







*该论文创新点:
1:采用拟合三维人脸来代替直接定位特征点 ;然后可以根据三维人脸进行特征点的标记 ;
2:设置新的级联卷积神经网络,并为该网络设置新的input_feature是PAF和PNCC的结合 ;
3:采用人脸轮廓合成方法处理300W数据集,从而得到300W-LP训练数据集,用该数据集训练模型,得到的模型结果比300W数据集的结果要好很多;
4:采用四维的四元数来代替欧拉角来表示旋转 ; 从而避免了万向锁;同时将四元数除以根号f , 将缩放量参数也合并到四元数中;

5:(非创新点,但需牢记compare的套路):利用300W-LP数据集训练需要对比论文的模型,然后在同一数据集下进行测试该模型(AFLW与AFLW2000-3D与300W数据集),计算每个图片的NME,从而可以得到平均的NME,然后在大Table中进行比较各个论文的NME,从而对比Table填完后,相应的论文实验就此结束 ;
该论文主要解决得问题:
1:为解决大姿态情况下人脸特征点丢失问题时,通过级联神经网络拟合三维人脸来代替直接标注特征点,之后再利用三维人脸信息可以在得到特征点的信息;
2:为解决如何拟合三维人脸模型的问题,设计了新的网络,并未该网络设置了新的inoput_feature ; 同时设置了新的损失函数;
3:为解决训练数据集短缺的问题,提出了人脸轮廓合成方法,处理300w数据集得到300W-LP数据集;
一:input_feature特征图的设计 :
根据论文叙述,一般所有论文描述的特征图输入共有两种; 第一种是直接将原图片作为特征图输入到神经网络中(imgae_view) ; 第二种是按照模型的需要,将像素进行重排列后得到的特征图输入到神经网络中(model_view) 。 本文对于特征图的设计采用了两种方法得到的两种特征图,然后将两种特征图进行结合 。
PAF的构造理解:
如下图是PAF图生成的步骤 ;

大致步骤:首先初始化一个3DMM的参数P ,然后利用公式重建出三维人脸模型
1:将该三维人脸模型进行上采样得到一个64x64的feature anchor (a) ;
2:在将该三维人脸模型投影到二维平面图上,从而又得到一个64x64的feature anchor (b); 此时将两个feature anchor设置为一个可视化,一个不可视化;
3:分别剪切每个feature anchor大小为dxd ; 与原来的图片连接成扩展的二维图片 ©
4:将该图片进行PAC卷积处理,得到64x64的PAF结果图(d) ;
PNCC的构造理解:

1:首先初始化一个3DMM的参数P ,然后利用公式重建出三维人脸模型维度是[3,53215],第一行是代表该所有特征点的x轴坐标;
2:将该三维人脸模型按照如下公式进行归一化处理,得到NCC(图a); 此时用NCC作为该三维人脸模型的纹理颜色图;
3:将三维人脸模型按照如下公式投影到二维平面上,采用Z-BUFF算法渲染p2d,且NCC作为color_map ,从而得到PNCC图(b) ;
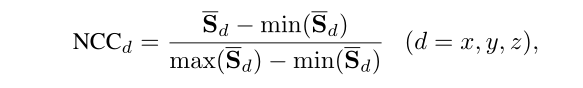

二:网络结构设计:

网络输出的结果:在初始化参数p输入 后,参数输出更新的数是detail p ; 此时参数的值是 p+detail p ;
三:
训练数据集:
训练时主要采用人脸轮廓合成技术从300W数据集中合成300W-LP数据集 ;这个数据集的标签是每个图片真实的3DMM参数Param_GT; 同时后面的实验结果证明,这个数据集对模型进行训练比300W数据集对模型进行训练的结果要优秀很多;
四:
损失函数和优化函数的设计:
该论文主要使用vdc(顶点距离损失),wpdc(权重参数距离损失),vdc from wpdc(先用wpdc损失函数训练好模型后,在用wpdc训练好的模型参数初始化网络模型,此时继续用vdc损失函数微调神经网络模型);owpdc损失函数 ; 主要使用了SGD优化函数 ; 详细解析如下 ;
训练时运用到的损失函数解析:
1:重识3DMM的基本原理:
任何一个照片都能通过固定的公式重建出三维人脸模型,具体公式略 , 但大体用到的数据有 :bfM数据中的平均形状,形状向量基,表情向量基(来自于FaceWareHouse数据集) ; 注:这些数据都是三维人脸模型,每一个三维人脸模型都存储了53215个顶点的三维坐标,只不过将这些坐标展开成向量形式 ; 该论文主要从bfm数据中一共选取了40个形状向量基,10个表情向量基 ; 形状向量基的维度是 [53215x3 , 40 ] ; 之后我们在利用网络回归出3DMM的参数,然后利用公式就可以重建出三维人脸模型 ;
2:VDC损失函数的说明
中文称,顶点距离损失 ;
计算VDC损失函数的损失时传入的数据为:利用神经网络回归出训练数据集中每张照片的3DMM参数(40个形状向量参数,10个表情向量参数,12个数组成摄像机矩阵), 该批训练照片的每个真实的3DMM参数(这个数据先前已存在PKL文件中)
计算算法思路大概实现:根据神经网络回归出的3DMM参数,利用如下公式重建出三维人脸模型,并用稠密特征点表示该重建的三维人脸模型,即维度时[3 , 53215] ; 同时利用这批数据的真实3DMM参数,然后根据同样的公式重建出三维人脸模型,采用同样的表达方式表达该三维人脸模型 ;
之后在计算两个三维人脸模型的顶点距离损失 ;则该损失值就是该图片的损失值 ;

3:WPDC损失函数的说明:
中文称:权重参数距离损失
传入的参数:同上
大致算法计算形式:先根据固定算法给62个3DMM参数分配固定的权重,然后在计算回归出的3DMM参数与真实的3DMM参数在固定权重上的距离损失; 该损失值就是此照片损失 ;
4:vdc fitune from wpdc
中文称:用vdc 微调 wpdc损失函数训练好的模型 ;
大概过程:先使用wpdc损失函数同上进行训练模型 ; 保存模型的参数 ; 重新开始此次训练时,将神经网络模型的参数初始化为刚刚用wpdc训练好模型的参数,然后继续用vdc损失函数去训练该模型 ;
5:owpdc
优先权重参数距离损失 ; 赋予每个参数不同的优先权,具体暂时不太懂 ;
3DDFA_V2中使用的是元联合优化策略,动态的组合fwpdc和vdc ;
五:
**** 模型的测试:(应该是套路吧:用xx数据集对该模型进行测试,主要就是计算该数据集中每个照片的NME,然后得到该数据集中偏航在0-30,30-60,60-90°之间的所有照片的平均NME,之后便可以用NME来衡量对比模型的好坏)
测试时用到的数据集是:aflw_2000-3d数据集 ; 该数据集中包含了大姿态的照片以及每个照片人工标注的68个特征点 ; 还有AFLW数据集,该数据集的标签是每个图片的21个特征点 ; 用AFLW2000-3D数据集对这个模型展开测试 ,主要就是计算每个图片的NME(预测的特征点与真实的特征点距离,除以该人脸的边界框bbox的大小 ,即 nme = dist / llength),然后便可以得到AFLW2000-3D数据集中偏航在0-30°,30°-60°,60°-90°的所有照片的平均NME,之后用NME来衡量这个模型的好坏 。
另外我们还需利用神经网络回归出每个照片的预测的3DMM参数,然后结合bfm模型中的形状向量基,平均形状等数据,利用公式重建出三维人脸模型,并用稀疏特征点表示该三维人脸模型 ;
之后利用每个图片的真实68特征点获得bbox框的大小 llength ;
计算该图片真实的68特征点与预测的68特征点在二维平面上的距离损失 = dist ;
nme = dist / llength ; 从而得到每个图片的NME ;
之后便可以计算0-30° , 30°-60°,60°-90°的所有照片的平均nme , 可知在大姿态情况下,nme是相对于其他方法来说算是优秀的;
六:与其他论文的结果比较
本节主要目的就是利用AFLW-2000-3D数据集和AFLW数据集在多论文中描述的方法中对比别人的模型。同时作者利用300W与300W-LP两个不同的数据集去训练别人的模型,既保证了对比的公平性又证明了人脸轮廓分析方法合成的300W-LP数据集对训练模型有很大的提升。 之后计算AFLW-2000-3D数据集中每个图片的NME,因此可以用NME来衡量哪个模型更优秀;下图是比较的一个表格

对于上图表格的说明与解析:
1:比如这个表,我们用300W数据集去训练LBF中的模型(保证最大的公平性),得到模型后;用AFLW-2000-3D数据集对该模型展开测试,主要就是计算AFLW-2000-3D数据集中每个图片的NME;从而可以得到AFLW-2000-3D数据集中图片偏航在0-30°之间的所有照片的平均NME,,,。之后就可以用NME来衡量该模型的好坏 。 下一列就是用AFLW数据集对该模型进行测试,目的也是为了计算每个图片的NME,之后便可以得到AFLW数据集中图片偏航在0-30°,30-60°之间的所有照片的平均NME,然后我们用NME的比较来衡量模型的好坏;
2:我们还能发现,使用300W-LP数据集训练该模型,NME有了明显的减少,表明该模型有了很大的提高 ; 从而验证了作者利用人脸合成方法形成的数据集对于训练模型有很大的帮助 ;
七:论文额外的部分代码
dlib人脸检测器的说明:
1: shape_predictor = dlib.shape_predictor(.dat文件)
功能: 是标记人脸特征点;
目的:获得人脸特征点检测器 ;
2:landmark_location=shape_predictor(img , rectangle).parts()
功能:是获得人脸特征点的位置 ;
参数:img是3维度的numpy,rectangle是矩形 ;
目的:获得68个人脸特征点的位置,即返回一个列表,里面包含68个元组(x , y),表示每个特征点的坐标位置 ;
3:detector = dlib.get_frontal_face_detector()
目的:获得dlib人脸检测器;
4:rect = detector(img , 1)
目的:获得矩形;返回的值是个列表,用来存储矩形,有几个人脸就有几个矩形;若没有人脸,则返回的是个空列表;
接下来可以用 :
bbox = [rect.left(), rect.top(), rect.right(), rect.bottom()],然后利用矩形从而获得人脸盒子bbox ;
3DDFA和3DDFA_V2的不同之处:
1:3DDDFA:3DDFA采用dlib人脸特征点检测器;
3DDFA获得roi_box的参数的方法为:获得矩形,再将矩形转化为box人脸盒子,然后利用人脸盒子从而获得roi_box参数 ; 第二种方法就是:利用人脸特征点检测器获得68个人脸特征点的坐标位置,然后利用68个人脸特征点从而获得roi_box参数;
2:3DDFA_v2:采用facebox人脸检测器 ; 获得人脸盒子box后,利用人脸盒子从而获得roi_box参数 ;
表达重建三维人脸模型的方法:
1:用稀疏特征点代表该重建的三维人脸模型;返回的维度是[3,68];共有68个特征点,这些数据表明了68个特征点的三维坐标,第一行是x轴,第二行是y轴坐标,第三行是z轴坐标;因为我们是在这个二维平面上画出该三维人脸模型,所以,我们取的特征点坐标是x轴和y轴的 ;
2用稠密特征点代表该重建的三维人脸模型;返回的维度是[3,53215];共53215个特征点,表明了这些特征点的三维坐标,同上
3:使用sim3dr网格代表该重建的三维人脸模型 ;
五:
使用matplotlib画出三维点和二维点
1:二维点的显示:
plt.figure(figsize = ) ;
plt.imshow(img) #形成一个热图,但不显示该图片,方便在该热图上添加东西,需要调用show才显示该热图 ;
plt.plot(list x , list y )是单纯画出线条的;其中加上属性’o’(plt.plot(x , y , ‘o’))才是生成点!!!!其加上属性plt.plot(x , y ,marker=‘o’)是即画圆又连直线; 可以累加多次调用plot生成坐标点 ;
plt.axis(list[] , list [])#这个是配置坐标系的 ;
二:三维点的生成以及绘画
fig = plt.figure() #先配置图片大小 ;
ax = fig.add_subplot(1 ,2 ,1, projection=‘3d’) ;先创建一个子窗口,并向该子窗口中第一个窗口添加内容 ; 并确定是三维的子窗口
ax.scatter(list x , list y ,list z) ;形成一个散点 ;但这些散点之间不链接;
ax.plot3D(list x , list y ,list z )#是按照固定的顺序链接这些散点 ;
ax.set_xlable(‘x’) ; ax.set_ylable(‘y’) ;ax.set_zlable(‘z’)#用这些信息来配置坐标系 ;
ax.set_xticklabels([]) ; x轴坐标系的坐标标记为空 ;
三:关于plt.plot()的说明
1:plt.plot(list x , list y)是画出点所连接的直线 ;
2:plt.plot(list x , list y,‘o’)是只画出这些点
3:plt.plot(list x ,list y , marker=‘o’)是即画出点,又画出点所连接的直线
关于offset矩阵的说明:
offset矩阵中包含着pitch(俯仰) , yaw(偏航) , roll(旋转);其具体的角度操作来表示人脸旋转,详情可以见论文,主要就是分好轴,然后转动坐标系,就相当于转动这个人脸获得旋转;
其中用欧拉角来表示人脸的姿势可能会出现万向锁,即不同的欧拉角表达[pitch , yaw ,roll ]可能出现相同的旋转人脸 ;
所以我们使用四维单元四元数来代替欧拉角表示旋转 ; 就是因为欧拉角会出现万向锁 (3ddfa_v2);
关于该公式的理解:
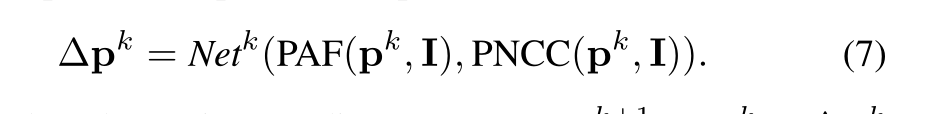
利用神经网络回归出3DMM参数的理解:在第k次迭代的时候,我们初始化一个3DMM的参数Pk , 然后利用这个Pk,我们可以构建出PAF图和PNCC图,将这两个图与原始的图片叠加在一起,喂入到双流的神经网络(PNCC流和PAF流)中,然后将这两个结果累加在一起分析最终预测到的神经网络参数增加量 detail Pk;















 8759
8759











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









