






我们可以根据在带有路由的 Web 应用程序中访问的 URL 来确定用户看到的页面。使用现代单页应用程序 ( SPA )管理路线的方法不止一种。在本文中,我们将研究哈希路由的工作原理。我们还解释了使用历史 API和 浏览器路由器的更现代的路由方法。这些示例将使用React Router库。
哈希路由器
#作为 URL 的一部分已经存在了很长一段时间了。它位于指向网页中特定资源的 URL 的可选片段之前。看看这个例子:
|
https://developer.mozilla.org/en-US/docs/Web/API/URL#properties
|
当我们访问上面的页面时,浏览器会遍历 DOM 树来寻找具有属性id 的元素。
|
<h2 id="properties">
<a href="#properties" title="Permalink to Properties">Properties</a>
</h2>
|
由于浏览器可以找到上述元素,它会向下滚动视图。
URL 中的井号还有一个重要特征。让我们看看开发者工具:
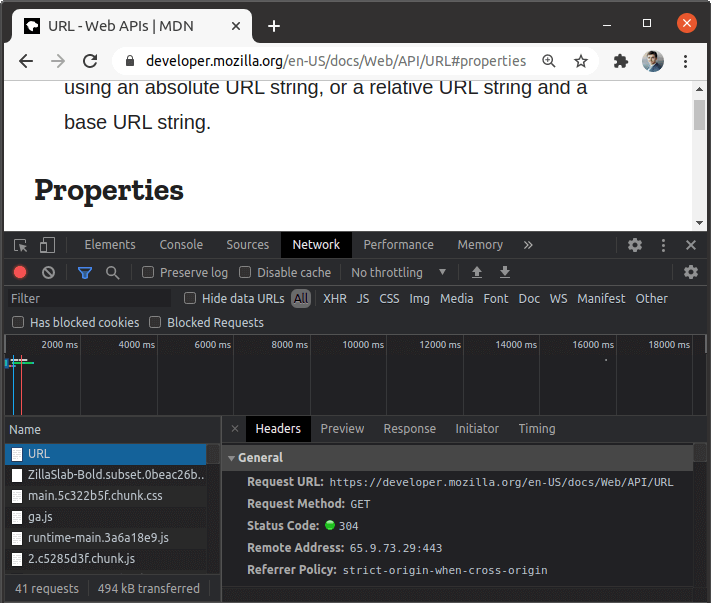
上面,我们可以看到浏览器没有向服务器发送#properties值。它由浏览器解释并通过 JavaScript 访问。
|
console.log(window.location.hash);
// #properties
|
上述事实使哈希成为为单页应用程序创建路由时使用的一个很好的候选者。使用 SPA,我们通常为每个页面提供相同的初始 HTML 代码。然后我们使用 JavaScript 根据 URL 生成页面。
我们可以很容易地体验到上述内容。让我们看看服务器对使用 Create React App 创建的应用程序的响应:

我们可以看到服务器响应了< div id = "root" / > 和一组 JavaScript 文件。我们希望应用程序的每条路由都得到上述响应。因此,我们的服务器不会收到有关用户想要访问的确切路径的信息,这很方便。
使用哈希路由器
要在 React 中使用哈希路由器,我们可以使用React Router 库。
|
npm install react-router-dom
|
|
import React from 'react';
import { HashRouter, Route } from 'react-router-dom';
import Posts from './Pages/Posts';
import LandingPage from './Pages/LandingPage';
export const App = () => (
<HashRouter>
<Route
exact
path='/'
component={LandingPage}
/>
<Route
exact
path='/posts'
component={Posts}
/>
</HashRouter>
)
|
执行上述操作为我们创建了两条路线:
- https : //app.com/#/
- https : //app.com/#/posts
在底层,React Router 使用了历史库。即将发布的 v6.0.0 将使用不再支持旧浏览器的历史库版本。这是由于使用了 History API。这意味着我们将在使用 Internet Explorer 9 及更早版本时遇到问题。如果出于某种原因,你的目标是非常旧的浏览器,你应该使用旧版本的 React Router。
好处
哈希路由的主要卖点是浏览器不会将有关路由的信息发送到 Web 服务器。多亏了这一点,配置非常简单。
缺点
哈希路由的问题在于它看起来有点不合适。这是因为用户通常习惯于干净简单的 URL。因此,中间的哈希可能看起来很奇怪。
此外,使用哈希路由器可能会被认为对 SEO 不利。
浏览器路由器
上述解决方案的替代方案是浏览器路由器。它是在考虑使用History API的情况下构建的。使用 History API,我们可以直接使用 JavaScript 操作浏览器历史记录。
很长一段时间以来,我们已经能够使用 JavaScript 更改 URL。
|
document.location.href = 'https://developer.mozilla.org/';
|
虽然上述方法有效,但它也会重新加载页面。因此,它使其不太适合单页应用程序。
我们可以改变窗口。位置。hash属性没有页面重新加载,但这只会更改哈希值。
使用 History API,我们可以在不触发页面重新加载的情况下更改当前 URL。
|
window.history.pushState({}, null, 'https://developer.mozilla.org/')
|
第一个参数是我们想要与新条目关联的状态。它可以是任何可以序列化的数据。有关更多信息,请查看MDN 文档。
虽然上述功能非常强大,但它也有一些限制。提供的 URL 必须与当前页面的来源相同。
如果您想了解有关 History API 的更多信息,请查看此页面。
使用React Router 库中的BrowserRouter看起来非常简单:
|
import React from 'react';
import { BrowserRouter, Route } from 'react-router-dom';
import Posts from './Pages/Posts';
import LandingPage from './Pages/LandingPage';
export const App = () => (
<BrowserRouter>
<Route
exact
path='/'
component={LandingPage}
/>
<Route
exact
path='/posts'
component={Posts}
/>
</BrowserRouter>
)
|
上面的代码为我们创建了两条路线:
- https : //app.com/
- https : //app.com/posts
我们可以注意到这些 URL 不再包含哈希字符。这意味着即使我们开发单页应用程序,浏览器也会将整个 URL 发送到服务器。即使我们已经使用 React Router 定义了一个路由,我们用来托管我们的应用程序的 Web 服务器可能不知道它。
访问https : //app.com/posts路由可能会导致404 Not Found 错误。我们需要配置我们的 Web 服务器以响应我们的 React 应用程序,而不管它工作的确切路径如何。通过这样做,我们让 React Router 完成所有需要的工作,以根据 URL 确定要呈现的内容。
Web 服务器配置会有所不同,具体取决于您使用的是nginx、Apache、Amazon S3还是其他东西。
好处
BrowserRouter的一大优势是 URL 看起来更清晰。它们不再包含#字符,这对 SEO 来说也可能是一件好事。使用BrowserRouter,我们的用户不会再通过查看 URL 立即注意到他们正在处理单页应用程序。
缺点
虽然BrowserRouter有很多优点,但它需要额外配置的成本。将每个 URL 分别指向我们的 React 应用程序会很麻烦。因此,我们需要将我们的 Web 服务器配置为始终以相同的 HTML 响应每个可能的 URL。如果我们想为同源 API 提供服务,我们需要为其创建一个模式,并且如果 URL 包含* / api / *模式,则不为 React 应用程序提供服务。
概括
在本文中,我们介绍了 HashRouter和BrowserRouter的主要特性。在这样做的同时,我们还描述了一些在它们的引擎盖下工作的机制。事实证明,它们各有优缺点。官方的React Router 文档鼓励我们使用BrowserRouter,即使它需要在 Web 服务器端进行额外的配置。















 956
956











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









