







RDD 本质上是一个只读的分区记录集合
首先
from pyspark import SparkConf, SparkContext
conf = SparkConf().setMaster("local").setAppName("My App")
sc = SparkContext(conf = conf)
文件保存:
lines.saveAsTextFile(图片路径)
json 文件的读取和写
from pyspark import SparkContext
import json
import sys
if __name__ == "__main__":
if len(sys.argv) != 4:
print "Error usage: LoadJson [sparkmaster] [inputfile] [outputfile]"
sys.exit(-1)
master = sys.argv[1]
inputFile = sys.argv[2]
outputFile = sys.argv[3]
sc = SparkContext(master, "LoadJson")
input = sc.textFile(inputFile)
data = input.map(lambda x: json.loads(x))
data.filter(lambda x: 'lovesPandas' in x and x['lovesPandas']).map(
lambda x: json.dumps(x)).saveAsTextFile(outputFile)
sc.stop()
print "Done!"
CSV文件的读取和写
from pyspark import SparkContext
import csv
import sys
import StringIO
def loadRecord(line):
"""Parse a CSV line"""
input = StringIO.StringIO(line)
reader = csv.DictReader(input, fieldnames=["name", "favouriteAnimal"])
return reader.next()
def loadRecords(fileNameContents):
"""Load all the records in a given file"""
input = StringIO.StringIO(fileNameContents[1])
reader = csv.DictReader(input, fieldnames=["name", "favouriteAnimal"])
return reader
def writeRecords(records):
"""Write out CSV lines"""
output = StringIO.StringIO()
writer = csv.DictWriter(output, fieldnames=["name", "favouriteAnimal"])
for record in records:
writer.writerow(record)
return [output.getvalue()]
if __name__ == "__main__":
if len(sys.argv) != 4:
print "Error usage: LoadCsv [sparkmaster] [inputfile] [outputfile]"
sys.exit(-1)
master = sys.argv[1]
inputFile = sys.argv[2]
outputFile = sys.argv[3]
sc = SparkContext(master, "LoadCsv")
# Try the record-per-line-input
input = sc.textFile(inputFile)
data = input.map(loadRecord)
pandaLovers = data.filter(lambda x: x['favouriteAnimal'] == "panda")
pandaLovers.mapPartitions(writeRecords).saveAsTextFile(outputFile)
# Try the more whole file input
fullFileData = sc.wholeTextFiles(inputFile).flatMap(loadRecords)
fullFilePandaLovers = fullFileData.filter(
lambda x: x['favouriteAnimal'] == "panda")
fullFilePandaLovers.mapPartitions(
writeRecords).saveAsTextFile(outputFile + "fullfile")
sc.stop()
print "Done!"
sparkwordcount.txt 的内容如下:

1 RDD创建
1. 从文件系统中加载数据创建RDD
Spark采用textFile()方法来从文件系统中加载数据创建RDD
该方法把文件的URI作为参数,这个URI可以是:
- 本地文件系统的地址
# 从本地系统中加载数据
lines = sc.textFile("file:///home/hadoop/MyTmp/sparkwordcount.txt")
lines.foreach(print) #循环遍历文件的每一行
- 或者是分布式文件系统HDFS的地址
# 从分布式文件系统 HDFS 中加载数据
lines = sc.textFile("hdfs://localhost:9000/user/hadoop/sparkwordspace/sparkwordcount.txt")
lines.foreach(print) #循环遍历文件的每一行
- 或者是Amazon S3的地址等等
这个不会~~
2. 通过并行集合(列表)创建RDD
# 通过并行集合(列表)创建 RDD
# 可以调用 SparkContext 的 parallelize 方法,在 Driver 中一个已经存在的集合 (列表)上创建。
array = [1,2,3,4,5]
rdd = sc.parallelize(array)
rdd.foreach(print)
2 RDD操作
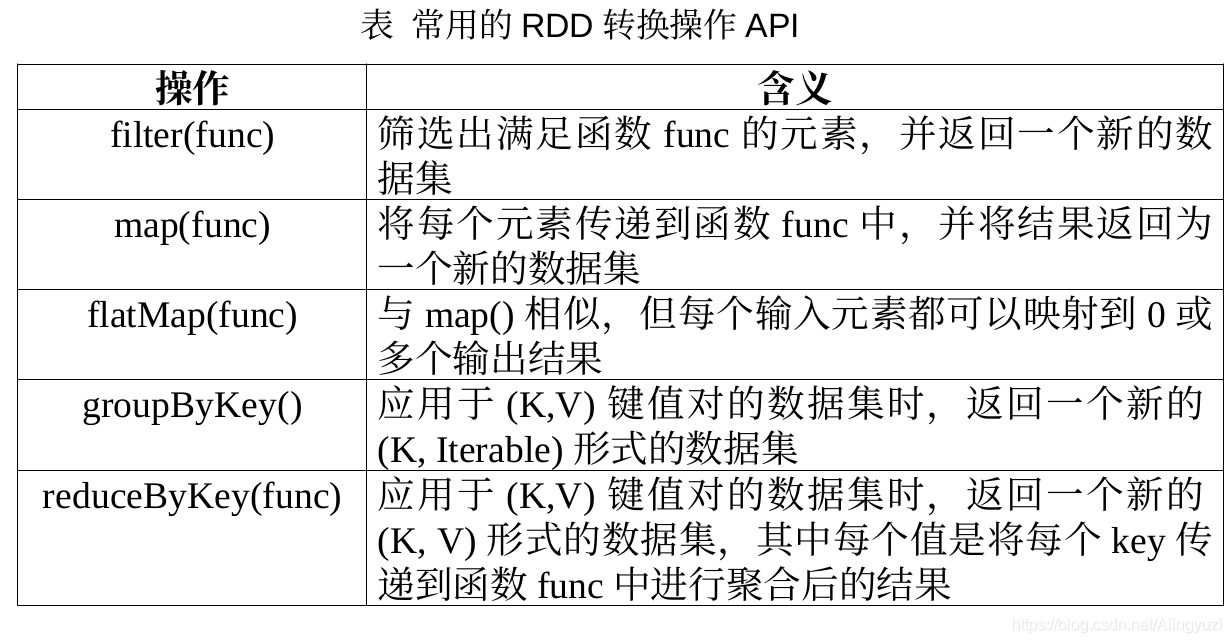
1. 转换操作
• 对于 RDD 而言,每一次转换操作都会产生不同的 RDD ,供给下一个“转换”使用
• 转换得到的 RDD 是惰性求值的,也就是说,整个转换过程只是记录了转换的轨迹,并不会发生真正的计算,只有遇到行动操作时,才会发生真正的计算,开始从血缘关系源头开始,进行物理的转换操作。
filter(func) :筛选出满足函数 func 的元素,并返回一个新的数据集
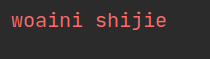
lines = sc.textFile("file:///home/hadoop/MyTmp/sparkwordcount.txt")
linesWith_woaini = lines.filter(lambda line: "woaini" in line)
linesWith_woaini.foreach(print)
结果如下:
map(func) :将每个元素传递到函数 func 中,并将结果返回为一个新的数据集
data = [1,2,3,4,5]
rdd1 = sc.parallelize(data)
rdd1.foreach(print)
print("*"*50)
rdd2 = rdd1.map(lambda x:x+10)#rdd1中的每个元素进行加10操作
rdd2.foreach(prt)
结果如下:

map(func)另外一个实例
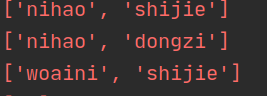
lines = sc.textFile("file:///home/hadoop/MyTmp/sparkwordcount.txt")
words = lines.map( lambda line:line.split(" ")) #对每行进行空格拆分,得到列表类型
words.foreach(print)
结果如下:
**flatMap(func)**与map() 相似,但每个输入元素都可以映射到0或多个输出结果
lines = sc.textFile("file:///home/hadoop/MyTmp/sparkwordcount.txt")
word = lines.flatMap(lambda line :line.split(" "))
word.foreach(print)
结果如下:
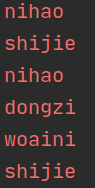
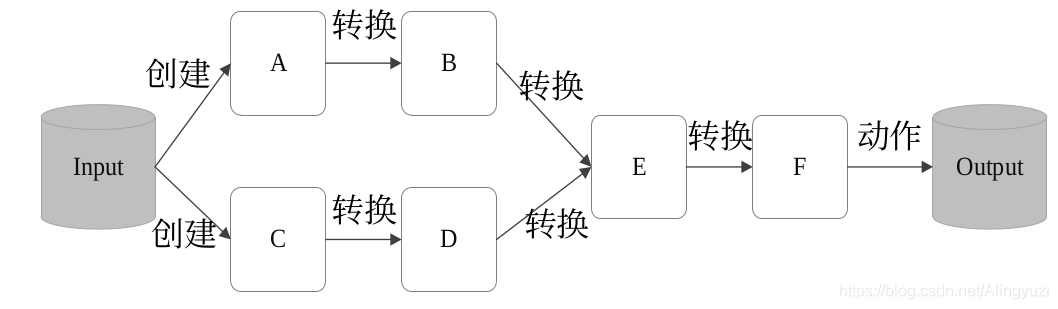
下图为flatmap的操作流程,图来源于网络
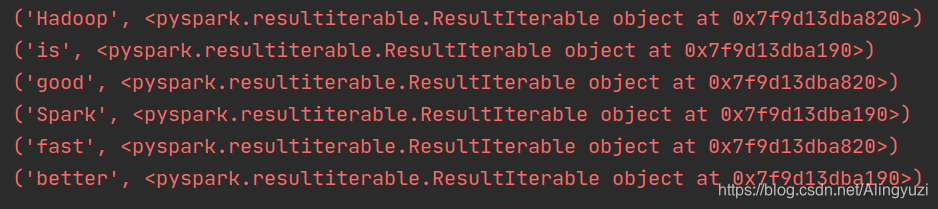
groupByKey() 应用于 (K,V) 键值对的数据集时,返回一个新的 (K, Iterable) 形式的数据集
words = sc.parallelize([("Hadoop",1),("is",1),("good",1), ("Spark",1),("is",1),("fast",1),("Spark",1),("is",1),("better",1)])
words1 = words.groupByKey()
words1.foreach(print)
结果如下:
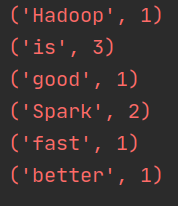
reduceByKey(func) 应用于 (K,V) 键值对的数据集时,返回一个新的 (K, V)形式的数据集,其中的每个值是将每个 key 传递到函数 func 中进行聚合后得到的结果
words = sc.parallelize([("Hadoop",1),("is",1),("good",1), ("Spark",1),("is",1),("fast",1),("Spark",1),("is",1),("better",1)])
words1 = words.reduceByKey(lambda a,b:a+b)
words1.foreach(print)
结果如下:
3 持久化
在 Spark 中, RDD 采用惰性求值的机制,每次遇到行动操作,都会从头开始 执行计算。每次调用行动操作,都会触发一次从头开始的计算。这对于迭代计算而言,代价是很大的,迭代计算经常需要多次重复使用同一组数据。
解决方案:
• 可以通过持久化(缓存)机制避免这种重复计算的开销
• 可以使用 persist() 方法对一个 RDD 标记为持久化
• 之所以说“标记为持久化”,是因为出现 persist() 语句的地方,并不会马上计算生成 RDD 并把它持久化,而是要等到遇到第一个行动操作触发真正计算以后,才会把计算结果进行持久化
• 持久化后的 RDD 将会被保留在计算节点的内存中被后面的行动操作重复使用
persist() 的使用
persist() 的圆括号中包含的是持久化级别参数:
•persist(MEMORY_ONLY) :表示将 RDD 作为反序列化的对象存储于 JVM 中,如果内存不足,就要按照 LRU 原则替换缓存中的内容
•persist(MEMORY_AND_DISK) 表示将 RDD 作为反序列化的对象存储在 JVM 中,如果内存不足,超出的分区将会被存放在硬盘上
• 一般而言,使用 cache() 方法时,会调用persist(MEMORY_ONLY)
• 可以使用 unpersist() 方法手动地把持久化的 RDD 从缓存中移除
持久化级别
| 级别 | 使用的空间 | cpu时间 | 是否在内存中 | 是否在磁盘中 | 备注 |
|---|---|---|---|---|---|
| MEMORY_ONLY | 高 | 低 | 是 | 否 | |
| MEMORY_ONLY_SER | 低 | 高 | 是 | 否 | |
| MEMORY_AND_DISK | 高 | 中等 | 部分 | 部分 | 如果数据在内存中放不下,则溢写到磁盘上 |
| MEMORY_AND_DISK_SER | 低 | 高 | 部分 | 部分 | 如果数据在内存中放不下,则溢写到磁盘上。在内存中存放序列化后的数据 |
| DISK_ONLY | 低 | 高 | 否 | 是 |
array = ["hadoop","spark","Hive"]
rdd = sc.parallelize(array)
rdd.cache()# 会调用 persist(MEMORY_ONLY) ,但是,语句执行到这里,并不会缓存 rdd ,因为这时 rdd 还没有被计算生成
print(rdd.count()) # 第一次行动操作,触发一次真正从头到尾的计算,这时上面的 rdd.cache() 才会被执行,把这个 rdd 放到缓存中
print(','.join(rdd.collect())) # 第二次行动操作,不需要触发从头到尾的计算,只需要重复使用上面缓存中的 rdd
rdd.unpersist() # 手动地把持久化的 RDD 从缓存中移除
4 分区
在分布式程序中,通信的代价是很大的,因此控制数据分布以获得最少的网络传输可以极大的提升整体性能。spark程序可以通过控制rdd分区方式来减少通信开销。
RDD分区原则
RDD 分区的一个原则是使得分区的个数尽量等于集群中的 CPU 核心( core )数目
对于不同的 Spark 部署模式而言(本地模式、 Standalone 模式、 YARN 模式、 Mesos 模式),都可以通过设置
spark.default.parallelism 这个参数的值,来配置默认的分区数目,
一般而言:
本地模式:默认为本地机器的 CPU 数目,若设置了 local[N], 则默认为 N
Apache Mesos :默认的分区数为 8
Standalone 或 YARN :在“集群中所有 CPU 核心数目总和”和“ 2” 二者中取较大值作为默认值
设置分区
1.创建 RDD 时手动指定分区个数
在调用 textFile() 和 parallelize() 方法的时候手动指定分区个数即可,语法格式如下:
#sc.textFile(path, partitionNum)其中, path 参数用于指定要加载的文件的地址, partitionNum 参数用于指定分区个数。
textFile() 方法
lines = sc.textFile("file:///home/hadoop/MyTmp/sparkwordcount.txt",2) # 设置两个分区
parallelize() 方法
array = [1,2,3,4]
rdd = sc.parallelize(array,2) # 设置两个分区
2 使用 reparititon 方法重新设置分区个数
通过转换操作得到新 RDD 时,直接调用 repartition 方法即可
# ( 2 )使用 reparititon 方法重新设置分区个数
# 通过转换操作得到新 RDD 时,直接调用 repartition 方法即可。例如:
array = [1,2,3,4,5]
data = sc.parallelize(array,2)
print(len(data.glom().collect())) # 显示 data 这个 RDD 的分区数量
rdd = data.repartition(1) # 对 data 这个 RDD 进行重新分区
print(len(rdd.glom().collect())) # 显示 rdd 这个 RDD 的分区数量
自定义分区
Spark 提供了自带的 HashPartitioner (哈希分区)与 RangePartitioner (区域分区),能够满足大多数应用场景的需求。与此同时, Spark 也支持自定义分区方式,即通过提供一个自定义的分区函数来控制 RDD 的分区方式,从而利用领域知识进一步减少通信开销
实例:根据 key 值的最后一位数字,写到不同的文件
例如:
10 写入到 part-00000
11 写入到 part-00001
.
.
.
19 写入到 part-00009
from pyspark import SparkConf, SparkContext
def MyPartitioner(key): #
print("MyPartitioner is running")
print('The key is %d' % key)
return key%10
def main():
print("The main function is running")
conf = SparkConf().setMaster("local").setAppName("MyApp")
sc = SparkContext(conf = conf)
data = sc.parallelize(range(10),5)
# partitionBy(10, MyPartitioner) 设置10个分区,按照自定义分区方法分区
data.map(lambda x:(x,1)) \
.partitionBy(10,MyPartitioner) \
.map(lambda x:x[0])\
.saveAsTextFile("file:///home/hadoop/MyTmp/sparkoutput20201204")
if __name__ == '__main__':
main()
5 一个综合实例
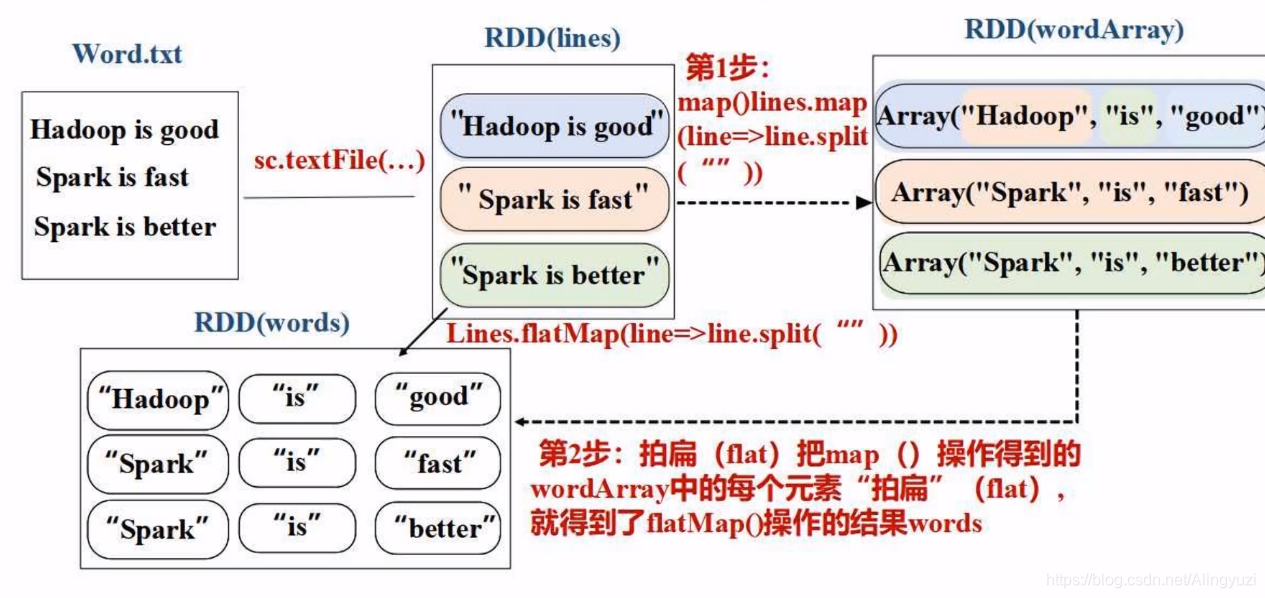
假设有一个本地文件 word.txt ,里面包含了很多行文本,每行文本由多个单词构成,单词之间用空格分隔。可以使用如下语句进行词频统计(即统计每个单词出现的次数):














 665
665











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









