







介绍
Apache PDFBox是一个开源Java库,支持PDF文档的开发和转换。 使用此库,您可以开发用于创建,转换和操作PDF文档的Java程序。
PDFbox这个PDF处理类库,我使用过程中,能够满足我在一些场景中的需求,达成了我想要的效果,最后在此做一个使用demo的介绍,希望能够给大家带来帮助!
Apache-PDFbox
PDFvox-快速指南-WIKI
注意点
PDF内容是按坐标进行定位的;如果我们能够按照坐标及范围进行读取PDF,那将会更加的精准和高效;
关于如何获取PDF的坐标位置,请查阅如下文章👇
文章链接:如何获取PDF文件中对应内容的坐标及范围?
案例
创建项目
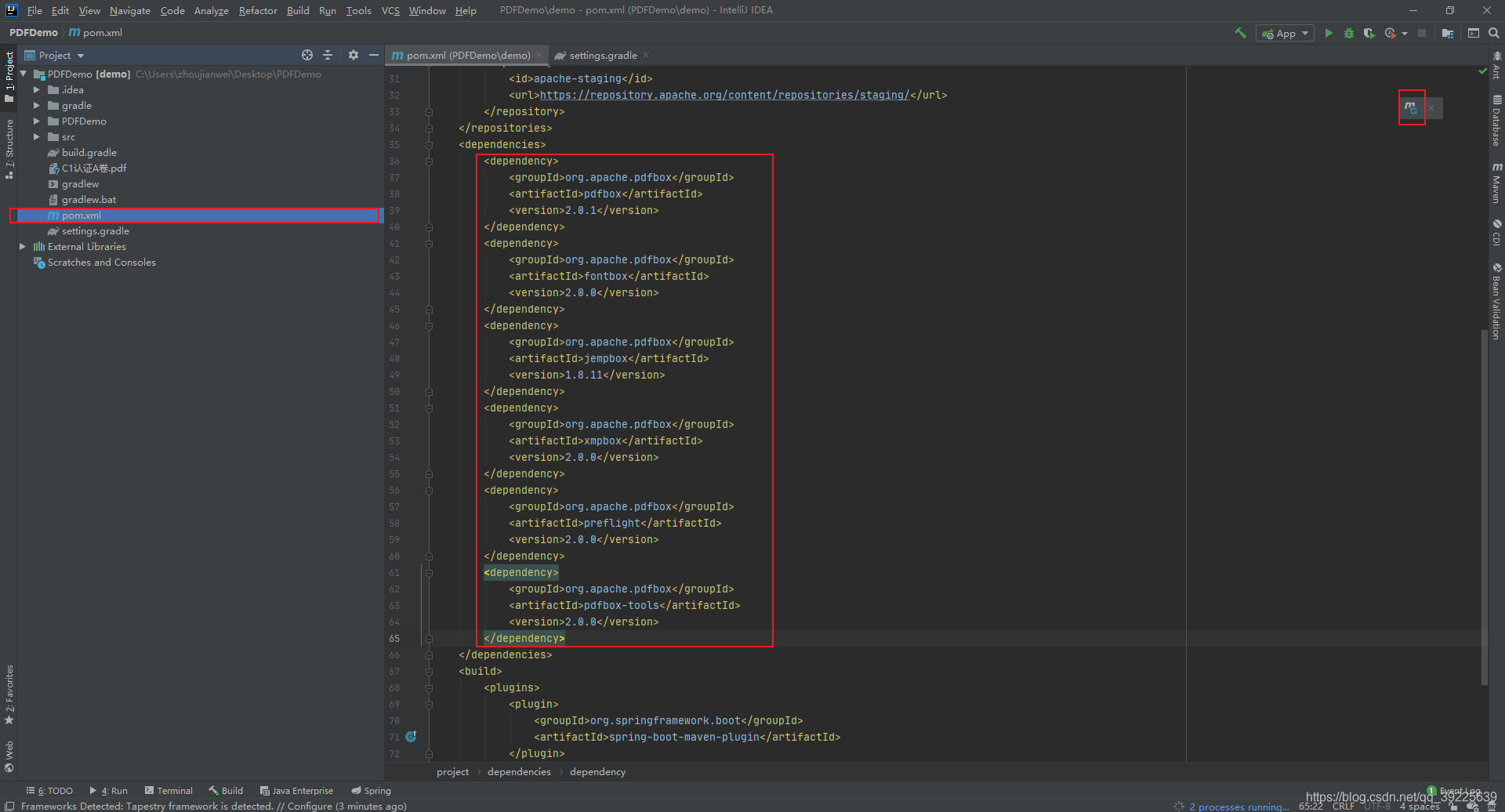
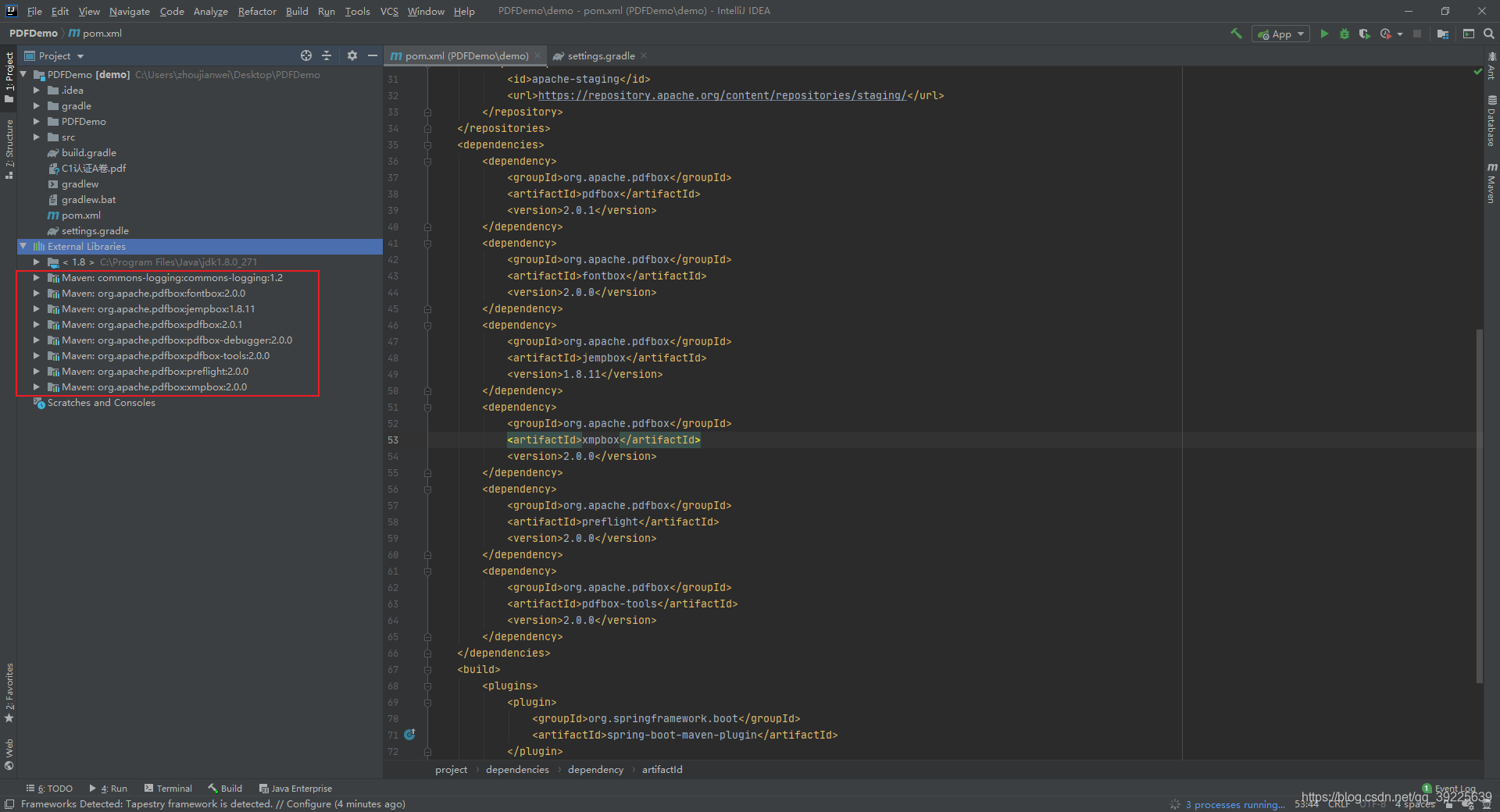
引入依赖
通过maven引入PDFbox依赖
<dependencies>
<dependency>
<groupId>org.apache.pdfbox</groupId>
<artifactId>pdfbox</artifactId>
<version>2.0.1</version>
</dependency>
<dependency>
<groupId>org.apache.pdfbox</groupId>
<artifactId>fontbox</artifactId>
<version>2.0.0</version>
</dependency>
<dependency>
<groupId>org.apache.pdfbox</groupId>
<artifactId>jempbox</artifactId>
<version>1.8.11</version>
</dependency>
<dependency>
<groupId>org.apache.pdfbox</groupId>
<artifactId>xmpbox</artifactId>
<version>2.0.0</version>
</dependency>
<dependency>
<groupId>org.apache.pdfbox</groupId>
<artifactId>preflight</artifactId>
<version>2.0.0</version>
</dependency>
<dependency>
<groupId>org.apache.pdfbox</groupId>
<artifactId>pdfbox-tools</artifactId>
<version>2.0.0</version>
</dependency>
</dependencies>
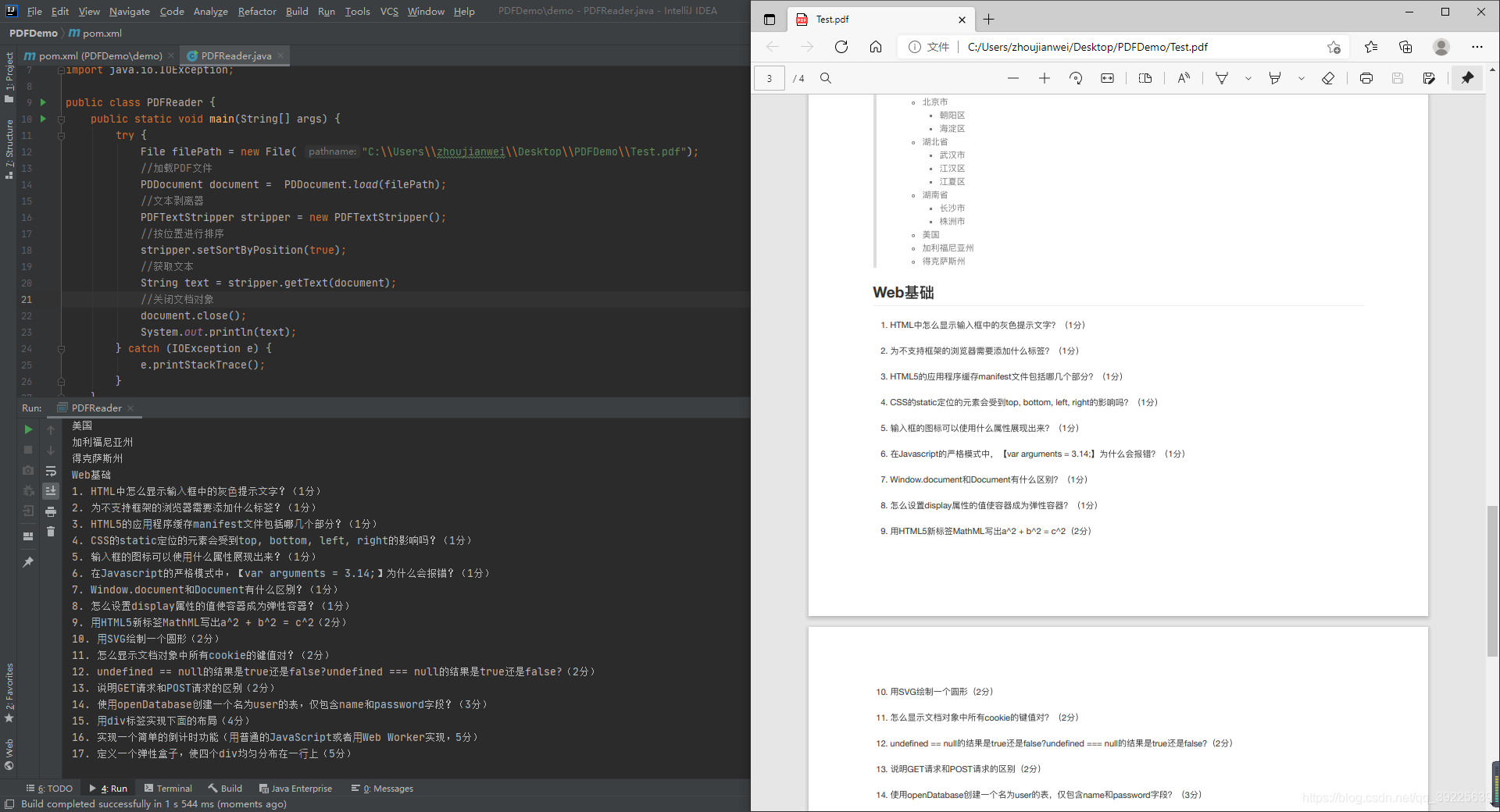
读取PDF文本内容
读取所有页,所有文本
import org.apache.pdfbox.pdmodel.PDDocument;
import org.apache.pdfbox.text.PDFTextStripper;
import java.io.File;
import java.io.IOException;
public class PDFReader {
public static void main(String[] args) {
try {
File filePath = new File( "C:\\Users\\zhoujianwei\\Desktop\\PDFDemo\\Test.pdf");
//加载PDF文件
PDDocument document = PDDocument.load(filePath);
//文本剥离器
PDFTextStripper stripper = new PDFTextStripper();
//按位置进行排序
stripper.setSortByPosition(true);
//获取文本
String text = stripper.getText(document);
//关闭文档对象
document.close();
System.out.println(text);
} catch (IOException e) {
e.printStackTrace();
}
}
}
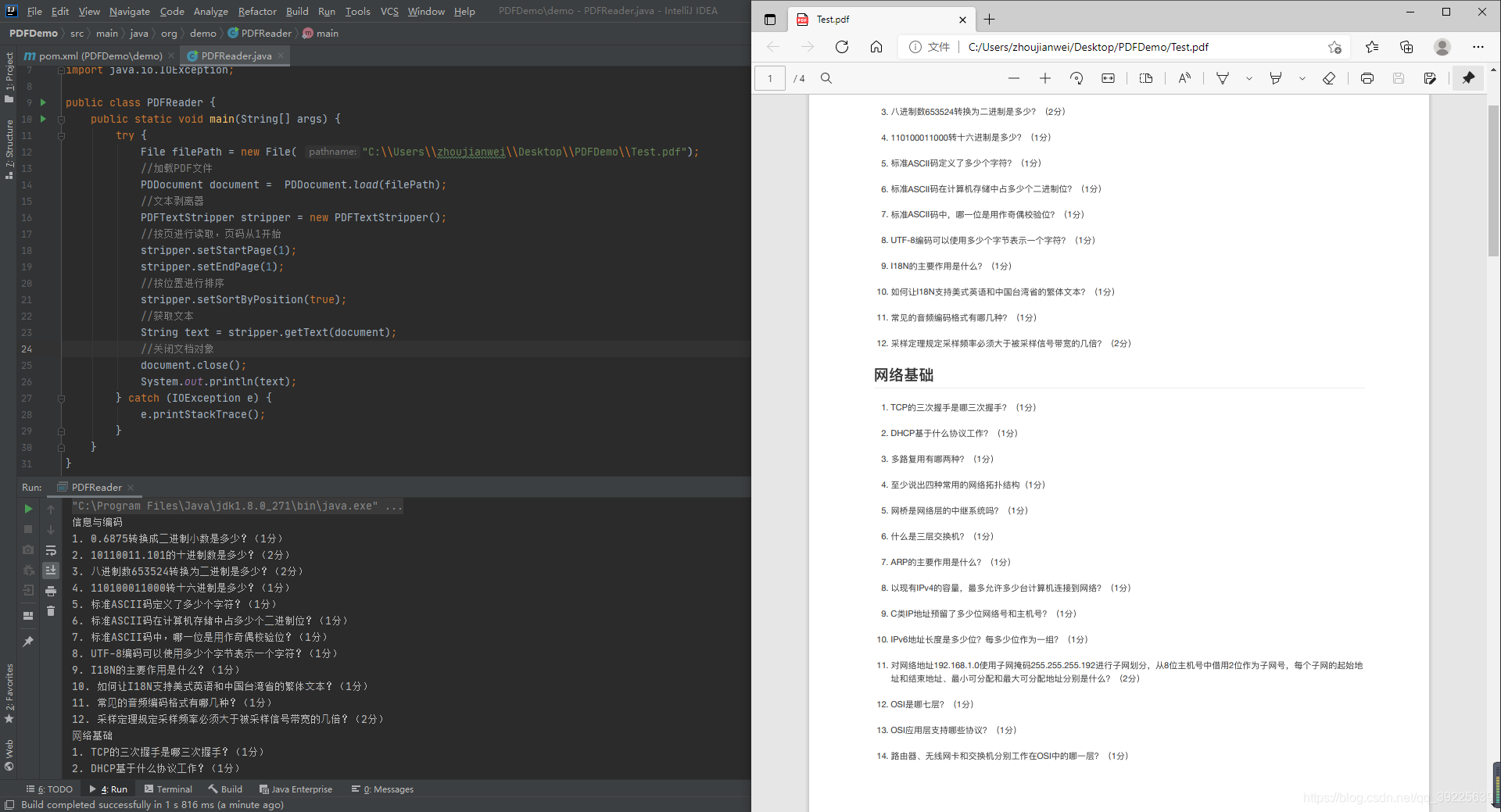
按页读取文本
//按页进行读取,页码从1开始;关键代码
stripper.setStartPage(1);
stripper.setEndPage(1);
import org.apache.pdfbox.pdmodel.PDDocument;
import org.apache.pdfbox.text.PDFTextStripper;
import java.io.File;
import java.io.IOException;
public class PDFReader {
public static void main(String[] args) {
try {
File filePath = new File( "C:\\Users\\zhoujianwei\\Desktop\\PDFDemo\\Test.pdf");
//加载PDF文件
PDDocument document = PDDocument.load(filePath);
//文本剥离器
PDFTextStripper stripper = new PDFTextStripper();
//按页进行读取,页码从1开始
stripper.setStartPage(1);
stripper.setEndPage(1);
//按位置进行排序
stripper.setSortByPosition(true);
//获取文本
String text = stripper.getText(document);
//关闭文档对象
document.close();
System.out.println(text);
} catch (IOException e) {
e.printStackTrace();
}
}
}
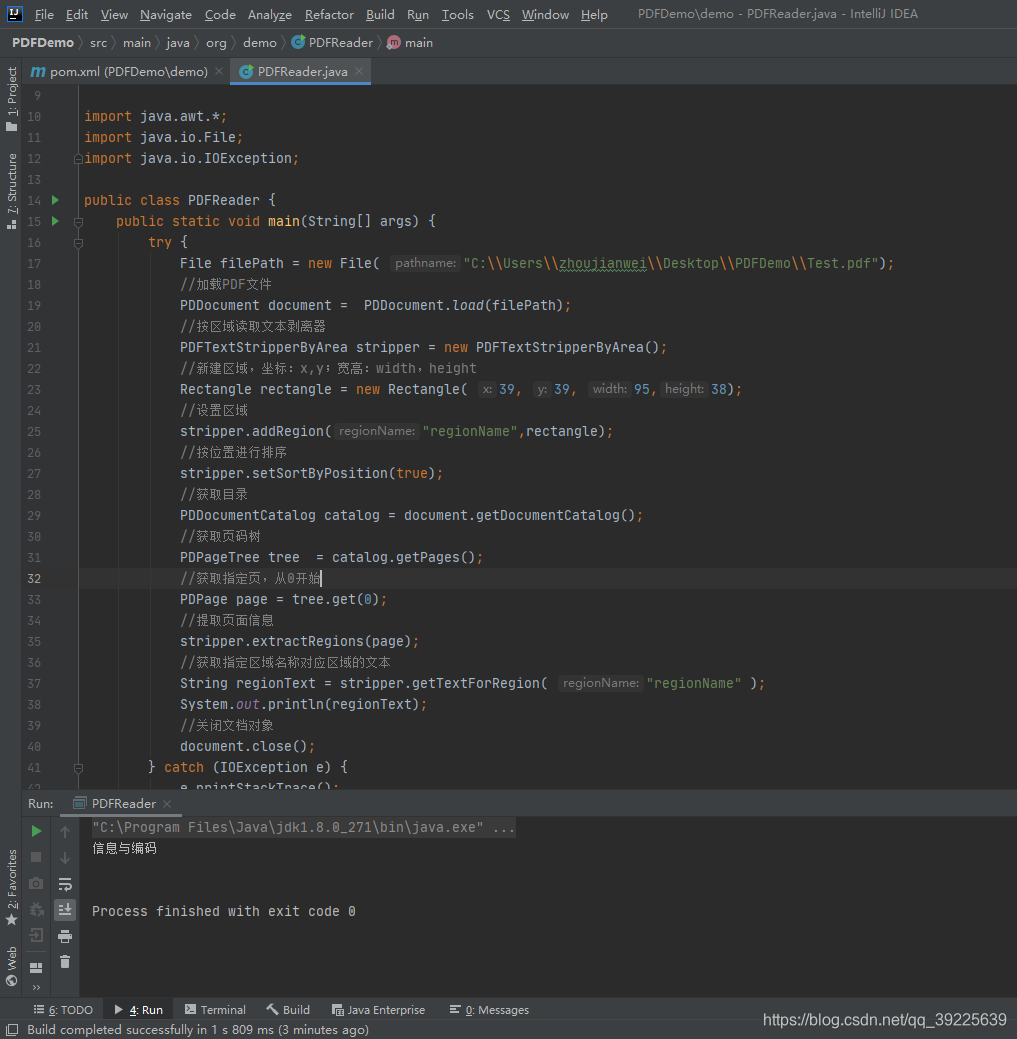
按坐标读取
//普通的文本剥离器
PDFTextStripper stripper = new PDFTextStripper();
//按区域读取文本剥离器
PDFTextStripperByArea stripper = new PDFTextStripperByArea();
//新建区域,坐标:x,y;宽高:width,height
Rectangle rectangle = new Rectangle( 39, 39, 95,38);
//设置区域
stripper.addRegion("regionName",rectangle);
//按位置进行排序
stripper.setSortByPosition(true);
//获取目录
PDDocumentCatalog catalog = document.getDocumentCatalog();
//获取页码树
PDPageTree tree = catalog.getPages();
//获取指定页,从0开始
PDPage page = tree.get(0);
//提取页面信息
stripper.extractRegions(page);
//获取指定区域名称对应区域的文本
String regionText = stripper.getTextForRegion( "regionName" );
区域坐标及范围测量;👇
文章链接:如何获取PDF文件中对应内容的坐标及范围?

完整代码
package org.demo;
import org.apache.pdfbox.pdmodel.PDDocument;
import org.apache.pdfbox.pdmodel.PDDocumentCatalog;
import org.apache.pdfbox.pdmodel.PDPage;
import org.apache.pdfbox.pdmodel.PDPageTree;
import org.apache.pdfbox.text.PDFTextStripper;
import org.apache.pdfbox.text.PDFTextStripperByArea;
import java.awt.*;
import java.io.File;
import java.io.IOException;
public class PDFReader {
public static void main(String[] args) {
try {
File filePath = new File( "C:\\Users\\zhoujianwei\\Desktop\\PDFDemo\\Test.pdf");
//加载PDF文件
PDDocument document = PDDocument.load(filePath);
//按区域读取文本剥离器
PDFTextStripperByArea stripper = new PDFTextStripperByArea();
//新建区域,坐标:x,y;宽高:width,height
Rectangle rectangle = new Rectangle( 39, 39, 95,38);
//设置区域
stripper.addRegion("regionName",rectangle);
//按位置进行排序
stripper.setSortByPosition(true);
//获取目录
PDDocumentCatalog catalog = document.getDocumentCatalog();
//获取页码树
PDPageTree tree = catalog.getPages();
//获取指定页,从0开始
PDPage page = tree.get(0);
//提取页面信息
stripper.extractRegions(page);
//获取指定区域名称对应区域的文本
String regionText = stripper.getTextForRegion( "regionName" );
System.out.println(regionText);
//关闭文档对象
document.close();
} catch (IOException e) {
e.printStackTrace();
}
}
}
运行结果



















 2111
2111

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











