







看过了内存优化的文章,了解到在Android里为了节约内存,应该尽量避免使用HashMap.
今天的主角是SparseArray和ArrayMap.下面我打算从源码的角度去分析为什么我们要取代HashMap.主要是从三个方法put(),remove(),get()进行分析.
1.SpareArray:
SparseArray仅使用于用int值做key的键值对,他主要是通过两个数组去存储数据
private int[] mKeys;
private Object[] mValues;mKeys[]用于存储key,mValues[]用于存储对应的value.
首先看下他的put方法
public void put(int key, E value) {
//通过二分法找到下标
int i = ContainerHelpers.binarySearch(mKeys, mSize, key);
//如果已存在就直接赋值取代
if (i >= 0) {
mValues[i] = value;
} else {
i = ~i;
if (i < mSize && mValues[i] == DELETED) {
mKeys[i] = key;
mValues[i] = value;
return;
}
//省略清理数组的代码
mKeys[i] = key;
mValues[i] = value;
mSize++;
}
}再看他的获取方式get()方法
public E get(int key, E valueIfKeyNotFound) {
//二分查找法找到下标
int i = ContainerHelpers.binarySearch(mKeys, mSize, key);
if (i < 0 || mValues[i] == DELETED) {
return valueIfKeyNotFound;
} else {
return (E) mValues[i];
}
}
用二分查找法找下标,没什么好说的
看看remove()方法,直接调用了delete():
public void delete(int key) {
int i = ContainerHelpers.binarySearch(mKeys, mSize, key);
if (i >= 0) {
if (mValues[i] != DELETED) {
mValues[i] = DELETED;
mGarbage = true;
}
}
}删除的时候用一个叫DELETED的Object对象替换原对象
private static final Object DELETED = new Object();然后会通过清理数组的代码去整合数组,代码如下
private void gc() {
int n = mSize;
int o = 0;
int[] keys = mKeys;
Object[] values = mValues;
for (int i = 0; i < n; i++) {
Object val = values[i];
if (val != DELETED) {
if (i != o) {
keys[o] = keys[i];
values[o] = val;
values[i] = null;
}
o++;
}
}
mGarbage = false;
mSize = o;
}SparseArray总结一下,他的核心使用二分算法去查找,效率很高,需要的内存也不多,就两个数组,因此这个是最节约内存的(后面会有测试数据).
2.ArrayMap
如果key不能是int的,那就可以考虑用ArrayMap去存储键值对
put()方法:
public V put(K key, V value) {
final int hash;
int index;
if (key == null) {
hash = 0;
index = indexOfNull();
} else {
//查找index里面是用二分查找法
hash = key.hashCode();
index = indexOf(key, hash);
}
//
if (index >= 0) {
index = (index<<1) + 1;
final V old = (V)mArray[index];
mArray[index] = value;
return old;
}
//省略清理数组的代码
mHashes[index] = hash;
mArray[index<<1] = key;
mArray[(index<<1)+1] = value;
mSize++;
return null;
}可以看出ArrayMap主要由两个数组来存储键值对,分别是mHashes[]用存储key对应的hashcode,mArray[]用来存储key和value(通过移位操作找到下标,由于要存储两个东西,所以就让index左移一位,就是乘以2嘛,从而达到用一个数组同时存储key和value).
下面是get()方法:
public V get(Object key) {
final int index = key == null ? indexOfNull() : indexOf(key, key.hashCode());
return index >= 0 ? (V)mArray[(index<<1)+1] : null;
}用二分算法找到下标然后找出值,很简单.
remove()同理,用二分算法找到index然后移除对应的值,代码如下
public V remove(Object key) {
int index = key == null ? indexOfNull() : indexOf(key, key.hashCode());
if (index >= 0) {
return removeAt(index);
}
return null;
}总结ArrayMap,他也是用了二分算法(谷歌为什么这么喜欢二分算法),存数据用了两个数组
int[] mHashes;
Object[] mArray;效率应该跟SparseArray比较接近,但他存储了3个东西,一个是key,一个是key对应的hashcode,还有一个value,所以内存占用应该会比SparseArray多点.
3.HashMap:
一张图看懂HashMap
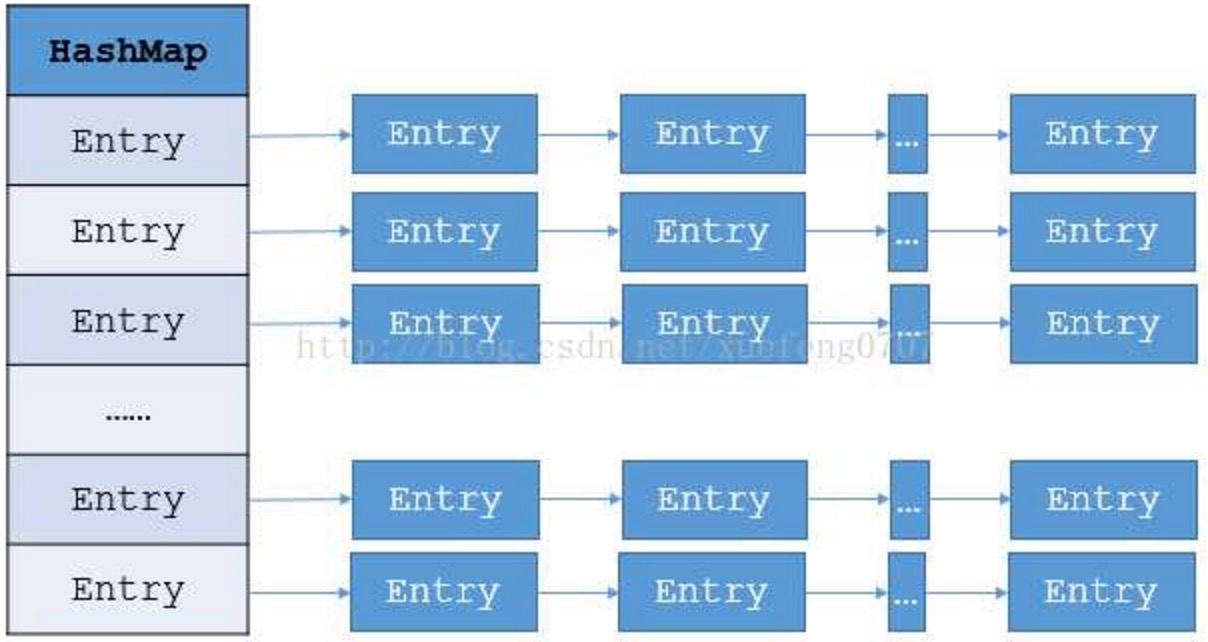
HashMap其实就是一个数组,这个数组存储着HashMapEntry对象,而HashMapEntry是个链表结构,所以HashMap其实是数组和链表的结合体.
HashMap的成员主要有:
//存储空key的HashMapEntry
transient HashMapEntry<K, V> entryForNullKey;
//核心数组,用于存储对应的HashMapEntry链表
transient HashMapEntry<K, V>[] table;
//用来存储key的集合
private transient Set<K> keySet;
//存储Entry的集合
private transient Set<Entry<K, V>> entrySet;
//存储值的集合
private transient Collection<V> values;可以看出HashMap的东西还挺多的.
来看put()方法:
@Override
public V put(K key, V value) {
if (key == null) {
//把空的key用专门的一个链表去存储
return putValueForNullKey(value);
}
//得到转换后的hash值
int hash = secondaryHash(key);
HashMapEntry<K, V>[] tab = table;
int index = hash & (tab.length - 1);
//找到index后对对应的HashMapEntry做遍历如果已经存在就返回
for (HashMapEntry<K, V> e = tab[index]; e != null; e = e.next) {
if (e.hash == hash && key.equals(e.key)) {
preModify(e);
V oldValue = e.value;
e.value = value;
return oldValue;
}
}
// No entry for (non-null) key is present; create one
modCount++;
if (size++ > threshold) {
tab = doubleCapacity();
index = hash & (tab.length - 1);
}
addNewEntry(key, value, hash, index);
return null;
}addNewEntry():
table[index] = new HashMapEntry<K, V>(key, value, hash, table[index]);在看看get方法():
public V get(Object key) {
if (key == null) {
HashMapEntry<K, V> e = entryForNullKey;
return e == null ? null : e.value;
}
int hash = key.hashCode();
hash ^= (hash >>> 20) ^ (hash >>> 12);
hash ^= (hash >>> 7) ^ (hash >>> 4);
HashMapEntry<K, V>[] tab = table;
for (HashMapEntry<K, V> e = tab[hash & (tab.length - 1)];
e != null; e = e.next) {
K eKey = e.key;
if (eKey == key || (e.hash == hash && key.equals(eKey))) {
return e.value;
}
}
return null;
}
get()方法就是通过key的hash值拿到index,然后遍历那个位置的HashMapEntry.
最后看看remove方法():
@Override
public V remove(Object key) {
if (key == null) {
//删除空key的方法
return removeNullKey();
}
int hash = secondaryHash(key);
HashMapEntry<K, V>[] tab = table;
int index = hash & (tab.length - 1);
//同样是通过key的hash值找出index,然后遍历那个位置的HashMapEntry
for (HashMapEntry<K, V> e = tab[index], prev = null;
e != null; prev = e, e = e.next) {
if (e.hash == hash && key.equals(e.key)) {
if (prev == null) {
tab[index] = e.next;
} else {
prev.next = e.next;
}
modCount++;
size--;
postRemove(e);
return e.value;
}
}
return null;
}4.总结
分析完了3个类,我们总结下为什么HashMap比较耗内存.
对比下就会发现,HashMap里面用于存储数据的数组是最多的.其次,性能优化的文章(传送门:http://hukai.me/android-performance-patterns-season-3/)说HashMap会做自动装箱(AutoBoxing boolean,int,float等转换成Boolean,Integer,Float等对象)处理.而SparseArray和ArrayMap都能避免AutoBoxing从而达到节约内存.那篇文章还说,满足两个条件才考虑用ArrayMap:
1.对象个数的数量级最好是千以内
2.数据组织形式包含Map结构
原因是超过一定数量ArrayMap插入和删除效率不高.
光瞎说没有说服力,我们用实际数据测下他们所占的内存大小
首先我们分别为三个类创建一个对象,然后向他们添加1000个Object对象
for (int i = 0 ; i < 10000 ; i++){
mHashMap.put(i,new Object());
}
for (int i = 0 ; i < 10000 ; i++){
mArrayMap.put(i,new Object());
}
for (int i = 0 ; i < 10000 ; i++){
mSparseArray.put(i,new Object());
}然后用Android Studio自带的内存分析工具看下他们所占内存大小
图1是加1000个的大小,图2是10000个数据的大小


可以看出HashMap,ArrayMap,SparseArray所占内存大小为5:3:2左右.
所以以后我们应该尽量考虑内存优化根据情况尽量不要使用HashMap了.















 446
446

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









