






在Java程序中有效并行使用CPU核心一直是一个挑战。很少有能够将工作分配到多个CPU核心,然后将它们合并以返回结果集的框架。Java 7Fork and Join框架已包含此功能。
基本上,Fork-Join将手头的任务分解为多个小任务,直到该小任务足够简单,可以将其解决而无需进一步拆分。这就像分而治之的算法。在此框架中要注意的一个重要概念是,理想情况下,没有工作线程处于空闲状态。他们实现了一种工作窃取算法,该算法使空闲的工作线程从忙碌的工作线程那里窃取工作进行处理。
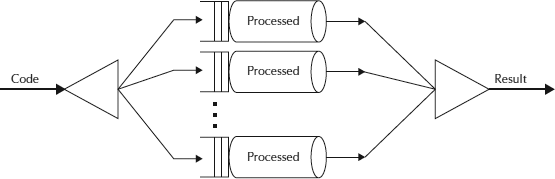
Fork-Join框架
它基于Java并发性思想领袖Doug Lea的工作。Fork / Join处理线程的麻烦;您只需要向框架指出可以分解并递归处理哪些部分。它使用伪代码(摘自Doug Lea关于该主题的论文):
结果解决(问题){
如果(问题很小)
直接解决问题
其他{
将问题分解为独立的部分
分叉新的子任务来解决每个部分
加入所有子任务
由子结果组成结果
}
}讨论要点
1)Fork / Join框架中使用的核心类
i) ForkJoinPool
ii)ForkJoinTask
2)Fork / Join Pool框架的示例实现
i) 实现源代码
ii)它如何工作?
3)Fork / Join框架与ExecutorService之间的区别
4)JDK中的现有实现
5)结论Fork / Join框架中使用的核心类
支持Fork-Join机制的核心类是ForkJoinPool和ForkJoinTask。
货叉池
从本质上讲,它是实现我们上面提到的工作窃取算法的ForkJoinPool一种专门实现ExecutorService。我们ForkJoinPool通过提供目标并行度(即处理器数量)来创建的实例,如下所示:
ForkJoinPool pool = new ForkJoinPool(numberOfProcessors);
Where numberOfProcessors = Runtime.getRunTime().availableProcessors();
尽管您指定了任何初始池大小,但池会动态调整其大小,以尝试在任何给定的时间点维护足够的活动线程。与其他相比,另一个重要的区别ExecutorService是,由于程序池的所有线程都处于守护程序模式,因此无需在程序退出时显式关闭该池。
向任务提交任务的三种不同方法ForkJoinPool。
1)execute()方法//所需的异步执行;调用其fork方法在多个线程之间分配工作。
2)invoke()方法://等待获取结果;在池上调用invoke方法。
3)Submit()方法://返回一个Future对象,可用于检查状态并在完成时获取结果。
ForkJoinTask
这是用于创建在.NET中运行的任务的抽象类ForkJoinPool。该Recursiveaction和RecursiveTask是仅有的两个直接的,称为子类ForkJoinTask。这两个类之间的唯一区别是,RecursiveAction当RecursiveTask确实具有返回值并返回指定类型的对象时,它们不返回值。
在这两种情况下,您都需要在子类中实现compute方法,该方法执行任务所需的主要计算。
本ForkJoinTask类提供了用于检查任务的执行状态的几种方法。该isDone()方法返回,如果以任何方式任务完成如此。该isCompletedNormally()如果没有取消或遇到异常,并且在任务完成方法返回true isCancelled()如果任务被取消,则返回true。最后,如果任务已取消或遇到异常,则isCompletedabnormally()返回true。
Fork / Join Pool框架的示例实现
在此示例中,您将学习如何使用ForkJoinPool和ForkJoinTask类提供的异步方法来管理任务。您将实现一个程序,该程序将搜索文件夹及其子文件夹中具有确定扩展名的文件。ForkJoinTask您将要实现的类将处理文件夹的内容。对于该文件夹内的每个子文件夹,它将ForkJoinPool以异步方式将新任务发送到类。对于该文件夹中的每个文件,任务将检查文件的扩展名并将其继续添加到结果列表中。
上述问题的解决方案在FolderProcessor类中实现,如下所示:
实现源代码
import java.util.concurrent.ForkJoinPool;
import java.util.concurrent.RecursiveAction;
public class CustomRecursiveAction extends RecursiveAction {
/**
*
*/
private static final long serialVersionUID = 1L;
final int THRESHOLD = 2;
double[] numbers;
int indexStart, indexLast;
CustomRecursiveAction(double[] n, int s, int l) {
numbers = n;
indexStart = s;
indexLast = l;
}
@Override
protected void compute() {
if ((indexLast - indexStart) > THRESHOLD)
for (int i = indexStart; i < indexLast; i++)
numbers[i] = numbers[i] + Math.random();
else
invokeAll(new CustomRecursiveAction(numbers, indexStart, (indexStart - indexLast) / 2),
new CustomRecursiveAction(numbers, (indexStart - indexLast) / 2, indexLast));
}
public static void main(String[] args) {
final int SIZE = 10;
ForkJoinPool pool = new ForkJoinPool();
double na[] = new double[SIZE];
System.out.println("initialized random values :");
for (int i = 0; i < na.length; i++) {
na[i] = (double) i + Math.random();
System.out.format("%.4f ", na[i]);
}
System.out.println();
CustomRecursiveAction task = new CustomRecursiveAction(na, 0, na.length);
pool.invoke(task);
System.out.println("Changed values :");
for (int i = 0; i < 10; i++)
System.out.format("%.4f ", na[i]);
System.out.println();
}
}
import java.io.File;
import java.util.ArrayList;
import java.util.List;
import java.util.concurrent.ForkJoinPool;
import java.util.concurrent.RecursiveTask;
import java.util.concurrent.TimeUnit;
public class FolderProcessor extends RecursiveTask<List<String>> {
private static final long serialVersionUID = 1L;
// This attribute will store the full path of the folder this task is going to
// process.
private final String path;
// This attribute will store the name of the extension of the files this task is
// going to look for.
private final String extension;
// Implement the constructor of the class to initialize its attributes
public FolderProcessor(String path, String extension) {
this.path = path;
this.extension = extension;
}
// Implement the compute() method. As you parameterized the RecursiveTask class
// with the List<String> type,
// this method has to return an object of that type.
@Override
protected List<String> compute() {
// List to store the names of the files stored in the folder.
List<String> list = new ArrayList<String>();
// FolderProcessor tasks to store the subtasks that are going to process the
// subfolders stored in the folder
List<FolderProcessor> tasks = new ArrayList<FolderProcessor>();
// Get the content of the folder.
File file = new File(path);
File content[] = file.listFiles();
// For each element in the folder, if there is a subfolder, create a new
// FolderProcessor object
// and execute it asynchronously using the fork() method.
if (content != null) {
for (int i = 0; i < content.length; i++) {
if (content[i].isDirectory()) {
FolderProcessor task = new FolderProcessor(content[i].getAbsolutePath(), extension);
task.fork();
tasks.add(task);
}
// Otherwise, compare the extension of the file with the extension you are
// looking for using the checkFile() method
// and, if they are equal, store the full path of the file in the list of
// strings declared earlier.
else {
if (checkFile(content[i].getName())) {
list.add(content[i].getAbsolutePath());
}
}
}
}
// If the list of the FolderProcessor subtasks has more than 50 elements,
// write a message to the console to indicate this circumstance.
if (tasks.size() > 50) {
System.out.printf("%s: %d tasks ran.\n", file.getAbsolutePath(), tasks.size());
}
// add to the list of files the results returned by the subtasks launched by
// this task.
addResultsFromTasks(list, tasks);
// Return the list of strings
return list;
}
// For each task stored in the list of tasks, call the join() method that will
// wait for its finalization and then will return the result of the task.
// Add that result to the list of strings using the addAll() method.
private void addResultsFromTasks(List<String> list, List<FolderProcessor> tasks) {
for (FolderProcessor item : tasks) {
list.addAll(item.join());
}
}
// This method compares if the name of a file passed as a parameter ends with
// the extension you are looking for.
private boolean checkFile(String name) {
return name.endsWith(extension);
}
public static void main(String[] args) {
// Create ForkJoinPool using the default constructor.
ForkJoinPool pool = new ForkJoinPool();
// Create three FolderProcessor tasks. Initialize each one with a different
// folder path.
FolderProcessor system = new FolderProcessor("C:\\Windows", "log");
FolderProcessor apps = new FolderProcessor("C:\\Program Files", "log");
FolderProcessor documents = new FolderProcessor("C:\\Documents And Settings", "log");
// Execute the three tasks in the pool using the execute() method.
pool.execute(system);
pool.execute(apps);
pool.execute(documents);
// Write to the console information about the status of the pool every second
// until the three tasks have finished their execution.
do {
System.out.printf("******************************************\n");
System.out.printf("Main: Parallelism: %d\n", pool.getParallelism());
System.out.printf("Main: Active Threads: %d\n", pool.getActiveThreadCount());
System.out.printf("Main: Task Count: %d\n", pool.getQueuedTaskCount());
System.out.printf("Main: Steal Count: %d\n", pool.getStealCount());
System.out.printf("******************************************\n");
try {
TimeUnit.SECONDS.sleep(1);
} catch (InterruptedException e) {
e.printStackTrace();
}
} while ((!system.isDone()) || (!apps.isDone()) || (!documents.isDone()));
// Shut down ForkJoinPool using the shutdown() method.
pool.shutdown();
// Write the number of results generated by each task to the console.
List<String> results;
results = system.join();
System.out.printf("System: %d files found.\n", results.size());
results = apps.join();
System.out.printf("Apps: %d files found.\n", results.size());
results = documents.join();
System.out.printf("Documents: %d files found.\n", results.size());
}
}上面程序的输出将如下所示:
Main: Parallelism: 2
Main: Active Threads: 3
Main: Task Count: 1403
Main: Steal Count: 5551
******************************************
******************************************
Main: Parallelism: 2
Main: Active Threads: 3
Main: Task Count: 586
Main: Steal Count: 5551
******************************************
System: 337 files found.
Apps: 10 files found.
Documents: 0 files found.这个怎么运作?
在FolderProcessor该类中,每个任务都处理文件夹的内容。如您所知,此内容包含以下两种元素:
- 档案
- 其他文件夹
如果任务找到一个文件夹,它将创建另一个Task对象来处理该文件夹,并使用fork()方法将其发送到池中。如果该任务具有空闲的工作线程或可以创建新的工作线程,则此方法会将任务发送到执行该任务的池。该方法将立即返回,因此任务可以继续处理文件夹的内容。对于每个文件,任务都会将其扩展名与要查找的扩展名进行比较,如果相等,则将文件名添加到结果列表中。
任务处理完分配的文件夹的所有内容后,它将等待使用join()方法完成发送给池的所有任务的完成。在任务中调用的此方法等待其执行完成,并返回由compute()方法返回的值。该任务将其发送的所有任务的结果与自己的结果分组,并将该列表作为compute()方法的返回值返回。
Fork / Join框架和ExecutorService之间的区别
在该叉/加入和执行器框架之间的主要区别是工作窃取算法。与Executor框架不同,当任务正在等待使用join操作创建的子任务完成时,正在执行该任务的线程(称为worker线程)将寻找尚未执行的其他任务并开始执行它的执行。通过这种方式,线程可以充分利用其运行时间,从而提高了应用程序的性能。
JDK中的现有实现
Java SE中有一些通常有用的功能,已经使用fork / join框架实现了。
1) Java SE 8中引入的一种这样的实现由java.util.Arrays类用于其parallelSort()方法。这些方法类似于sort(),但是通过fork / join框架利用并发性。在多处理器系统上运行时,大型数组的并行排序比顺序排序快。
2)Stream.parallel()中使用的并行性。阅读Java 8中有关此并行流操作的更多信息。
结论
设计好的多线程算法很困难,并且fork / join并非在每种情况下都有效。它在其自身的适用范围内非常有用,但是最后,您必须确定问题是否适合该框架,如果不合适,则必须准备好利用java提供的精湛工具来开发自己的解决方案。 util.concurrent软件包。














 236
236











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









