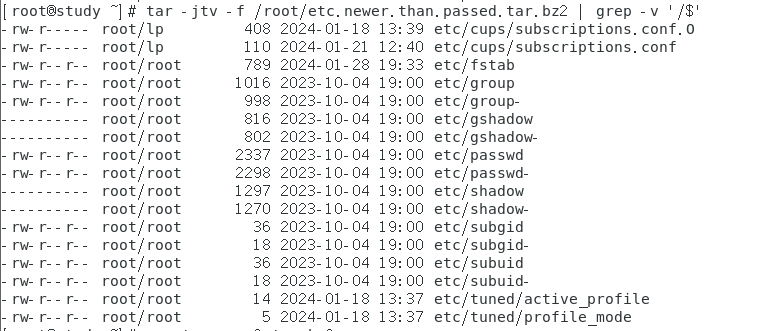
查看 tar 文件的数据内容,与备份文件名是否有根目录的意义
命令如下:
tar -jtv -f etc.gz.bz2
如果加上 -v 选项时,详细的文件权限/属性会被列出来,如果只想要知道文件名而已,那么将 -v 拿掉即可。
通过观察红框里的内容,我们发现每个文件名都没了根目录,也就是上面出现的报错信息【tar: Removing leading `/’ from member names(删除了文件名开头的 ‘/’)】所告知的情况。
那么为什么要去掉根目录呢?主要是为了安全。我们使用 tar 备份的数据可能需要解压缩回来使用,那么在 tar 所记录的文件名就是解压缩后的实际文件名。如果拿掉了根目录,那么在 /tmp 解开,解压缩的文件名就会变成【/tmp/etc/xxx】。但如果没有去掉根目录,解压缩后的文件名就会是绝对路径,即解压缩后的数据一定会被放置到【/etc/xxx】去,如此一来,原来的数据就会被覆盖掉。
如果确实需要备份根目录,那么使用 -P 这个选项:
备份:tar -jcvpP -f /root/etc.and.root.tar.bz2 .etc 查看:tar -jt -f etc.and.root.tar.bz2
-
将备份的数据解压缩,并考虑特定目录的解压缩操作
命令如下:
tar -jxv -f /root/etc.tar.bz2这个命令会把 xxx.bz2 这个文件解压缩到当前的目录下,如果需要把文件解压到指定目录?
tar -jxv -f /root/etc.tar.bz2 -C /tmp -
仅解开单一文件
刚刚上面解压缩的是整个打包文件,如果只是想解开其中的一个文件,那该如何做呢?
- 通过 -t 选项找到需要解压的文件名
- 正常解压缩的语法 + 待解开的文件名
范例:解开其中的 shadow 文件

-
打包某个目录,但不包含该目录下的某些文件之做法
假设我们想要打包 /etc /root 这几个重要目录,但不想要打包 /root/etc* 开头的文件,因为该文件是刚刚建立的备份文件。而且假设这个新打包的文件要放置成为 /root/system.tar.bz2 ,当然这个文件自己不要打包自己(因为这个文件放置在 /root 下面),此时我们可以通过 --exclude 这个选项帮忙,意思是不包含后面的文件:
tar -jcv -f /root/system.tar.bz2 --exclude=/root/etc* --exclude=/root/system.tar.bz2 \ > /etc /root
-
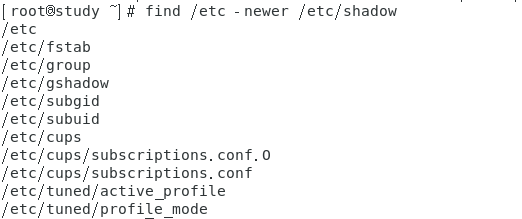
仅备份比某个时刻还要新的文件
【–newer】选项包含 ctime mtime;【–newer-mtime】仅是 mtime


步骤如下:
- 先由 find 找出比 /etc/passed 还要新的文件
- 用 tar 进行打包
- 显示出文件即可

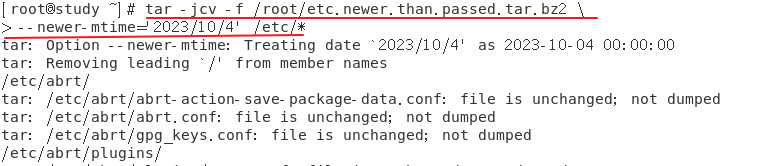
-
基本名称:tarfile、tarball
- 如果是仅打包,【tar -cv -f file.tar】,这个文件称为 tarfile
- 如果还有进行压缩支持,【tar -jcv -f file.tar.bz2】,这个文件称 tarball
此外,tar 除了可以将数据打包成文件之外 ,还能够将文件打包到某些特别的设备中,例如磁带。这里不能使用 cp 命令,要使用【tar -cv -f /dev/st0 /home /root /etc】
-
特殊应用:利用管道命令和数据流
在 tar 的使用中,有一种方式最特殊,那就是通过标准输入输出的数据流重定向,以及管道命令的方式,将待处理的文件一边打包一边解压缩到指定目录
范例:将 /etc 整个目录一边打包一边在 /tmp 解开 tar -cvf - /etc | tar -xvf -上述命令的注意点:
- 输出文件变成 - 而输入文件也变成 - ,还有一个 | 存在;这分别代表标准输出、标准输入与管道命令
- 可以将 - 想成是内存中的一个设备,即缓冲区
- 这个操作有点像是 cp -r 的命令,但若是觉得复制命令麻烦则可以使用这个;同时又不想让中间文件存在
-
例题:系统备份范例
假设目前已只重要的需要备份的目录如下:
- /etc:配置文件
- /home:用户的家目录
- /var/spool/mail:系统中所有账号的邮箱
- /var/spool/cron:所有账号的定时任务配置文件
- /root:系统管理员的家目录
要求:/home/loop* 不需要备份,/root 下的压缩文件也不需要备份,备份文件放置在 /backpus 文件夹中,该文件夹仅有 root 用户可以访问。此外,每次备份的文件名希望不同,例如:backup-system-20220114.tar.bz2 之类的文件名来处理。
创建目录及修改权限: mkdir /backups chmod 744 /backups 备份命令: tar -jcv --exclude=/home/loop* --exclude=/root/etc* --exclude=system.tar* \ -f /backups/backup-system-20240215.tar.bz2 \ /etc /home /root /var/spool/mail /var/spool/cron
-
解压缩后的 SELinux 问题
如果因为某些缘故,必须要以备份的数据来恢复到原本的系统中,那么要特别注意恢复后,系统的 SELinux 问题,尤其是在系统文件上面。详细的介绍会在第 16 章学习,在这里,需要先知道,SELinux 的权限问题可能会让你的系统无法读写某些配置文件的内容,导致影响系统无法正确使用
那如何处理呢?简单的处理方式有这几个:
- 通过各种可行的恢复方式登录系统,然后修改 /etc/selinux/config 文件,将 SELinux 改成 permission 模式,重新启动
- 在第一次恢复系统后,不要立即重新启动,先使用 restorecon -Rv /etc 自动修复一下 SELinux 的类型即可
- 通过各种可行的恢复方式登录系统,建立 ./autorelabel 文件,重新启动后系统会自动修复 SELinux 的类型,并且又会再次重新启动,之后就正常了
注意:首选第二种,次选第三种
8.4 XFS 文件系统的备份与还原
使用 tar 通常是针对目录树系统来进行备份的工作,那么如果想要针对整个文件系统来进行备份与还原?
8.4.1 XFS 文件系统备份 xfsdump
xfsdump 除了可以进行文件系统的完整备份之外,还可以进行增量备份。
增量备份:假设对一个文件系统第一次使用 xfsdump 进行完整备份后,等过一段时间的文件系统自然允许后,再进行第二次 xfsdump 时,就可以选择增量备份。此时新备份的数据只会记录与第一次完整备份所有差异的文件而已。
==对于 xfsdump 备份的数据,第一次备份一定是完整备份,完整备份在 xfsdump 中被定义为 level 0。==至于各个 level 记录的文件则放置于 /var/lib/xfsdump/inventory 中
另外,使用 xfsdump 备份时,请注意下面的限制:
- xfsdump 不支持没有挂载的文件系统的备份,所以只能备份已挂载的文件系统
- xfsdump 必须使用 root 权限才能操作
- xfsdump 只能备份 xfs 文件系统
- xfsdump 备份下来的数据只能让 xfsrestore 解析
- xfsdump 是通过文件系统的 UUID 来辨别各备份文件,因此不能备份两个具有相同 UUID 的文件系统
简单使用 xfsdump 选项如下:
语法:
xfsdump [-L S_label] [-M M_label] [-l #] [-f 备份文件] 待备份数据
xfsdump -I
选项与参数:
-L:记录每次备份的 session 标头,这里可以填写针对此文件系统的简易说明
-M:可以记录存储媒介的标头,这里可以填写此媒介的简易说明
-l:指定等级,有 0~9 共10个等级(默认为 0,即完整备份)
-f:后面接产生的文件,亦可接例如 /dev/st0 设备文件名或其他一般文件名
-I:从 /var/lib/xfsdump/inventory 列出目前备份的信息状态
特别注意,xfsdump 默认仅支持文件系统的备份,并不支持特定目录的备份,所以不能用 xfsdump 去备份 /etc,因为 /etc 从来就不是一个独立的文件系统
-
用 xfsdump 备份完整的文件系统
范例:对文件系统 /boot 进行备份操作
步骤一,需要先确认 /boot 是独立的文件系统

步骤二,将完整备份的文件名记录为 /srv/boot.dump
使用命令时可以不加 -L 或者 -M 参数,只是会进入交互模式
而执行 xfsdump 的过程中会出现如下信息,需要注意观察
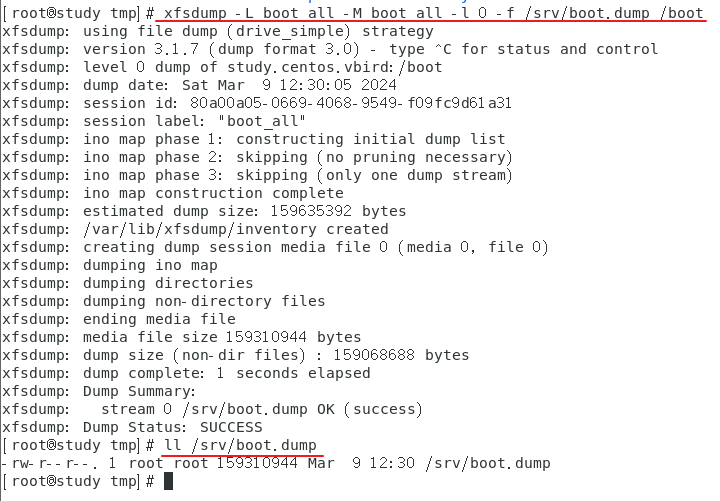
在使用了 xfsdump 之后才会有下面的文件产生,准备让下次备份时可以作为一个参考依据

-
用 xfsdump 进行增量备份
一定要经过完整备份后才能够继续有其他增量备份的能力
步骤零,看一下有没有任何文件系统被 xfsdump 备份过的数据
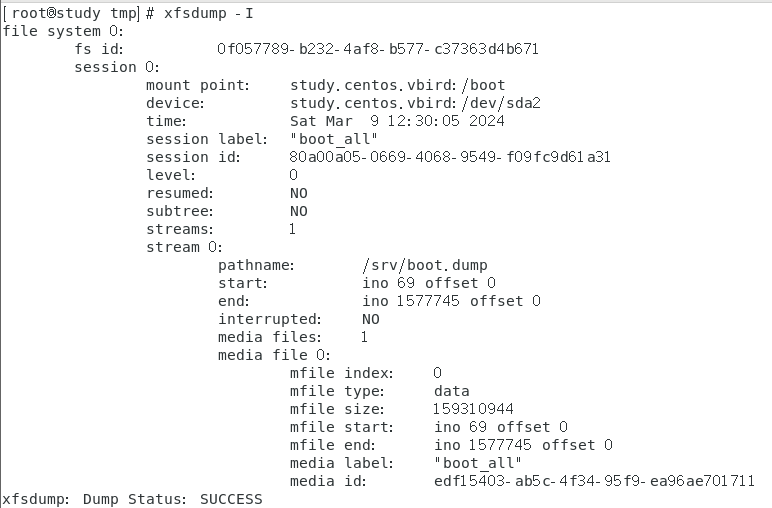
步骤一,建立一个大约 10MB 的文件在 /boot 内

步骤二,开始建立差异备份文件,此时使用 level 1,文件大小差不多是刚才建立文件的大小


步骤三,查看备份记录是否有 level 1
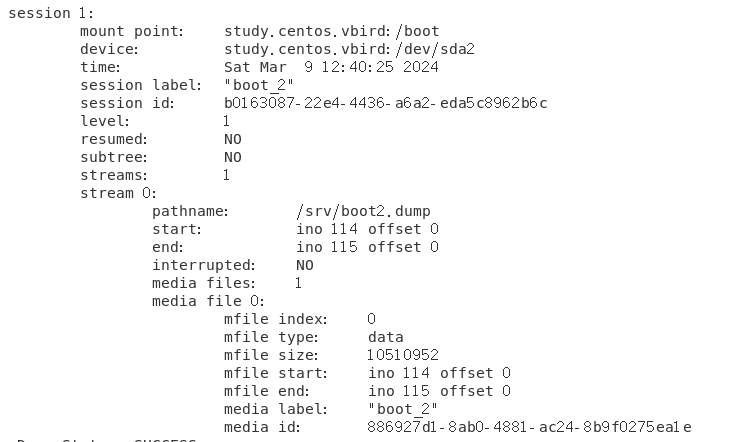
通过这个简单的方法,就可以仅备份差异文件的部分
8.4.2 XFS 文件系统还原 xfsrestore
xfsdump 的恢复使用的是 xfsstore 这个命令,这个命令的选项也很多,可以自行使用 man 查看,这里仅做一些简单介绍:
语法:
xfsrestore -I
单一文件全系统恢复:xfsrestore [-f 备份文件] [-L S_label] [-s] 待恢复的目录
通过增量备份文件来恢复系统:xfsrestore [-f 备份文件] -r 待恢复目录
进入交互模式:xfsrestore [-f 备份文件] -i 待恢复目录
选项与参数:
-I:可查询备份数据
-f:后面接备份文件
-L:就是 session 的 Label name,可以用 -I 查到的数据,在这个选项后输入
-s:需要接某特定目录,即仅恢复某一个文件或目录之意
-r:如果用文件来存储备份数据,则不需要使用,如果一个磁带内有多个文件,需要此选项来完成累积恢复
-i:进入交互模式,高级管理员使用
-
用 xfsrestore 观察 xfsdump 后的备份数据内容
由于 xfsresore 与 xfsdump 都会到 /var/lib/xfsdump/inventory 里面去取数据来显示,因此两者的输出是相同的
需要注意中间的 session label
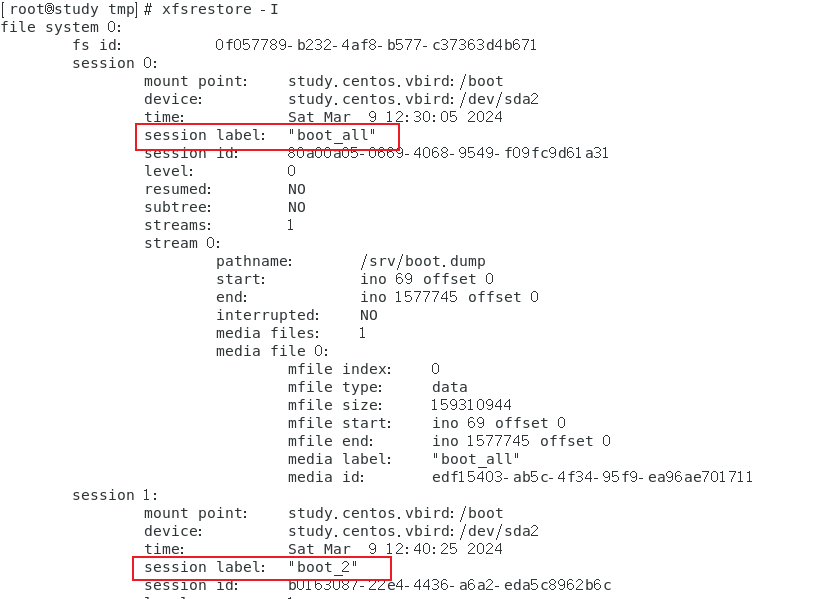
这个文件查找出到底哪个文件是挂载点?而该备份文件又是什么 level 等内容
-
简单恢复 level 0 的文件系统
-
直接将数据给覆盖回去即可
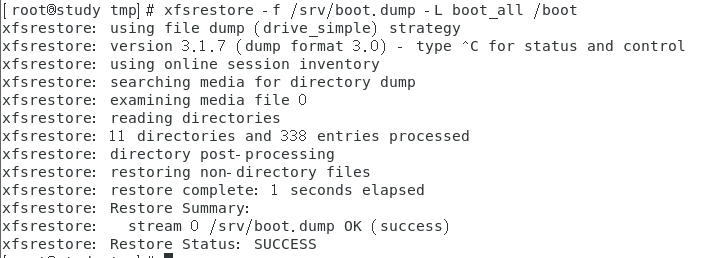
-
将备份数据在 /tmp/boot 下面解开
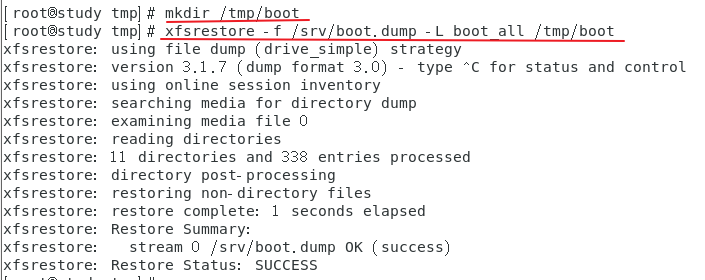

查看两个还原大小发现不一致?

**解释:**因为原本 /boot 里面的东西没有删除,直接恢复的结果就是:同名的文件会被覆盖,其他系统内的新文件会被保留。如果备份的目的地是新的位置,当然就只有原本备份的数据而已
-
仅恢复备份文件内的 grub2 到 /tmp/boot2 中去
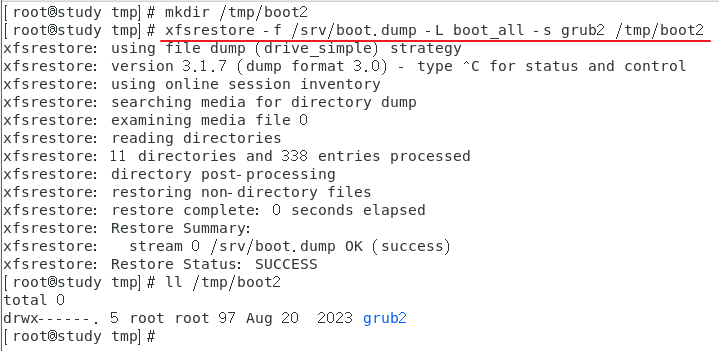
-
-
恢复增量备份数据
范例:继续恢复 level 1 到 /tmp/boot 中
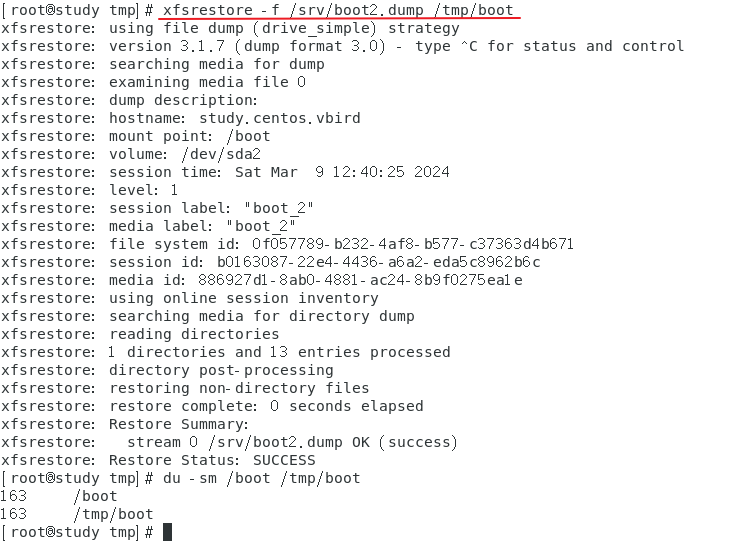
-
仅还原部分文件的 xfsrestore 交互模式
刚刚的 -s 可以接部分数据来还原,但是,如果我根本不知道备份文件里面还有啥文件,那该如何操作?可以使用 -i 交互模式
范例:先进入备份文件中,准备找出需要备份的文件,同时预计还原到 /tmp/boot3 中
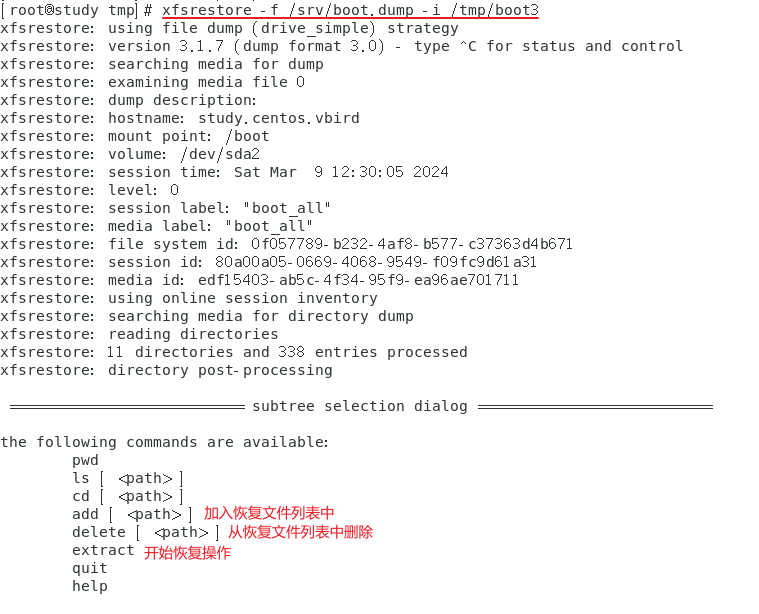
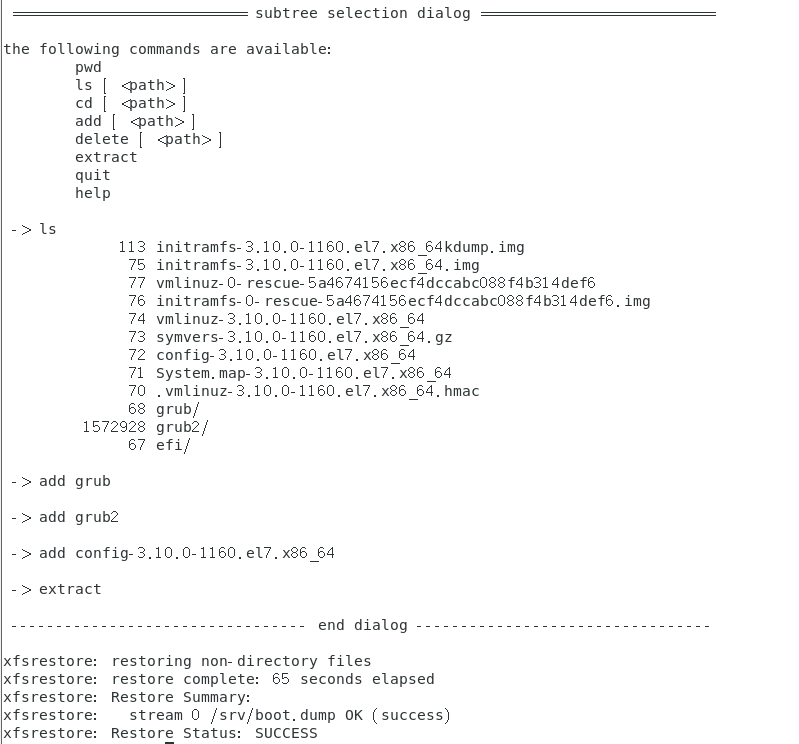
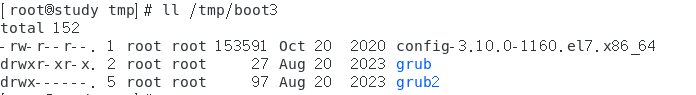
8.5 光盘写入工具
8.5.1 mkisofs:建立镜像文件
-
制作一般数据光盘镜像文件
语法: mkisofs [-o 镜像文件] [-Jrv] [-V vol] [-m file] 待备份文件... -graft-point isodir=systemdir... 选项与参数: -o:后面接想要产生的镜像文件 -J:产生较兼容 Windows 的文件名结构,可增加文件名长度到 64 个 unicode 字符 -r:通过 Rock Ridge 产生支持 UNIX/Linux 的文件数据,可记录较多的信息 -v:通过创建 ISO 文件的过程 -V vol:建立 Volume,有点像 Windows 在资源管理器内看到的 CD 卷标 -m file:排除文件,后面的文件不备份到镜像文件中,也能使用 * 通配符 -graft-point:移植目录光盘的格式一般称为 iso9660,这种格式一般仅支持旧版的 DOS 文件名,如果加上 -r 选项之后,文件信息能够被记录的比较完整
一般默认的情况下,所有要被加到镜像文件中的文件都会被放置到镜像文件中的根目录,会造成文件分类不易的情况。这种情况,可以使用 -graft-point 这个选项,可以使用如下方法:
- 镜像文件中的目录所在等于实际 Linux 文件系统的目录所在
- /movies/=/srv/movies/(在 Linux 的 /srv/movies 内的文件,加至镜像文件中的 /movies 目录)
- /linux/etc=/etc(在 Linux 的 /etc 内的所有数据备份到镜像文件中的 /linux/etc 目录)
范例:将 /root /home /etc 等目录的数据制作成镜像文件,不使用 -graft-point 选项
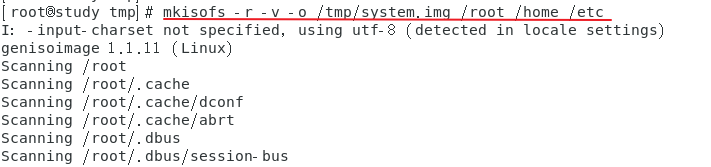
将镜像文件挂载起来,查看里面的文件内容
mount -o loop /tmp/system.img /mnt
由上面范例可以看到,三个目录的数据通通放到了镜像文件的最顶层目录中,不合理,改进写法如下:
mkisofs -V 'Linux-file' -r -o /tmp/system.img -m /root/etc -graft-point /root=/root /home=/home /etc=/etc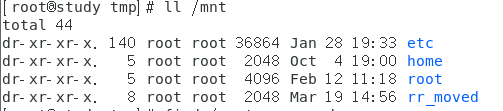
再或者是将要制作的数据内容预处理到其中一个目录,再刻录该目录即可。
-
制作/修改可启动光盘镜像文件
8.6 其他常见的压缩与备份工具
8.6.1 dd
这个命令的作用不只是制作一个文件,最大的功能应该是在于备份,因为 dd 可以读取磁盘设备的内容(几乎是直接读取扇区),然后将整个设备备份成一个文件,该命令的用途还有很多,下面只介绍重要的选项:
语法:
dd if="input_file" of="output_file" bs="block_size" count="number"
选项与参数:
if:就是 input file,也可以是一个设备
of:就是 output file,也可以是一个设备
bs:设置的一个 block 的大小,若未指定则默认是 512 Bytes,即一个扇区的大小
count:多少个 bs 的意思
范例一:将 /etc/passwd 备份到 /tmp/passwd.back 当中
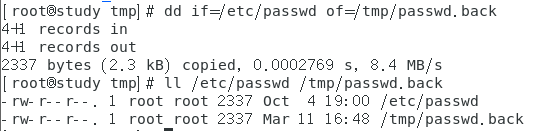
仔细观察一下,我的 /etc/passwd 的大小为 2337 Bytes,因为我没有设置 bs 的大小,所以是默认的 512 Bytes 为一个单位,因此,上面的 4+1 表示有 4 个完整的 512 Bytes,以及未满 512 Bytes 的另一个 block 的意思,事实上,这个命令的用法感觉好像是 cp 命令
范例三:假设你的 USB 是 /dev/sda ,将镜像文件刻录到U盘上面
dd if=/tmp/system.iso of=/dev/sda
如果不想要使用 DVD 来作为启动设备,那就可以将镜像文件使用这个 dd 写入磁盘,该磁盘就会变成更可启动光盘一样的功能,可以让你用 U 盘来安装 Linux,速度块很多
范例四:将你的 /boot 整个文件系统通过 dd 备份下来
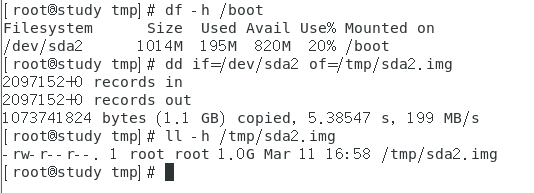
默认 dd 是一个一个扇区去读写,而且即使没有用到的扇区也会写到备份文件中,因此这个文件就会变得和原本的磁盘一模一样大,不像使用 xfsdump 只备份文件系统中使用到的部分。不过,dd 就是因为不理会文件系统,单纯有啥记录啥,所以不论该磁盘内的文件系统你是否识别,它都可以备份、还原。
例题
如果想要将 /dev/vda2 完整地复制到另一个硬盘分区上,使用系统上未划分完毕的容量再建立一个与 /dev/vda2 差不多大小的分区,然后将之进行完整的复制。(这里例题使用的是另一个 U 盘)
1. 先进行分区操作
fdisk /dev/sda
2. 不需要格式化,直接进行 sector 表面的复制
dd if=/dev/vda2 of=/dev/sda1
# 清楚 log
xfs_repair -L /dev/sda1
# 生成一个新的 UUID,因为 xfs 文件系统主要使用 UUID 来识别文件系统,但我们使用 dd 复制,连 UUID 也都复制成相同的
uuidgen
xfs_admin -U 新的UUID
8.6.2 cpio
这个命令 cpio 可以备份任何东西,包括设备文件,不过 cpio 不会主动地去找文件来备份。一般来说,需要配合类似 find 等可以查找文件的命令来告知 cpio 该被备份的数据文件在哪里。
语法:
备份:cpio -ovcB > [file/device]
还原:cpio -ivcdu < [file/device]
查看:cpio -ivct < [file/device]
备份会使用到的选项与参数:
-o:将数据复制输出到文件设备上
-B:让默认的 blocks 可以增加至 5120 字节,默认是 512 字节。这样做得好处是可以让大文件的存储速度 加快
还原会使用到的选项与参数:
-i:将数据自文件或设备复制出来到系统当中
-d:自动建立目录,使用 cpio 所备份的内容不见得会在同一层目录中
-u:自动将较新的文件覆盖较旧的文件
-t:需配合 -i 使用,可用在查看以 cpio 建立的文件或设备的内容
一些可公用的选项与参数:
-v:让存储的过程中文件名称可以在屏幕上显示
-c:以一种较新的 portable format 方式存储
范例:找出 /boot 下面的所有文件,让后将它备份到 /tmp/boot.cpio 中


[!IMPORTANT]
这里为什么要先转换目录到 / 再去找 boot 呢?为何不能直接找 /boot ?
这是因为 cpio 很笨,它不会理会你给的是绝对路径还是相对路径的文件名,如果你加上绝对路径的 / 开头,那么未来解开的时候,它就一定会覆盖掉原本的 /boot,那就太危险了。这里的情况与 tar -P 选项类似。
范例:将刚刚的文件在 /root 目录下解开
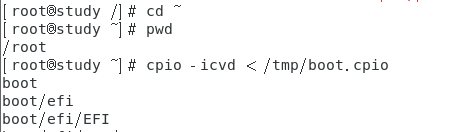
这个 cpio 好像不怎么好用,而且由于它必须配合其他程序使用,所以 cpio 与管道命令及数据流重定向的相关性就相当重要
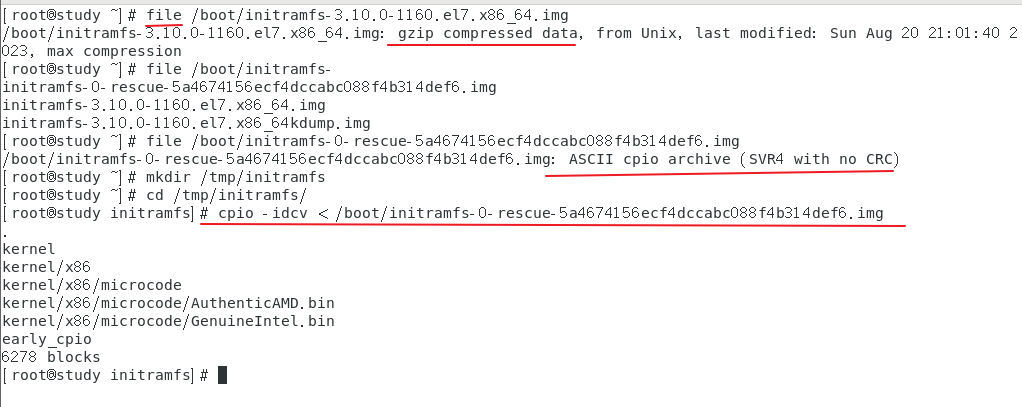
范例:在系统中有个使用 cpio 建立的文件,将文件解压缩看看
先要使用 file 命令查看这个文件是不是 cpio 备份的文件,若是才能用 cpio 解压















 699
699











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









