







1 图解Attention
问题:Attention出现的原因是什么?
潜在的答案:基于循环神经网络(RNN)一类的seq2seq模型,在处理长文本时遇到了挑战,而对长文本中不同位置的信息进行Attention有助于提升RNN的模型效果。
(1)名词理解:
1、循环神经网络:循环神经网络(Recurrent Neural Network, RNN)是一类以序列(sequence)数据为输入,在序列的演进方向进行递归且所有节点(循环单元)按链式连接的递归神经网络。

为什么需要循环神经网络:
普通的神经网络都只能单独的取处理一个个的输入,前一个输入和后一个输入是完全没有关系的。但是,某些任务需要能够更好的处理序列的信息,即前面的输入和后面的输入是有关系的。
比如,当我们在理解一句话意思时,孤立的理解这句话的每个词是不够的,我们需要处理这些词连接起来的整个序列; 当我们处理视频的时候,我们也不能只单独的去分析每一帧,而要分析这些帧连接起来的整个序列。
例如:我 吃 苹果 (已经分词好的句子)
这个任务的输出是:
我/nn 吃/v 苹果/nn(词性标注好的句子)
对于这个任务来说,我们当然可以直接用普通的神经网络来做,给网络的训练数据格式了就是我-> 我/nn 这样的多个单独的单词->词性标注好的单词。
但是很明显,一个句子中,前一个单词其实对于当前单词的词性预测是有很大影响的,比如预测苹果的时候,由于前面的吃是一个动词,那么很显然苹果作为名词的概率就会远大于动词的概率,因为动词后面接名词很常见,而动词后面接动词很少见。
RNN时间线展开图:

计算公式如图:

2、Attention:
通用定义:
- 给定一组向量集合values,以及一个向量query,Attention机制是一种根据该query计算values的加权求和的机制。
- Attention的重点就是这个集合values中的每个value的“权值”的计算方法。
- 有时候也把这种Attention的机制叫做query的输出关注了原文的不同部分。
Attention的机制就是一个加权求和的机制。Attention的思想如同它的名字一样,就是“注意力”,在预测结果时把注意力放在不同的特征上。比如在预测“我妈今天做的这顿饭真好吃”的情感时,如果只预测正向还是负向,那真正影响结果的只有“真好吃”这三个字,前面说的“我妈今天做的这顿饭”基本没什么用。
所以引入Attention机制,让我们可以根据任务目标赋予输入token不同的权重,理想情况下前半句的权重都在0.0级,后三个字则是“0.3, 0.3, 0.3”,在计算句子表示时就变成了:
最终表示 = 0.01x我+0.01x妈+0.01x今+0.01x天+0.01x做+0.01x的+0.01x这+0.01x顿+0.02x饭+0.3x真+0.3x好+0.3x吃
怎么用知道了,那核心就在于这个权重怎么计算。通常我们会将输入分为
q
u
e
r
y
(
Q
)
,
k
e
y
(
K
)
,
v
a
l
u
e
(
V
)
query(Q), key(K), value(V)
query(Q),key(K),value(V)三种:

QK的具体运算f有多种方法,常见的有加性Attention和乘性Attention:
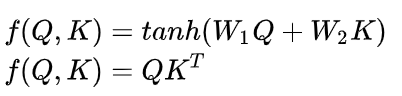
(2)问题拆解:
1、什么是seq2seq模型?
2、基于RNN的seq2seq模型如何处理文本/长文本序列?
3、seq2seq模型处理长文本序列时遇到了什么问题?
4、基于RNN的seq2seq模型如何结合Attention来改善模型效果?
1.1 seq2seq框架
seq2seq是一种常见的NLP模型结构,全称是:sequence to sequence,翻译为“序列到序列”。通过深度神经网络模型(常用的是LSTM)将一个作为输入的序列映射为一个作为输出的序列,这一过程由编码输入(encoder)与解码输出(decoder)两个环节组成。
(1)名词理解:
LSTM:长短期记忆(Long short-term memory, LSTM)是一种特殊的RNN,主要是为了解决长序列训练过程中的梯度消失和梯度爆炸问题。简单来说,就是相比普通的RNN,LSTM能够在更长的序列中有更好的表现。
人类并不是每时每刻都从一片空白的大脑开始他们的思考。在你阅读这篇文章时候,你都是基于自己已经拥有的对先前所见词的理解来推断当前词的真实含义。我们不会将所有的东西都全部丢弃,然后用空白的大脑进行思考。我们的思想拥有持久性。
传统的神经网络并不能做到这点,看起来也像是一种巨大的弊端。例如,假设你希望对电影中的每个时间点的时间类型进行分类。传统的神经网络应该很难来处理这个问题——使用电影中先前的事件推断后续的事件。
RNN 解决了这个问题。RNN 是包含循环的网络,允许信息的持久化。链式的特征揭示了 RNN 本质上是与序列和列表相关的。他们是对于这类数据的最自然的神经网络架构。
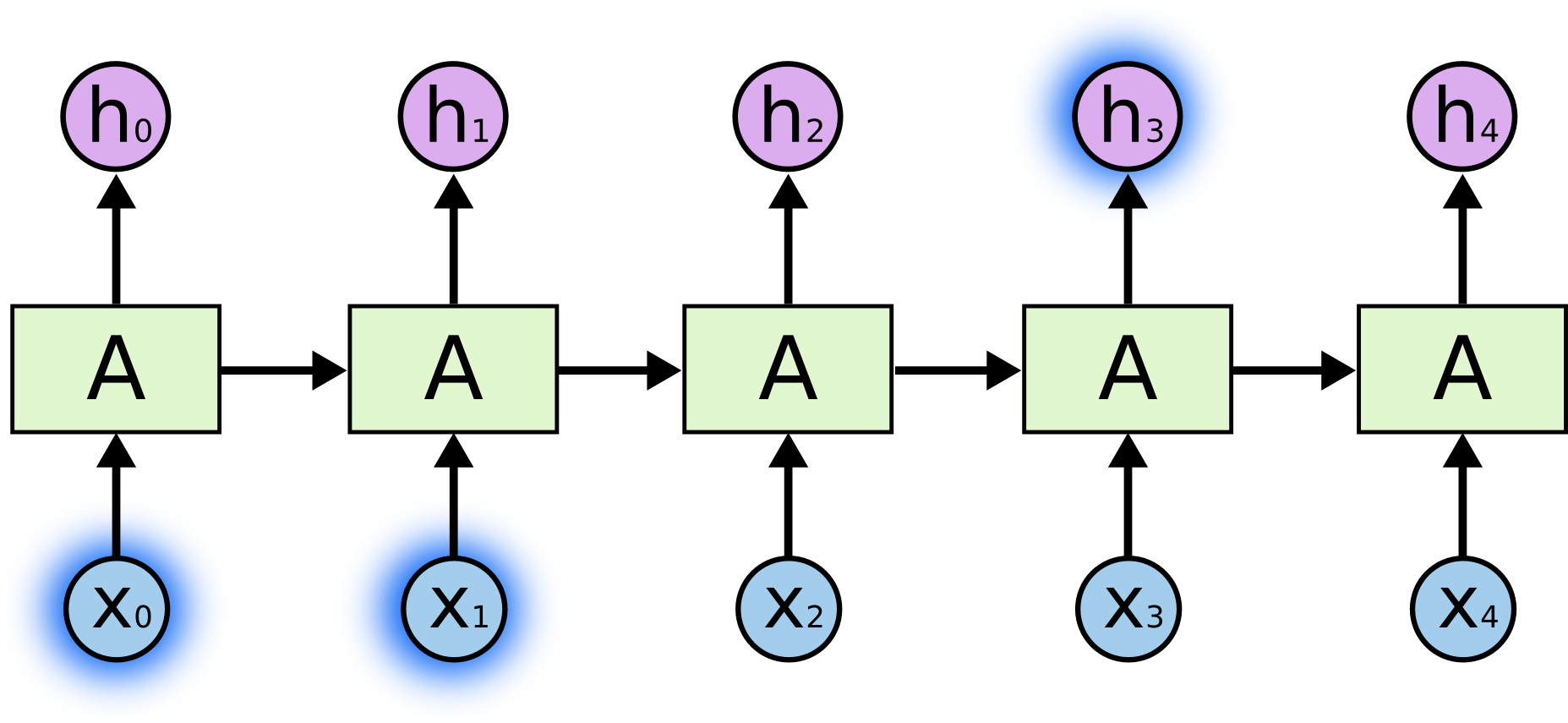
有时候,我们仅仅需要知道先前的信息来执行当前的任务。例如,我们有一个语言模型用来基于先前的词来预测下一个词。如果我们试着预测 “the clouds are in the sky” 最后的词,我们并不需要任何其他的上下文 —— 因此下一个词很显然就应该是 sky。在这样的场景中,相关的信息和预测的词位置之间的间隔是非常小的,RNN 可以学会使用先前的信息。
不太长的相关信息和位置间隔:
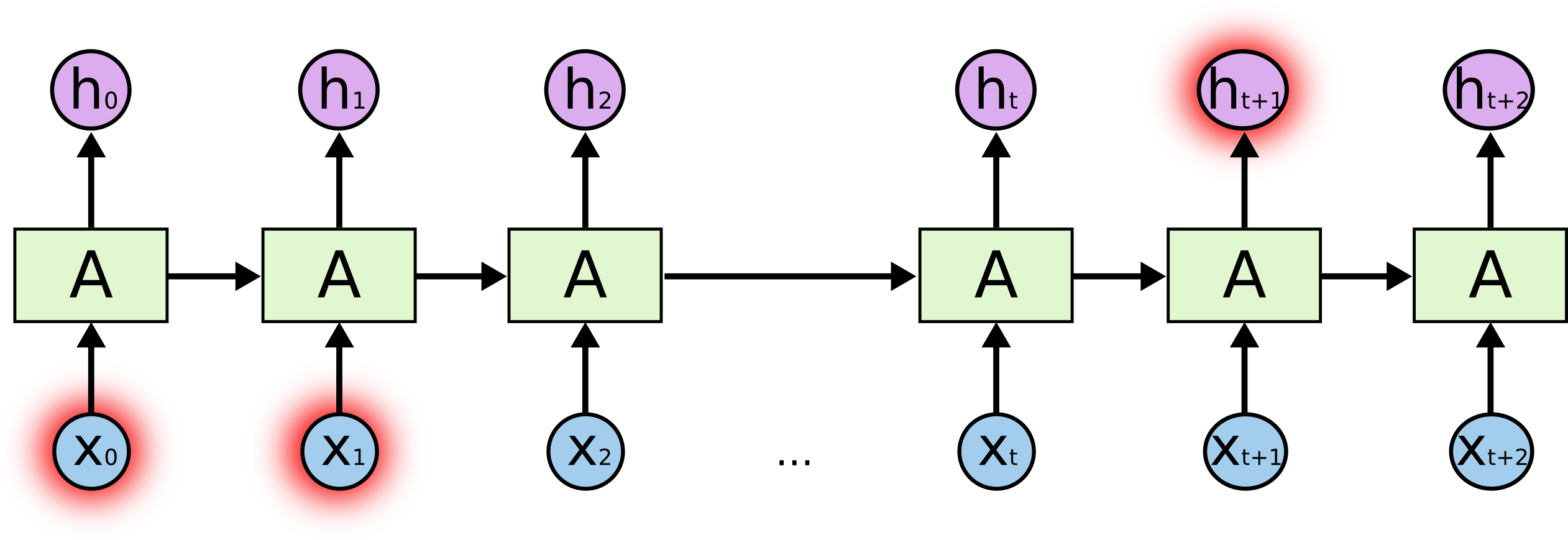
但是同样会有一些更加复杂的场景。假设我们试着去预测“I grew up in France… I speak fluent French”最后的词。当前的信息建议下一个词可能是一种语言的名字,但是如果我们需要弄清楚是什么语言,我们是需要先前提到的离当前位置很远的 France 的上下文的。这说明相关信息和当前预测位置之间的间隔就肯定变得相当的大。
不幸的是,在这个间隔不断增大时,RNN 会丧失学习到连接如此远的信息的能力。
相当长的相关信息和位置间隔:
而LSTM 通过刻意的设计来避免长期依赖问题。
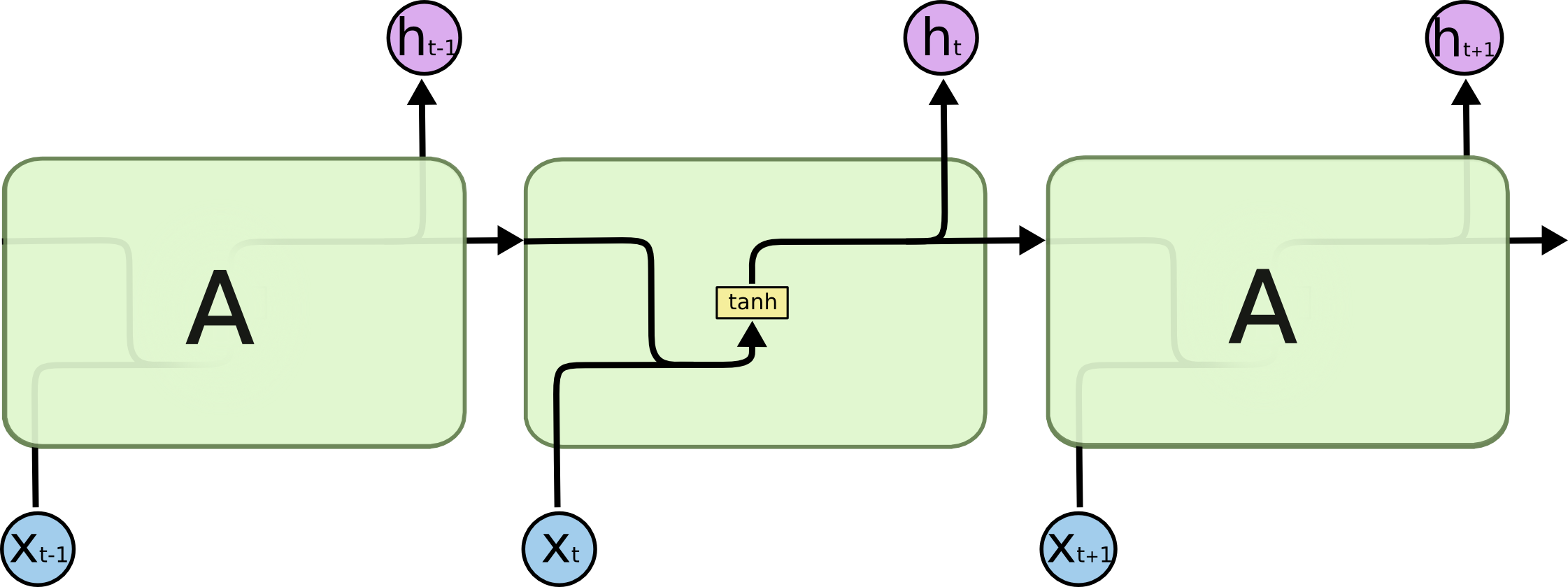
所有 RNN 都具有一种重复神经网络模块的链式的形式。在标准的 RNN 中,这个重复的模块只有一个非常简单的结构,例如一个 tanh 层。
标准 RNN 中的重复模块包含单一的层:
LSTM 同样是这样的结构,但是重复的模块拥有一个不同的结构。不同于 单一神经网络层,这里是有四个,以一种非常特殊的方式进行交互。

LSTM 中的重复模块包含四个交互的层:
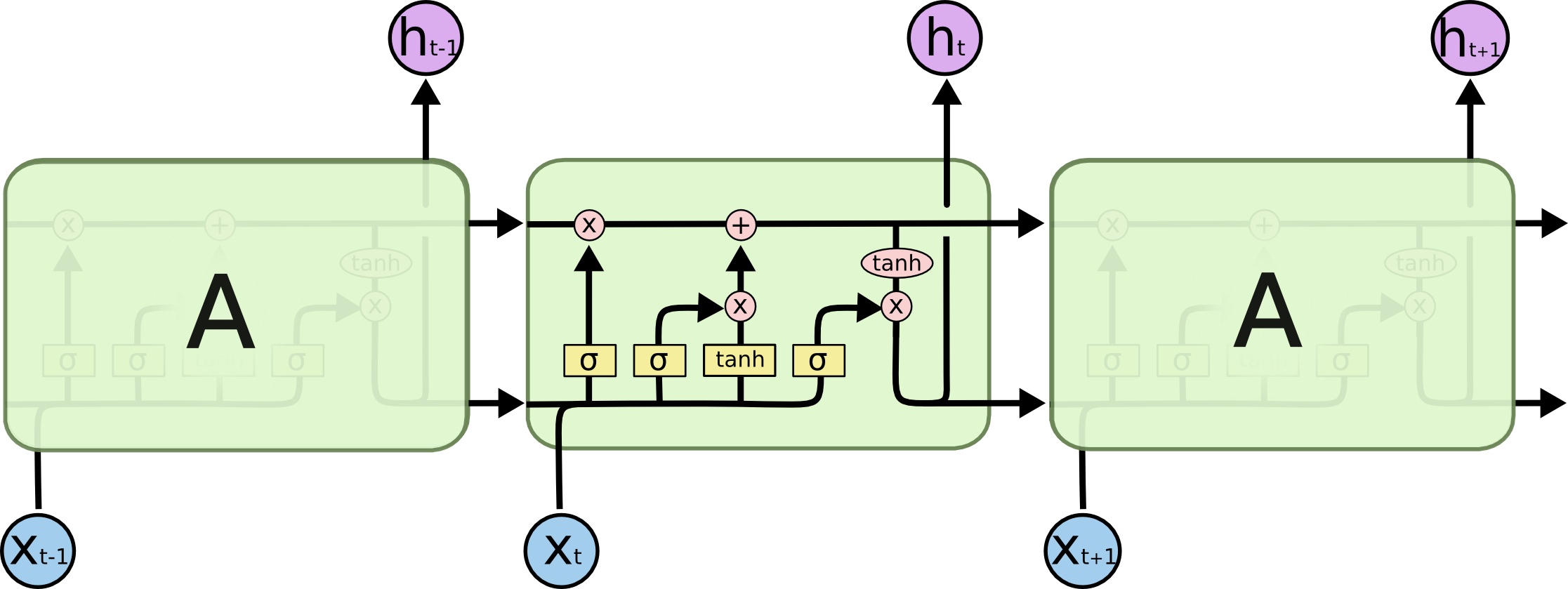
(2)模型简介:
Seq2Seq模型是输出的长度不确定时采用的模型,这种情况一般是在机器翻译的任务中出现,将一句中文翻译成英文,那么这句英文的长度有可能会比中文短,也有可能会比中文长,所以输出的长度就不确定了。如下图所,输入的中文长度为4,输出的英文长度为2。

在网络结构中,输入一个中文序列,然后输出它对应的中文翻译,输出的部分的结果预测后面,根据上面的例子,也就是先输出“machine”,将"machine"作为下一次的输入,接着输出"learning",这样就能输出任意长的序列。
顾名思义:从一个文本序列得到一个新的文本序列。
典型的任务有:机器翻译任务,文本摘要任务。
(3)步骤:
输入序列->编码,形成context向量->解码context向量->输出序列
seq2seq模型的输入可以是一个(单词、字母或者图像特征)序列,输出是另外一个(单词、字母或者图像特征)序列。
seq2seq:

如下图所示,以NLP中的机器翻译任务为例,序列指的是一连串的单词,输出也是一连串单词。
translation:

1.2 seq2seq细节
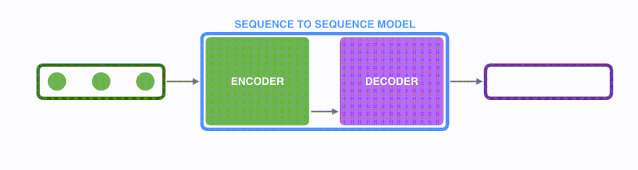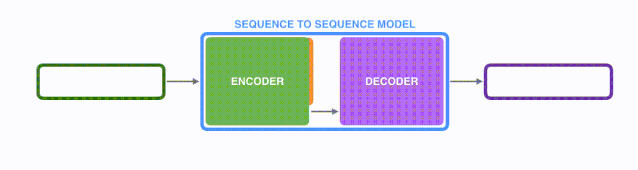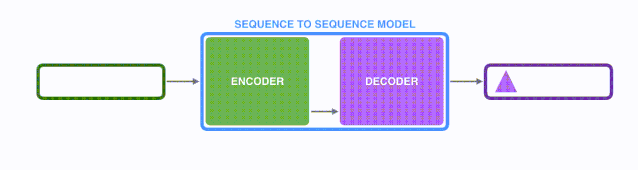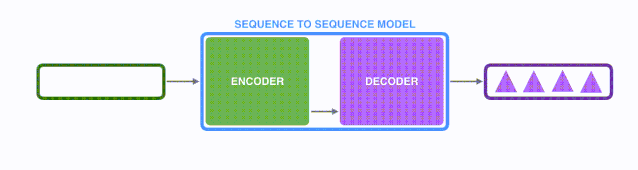
将上图中蓝色的seq2seq模型进行拆解,如下图所示:seq2seq模型由编码器(Encoder)和解码器(Decoder)组成。绿色的编码器会处理输入序列中的每个元素并获得输入信息,这些信息会被转换成为一个黄色的向量(称为context向量)。
当我们处理完整个输入序列后,编码器把 context向量 发送给紫色的解码器,解码器通过context向量中的信息,逐个元素输出新的序列。
seq2seq中的encoder-decoder:
由于seq2seq模型可以用来解决机器翻译任务,因此机器翻译被任务seq2seq模型解决过程如下图所示,当作seq2seq模型的一个具体例子来学习。
seq2seq中的encoder-decoder,机器翻译的例子:
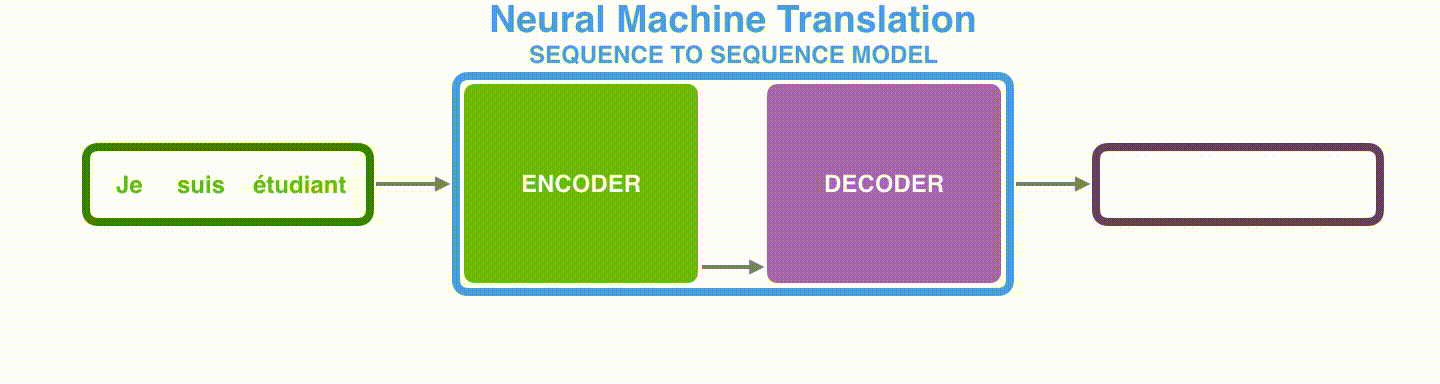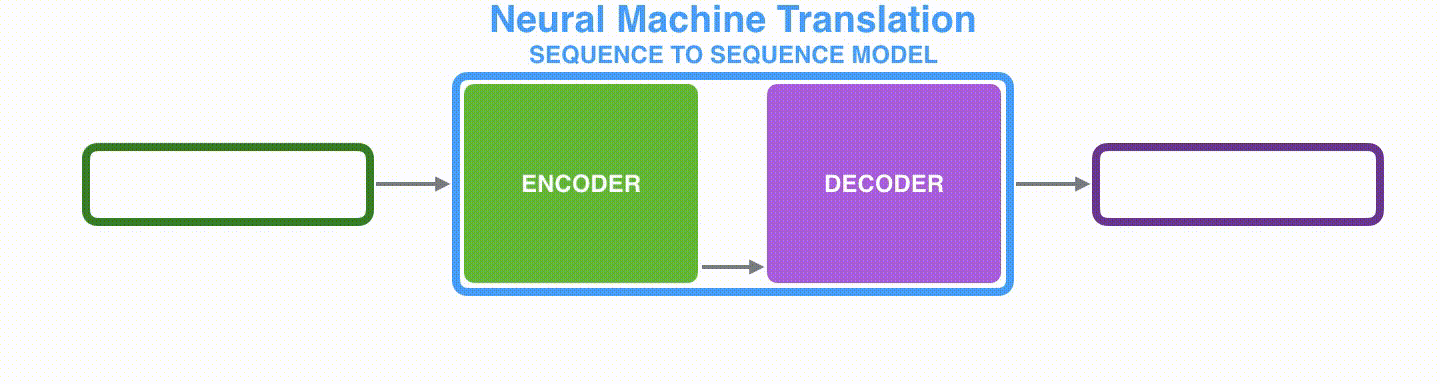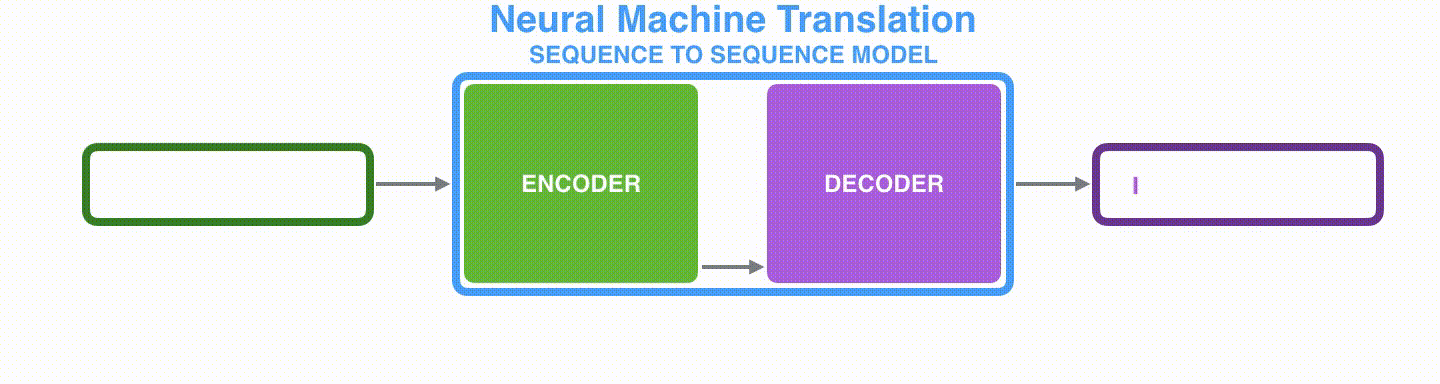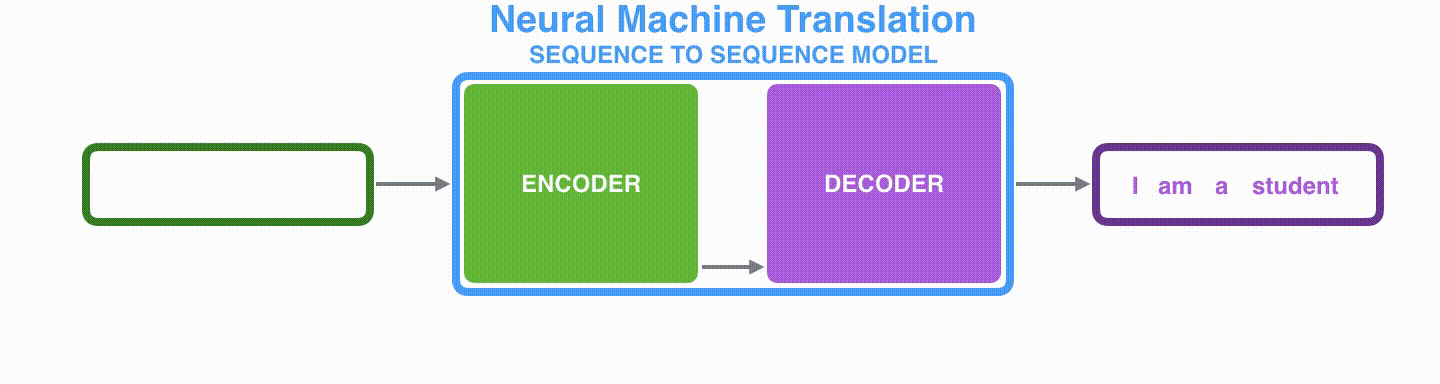
基本思想就是利用两个RNN,一个RNN作为encoder,另一个RNN作为decoder。encoder负责将输入序列压缩成指定长度的context向量,这个向量就可以看成是这个序列的语义,这个过程称为编码。
如下图,获取语义向量最简单的方式就是直接将最后一个输入的隐状态作为语义向量C。也可以对最后一个隐含状态做一个变换得到语义向量,还可以将输入序列的所有隐含状态做一个变换得到语义变量。
RNN网络:
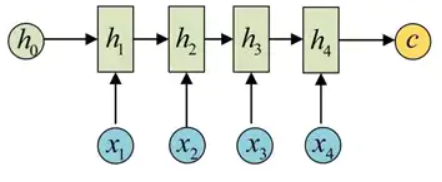
而decoder则负责根据语义向量生成指定的序列,这个过程也称为解码,如下图,最简单的方式是将encoder得到的语义变量作为初始状态输入到decoder的RNN中,得到输出序列。
可以看到上一时刻的输出会作为当前时刻的输入,而且其中语义向量C只作为初始状态参与运算,后面的运算都与语义向量C无关。
语义向量只作初始化参数参与运算:

decoder处理方式还有另外一种,就是语义向量C参与了序列所有时刻的运算,如下图,上一时刻的输出仍然作为当前时刻的输入,但语义向量C会参与所有时刻的运算。
语义向量参与解码的每一个过程:

深入学习机器翻译任务中的seq2seq模型,如下图所示。seq2seq模型中的编码器和解码器一般采用的是循环神经网络RNN。编码器将输入的法语单词序列编码成context向量(在绿色encoder和紫色decoder中间出现),然后解码器根据context向量解码出英语单词序列。
context向量对应浮点数向量:

黄色的context向量是什么?
本质上是一组浮点数。而这个context的数组长度是基于编码器RNN的隐藏层神经元数量的。上图展示了长度为4的context向量,但在实际应用中,context向量的长度是自定义的,比如可能是256,512或者1024。
单隐藏层神经网络:输入和输出中间有一个隐层,即输入层的输出是隐层的输入,隐层的输出和对应权重的乘积是输出层的输入,输出层的输出才是最终的输出。



我们在处理单词之前,需要将单词映射成为向量,通常使用 word embedding 算法来完成。一般来说,我们可以使用提前训练好的 word embeddings,或者在自有的数据集上训练word embedding。为了简单起见,上图展示的word embedding维度是4。上图左边每个单词经过word embedding算法之后得到中间一个对应的4维的向量。
可视化一下基于RNN的seq2seq模型中的编码器在第1个时间步是如何工作:
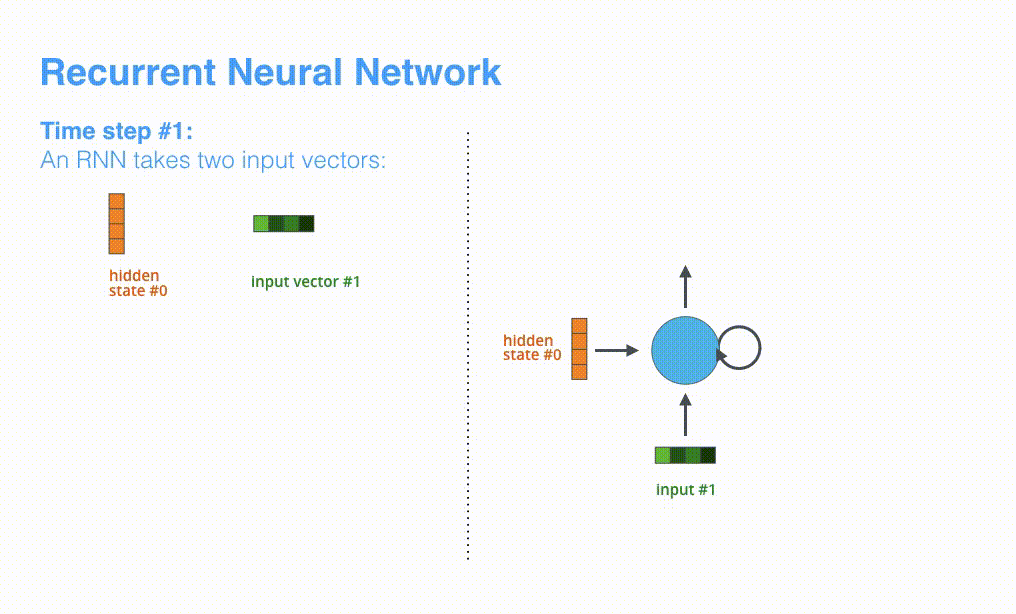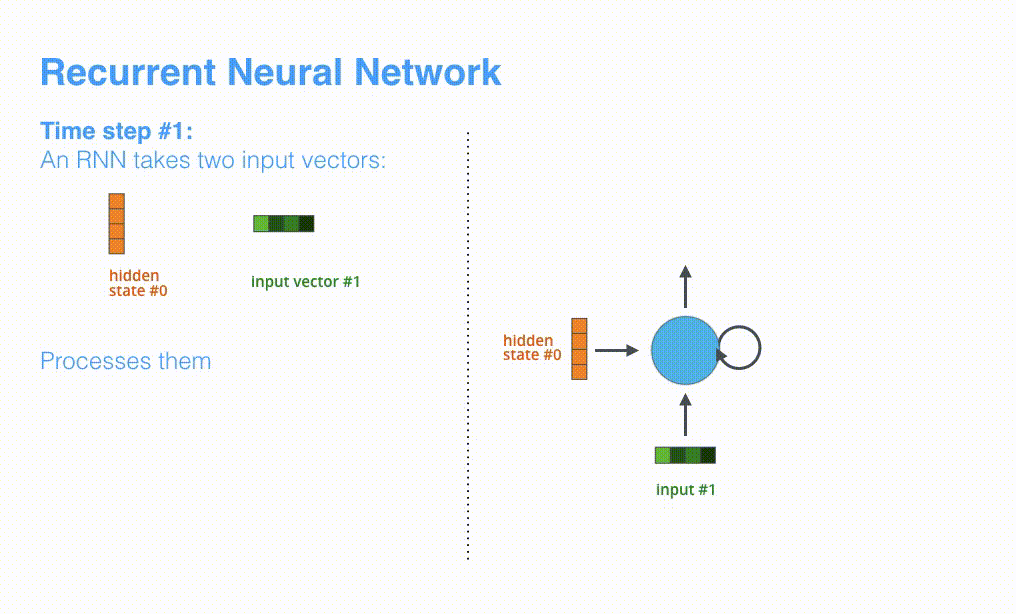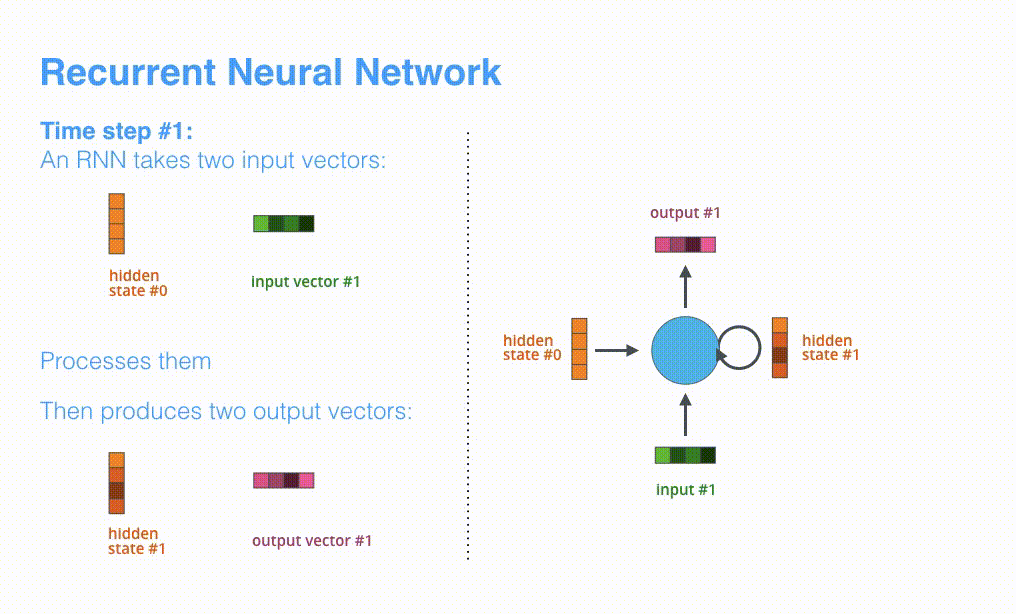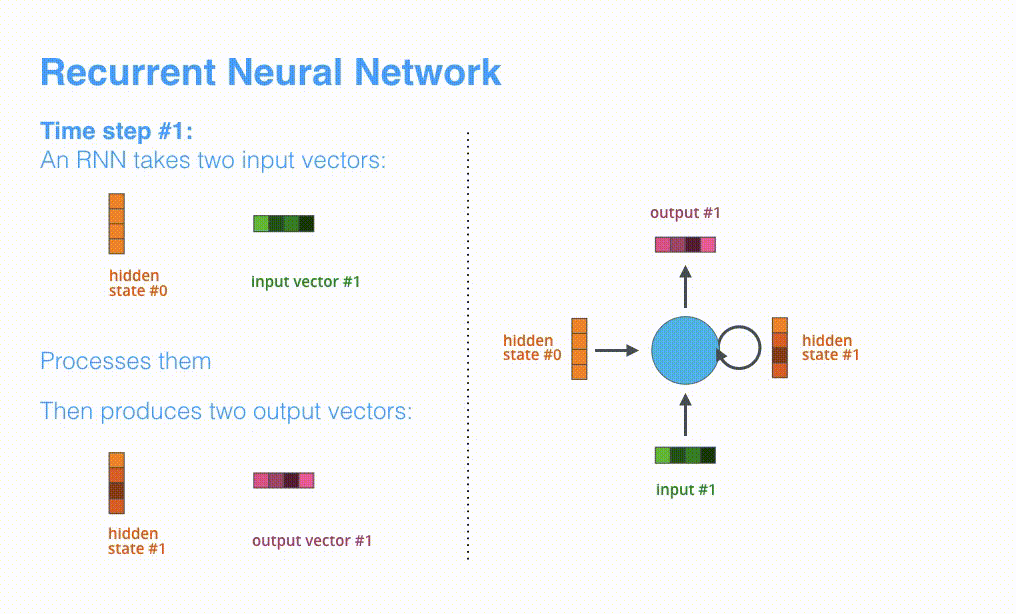
RNN在第2个时间步,采用第1个时间步得到hidden state#0(隐藏层状态)和第2个时间步的输入向量input#1,来得到新的输出hidden state#1。
看下面的动态图,让我们详细观察一下编码器如何在每个时间步得到hidden sate,并将最终的hidden state传输给解码器,解码器根据编码器所给予的最后一个hidden state信息解码处输出序列。注意,最后一个 hidden state实际上是我们上文提到的context向量。
编码器逐步得到hidden state并传输最后一个hidden state给解码器:
last hidden state=context向量
接着,结合编码器处理输入序列,一起来看下解码器如何一步步得到输出序列的l。与编码器类似,解码器在每个时间步也会得到 hidden state(隐藏层状态),而且也需要把 hidden state(隐藏层状态)从一个时间步传递到下一个时间步。
编码器首先按照时间步依次编码每个法语单词,最终将最后一个hidden state也就是context向量传递给解码器,解码器根据context向量逐步解码得到英文输出。
回到最开始的问题:
1、什么是seq2seq模型?
Seq2Seq模型是将一个序列信号,通过编码解码生成一个新的序列信号,通常用于机器翻译、语音识别、自动对话等任务。Seq2Seq模型的核心思想是,通过深度神经网络将一个作为输入的序列映射为一个作为输出的序列,这个过程由编码输入和解码输出两个环节构成。
Seq2Seq在解码的时候最基础的算法是贪心法,即每次贪心的选择概率最大的结果。贪心算法的计算代价低,适合作为基准结果与其他方法比较。
2、基于RNN的seq2seq模型如何处理文本/长文本序列?
输入序列,由编码器获得输入信息,并在不同的时间步得到对应的隐藏层状态hidden state以及下一时间步的输入向量input,用于得到新的输出hidden state。并将最终的hidden state(也就是context向量)传输给解码器,解码器根据最终的hidden state信息解码输出序列。
1.3 Attention
基于RNN的seq2seq模型编码器所有信息都编码到了一个context向量中,便是这类模型的瓶颈。
一方面单个向量很难包含所有文本序列的信息,另一方面RNN递归地编码文本序列使得模型在处理长文本时面临非常大的挑战(比如RNN处理到第500个单词的时候,很难再包含1-499个单词中的所有信息了)。
据此,提出一种叫做注意力Attention的技术。通过Attention技术,seq2seq模型极大地提高了机器翻译的质量。归其原因是:Attention注意力机制,使得seq2seq模型可以有区分度、有重点地关注输入序列。
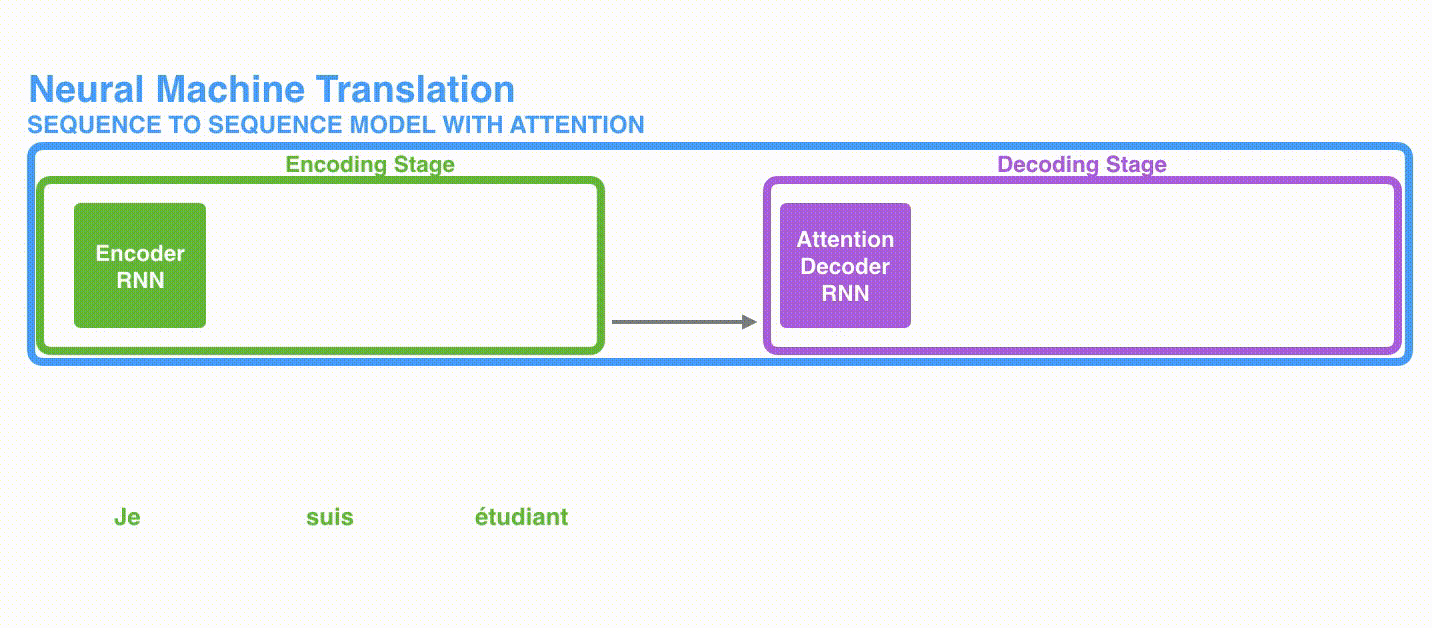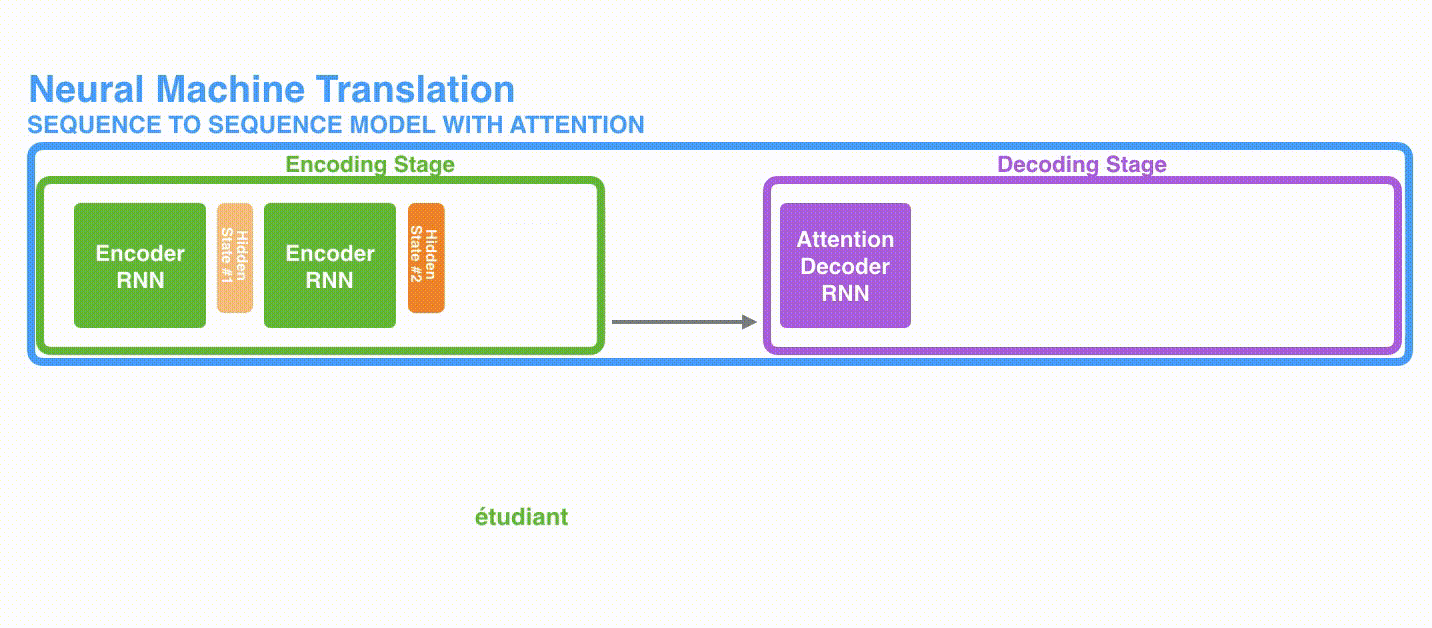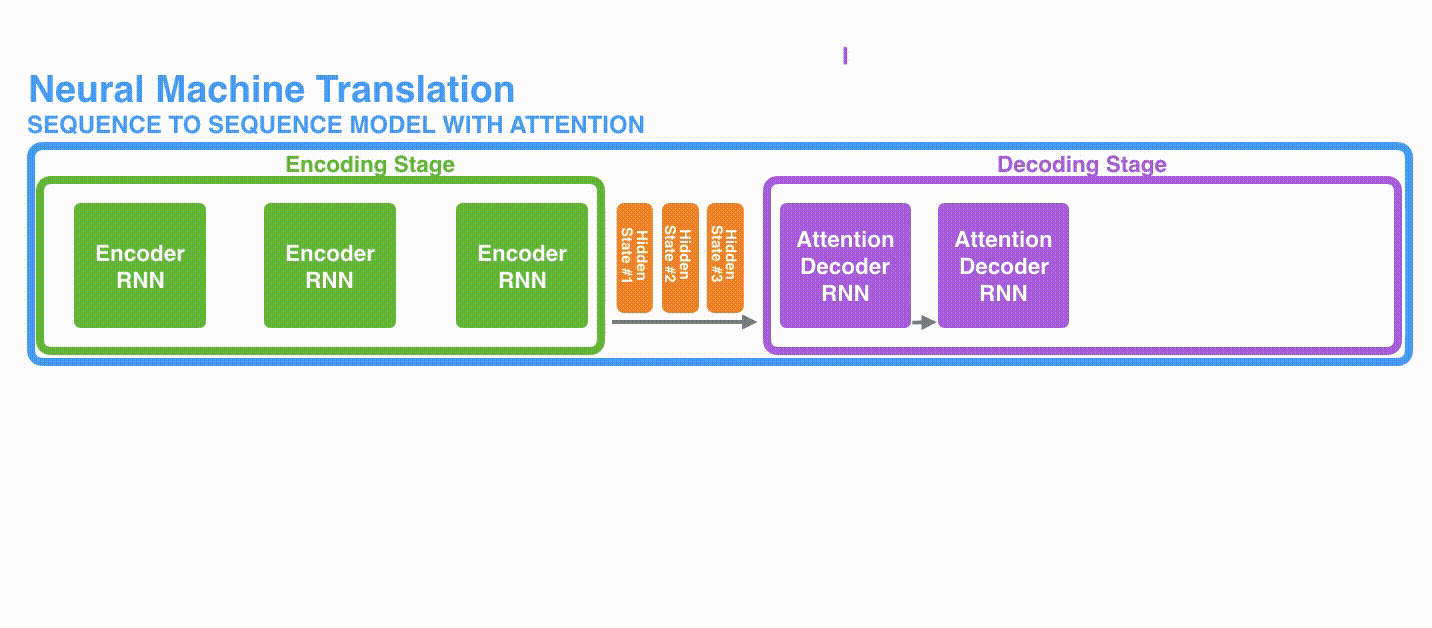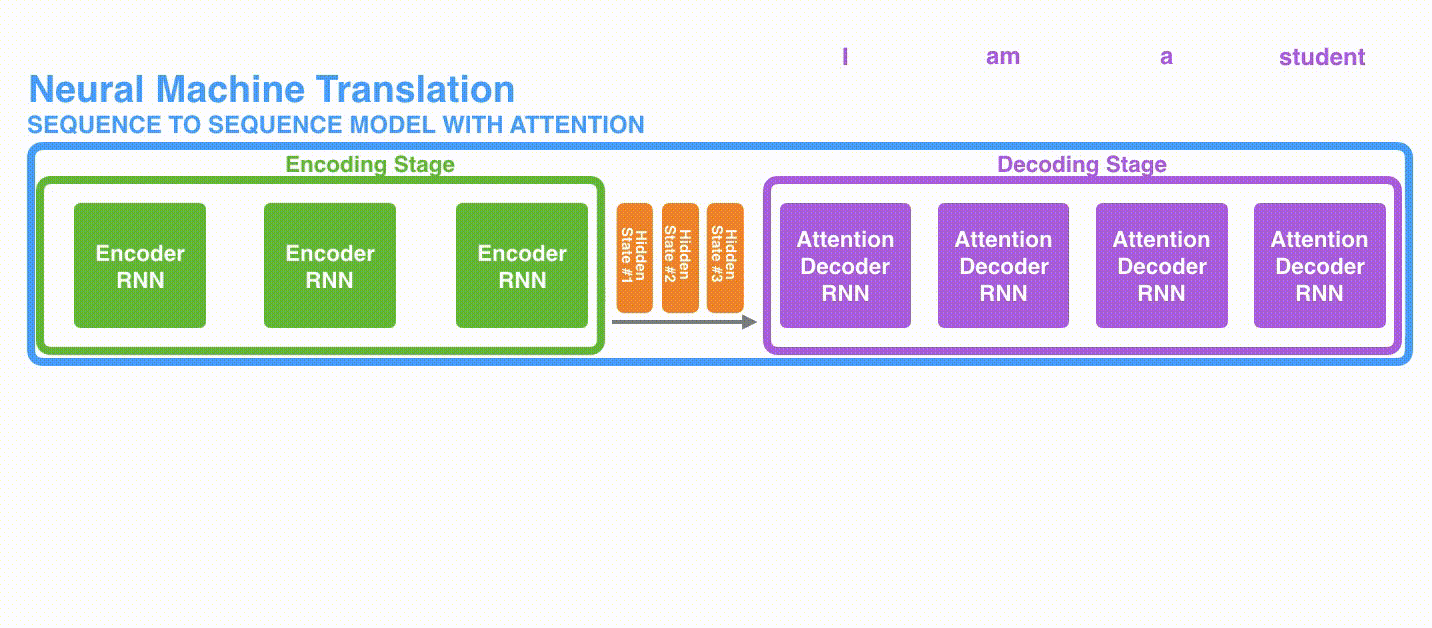
机器翻译的例子:

在第 7 个时间步,注意力机制使得解码器在产生英语翻译student英文翻译之前,可以将注意力集中在法语输入序列的:étudiant。这种有区分度得attention到输入序列的重要信息,使得模型有更好的效果。
一个注意力模型与经典的seq2seq模型主要有2点不同:
1、首先,编码器会把更多的数据传递给解码器。编码器把所有时间步的 hidden state(隐藏层状态)传递给解码器,而不是只传递最后一个 hidden state(隐藏层状态)。
更多的信息传递给decoder:
2、注意力模型的解码器在产生输出之前,做了一个额外的attention处理。如下图所示,具体为:
- 由于编码器中每个 hidden state(隐藏层状态)都对应到输入句子中一个单词,那么解码器要查看所有接收到的编码器的 hidden state(隐藏层状态)。
- 给每个 hidden state(隐藏层状态)计算出一个分数(我们先忽略这个分数的计算过程)。
- 所有hidden state(隐藏层状态)的分数经过softmax进行归一化。也就是计算权重。
- 将每个 hidden state(隐藏层状态)乘以所对应的分数,从而能够让高分对应的 hidden state(隐藏层状态)会被放大,而低分对应的 hidden state(隐藏层状态)会被缩小。
- 将所有hidden state根据对应分数进行加权求和,得到对应时间步的context向量。
在第4个时间步,编码器结合attention得到context向量的5个步骤:

所以Attention可以简单理解为:一种有效的加权求和技术,其艺术在于如何获得权重。
结合注意力的seq2seq模型解码器全流程,动态图展示的是第4个时间步:
1、注意力模型的解码器 RNN 的输入包括:一个word embedding 向量,和一个初始化好的解码器 hidden state,图中是h_init。
2、RNN 处理上述的 2 个输入,产生一个输出和一个新的 hidden state(h4)。
3、注意力的步骤:我们使用编码器的所有 hidden state向量和 h4 向量来计算这个时间步的context向量(C4)。
4、我们把 h4 和 C4 拼接起来,得到一个橙色向量。
5、我们把这个橙色向量输入一个前馈神经网络(这个网络是和整个模型一起训练的)。
6、根据前馈神经网络的输出向量得到输出单词:假设输出序列可能的单词有N个,那么这个前馈神经网络的输出向量通常是N维的,每个维度的下标对应一个输出单词,每个维度的数值对应的是该单词的输出概率。
7、在下一个时间步重复1-6步骤。
解码器结合attention全过程:
回到最开始的问题:
3、seq2seq处理长文本序列的挑战是什么?
单个context向量很难包含所有文本序列的信息,且RNN递归地编码文本序列使得模型在处理长文本时面临非常大的挑战。
关于RNN的attention机制和LSTM区别:
蒟蒻暂时还不明白,欢迎大佬解答~
4、seq2seq是如何结合attention来解决问题3中的挑战的?
attention注意力机制,使得seq2seq模型可以有区分度、有重点地关注输入序列。
解码步骤时候attention关注的词:
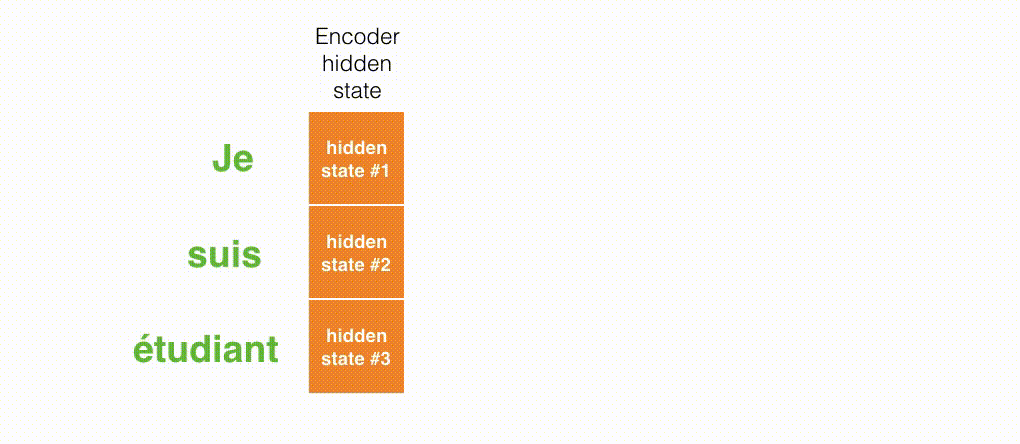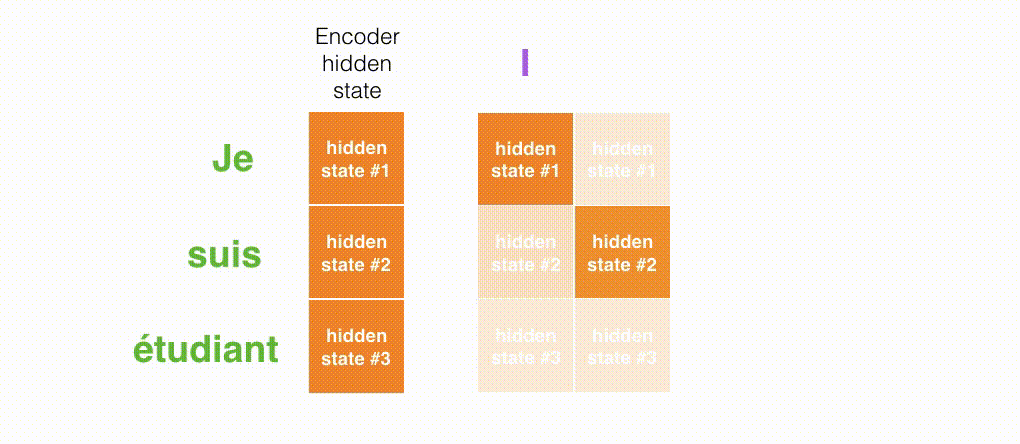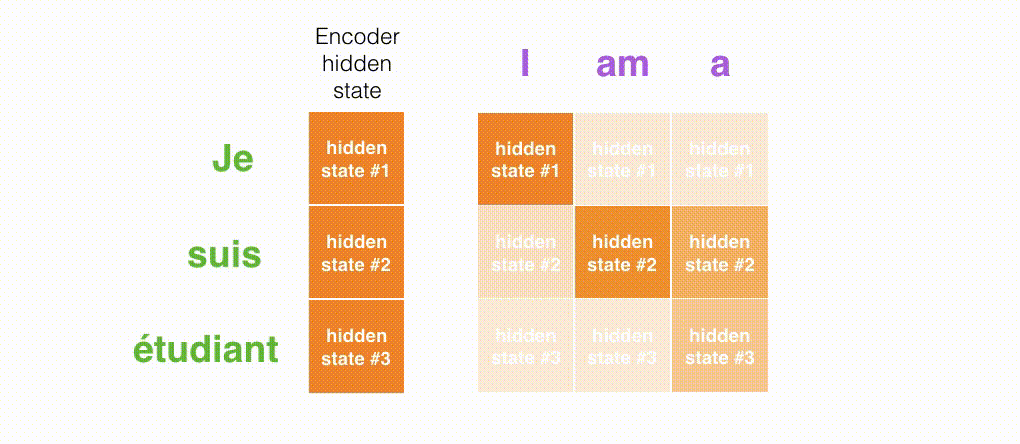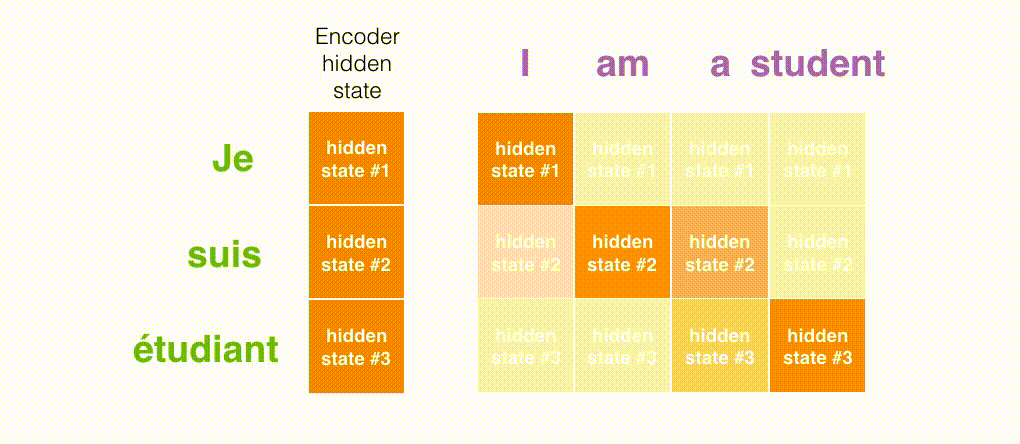
注意力模型不是无意识地把输出的第一个单词对应到输入的第一个单词,它是在训练阶段学习到如何对两种语言的单词进行对应(在我们的例子中,是法语和英语)。
2 图解transformer
2.1 图解transformer
有没有一种神经网络结构直接基于attention构造,并且不再依赖RNN、LSTM或者CNN网络结构?
答案:Transformer。
Transformer模型在2017年被google提出,直接基于Self-Attention结构,取代了之前NLP任务中常用的RNN神经网络结构。
与RNN这类神经网络结构相比,Transformer一个巨大的优点是:模型在处理序列输入时,可以对整个序列输入进行并行计算,不需要按照时间步循环递归处理输入序列(速度更快)。
Transformer模型结构中的左半部分为编码器(encoder),右半部分为解码器(decoder),与seq2seq模型类似。
Transformer整体结构图:

2.1.1 Transformer宏观结构
Transformer最开始提出来解决机器翻译任务,因此可以看作是seq2seq模型的一种。以机器翻译任务为例,先将Transformer这种特殊的seq2seq模型看作一个黑盒,黑盒的输入是法语文本序列,输出是英语文本序列(Transformer宏观结构属于seq2seq范畴,只是将之前seq2seq中的编码器和解码器,从RNN模型替换成了Transformer模型)。
(1)名词解释:
1、前馈神经网络:是人工神经网络的一种。前馈神经网络采用一种单向多层结构。其中每一层包含若干个神经元。在此种神经网络中,各神经元可以接收前一层神经元的信号,并产生输出到下一层。第0层叫输入层,最后一层叫输出层,其他中间层叫做隐含层(或隐藏层、隐层)。隐层可以是一层。也可以是多层。
一个典型的多层前馈神经网络:

2、self-attention自注意力:自注意力机制是注意力机制的变体,其减少了对外部信息的依赖,更擅长捕捉数据或特征的内部相关性。
自注意力机制在文本中的应用,主要是通过计算单词间的互相影响,来解决长距离依赖问题。
自注意力机制的计算过程:
- 预处理输入数据
- 初始化权重
- 计算key,query 和value
- 计算输入值的注意力得分
- 计算softmax层
- 注意力得分与value相乘
- 对6中结果加权求和,并得到第一个输出值
- 重复4-7,计算其余输入数据的输出值
self-attention的思想和attention类似,但是self-attention是Transformer用来将其他相关单词的“理解”转换成我们正在处理的单词的一种思路,我们看个例子: The animal didn’t cross the street because it was too tired 这里的it到底代表的是animal还是street呢,对于我们来说能很简单的判断出来,但是对于机器来说,是很难判断的,self-attention就能够让机器把it和animal联系起来。
(2)整体结构:
Transformer黑盒输入和输出:

将中间部分的“THE TRANSFORMER”拆开成seq2seq标准结构,得到下图:左边是编码部分encoders,右边是解码器部分decoders。

编码部分由多层编码器组成(Transformer论文中使用的是6层编码器,这里的层数6并不是固定的,你也可以根据实验效果来修改层数)。同理,解码部分也是由多层的解码器组成(论文里也使用了6层解码器)。每层编码器网络结构是一样的,每层解码器网络结构也是一样的。不同层编码器和解码器网络结构不共享参数。
6层编码和6层解码器:

单层encoder主要由以下两部分组成,如下图所示
- Self-Attention Layer
- Feed Forward Neural Network(前馈神经网络,缩写为 FFNN)

单层encoder:

与编码器对应,如下图,解码器在编码器的self-attention和FFNN中间插入了一个Encoder-Decoder Attention层,这个层帮助解码器聚焦于输入序列最相关的部分(类似于seq2seq模型中的 Attention)。
单层decoder:

Transformer由编码部分和解码部分组成,而编码部分和解码部分又由多个网络结构相同的编码层和解码层组成。
每个编码层由self-attention和FFNN组成,每个解码层由self-attention、FFN和encoder-decoder attention组成。
2.1.2 Transformer结构细节
问题:
Transformer如何将输入文本序列转换为向量表示?
如何逐层处理这些向量表示得到最终的输出?
(1)输入处理
1、词向量
和常见的NLP 任务一样,我们首先会使用词嵌入算法(embedding algorithm),将输入文本序列的每个词转换为一个词向量。实际应用中的向量一般是 256 或者 512 维。
2、位置向量
Transformer模型对每个输入的词向量都加上了一个位置向量。这些向量有助于确定每个单词的位置特征,或者句子中不同单词之间的距离特征。词向量加上位置向量背后的直觉是:将这些表示位置的向量添加到词向量中,得到的新向量,可以为模型提供更多有意义的信息,比如词的位置,词之间的距离等。
位置编码向量:

依旧假设词向量和位置向量的维度是4,我们在下图中展示一种可能的位置向量+词向量。
位置编码向量:


位置编码在0-100位置,在4、5、6、7维的数值:

优点:可以扩展到未知的序列长度。
例如:当我们的模型需要翻译一个句子,而这个句子的长度大于训练集中所有句子的长度,这时,这种位置编码的方法也可以生成一样长的位置编码向量。
(2)编码器encoder
编码部分的输入文本序列经过输入处理之后得到了一个向量序列,这个向量序列将被送入第1层编码器,第1层编码器输出的同样是一个向量序列,再接着送入下一层编码器:第1层编码器的输入是融合位置向量的词向量,更上层编码器的输入则是上一层编码器的输出。
下图展示了向量序列在单层encoder中的流动:融合位置信息的词向量进入self-attention层,self-attention的输出每个位置的向量再输入FFN神经网络得到每个位置的新向量。
单层encoder的序列向量流动:

2个单词的例子:

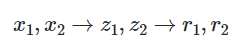
1、Self-Attention层
-
Self-Attention概览
想要翻译的句子是:The animal didn’t cross the street because it was too tired
当模型处理句子中其他词时,Self Attention机制也可以使得模型不仅仅关注当前位置的词,还会关注句子中其他位置的相关的词,进而可以更好地理解当前位置的词。
与RNN对比一下:RNN 在处理序列中的一个词时,会考虑句子前面的词传过来的hidden state,而hidden state就包含了前面的词的信息;而Self Attention机制值得是,当前词会直接关注到自己句子中前后相关的所有词语。

-
Self-Attention细节
先通过一个简单的例子来理解一下:什么是“self-attention自注意力机制”?假设一句话包含两个单词:Thinking Machines。自注意力的一种理解是:Thinking-Thinking,Thinking-Machines,Machines-Thinking,Machines-Machines,共种两两attention。那么具体如何计算呢?假设Thinking、Machines这两个单词经过词向量算法得到向量是: X 1 , X 2 X_{1},X_{2} X1,X2
第1步:对输入编码器的词向量进行线性变换得到:Query向量: q 1 , q 2 q_1,q_2 q1,q2,Key向量: k 1 , k 2 k_1,k_2 k1,k2,Value向量: v 1 , v 2 v_1,v_2 v1,v2。
Query 向量,Key 向量,Value 向量是什么含义呢?
其实它们就是 3 个向量,给它们加上一个名称,可以让我们更好地理解 Self-Attention 的计算过程和逻辑。attention计算的逻辑常常可以描述为:query和key计算相关或者叫attention得分,然后根据attention得分对value进行加权求和。
第2步:计算Attention Score(注意力分数)。假设我们现在计算第一个词Thinking的Attention Score(注意力分数),需要根据Thinking对应的词向量,对句子中的其他词向量都计算一个分数。这些分数决定了我们在编码Thinking这个词时,需要对句子中其他位置的词向量的权重。
第3步:把每个分数除以 √ d k √dk √dk, √ d k √dk √dk是Key向量的维度。除以一个数是为了在反向传播时,求梯度时更加稳定。
第4步:接着把这些分数经过一个Softmax函数,Softmax可以将分数归一化,这样使得分数都是正数并且加起来等于1。
第5步:得到每个词向量的分数后,将分数分别与对应的Value向量相乘。这种做法背后的直觉理解就是:对于分数高的位置,相乘后的值就越大,我们把更多的注意力放到了它们身上;对于分数低的位置,相乘后的值就越小,这些位置的词可能是相关性不大的。
第6步:把第5步得到的Value向量相加,就得到了Self Attention在当前位置对应的输出。
在下图展示了对第一个位置词向量计算Self Attention 的全过程。最终得到的当前位置(这里的例子是第一个位置)词向量会继续输入到前馈神经网络。
Thinking经过attention之后的向量表示z1:

3.Self-Attention矩阵计算
self-attention的矩阵计算方法:
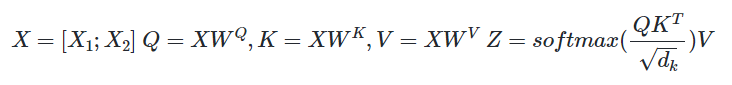
第1步:计算 Query,Key,Value 的矩阵。首先,我们把所有词向量放到一个矩阵X中,然后分别和
W
Q
W^{Q}
WQ,
W
K
W^{K}
WK,
W
V
W^{V}
WV 3个权重矩阵相乘,得到
Q
,
K
,
V
Q,K,V
Q,K,V矩阵。矩阵X中的每一行,表示句子中的每一个词的词向量。
Q
,
K
,
V
Q,K,V
Q,K,V矩阵中的每一行表示 Query向量,Key向量,Value 向量。
Q
K
V
QKV
QKV矩阵乘法:

第2步:由于我们使用了矩阵来计算,我们可以把上面的第 2 步到第 6 步压缩为一步,直接得到 Self Attention 的输出。

2、多头注意力机制
Transformer 的论文通过增加多头注意力机制(一组注意力称为一个 attention head),进一步完善了Self-Attention。这种机制从如下两个方面增强了attention层的能力:
- 它扩展了模型关注不同位置的能力
- 多头注意力机制赋予attention层多个“子表示空间”(多头注意力机制会有多组权重矩阵)
多头注意力机制:

在多头注意力机制中,我们为每组注意力设定单独的
W
Q
W^{Q}
WQ,
W
K
W^{K}
WK,
W
V
W^{V}
WV 参数矩阵。将输入X和每组注意力的
W
Q
W^{Q}
WQ,
W
K
W^{K}
WK,
W
V
W^{V}
WV 相乘,得到8组
Q
,
K
,
V
Q, K, V
Q,K,V矩阵。
接着,我们把每组 K , Q , V K, Q, V K,Q,V计算得到每组的 Z Z Z矩阵,就得到8个 Z Z Z矩阵。
由于前馈神经网络层接收的是 1 个矩阵(其中每行的向量表示一个词),而不是 8 个矩阵,所以我们直接把8个子矩阵拼接起来得到一个大的矩阵,然后和另一个权重矩阵
W
O
W^{O}
WO相乘做一次变换,映射到前馈神经网络层所需要的维度。
拼接8个子矩阵并进行映射变换:

- 把8个矩阵 Z 0 , Z 1 . . . , Z 7 {Z_0,Z_1...,Z_7} Z0,Z1...,Z7拼接起来
- 把拼接后的矩阵和 W O W_O WO权重矩阵相乘
- 得到最终的矩阵Z,这个矩阵包含了所有 attention heads(注意力头) 的信息。这个矩阵会输入到FFNN (Feed Forward Neural Network)层。
多头注意力机制的矩阵运算: 绿色和橙色线条分别表示2组不同的attentin heads:
绿色和橙色线条分别表示2组不同的attentin heads:

当我们编码单词"it"时,其中一个 attention head (橙色注意力头)最关注的是"the animal",另外一个绿色 attention head 关注的是"tired"。因此在某种意义上,"it"在模型中的表示,融合了"animal"和"tire"的部分表达。
3、Attention代码实例
暂时没看懂,先空着
4、残差连接
编码器的每个子层(Self Attention 层和 FFNN)都有一个残差连接和层标准化(layer-normalization)。
残差连接(skip connect):

可以使用一个非线性变化函数来描述一个网络的输入输出,即输入为X,输出为F(x),F通常包括了卷积,激活等操作。
当我们强行将一个输入添加到函数的输出的时候,虽然我们仍然可以用G(x)来描述输入输出的关系,但是这个G(x)却可以明确的拆分为F(x)和X的线性叠加。
这就是skip connect的思想,将输出表述为输入和输入的一个非线性变换的线性叠加,没用新的公式,没有新的理论,只是换了一种新的表达。
残差的结构来自于LSTM的控制门的思想: y = H ( x , W H ) • T ( x , W T ) + X • ( 1 − T ( x , W T ) ) y = H(x,WH)•T(x,WT) + X•(1- T(x,WT)) y=H(x,WH)•T(x,WT)+X•(1−T(x,WT)),可以看出,当 T ( x , W T ) = 0 , y = x T(x,WT) = 0,y=x T(x,WT)=0,y=x,当 T ( x , W T ) = 1 T(x,WT) = 1 T(x,WT)=1, y = H ( x , W H ) y= H(x,WH) y=H(x,WH)。
即skip connection: y = H ( x , W H ) + X y = H(x,WH) + X y=H(x,WH)+X
为什么要skip connect?
首先大家已经形成了一个通识,在一定程度上,网络越深表达能力越强,性能越好。
不过,好是好了,随着网络深度的增加,带来了许多问题,梯度消散,梯度爆炸;在resnet出来之前大家没想办法去解决吗?当然不是。更好的优化方法,更好的初始化策略,BN层,Relu等各种激活函数,都被用过了,但是仍然不够,改善问题的能力有限,直到残差连接被广泛使用。
大家都知道深度学习依靠误差的链式反向传播来进行参数更新,假如我们有这样一个函数:

其中的f,g,k大家可以自行脑补为卷积,激活,分类器。
cost对f的导数为:
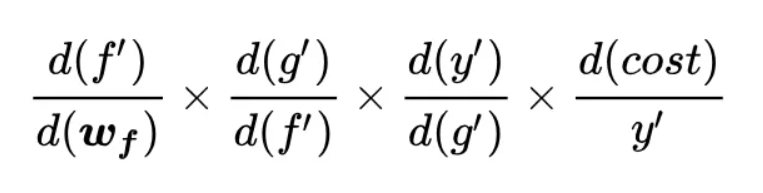
它有隐患,一旦其中某一个导数很小,多次连乘后梯度可能越来越小,这就是常说的梯度消散,对于深层网络,传到浅层几乎就没了。但是如果使用了残差,每一个导数就加上了一个恒等项1,dh/dx=d(f+x)/dx=1+df/dx。此时就算原来的导数df/dx很小,这时候误差仍然能够有效的反向传播,这就是核心思想。
(3)解码器
编码器一般为多层,第一个编码器输入一个序列文本,最后一个编码器输出一个序列向量,这组序列向量会作为解码器的K,V输入。其中K=V=解码器输出的序列向量表示。
解码阶段的每一个时间步都输出一个翻译后的单词,解码器当前时间步的输出又重新作为输入Q,和编码器的输出K、V共同作为下一个时间步解码器的输入。然后重复这个过程,直到输出一个结束符。
解码器中的Self Attention层,和编码器中的Self Attention层的区别:
- 在解码器里,Self Attention 层只允许关注到输出序列中早于当前位置之前的单词。具体做法是:在 Self Attention 分数经过 Softmax 层之前,屏蔽当前位置之后的那些位置(将attention score设置成-inf)。
- 解码器 Attention层是使用前一层的输出来构造Query 矩阵,而Key矩阵和 Value矩阵来自于编码器最终的输出。
(4)线性层和softmax
Decoder 最终的输出是一个向量,其中每个元素是浮点数。
我们怎么把这个向量转换为单词呢?
线性层和softmax完成的。
线性层就是一个普通的全连接神经网络,可以把解码器输出的向量,映射到一个更大的向量,这个向量称为 logits 向量:假设我们的模型有 10000 个英语单词(模型的输出词汇表),此 logits 向量便会有 10000 个数字,每个数表示一个单词的分数。
然后,Softmax 层会把这些分数转换为概率(把所有的分数转换为正数,并且加起来等于 1)。然后选择最高概率的那个数字对应的词,就是这个时间步的输出单词。
(5)损失函数
Transformer训练的时候,需要将解码器的输出和label一同送入损失函数,以获得loss,最终模型根据loss进行方向传播。
我们用一个简单的例子来说明训练过程的loss计算:把“merci”翻译为“thanks”。
我们希望模型解码器最终输出的概率分布,会指向单词 ”thanks“(在“thanks”这个词的概率最高)。但是,一开始模型还没训练好,它输出的概率分布可能和我们希望的概率分布相差甚远,如下图所示,正确的概率分布应该是“thanks”单词的概率最大。但是,由于模型的参数都是随机初始化的,所示一开始模型预测所有词的概率几乎都是随机的。
使用解码器预测出的组概率,与正确的概率做对比,然后使用反向传播来调整模型的权重,使得概率分布更加接近整数输出。
我们可以尝试以两组概率向量的空间距离作为loss(损失函数),即向量之间数值相减,求平方和然会再开方。也可以使用交叉熵(cross-entropy)]和KL 散度(Kullback–Leibler divergence)。
如果是在多个单词的句子中,transformer模型解码器需要多次输出概率分布向量:
- 每次输出的概率分布都是一个向量,长度是 vocab_size(前面约定最大vocab size,也就是向量长度是 6,但实际中的vocab size更可能是 30000 或者 50000)
- 第1次输出的概率分布中,最高概率对应的单词是 “i”
- 第2次输出的概率分布中,最高概率对应的单词是 “am”
- 以此类推,直到第 5 个概率分布中,最高概率对应的单词是 “”,表示没有下一个单词了
我们用例子中的句子训练模型,希望产生图中所示的概率分布,我们的模型在一个足够大的数据集上,经过足够长时间的训练后,希望输出的概率分布如下图所示。
模型训练后输出的多个概率分布:

(6)名词解释:
1、词嵌入算法:词嵌入(word embedding) 是文本表示的一类方法。词嵌入是自然语言处理(NLP)中语言模型与表征学习技术的统称。概念上而言,它是指把一个维数为所有词的数量的高维空间嵌入到一个维数低得多的连续向量空间中,每个单词或词组被映射为实数域上的向量。
词嵌入的方法包括人工神经网络、对词语同现矩阵降维、概率模型以及单词所在上下文的显式表示等。
在底层输入中,使用词嵌入来表示词组的方法极大提升了NLP中语法分析器和文本情感分析等的效果。
词嵌入的优点:
- 他可以将文本通过一个低维向量来表达,不像 one-hot 那么长。
- 语意相似的词在向量空间上也会比较相近。
- 通用性很强,可以用在不同的任务中。

2、独热编码(one-hot representation):独热编码是将分类变量转换为可提供给机器学习算法更好地进行预测的形式的过程。 一种稀疏向量,其中:一个元素设为 1;所有其他元素均设为 0。 one-hot 编码常用于表示拥有有限个可能值的字符串或标识符。
假如我们要计算的文本中一共出现了4个词:猫、狗、牛、羊。向量里每一个位置都代表一个词。所以用 one-hot 来表示就是:
猫:[1,0,0,0]
狗:[0,1,0,0]
牛:[0,0,1,0]
羊:[0,0,0,1]

但是在实际情况中,文本中很可能出现成千上万个不同的词,这时候向量就会非常长。其中99%以上都是 0。
one-hot 的缺点如下:
- 无法表达词语之间的关系
- 这种过于稀疏的向量,导致计算和存储的效率都不高
3、全连接神经网络:
各种神经网络都是基于全连接神经网络出发的,最基础的原理都是由反向传播而来。
全连接神经网络示意图:

左边输入,中间计算,右边输出。
全连接神经网络运算示意图:
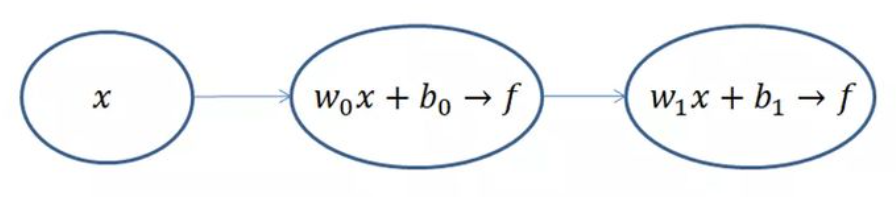
z
=
w
x
+
b
z=wx+b
z=wx+b
f
(
z
)
=
1
/
e
−
z
f(z)=1/e^{-z}
f(z)=1/e−z
每一级都是利用前一级的输出做输入,再经过圆圈内的组合计算,输出到下一级。
f(z)这个运算的目的是为了将输出的值域压缩到(0,1),也就是所谓的归一化,因为每一级输出的值都将作为下一级的输入,只有将输入归一化了,才会避免某个输入无穷大,导致其他输入无效,变成“一家之言”,最终网络训练效果非常不好。
反向传播示意图:

神经网络的训练是有监督的学习,也就是输入X 有着与之对应的真实值Y ,神经网络的输出Y 与真实值Y 之间的损失Loss 就是网络反向传播的东西。整个网络的训练过程就是不断缩小损失Loss 的过程。

上述的公式经过化简,我们可以看到A、B、C、D、E、F都是常系数,未知数就是w 和b ,也就是为了让Loss 最小,我们要求解出最佳的w 和b 。这时我们稍微想象一下,如果这是个二维空间,那么我们相当于要找一条曲线,让它与坐标轴上所有样本点距离最小。
曲线拟合图:

同理,我们可以将Loss 方程转化为一个三维图像求最优解的过程。三维图像就像一个“碗”,它和二维空间的抛物线一样,存在极值,那我们只要将极值求出,那就保证了我们能求出最优的(w , b)也就是这个“碗底”的坐标,使Loss 最小。
三维图像示意图:

如何求解呢?
要求极值,首先求导。
三维空间中:
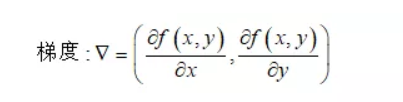
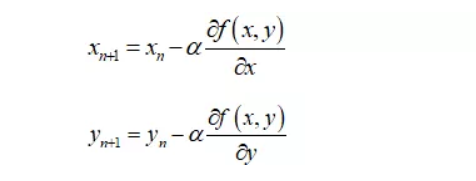
多维空间中(也是对各个维度求偏导,更新自己的坐标。):
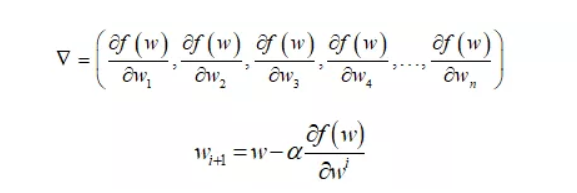
我们可以将整个求解过程看做下山(求偏导过程),为此,我们先初始化自己的初始位置。

这样我们不断地往下走(迭代),当我们逐渐接近山底的时候,每次更新的步伐也就越来越小,损失值也就越来越小,直到达到某个阈值或迭代次数时,停止训练,这样找到 就是我们要求的解。
我们将整个求解过程称为梯度下降求解法。
4、Greedy decoding:由于模型每个时间步只产生一个输出,我们这样看待:模型是从概率分布中选择概率最大的词,并且丢弃其他词。这种方法叫做贪婪解码(greedy decoding)。
5、Beam search:每个时间步保留k个最高概率的输出词,然后在下一个时间步,根据上一个时间步保留的k个词来确定当前应该保留哪k个词。假设k=2,第一个位置概率最高的两个输出的词是”I“和”a“,这两个词都保留,然后根据第一个词计算第2个位置的词的概率分布,再取出第2个位置上2个概率最高的词。对于第3个位置和第4个位置,我们也重复这个过程。这种方法称为集束搜索(beam search)。
6、softmax回归:和sigmoid的函数很类似,但是做了归一化。

-
一个简单的图像分类问题,输入图像的高和宽均为2像素,色彩为灰度。
图像中的4像素分别记为 x 1 , x 2 , x 3 , x 4 x_1,x_2,x_3,x_4 x1,x2,x3,x4。
假设真实标签为狗、猫或者鸡,这些标签对应的离散值为 y 1 , y 2 , y 3 y_1,y_2,y_3 y1,y2,y3。
我们通常使用离散的数值来表示类别,例如 y 1 = 1 , y 2 = 2 , y 3 = 3 y_1=1,y_2=2,y_3=3 y1=1,y2=2,y3=3。 -
权重矢量
o 1 = x 1 w 11 + x 2 w 21 + x 3 w 31 + x 4 w 41 + + b 1 o_1=x_1w_{11}+x_2w_{21}+x_3w_{31}+x_4w_{41}++b_1 o1=x1w11+x2w21+x3w31+x4w41++b1
o 3 = x 1 w 13 + x 2 w 23 + x 3 w 33 + x 4 w 43 + + b 3 o_3=x_1w_{13}+x_2w_{23}+x_3w_{33}+x_4w_{43}++b_3 o3=x1w13+x2w23+x3w33+x4w43++b3 -
神经网络图
下图用神经网络图描绘了上面的计算。softmax回归同线性回归一样,也是一个单层神经网络。由于每个输出 o 1 , o 2 , o 3 o_1,o_2,o_3 o1,o2,o3的计算都要依赖于所有的输入 x 1 , x 2 , x 3 , x 4 x_1,x_2,x_3,x_4 x1,x2,x3,x4,softmax回归的输出层也是一个全连接层。
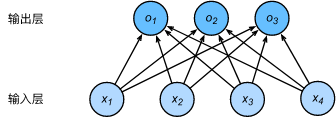
即,softmax回归是一个单层神经网络。
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









