






之前我们看到了如何将嵌入文件添加到 pdf 文档中。本教程演示如何从 PDF 文档中提取嵌入文件。
Maven 依赖项
我们使用 Apache Maven 来管理我们的项目依赖项。确保以下依赖项驻留在类路径中。
<dependency>
<groupId>org.apache.pdfbox</groupId>
<artifactId>pdfbox</artifactId>
<version>2.0.8</version>
</dependency>Apache PDFBox 从 PDF 文档中提取嵌入文件
以下示例从 PDF 文档中提取所有嵌入文件。
package com.memorynotfound.pdf.pdfbox;
import org.apache.pdfbox.pdmodel.PDDocument;
import org.apache.pdfbox.pdmodel.PDDocumentNameDictionary;
import org.apache.pdfbox.pdmodel.PDEmbeddedFilesNameTreeNode;
import org.apache.pdfbox.pdmodel.PDPage;
import org.apache.pdfbox.pdmodel.common.PDNameTreeNode;
import org.apache.pdfbox.pdmodel.common.filespecification.PDComplexFileSpecification;
import org.apache.pdfbox.pdmodel.common.filespecification.PDEmbeddedFile;
import org.apache.pdfbox.pdmodel.interactive.annotation.PDAnnotation;
import org.apache.pdfbox.pdmodel.interactive.annotation.PDAnnotationFileAttachment;
import java.io.File;
import java.io.FileOutputStream;
import java.io.IOException;
import java.util.List;
import java.util.Map;
public class ExtractEmbeddedFiles {
private static final String OUTPUT_DIR = "/tmp";
public static void main(String[] args) throws Exception{
try (final PDDocument document = PDDocument.load(new File("/tmp/embedded-file.pdf"))){
PDDocumentNameDictionary namesDictionary = new PDDocumentNameDictionary( document.getDocumentCatalog());
PDEmbeddedFilesNameTreeNode efTree = namesDictionary.getEmbeddedFiles();
if (efTree != null) {
Map<String, PDComplexFileSpecification> names = efTree.getNames();
if (names != null) {
extractFiles(names);
} else {
List<PDNameTreeNode<PDComplexFileSpecification>> kids = efTree.getKids();
for (PDNameTreeNode<PDComplexFileSpecification> node : kids) {
names = node.getNames();
extractFiles(names);
}
}
}
// extract files from annotations
for (PDPage page : document.getPages()) {
for (PDAnnotation annotation : page.getAnnotations()) {
if (annotation instanceof PDAnnotationFileAttachment) {
PDAnnotationFileAttachment annotationFileAttachment = (PDAnnotationFileAttachment) annotation;
PDComplexFileSpecification fileSpec = (PDComplexFileSpecification) annotationFileAttachment.getFile();
PDEmbeddedFile embeddedFile = getEmbeddedFile(fileSpec);
extractFile(fileSpec.getFilename(), embeddedFile);
}
}
}
} catch (IOException e){
System.err.println("Exception while trying to read pdf document - " + e);
}
}
private static void extractFiles(Map<String, PDComplexFileSpecification> names) throws IOException {
for (Map.Entry<String, PDComplexFileSpecification> entry : names.entrySet()) {
PDComplexFileSpecification fileSpec = entry.getValue();
String filename = fileSpec.getFile();
PDEmbeddedFile embeddedFile = getEmbeddedFile(fileSpec);
extractFile(filename, embeddedFile);
}
}
private static void extractFile(String filename, PDEmbeddedFile embeddedFile) throws IOException {
String embeddedFilename = OUTPUT_DIR + filename;
File file = new File(embeddedFilename);
System.out.println("Writing " + embeddedFilename);
try (FileOutputStream fos = new FileOutputStream(file)) {
fos.write(embeddedFile.toByteArray());
}
}
private static PDEmbeddedFile getEmbeddedFile(PDComplexFileSpecification fileSpec) {
PDEmbeddedFile embeddedFile = null;
if (fileSpec != null) {
embeddedFile = fileSpec.getEmbeddedFileUnicode();
if (embeddedFile == null) {
embeddedFile = fileSpec.getEmbeddedFileDos();
}
if (embeddedFile == null) {
embeddedFile = fileSpec.getEmbeddedFileMac();
}
if (embeddedFile == null) {
embeddedFile = fileSpec.getEmbeddedFileUnix();
}
if (embeddedFile == null) {
embeddedFile = fileSpec.getEmbeddedFile();
}
}
return embeddedFile;
}
}输出
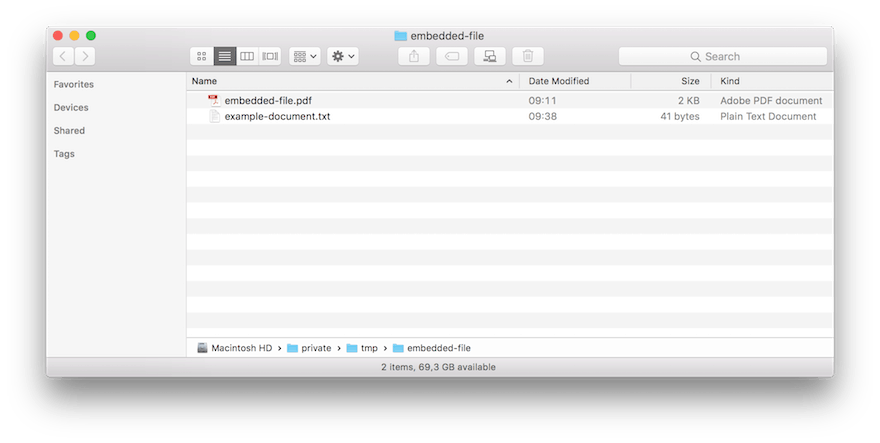
当我们运行应用程序时。嵌入的文件是从 PDF 文档中提取的。
参考















 1055
1055











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









