







- 从 Spark2.0 以上版本开始, Spark 使用全新的 SparkSession 接口替代 Spark1.6 中的
SQLContext 及HiveContext 接口来实现其对数据加载、转换、处理等功能。 SparkSession 实现了
SQLContext 及HiveContext 所有功能。 SparkSession 支持从不同的数据源加载数据,并把数据转换成 - DataFrame ,并且支持把 DataFrame 转换成 SQLContext 自身中的表 ,然后使用 SQL 语句来操作数据。
SparkSession 亦提供了 HiveQL 以及其他依赖于 Hive 的功能的支持
创建SparkSession对象
在pycharm上就需要自己创建!
from pyspark import SparkContext,SparkConf
from pyspark.sql import SparkSession
spark = SparkSession.builder.config(conf = SparkConf()).getOrCreate()
实际上,在启动进入 pyspark 以后, pyspark 就默认提供了一个SparkContext 对象(名称为 sc )和一个 SparkSession 对象(名称为 spark )
DataFrame 的创建
在创建 DataFrame 时,可以使用 spark.read 操作,从不同类型的文件中加载数据创建 DataFrame ,例如:
- spark.read.text(“people.txt”) :读取文本文件 people.txt 创建DataFrame
- spark.read.json(“people.json”) :读取 people.json 文件创建DataFrame ;在读取本地文件或 HDFS 文件时,要注意给出正确的文件路径
- spark.read.parquet(“people.parquet”) :读取 people.parquet 文件创建 DataFrame
或者也可以使用如下格式的语句:
- spark.read.format(“text”).load(“people.txt”) :读取文本文件people.json 创建DataFrame ;
- spark.read.format(“json”).load(“people.json”) :读取 JSON 文件people.json 创建 DataFrame ;
- spark.read.format(“parquet”).load(“people.parquet”) :读取Parquet 文件people.parquet 创建 DataFrame
例子如下:
# 创建SparkSession对象
from pyspark import SparkContext,SparkConf
from pyspark.sql import SparkSession
spark = SparkSession.builder.config(conf = SparkConf()).getOrCreate()
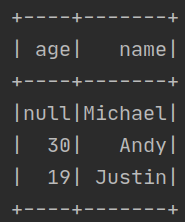
df = spark.read.json("file:///usr/local/spark/examples/src/main/resources/people.json")
df.show()
运行结果如下:
DataFrame 的保存
可以使用 spark.write 操作,把一个 DataFrame 保存成不同格式的文件,例如,把一个名称为 df 的 DataFrame 保存到不同格式文件中,方法如下:
df.write.text(“people.txt”)
df.write.json("people.json“)
df.write.parquet("people.parquet“)
或者也可以使用如下格式的语句:
df.write.format(“text”).save(“people.txt”)
df.write.format(“json”).save(“people.json”)
df.write.format(“parquet”).save(“people.parquet”)
示例文件 people.json 中创建一个 DataFrame ,名称为peopleDF ,把 peopleDF 保存到另外一个 JSON 文件中,然后,再从 peopleDF 中选取一个列(即 name 列),把该列数据保存到一个文本文件中.
# 创建SparkSession对象
from pyspark import SparkContext,SparkConf
from pyspark.sql import SparkSession
spark = SparkSession.builder.config(conf = SparkConf()).getOrCreate()
# 示例文件 people.json 中创建一个 DataFrame ,名称为peopleDF ,把 peopleDF 保存到另外一个 JSON 文件中,然后,再从 peopleDF 中选取一个列(即 name 列),把该列数据保存到一个文本文件中
peopleDF = spark.read.format("json").load("file:///usr/local/spark/examples/src/main/resources/people.json")
peopleDF.select("name", "age").write.format("json").save("file:///home/hadoop/MyTmp/newpeople.json")
peopleDF.select("name").write.format("text").save("file:///home/hadoop/MyTmp/newpeople.txt")
DataFrame 的常用操作
显示DataFrame 的模式信息
from pyspark import SparkContext,SparkConf
from pyspark.sql import SparkSession
spark = SparkSession.builder.config(conf = SparkConf()).getOrCreate()
df = spark.read.format("json").load("file:///usr/local/spark/examples/src/main/resources/people.json")
print(df.printSchema)
运行结果如下:

select():查看DataFrame 的列信息
from pyspark import SparkContext,SparkConf
from pyspark.sql import SparkSession
spark = SparkSession.builder.config(conf = SparkConf()).getOrCreate()
df = spark.read.format("json").load("file:///usr/local/spark/examples/src/main/resources/people.json")
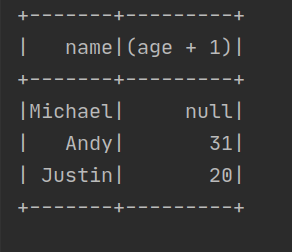
df.select(df["name"],df["age"]+1).show()
运行结果如下:
filter():过滤出符合条件的值
from pyspark import SparkContext,SparkConf
from pyspark.sql import SparkSession
spark = SparkSession.builder.config(conf = SparkConf()).getOrCreate()
df = spark.read.format("json").load("file:///usr/local/spark/examples/src/main/resources/people.json")
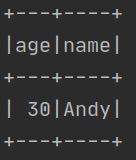
df.filter(df["age"]>20).show()
运行结果如下:
groupBy() :根据XX来分组
from pyspark import SparkContext,SparkConf
from pyspark.sql import SparkSession
spark = SparkSession.builder.config(conf = SparkConf()).getOrCreate()
# groupBy()
df = spark.read.format("json").load("file:///usr/local/spark/examples/src/main/resources/people.json")
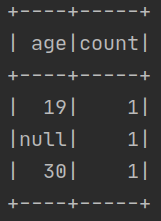
df.groupBy("age").count().show()
运行结果如下:
sort() 排序
from pyspark import SparkContext,SparkConf
from pyspark.sql import SparkSession
spark = SparkSession.builder.config(conf = SparkConf()).getOrCreate()
df = spark.read.format("json").load("file:///usr/local/spark/examples/src/main/resources/people.json")
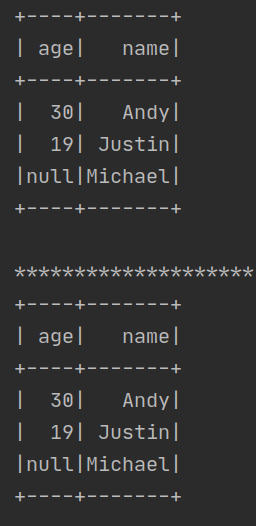
df.sort(df["age"].desc()).show()
print("*"*20)
df.sort(df["age"].desc(),df["name"].asc()).show()
运行结果如下:
从 RDD 转换得到 DataFrame
利用反射机制推断 RDD 模式
在“ /usr/local/spark/examples/src/main/resources/” 目录下,有个Spark 安装时自带的样例数据 people.txt ,其内容如下:

现在要把 people.txt 加载到内存中生成一个 DataFrame ,并查询其中的数据
from pyspark.sql import Row
# 创建SparkSession对象
from pyspark import SparkContext,SparkConf
from pyspark.sql import SparkSession
spark = SparkSession.builder.config(conf = SparkConf()).getOrCreate()
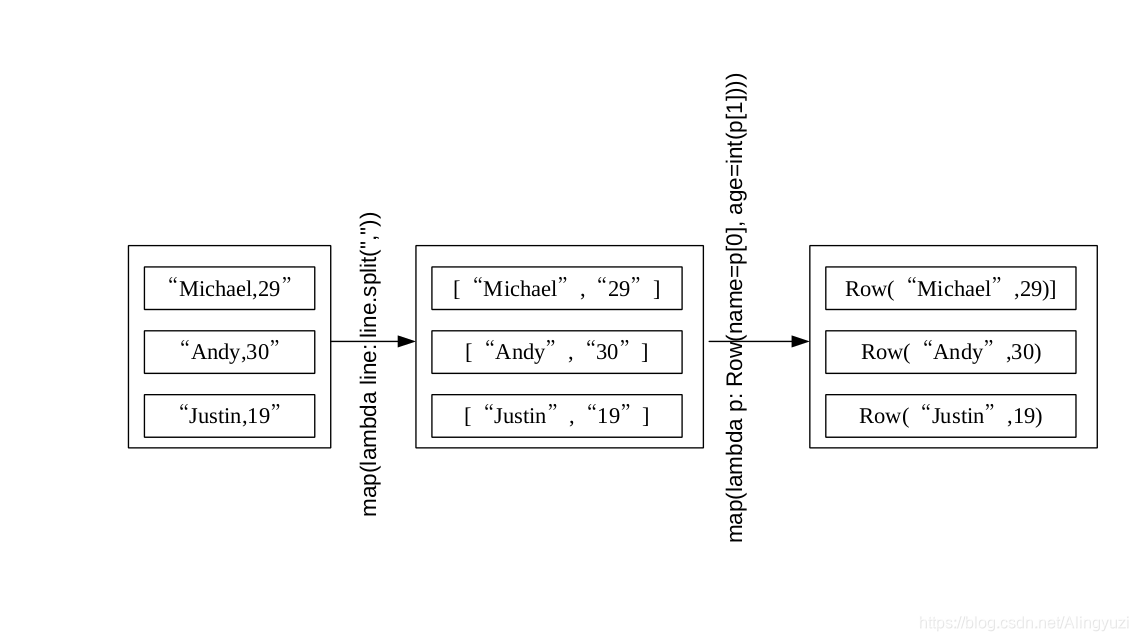
people = spark.sparkContext.textFile("file:///usr/local/spark/examples/src/main/resources/people.txt").\
map(lambda line :line.split(",")).map(lambda p:Row(name = p[0],age=int(p[1])))
schemaPeople = spark.createDataFrame(people)
# 必须注册为临时表才能供下面的查询使用
schemaPeople.createOrReplaceTempView("people")
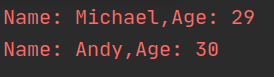
personsDF = spark.sql("select name,age from people where age > 20")
#DataFrame 中的每个元素都是一行记录,包含 name 和 age 两个字段,分别用 p.name 和 p.age 来获取值
personsRDD=personsDF.rdd.map(lambda p:"Name: "+p.name+","+"Age: "+str(p.age))
personsRDD.foreach(print)
运行结果如下:
原理:
使用编程方式定义 RDD 模式
当无法提前获知数据结构时,就需要采用编程方式定义 RDD 模式。比如,现在需要通过编程方式把 people.txt 加载进来生成DataFrame ,并完成 SQL 查询。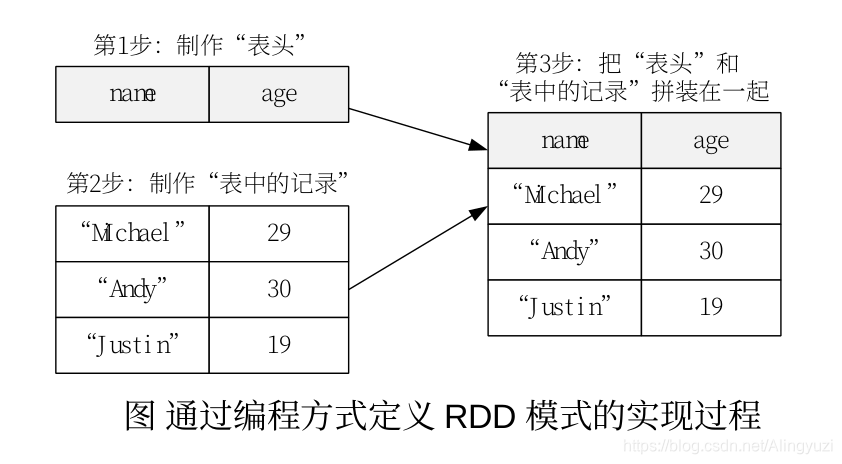
# 创建SparkSession对象
from pyspark import SparkContext,SparkConf
from pyspark.sql import SparkSession
spark = SparkSession.builder.config(conf = SparkConf()).getOrCreate()
from pyspark.sql import Row
from pyspark.sql.types import *
# 下面生成“表头”
schemaString = "name age"
fields = [StructField(field_name, StringType(), True) for field_name in schemaString.split(" ")]
schema = StructType(fields)
# 下面生成“表中的记录”
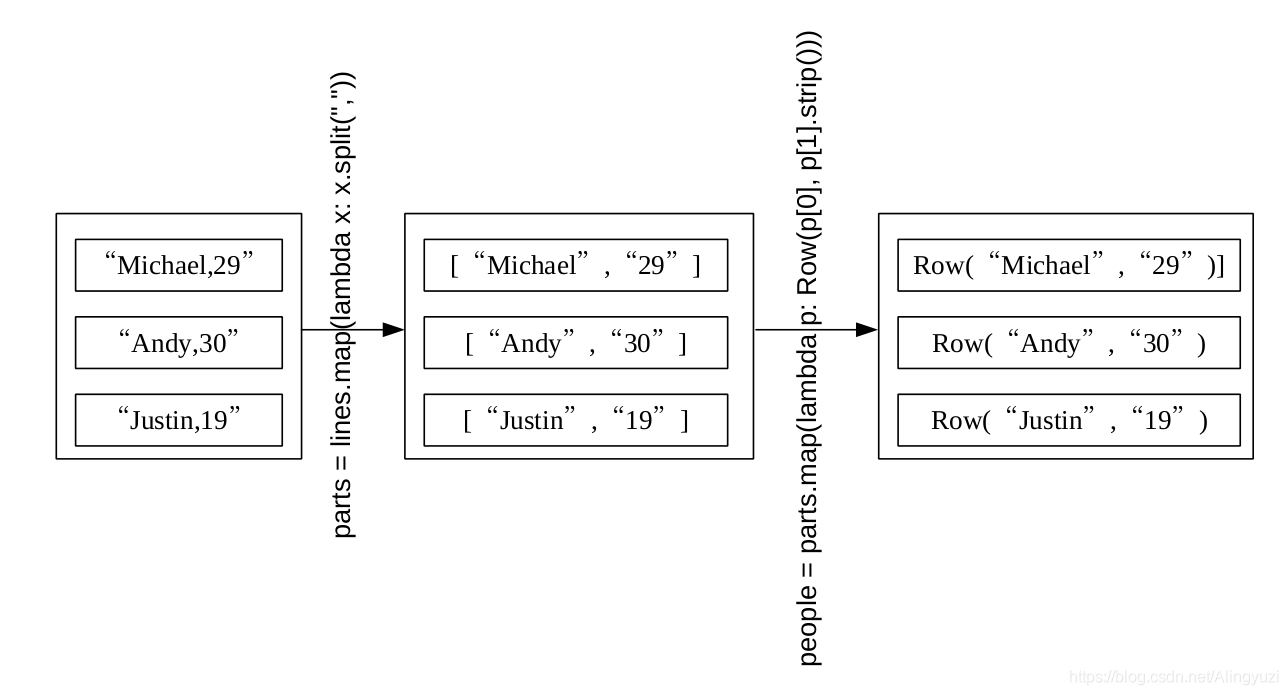
lines = spark.sparkContext.textFile("file:///usr/local/spark/examples/src/main/resources/people.txt")
parts = lines.map(lambda x: x.split(","))
people = parts.map(lambda p: Row(p[0], p[1].strip()))
# 下面把“表头”和“表中的记录”拼装在一起
schemaPeople = spark.createDataFrame(people, schema)
# 注册一个临时表供下面查询使用
schemaPeople.createOrReplaceTempView("people")
results = spark.sql("SELECT name,age FROM people")
results.show()
运行结果:
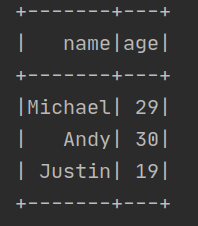
原理:














 157
157











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









