






7 管理存储池
Ceph 将数据存储在存储池中。存储池是用于存储对象的逻辑组。如果您先部署集群而不创建存储池,Ceph 会使用默认存储池来存储数据。存储池为您提供:
- 恢复能力:您可以设置允许多少个 OSD 发生故障而不会丢失数据。对于副本池,它是对象的所需副本数。创建新存储池时,会将默认副本数设置为 3。因为典型配置会存储一个对象和一个额外的副本,所以您需要将副本数设置为 2。对于纠删码池,该计数为编码块数(在纠删码配置中,设置为 m=2)。
- 归置组:用于跨 OSD 将数据存储在某个存储池中的内部数据结构。CRUSH 地图中定义了 Ceph 将数据存储到 PG 中的方式。您可以设置存储池的归置组数。典型配置为每个 OSD 使用约 100 个归置组,以提供最佳平衡而又不会耗费太多计算资源。设置多个存储池时,请务将存储池和集群作为整体考虑,确保设置合理的归置组数。
- CRUSH 规则:在存储池中存储数据时,映射到存储池的 CRUSH 规则组可让 CRUSH 识别将对象及其副本(对于纠删码池,则为块)放置在集群中的规则。您可为存储池创建自定义 CRUSH 规则。
- 快照:使用 ceph osd pool mksnap 创建快照时,可高效创建特定存储池的快照。
- 设置所有权:您可将某用户 ID 设置为存储池的所有者。
要将数据组织到存储池中,可以列出、创建和删除存储池。您还可以查看每个存储池的用量统计数字。
7.1 将存储池与应用关联
在使用存储池之前,需要将它们与应用关联。将与 CephFS 搭配使用或由对象网关自动创建的存储池会自动关联。需要使用 rbd 工具初始化要与 RBD 搭配使用的存储池(有关详细信息,请参见第 8.1 节 “块设备命令”)。
对于其他情况,可以手动将自由格式的应用名称与存储池关联:
root # ceph osd pool application enable pool_name application_name
提示:默认应用名称
CephFS 使用应用名称 cephfs,RADOS 块设备使用 rbd,对象网关使用 rgw。
一个存储池可以与多个应用关联,每个应用都可具有自己的元数据。可使用以下命令显示给定存储池的应用元数据:
root # ceph osd pool application get pool_name
7.2 操作存储池 #
本节介绍对存储池执行基本任务的特定信息。您可以了解如何列出、创建和删除存储池,以及如何显示存储池统计数字或管理存储池快照。
7.2.1 列出存储池
要列出集群的存储池,请执行以下命令:
root # ceph osd lspools
0 rbd, 1 photo_collection, 2 foo_pool,
7.2.2 创建存储池
要创建副本存储池,请执行以下命令:
root # ceph osd pool create pool_name pg_num pgp_num replicated crush_ruleset_name \
expected_num_objects
要创建纠删码池,请执行以下命令:
root # ceph osd pool create pool_name pg_num pgp_num erasure erasure_code_profile \
crush_ruleset_name expected_num_objects
如果超出每个 OSD 的归置组限制,则 ceph osd pool create 可能会失败。该限制通过 mon_max_pg_per_osd 选项设置。
pool_name
存储池的名称,必须唯一。必须指定此选项。
pg_num
存储池的归置组总数。必须指定此选项。默认值是 8。
pgp_num
用于归置数据的归置组总数。此数量应该与归置组总数相等,归置组拆分情况除外。必须指定此选项。默认值是 8。
pgp_type
存储池类型,可以是 replicated(用于保留对象的多个副本,以便从失败的 OSD 恢复)或 erasure(用于获得某种通用 RAID5 功能)。副本池需要的原始存储较多,但可实现所有 Ceph 操作。纠删码池需要的原始存储较少,但只实现一部分可用的操作。默认值是“replicated”。
crush_ruleset_name
此存储池的 crush 规则组的名称。如果所指定的规则组不存在,则创建副本池的操作将会失败,并显示 -ENOENT。但副本池将使用指定的名称创建新的纠删规则组。对于纠删码池,默认值是“erasure-code”。对于副本池,将选取 Ceph 配置变量 osd_osd_pool_default_crush_replicated_ruleset。
erasure_code_profile=profile
仅适用于纠删码池。使用纠删码配置。该配置必须是 osd erasure-code-profile set 所定义的现有配置。
创建存储池时,请将归置组数设置为合理的值(例如 100)。还需考虑每个 OSD 的归置组总数。归置组在计算方面的开销很高,因此如果您的许多存储池都包含很多归置组(例如有 50 个池,每个池各有 100 个归置组),性能将会下降。下降点的恢复视 OSD 主机性能而定。
有关计算存储池的合适归置组数量的详细信息,请参见归置组。
expected_num_objects
此存储池的预期对象数。如果设置此值,PG 文件夹拆分发生于存储池创建时。这可避免因运行时文件夹拆分导致的延迟影响。
7.2.3 设置存储池配额
您可以设置存储池配额,限定每个存储池的最大字节数和/或最大对象数。
root # ceph osd pool set-quota pool-name max_objects obj-count max_bytes bytes
例如:
root # ceph osd pool set-quota data max_objects 10000
要删除配额,请将其值设置为 0。
7.2.4 删除存储池
警告:删除存储池的操作不可逆
存储池中可能包含重要数据。删除存储池会导致存储池中的所有数据消失,且无法恢复。
不小心删除存储池十分危险,因此 Ceph 实施了两个机制来防止删除存储池。要删除存储池,必须先禁用这两个机制。
第一个机制是 NODELETE 标志。每个存储池都有这个标志,其默认值是“false”。要确定某个存储池的此标志值,请运行以下命令:
root # ceph osd pool get pool_name nodelete
如果命令输出 nodelete: true,则只有在使用以下命令更改该标志后,才能删除存储池:
ceph osd pool set pool_name nodelete false
第二个机制是集群范围的配置参数 mon allow pool delete,其默认值为“false”。这表示默认不能删除存储池。显示的错误讯息是:
Error EPERM: pool deletion is disabled; you must first set the
mon_allow_pool_delete config option to true before you can destroy a pool
若要规避此安全设置删除存储池,可以临时将 mon allow pool delete 设置为“true”,删除存储池,然后将该参数恢复为“false”:
root # ceph tell mon.* injectargs --mon-allow-pool-delete=true
root # ceph osd pool delete pool_name pool_name --yes-i-really-really-mean-it
root # ceph tell mon.* injectargs --mon-allow-pool-delete=false
injectargs 命令会显示以下讯息:
injectargs:mon_allow_pool_delete = 'true' (not observed, change may require restart)
这主要用于确认该命令已成功执行。它不是错误。
如果为您创建的存储池创建了自己的规则组和规则,则应该考虑在不再需要该存储池时删除规则组和规则。如果您创建了仅对不再存在的存储池具有许可权限的用户,则应该考虑也删除那些用户。
7.2.5 重命名存储池
要重命名存储池,请执行以下命令:
root # ceph osd pool rename current-pool-name new-pool-name
如果重命名了存储池,且为经过身份验证的用户使用了按存储池功能,则必须用新的存储池名称更新用户的功能。
7.2.6 显示存储池统计数字
要显示存储池的用量统计数字,请执行以下命令:
root # rados df
pool name category KB objects lones degraded unfound rd rd KB wr wr KB
cold-storage - 228 1 0 0 0 0 0 1 228
data - 1 4 0 0 0 0 0 4 4
hot-storage - 1 2 0 0 0 15 10 5 231
metadata - 0 0 0 0 0 0 0 0 0
pool1 - 0 0 0 0 0 0 0 0 0
rbd - 0 0 0 0 0 0 0 0 0
total used 266268 7
total avail 27966296
total space 28232564
7.2.7 设置存储池的值
要设置存储池的值,请执行以下命令:
root # ceph osd pool set pool-name key value
您可以设置以下键的值:
size
设置存储池中对象的副本数。有关更多详细信息,请参见第 7.2.9 节 “设置对象副本数”。仅用于副本池。
min_size
设置 I/O 所需的最小副本数。有关更多详细信息,请参见第 7.2.9 节 “设置对象副本数”。仅用于副本池。
crash_replay_interval
允许客户端重放已确认但未提交的请求的秒数。
pg_num
存储池的归置组数。如果将 OSD 添加到集群,则应该提高归置组的值,有关详细信息,请参见第 7.2.11 节 “增加归置组数”。
pgp_num
计算数据归置时要使用的归置组的有效数量。
crush_ruleset
用于在集群中映射对象归置的规则组。
hashpspool
为给定存储池设置 (1) 或取消设置 (0) HASHPSPOOL 标志。启用此标志会更改算法,以采用更佳的方式将 PG 分配到 OSD 之间。对之前 HASHPSPOOL 标志设为 0 的存储池启用此标志后,集群会开始回填,以使所有 PG 都可再次正确归置。请注意,这可能会在集群上产生相当高的 I/O 负载,因此对高负载生产集群必须进行妥善规划。
nodelete
防止删除存储池。
nopgchange
防止更改存储池的 pg_num 和 pgp_num。
nosizechange
防止更改存储池的大小。
write_fadvise_dontneed
对给定存储池设置/取消设置 WRITE_FADVISE_DONTNEED 标志。
noscrub、nodeep-scrub
禁用(深层)整理 (scrub) 特定存储池的数据以解决临时高 I/O 负载问题。
hit_set_type
对快速缓存池启用命中集跟踪。请参见布隆过滤器以了解更多信息。此选项可用的值如下:bloom、explicit_hash、explicit_object。默认值是 bloom,其他值仅用于测试。
hit_set_count
要为快速缓存池存储的命中集数。该数值越高,ceph-osd 守护进程耗用的 RAM 越多。默认值是 0。
hit_set_period
快速缓存池的命中集期间的时长(以秒为单位)。该数值越高,ceph-osd 守护进程耗用的 RAM 越多。
hit_set_fpp
布隆命中集类型的误报率。请参见布隆过滤器以了解更多信息。有效范围是 0.0 - 1.0,默认值是 0.05
use_gmt_hitset
为快速缓存分层创建命中集时,强制 OSD 使用 GMT(格林威治标准时间)时戳。这可确保在不同时区中的节点返回相同的结果。默认值是 1。不应该更改此值。
cache_target_dirty_ratio
在快速缓存分层代理将已修改(脏)对象清理到后备存储池之前,包含此类对象的快速缓存池百分比。默认值是 .4
cache_target_dirty_high_ratio
在快速缓存分层代理将已修改(脏)对象清理到速度更快的后备存储池之前,包含此类对象的快速缓存池百分比。默认值是 .6。
cache_target_full_ratio
在快速缓存分层代理将未修改(干净)对象从快速缓存池逐出之前,包含此类对象的快速缓存池百分比。默认值是 .8
target_max_bytes
触发 max_bytes 阈值后,Ceph 将会开始清理或逐出对象。
target_max_objects
触发 max_objects 阈值时,Ceph 将开始清理或逐出对象。
hit_set_grade_decay_rate
两次连续的 hit_set 之间的温度降低率。默认值是 20。
hit_set_search_last_n
计算温度时在 hit_set 中对出现的项最多计 N 次。默认值是 1。
cache_min_flush_age
在快速缓存分层代理将对象从快速缓存池清理到存储池之前的时间(秒)。
cache_min_evict_age
在快速缓存分层代理将对象从快速缓存池中逐出之前的时间(秒)。
fast_read
如果对纠删码池启用此标志,则读取请求会向所有分片发出子读取命令,并一直等到接收到足够解码的分片,才会为客户端提供服务。对于 jerasure 和 isa 纠删插件,前 K 个副本返回时,就会使用从这些副本解码的数据立即处理客户端的请求。这有助于获得一些资源以提高性能。目前,此标志仅支持用于纠删码池。默认值是 0。
scrub_min_interval
集群负载低时整理 (scrub) 存储池的最小间隔(秒)。默认值 0 表示使用来自 Ceph 配置文件的 osd_scrub_min_interval 值。
scrub_max_interval
不论集群负载如何都整理 (scrub) 存储池的最大间隔(秒)。默认值 0 表示使用来自 Ceph 配置文件的 osd_scrub_max_interval 值。
deep_scrub_interval
深层整理 (scrub) 存储池的间隔(秒)。默认值 0 表示使用来自 Ceph 配置文件的 osd_deep_scrub 值。
7.2.8 获取存储池的值
要获取存储池中的值,请执行以下命令:
root # ceph osd pool get pool-name key
您可以获取第 7.2.7 节 “设置存储池的值”中所列键以及下列键的值:
pg_num
存储池的归置组数。
pgp_num
计算数据归置时要使用的归置组的有效数量。有效范围小于或等于 pg_num。
7.2.9 设置对象副本数
要设置副本存储池上的对象副本数,请执行以下命令:
root # ceph osd pool set poolname size num-replicas
num-replicas 包括对象本身。例如,如果您想用对象和对象的两个副本组成对象的三个实例,请指定 3。
如果将 num-replicas 设置为 2,数据将只有一个副本。例如,如果您丢失了一个对象实例,则需要在恢复期间确定自上次整理 (scrub) 后,另一个副本没有损坏。
将存储池设置为具有一个副本意味着存储池中的数据对象只有一个实例。如果 OSD 发生故障,您将丢失数据。如果要短时间存储临时数据,可能就会用到只有一个副本的存储池。
为存储池设置三个以上副本只能小幅提高可靠性,但在极少数情况下可能适用。请记住,副本越多,存储对象副本所需的磁盘空间就越多。如果您需要终极数据安全性,则建议使用纠删码池。有关详细信息,请参见第 9 章 “纠删码池”。
警告:建议使用两个以上副本
强烈建议不要只使用 2 个副本。如果一个 OSD 发生故障,恢复期间的高负载很可能会导致第二个 OSD 也发生故障。
例如:
root # ceph osd pool set data size 3
可针对每个存储池执行此命令。
注意
对象可以接受降级模式下副本数量低于 pool size 的 I/O。要设置 I/O 所需副本的最小数目,应该使用 min_size 设置。例如:
root # ceph osd pool set data min_size 2
这可确保数据池中没有对象会接收到副本数量低于 min_size 的 I/O。
7.2.10 获取对象副本数
要获取对象副本数,请执行以下命令:
root # ceph osd dump | grep 'replicated size'
Ceph 将列出存储池,并高亮显示 replicated size 属性。Ceph 默认会创建对象的两个副本(共三个副本,或者大小为 3)。
7.2.11 增加归置组数
创建新存储池时,需指定存储池的归置组数(请参见第 7.2.2 节 “创建存储池”)。将更多 OSD 添加至集群后,出于性能和数据持久性原因,通常还需要增加归置组数。对于每个归置组,OSD 和监视器节点始终都需要用到内存、网络和 CPU,在恢复期间需求量甚至更大。因此,最大限度地减少归置组数可节省相当大的资源量。
警告:pg_num 的值过高
更改存储池的 pg_num 值时,新的归置组数有可能会超出允许的限制。例如
root # ceph osd pool set rbd pg_num 4096
Error E2BIG: specified pg_num 3500 is too large (creating 4096 new PGs \
on ~64 OSDs exceeds per-OSD max of 32)
该限制可防止归置组过度拆分,它从 mon_osd_max_split_count 值衍生。
为已调整大小的集群确定合适的新归置组数是一项复杂的任务。一种方法是不断增加归置组数,直到达到集群性能的最佳状态。要确定增加后的新归置组数,需要获取 mon_osd_max_split_count 参数的值,并将它与当前的归置组数相加。要了解基本原理,请查看下面的脚本:
cephadm > max_inc=`ceph daemon mon.a config get mon_osd_max_split_count 2>&1 \
| tr -d '\n ' | sed 's/.*"\([[:digit:]]\+\)".*/\1/'`
cephadm > pg_num=`ceph osd pool get rbd pg_num | cut -f2 -d: | tr -d ' '`
cephadm > echo "current pg_num value: $pg_num, max increment: $max_inc"
cephadm > next_pg_num="$(($pg_num+$max_inc))"
cephadm > echo "allowed increment of pg_num: $next_pg_num"
确定新的归置组数之后,使用以下命令来增加该数量:
root # ceph osd pool set pool_name pg_num next_pg_num
7.2.12 添加存储池
在您首次部署集群之后,Ceph 会使用默认存储池来存储数据。之后,您可以使用以下命令创建新的存储池:
root # ceph osd pool create
有关创建集群存储池的详细信息,请参见第 7.2.2 节 “创建存储池”。
7.3 存储池迁移
创建存储池(请参见第 7.2.2 节 “创建存储池”)时,您需要指定存储池的初始参数,例如存储池类型或归置组数量。如果您在存储池内放置数据后,又决定更改任何初始参数,则需要将存储池数据迁移到参数适合您的部署的另一个存储池中。
迁移存储池的方法有多种。建议使用快速缓存层,因为该方法是透明的,能够减少集群停机时间并避免复制所有存储池的数据。
7.3.1 使用快速缓存层迁移
该方法的原理十分简单,只需将需要迁移的存储池按相反的顺序加入快速缓存层中即可。有关快速缓存层的详细信息,请参见第 10 章 “快速缓存分层”。例如,要将名为“testpool”的副本池迁移到纠删码池,请执行以下步骤:
过程 7.1︰ 将副本池迁移到纠删码池 #
- 创建一个名为“newpool”的新纠删码池:
root@minion > ceph osd pool create newpool 4096 4096 erasure default
您现在有两个池,即装满数据的原始副本池“testpool”和新的空纠删码池“newpool”:
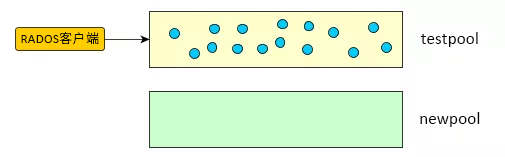
图 7.1︰ 迁移前的存储池 #
- 设置快速缓存层,并将副本池“testpool”配置为快速缓存池:
- root@minion > ceph osd tier add newpool testpool --force-nonempty
root@minion > ceph osd cache-mode testpool forward
自此之后,所有新对象都将创建在新池中:
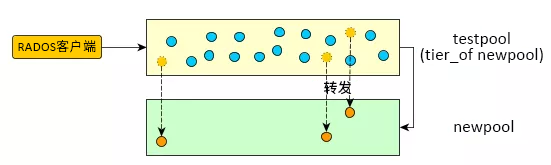
图 7.2︰ 快速缓存层设置 #
- 强制快速缓存池将所有对象移到新池中:
root@minion > rados -p testpool cache-flush-evict-all
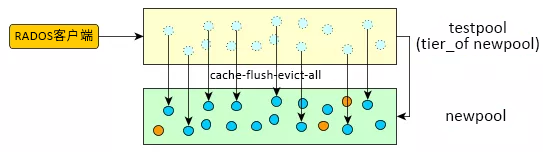
图 7.3︰ 数据清理 #
- 将所有客户端切换到新池。您需要指定一个覆盖层,以便在旧池中搜索对象,直到所有数据都已清理到新的纠删码池。
root@minion > ceph osd tier set-overlay newpool testpool
有了覆盖层,所有操作都会转到旧的副本池“testpool”:
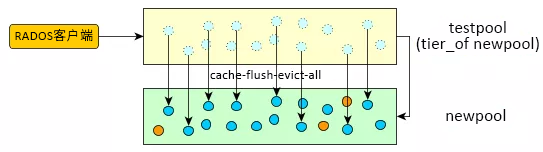
图 7.4︰ 设置覆盖层 #
现在,您可以将所有客户端都切换为访问新池中的对象。
- 所有数据都迁移到纠删码池“newpool”后,删除覆盖层和旧超速缓冲池“testpool”:
- root@minion > ceph osd tier remove-overlay newpool
root@minion > ceph osd tier remove newpool testpool
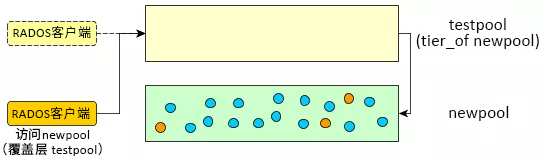
图 7.5︰ 迁移完成 #
7.4 存储池快照
存储池快照是整个 Ceph 存储池的状态快照。通过存储池快照,可以保留存储池状态的历史。创建存储池快照可能需要大量存储空间,具体取决于存储池的大小。在创建存储池快照之前,始终需要检查相关存储是否有足够的磁盘空间。
7.4.1 创建存储池快照
要创建存储池快照,请执行以下命令:
root # ceph osd pool mksnap pool-name snap-name
例如:
root # ceph osd pool mksnap pool1 snapshot1
created pool pool1 snap snapshot1
7.4.2 删除存储池快照
要删除存储池快照,请执行以下命令:
root # ceph osd pool rmsnap pool-name snap-name
7.5 数据压缩
从 SUSE Enterprise Storage 5 开始,BlueStore 提供即时数据压缩,以节省磁盘空间。
7.5.1 启用压缩
可使用以下命令启用存储池的数据压缩:
root # ceph osd pool set POOL_NAME ompression_algorithm snappy
root # ceph osd pool set POOL_NAME compression_mode aggressive
将 POOL_NAME 替换为要启用压缩的存储池。
7.5.2 存储池压缩选项
完整的压缩设置列表:
compression_algorithm
值:none、zstd、snappy。默认值:snappy。
使用的压缩算法取决于特定使用情形。下面是几点建议:
- 不要使用
zlib,其余几种算法更好。 - 如果需要较好的压缩率,请使用
zstd。注意,由于zstd在压缩少量数据时 CPU 开销较高,建议不要将其用于 BlueStore。 - 如果需要较低的 CPU 使用率,请使用
lz4或snappy。 - 针对实际数据的样本运行这些算法的基准测试,观察集群的 CPU 和内存使用率。
compression_mode
值:{none、aggressive、passive、force}。默认值:none。
none:从不压缩passive:如果提示COMPRESSIBLE,则压缩aggressive:除非提示INCOMPRESSIBLE,才压缩force:始终压缩
有关如何设置 COMPRESSIBLE 或 INCOMPRESSIBLE 标志的信息,请参见 http://docs.ceph.com/docs/doc-12.2.0-major-changes/rados/api/librados/#rados_set_alloc_hint。
compression_required_ratio
值:双精度型,比例 = SIZE_COMPRESSED / SIZE_ORIGINAL。默认值:.875
由于净增益低,存储高于此比例的对象时不会压缩。
compression_max_blob_size
值:无符号整数,大小以字节为单位。默认值:0
所压缩对象的最大大小。
compression_min_blob_size
值:无符号整数,大小以字节为单位。默认值:0
所压缩对象的最小大小。
7.5.3 全局压缩选项
可在 Ceph 配置中设置以下配置选项,并将其应用于所有 OSD 而不仅仅是单个存储池。第 7.5.2 节 “存储池压缩选项”中列出的存储池特定配置优先。
bluestore_compression_algorithm
值:none、zstd、snappy、zlib。默认值:snappy。
使用的压缩算法取决于特定使用情形。下面是几点建议:
- 不要使用
zlib,其余几种算法更好。 - 如果需要较好的压缩率,请使用
zstd。注意,由于zstd在压缩少量数据时 CPU 开销较高,建议不要将其用于 BlueStore。 - 如果需要较低的 CPU 使用率,请使用
lz4或snappy。 - 针对实际数据的样本运行这些算法的基准测试,观察集群的 CPU 和内存使用率。
bluestore_compression_mode
值:{none、aggressive、passive、force}。默认值:none。
none:从不压缩passive:如果提示COMPRESSIBLE,则压缩。aggressive:除非提示INCOMPRESSIBLE,才压缩force:始终压缩
有关如何设置 COMPRESSIBLE 或 INCOMPRESSIBLE 标志的信息,请参见 http://docs.ceph.com/docs/doc-12.2.0-major-changes/rados/api/librados/#rados_set_alloc_hint。
bluestore_compression_required_ratio
值:双精度型,比例 = SIZE_COMPRESSED / SIZE_ORIGINAL。默认值:.875
由于净增益低,存储高于此比例的对象时不会压缩。
bluestore_compression_min_blob_size
值:无符号整数,大小以字节为单位。默认值:0
所压缩对象的最小大小。
bluestore_compression_max_blob_size
值:无符号整数,大小以字节为单位。默认值:0
所压缩对象的最大大小。
bluestore_compression_min_blob_size_ssd
值:无符号整数,大小以字节为单位。默认值:8K
压缩并存储在固态硬盘上的对象的最小大小。
bluestore_compression_max_blob_size_ssd
值:无符号整数,大小以字节为单位。默认值:64K
压缩并存储在固态硬盘上的对象的最大大小。
bluestore_compression_min_blob_size_hdd
值:无符号整数,大小以字节为单位。默认值:128K
压缩并存储在普通硬盘上的对象的最小大小。
bluestore_compression_max_blob_size_hdd
值:无符号整数,大小以字节为单位。默认值:512K
压缩并存储在普通硬盘上的对象的最大大小。















 1530
1530











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









