









 本文深入探讨了GeneralG统计方法的特点及其应用场景,包括其对平均数的敏感性、直方图探索的重要性,以及在不同区域数据统计上的局限性。
本文深入探讨了GeneralG统计方法的特点及其应用场景,包括其对平均数的敏感性、直方图探索的重要性,以及在不同区域数据统计上的局限性。
上一篇讲了General G统计方法的一般性解释,那么这篇继续把这个内容讲完。
开始我们说了,如果高值和低值区域同时出现了聚类,就变成了拿这板砖互拍的情况。但是还有的时候,出现更奇葩的情况,比如你用其他的工具(比如局部莫兰指数、热点分析一类的,这些工具以后我们会慢慢说到。)计算出来,发现这份数据统计特征值真是极高的,但是同样一份数据,到了General G统计算法里面之后,发现,咦,怎么他的结果如此不显著?也就是说,你算的效果很好,我这边一算,完全就瞎猜嘛!如下图:
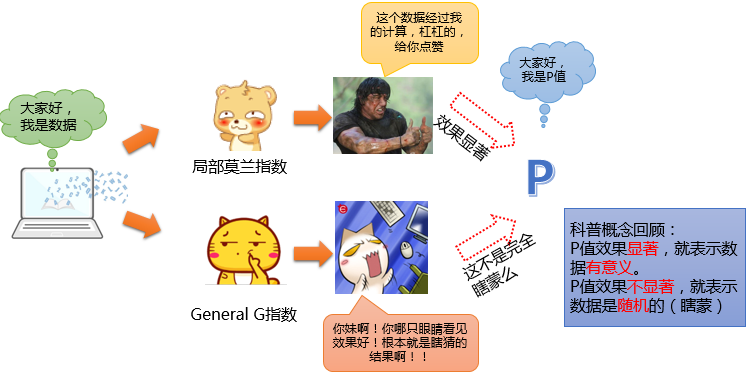
遇上这种情况,是算法出了问题么?当然不是,这是General G算法本身的一些特性导致的。
General G最大的特点,就是要计算平均数(可怕的平均数又出来了),大家知道,平均数有很大的问题,如下面的情况:
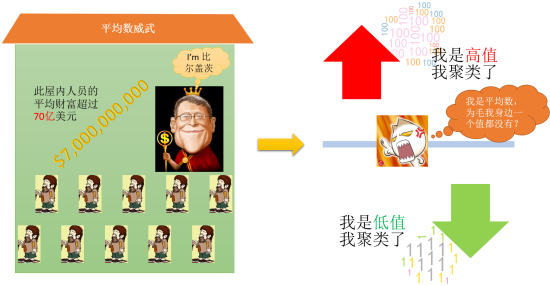
General G方法,对平均数非常敏感,如果他计算出来的平均数,与整份数据基本上没啥关系——我们开始也说了,General G方法是推论统计,主要用于通过局部数据对整体数据的特征进行推理;但是你拿到的数据,出现各种极值,而你计算出来的平均值完全不能代表你的数据,在这种情况,General G方法,就会出现很非常令人费解的结果。
所以,在利用General G的时候,最好先进行直方图探索,数据分布越接钟形曲线,那么使用General G的效果就越好,极值越多,效果就越不明显。
下面我们来说说这个工具的一些注意事项:
General G一般不能用于对不同区域的数据进行计算比较。因为空间数据对大小和距离都很敏感,同样表现为聚类的,理论上应该观测值等于期望值,但是如果面要素的大小不一样,就会出现,小的面要素会优于大的面要素,看下面这个情况:
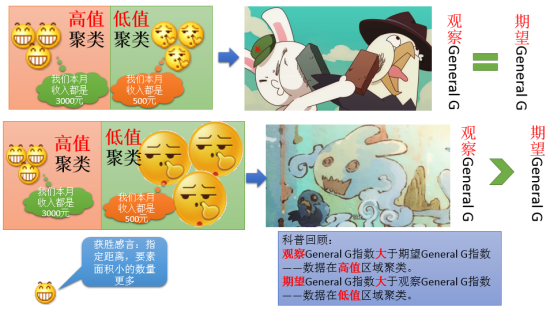
最后我们来看看General G指数可以在哪些分析中使用:
首先在不同的区域里面,对某种处方类药品的销量进行统计,然后进行General G计算,如果是低值聚类,应该是比较正常的情况, 但是如果发生了高值聚类,那么就有可能是某种疾病集中爆发的前兆(不一定是前兆,也有可能已经发生了集中爆发),如下图:
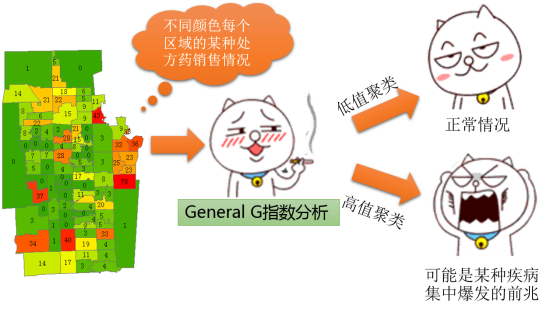
当然, 如果有同一地区多年份的数据,也可以通过General G指数进行分析,以确定是否有异常的变动,比如年年都是低值聚类,突然有一年出现了高值聚类,这种异常值,就是值得注意和需要研究的内容。
再比如对一个城市不同区域的人口数据和聚集情况进行研究,因为General G指数对绝对数值的增长不敏感,所以只要数据呈现总体增长,那么计算的结果都不会有太大的差距。另外在同一城市里面,人口聚类的重心可能不同,但是以区域进行统计的数据,这个重心很难计算出来的。在这种时候,General G指数就有用了,可以在一个城市内,通过区域统计数据,来计算是否发生了聚类,以通过研究人口,来探索城镇发展以及密集度的分析。
结束语,贴General G的数学公式,有数学恐惧症的同学慎入:





















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











