







- 创建项目与爬虫

- 查看网页源码并分析
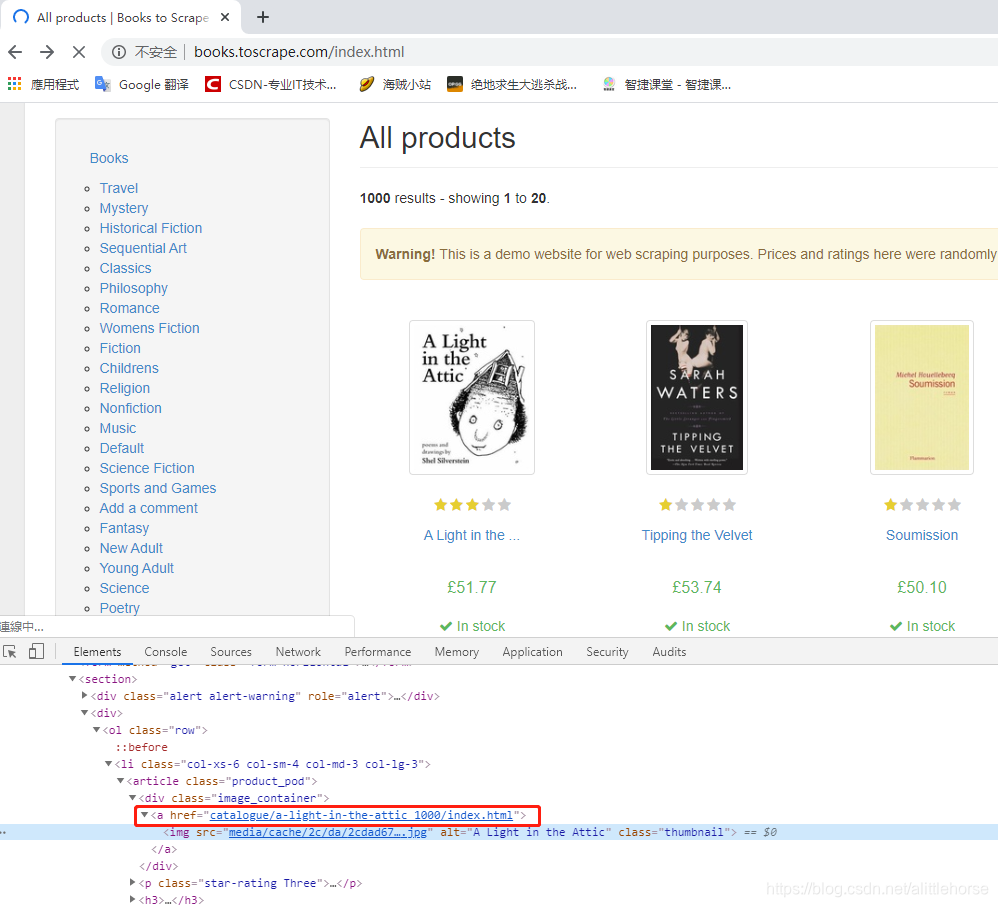
- 分析须爬取内容
- 内容位于网页中的位置
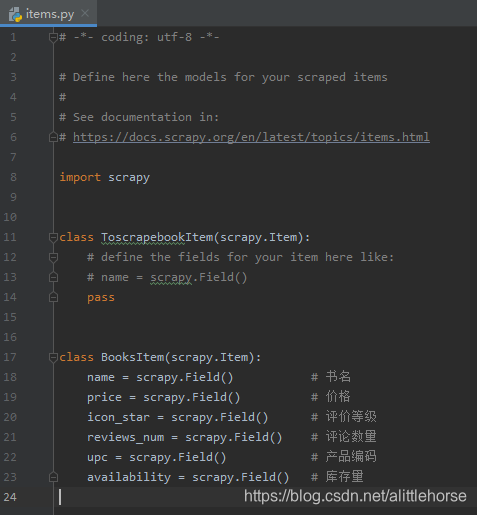
- 封装Item
根据分析需要爬取内容建立Item对象
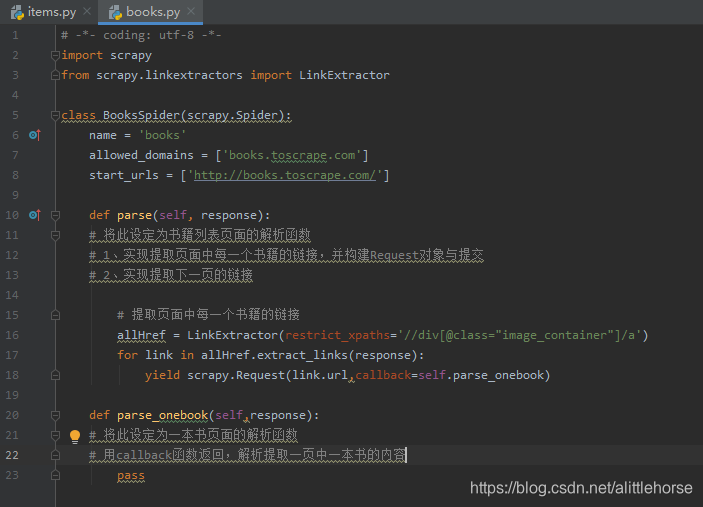
- 查看内容位于网页中的位置,并用scrapy shell测试是否能正常获取所需要的值
获取成功 LinkExtractor方法可以成功获取链接

- 以此方法建立解析函数 prase
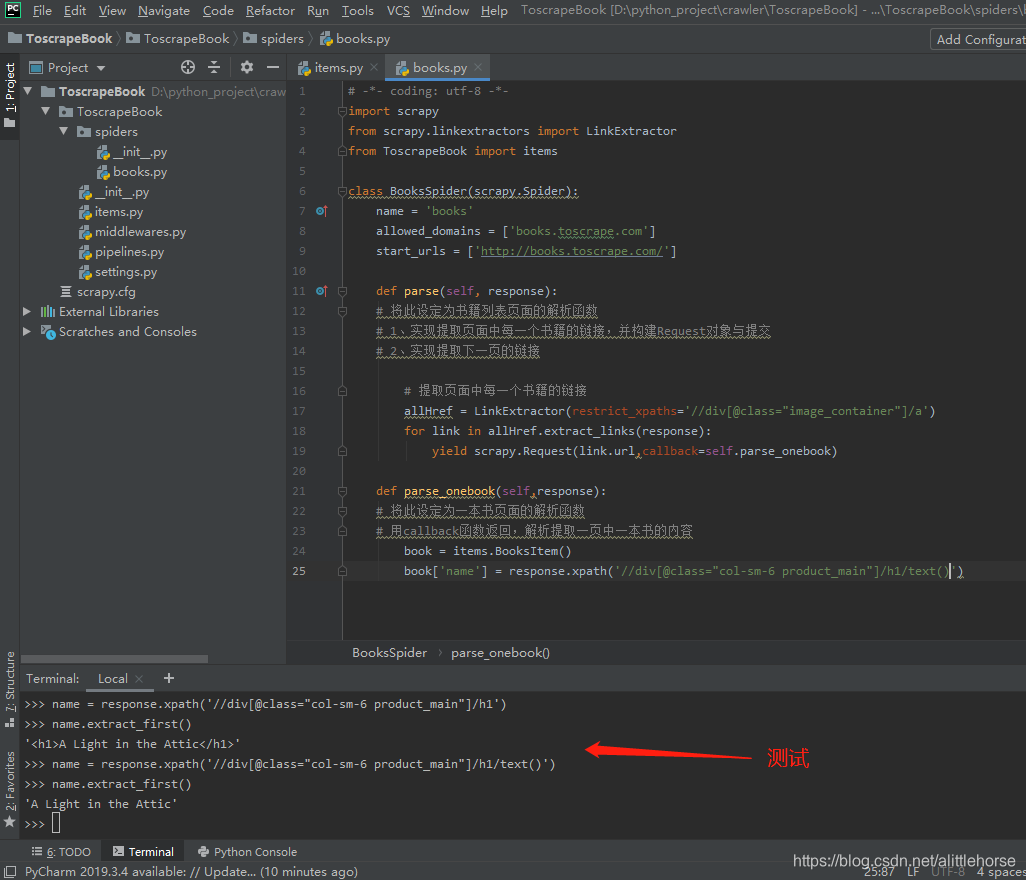
- 根据第二、第三点步骤分析得出单一书本页面需爬取内容与页面位置
如:
书名
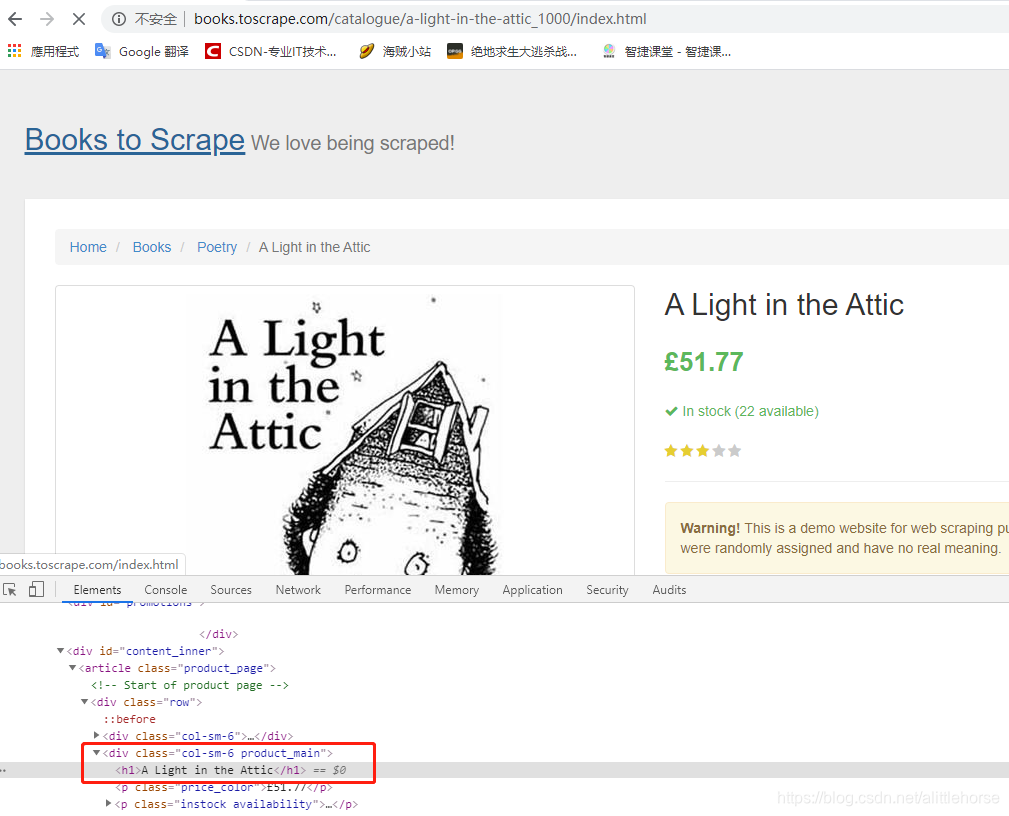
评价等级
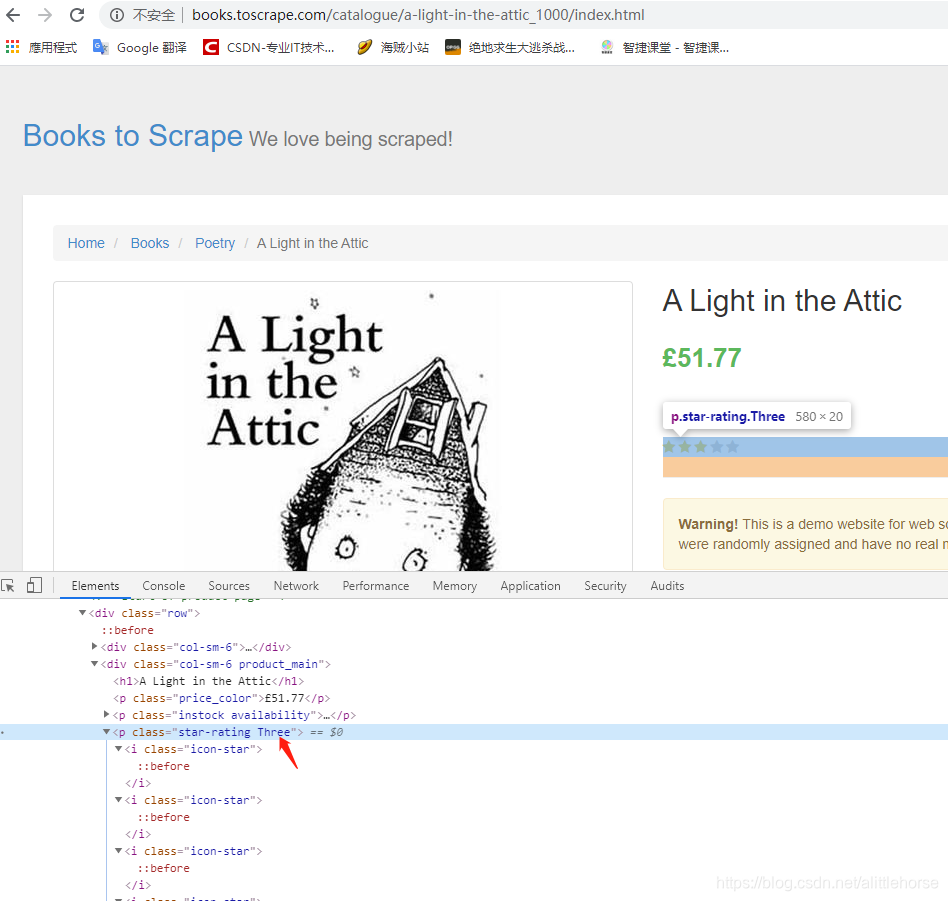
再次进入shell中测试
- 根据一切方法匹配到值
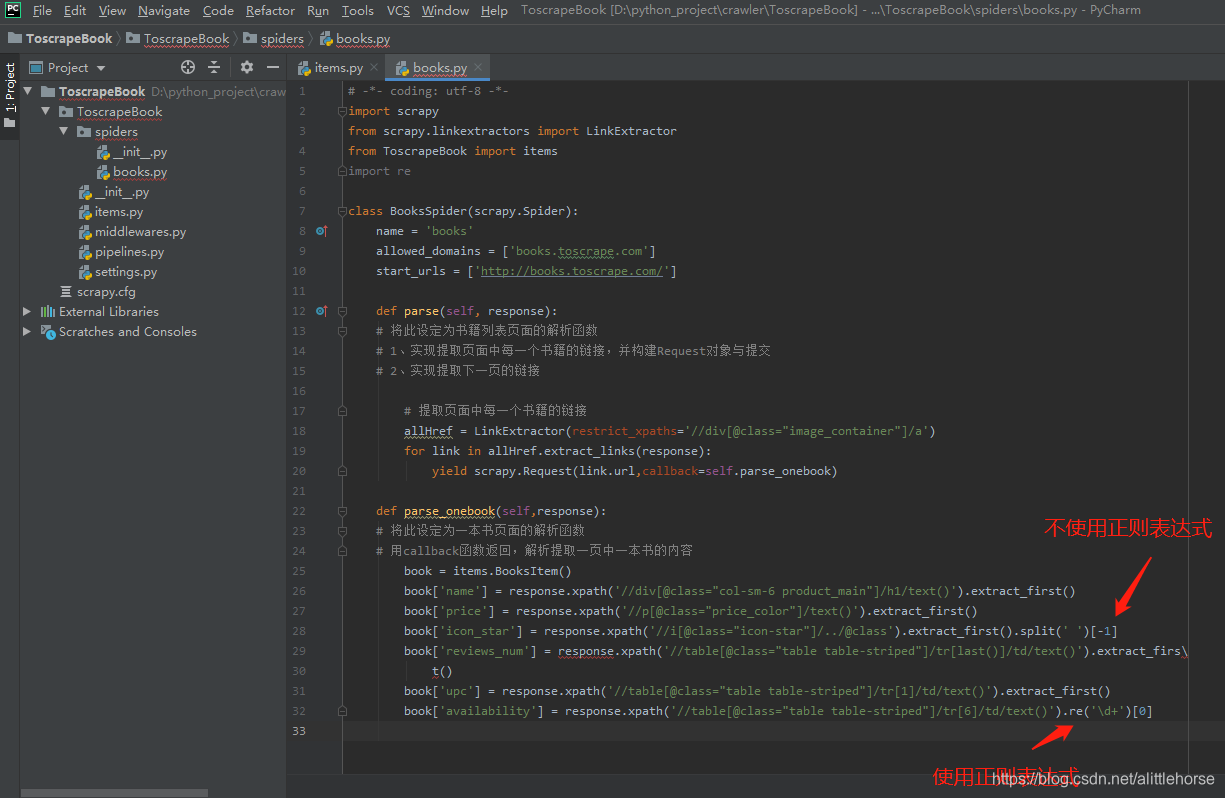
别忘记将Item yield出去
yield book
- 此时,一页中所有书本链接与一本书中的获取值已实现
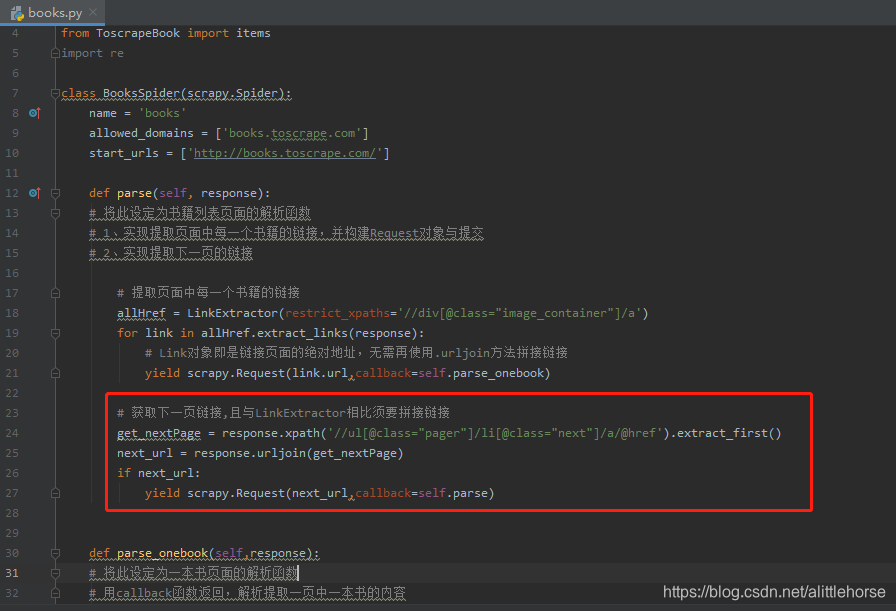
需实现下一页跳转方法
实现思路:获取下一页url(网页拼接urljoin()方法或者LinkExtractor)→ callback返回实现跳转
- 建立主函数运行并输出结果
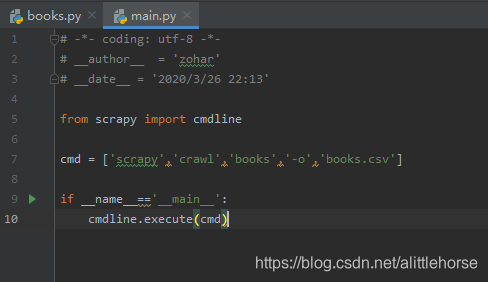
结果:(success)
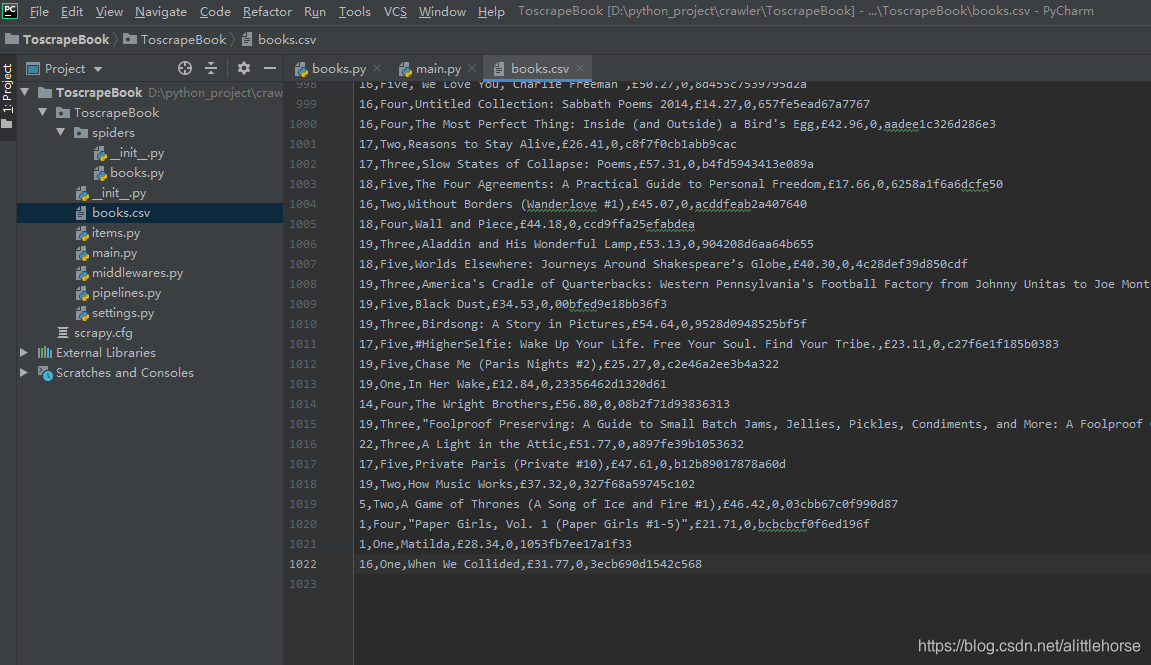

















 2964
2964

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









