






##第零步
安装requests库 与BeautifulSoup库,以及学习一点点html知识
##第一步
导入requests库 与BeautifulSoup库
import requests
from bs4 import BeautifulSoup##第三步
查看网站是否有反爬机制
如果有可以选择伪装浏览器
headers = {"User-Agent": "自己浏览器的标识"}按F12 找到网络(network)然后刷新网页,随便点击一个项目,找到User-Agent:将后面的内容完整的复制出来。
##第四步
先选择爬一个页面的数据
url = "https://books.toscrape.com"然后调用requests的get方法,这里如果网站没有反爬则不用headers=headers,加着也没啥影响接着调用BeautifulSoup对response.text这个字符串进行解析,并且BeautifulSoup可以对多个类型进行解析,因此还需要填入第二个参数,这里对html进行解析,因此可以填入html.parser这个解析器。
response = requests.get(url, headers=headers)
soup = BeautifulSoup(response.text, 'html.parser')##第五步
调用BeautifulSoup,其具有多种方法例如:print(soup.p) 将会打印第一个p元素下的内容。
在这里我们在网页上按F12,检查其html代码。
例如,我们首先想要第一页的所有书名,我们观察可以发现,所有书名都存储在<h3>下的<a>中,(这本质是一个找规律的过程,我们希望提取的元素没有其他不相干的元素,因此要尽量找出每个想要的内容存储的元素的区别),BeautifulSoup里有一个方法,findAll,它可以为我们找到我们想要找的元素,
book_names = soup.find_all("h3")findAll方法返回的是一个可迭代对象,可以通过for循环来获得对象内容。
for book_name in book_names:然后在接着用相同的方法找h3下的a元素。
title = book_name.find("a")["title"]在这里我们观察网页代码可以发现,书名的完整内容不存储在<a>标签的[titile]下,如果只获取<a>标签,我们获得的书名会因为有的书名过长而不能完全获得。例如:
 我们的书名后会有...,因此我们采用
我们的书名后会有...,因此我们采用
title = book_name.find("a")["title"]因为每一个p标签下只有一个<a>,因此我们可以采用find方法,但要注意的是,这不是一个可迭代的方法,因此不能用for循环。
print(title)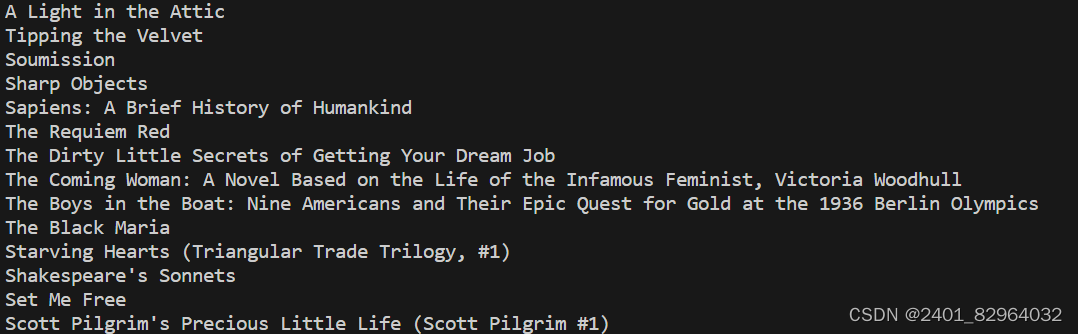
剩下的内容同理,比如获取价格:我们可以看到价格存储在<p class="price_color">£xx</p>下
因此这里我们可为findAll写入可选参数,表示寻找p标签下 class为price_color的元素
price_all = soup.find_all("p", class_="price_color")##最后
我们将书名和价格对应起来。全部代码如下:
import requests
from bs4 import BeautifulSoup
headers = {"User-Agent": "xxx"}
url = "https://books.toscrape.com"
response = requests.get(url, headers=headers)
soup = BeautifulSoup(response.text, 'html.parser')
book_names = soup.find_all("h3")
price_all = soup.find_all("p", class_="price_color")
title_list = []
price_list = []
for price_name in price_all:
price = price_name.string[2:]
price_list.append(price)
for book_name in book_names:
title = book_name.find("a")["title"]
print(title)
for i in range(len(title_list)):
print(title_list[i], price_list[i])获取全部50页的内容则需要观察每一页网址的规律,我们观察第二页发现网址变为
/catalogue/page-2.html,多观察几页发现是page-后面的数字在变,想到可以使用for循环依次改变值
for i in range(0,51,1):
url = f"https://books.toscrape.com/catalogue/page-{i}.html"注意的是这里字符串前要加一个f,它可以让你在字符串中插入变量。
PS:大一新生学习第一天,勿喷。如有错误,烦请指正,谢谢!

















 2722
2722

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









