







PGPool-II 4.2.1+PostgreSQL 13高可用
说明
按照示例文档过程一步步操作,要注意一些权限配置和用户密码。官方加密用了scram-sha-256,此文档全用md5。在ECS上部署VIP有问题,实体机可避免。
示例
https://www.pgpool.net/docs/latest/en/html/example-cluster.html
参考
数据库架构之【PostgreSQL12+PGPool-II4】RDBMS 集群方案 https://www.jianshu.com/p/dffd096f368d
数据库架构之【PostgreSQL12+Replication】RDBMS 主从库读写分离方案 https://www.jianshu.com/p/73e8357f31ad
图示
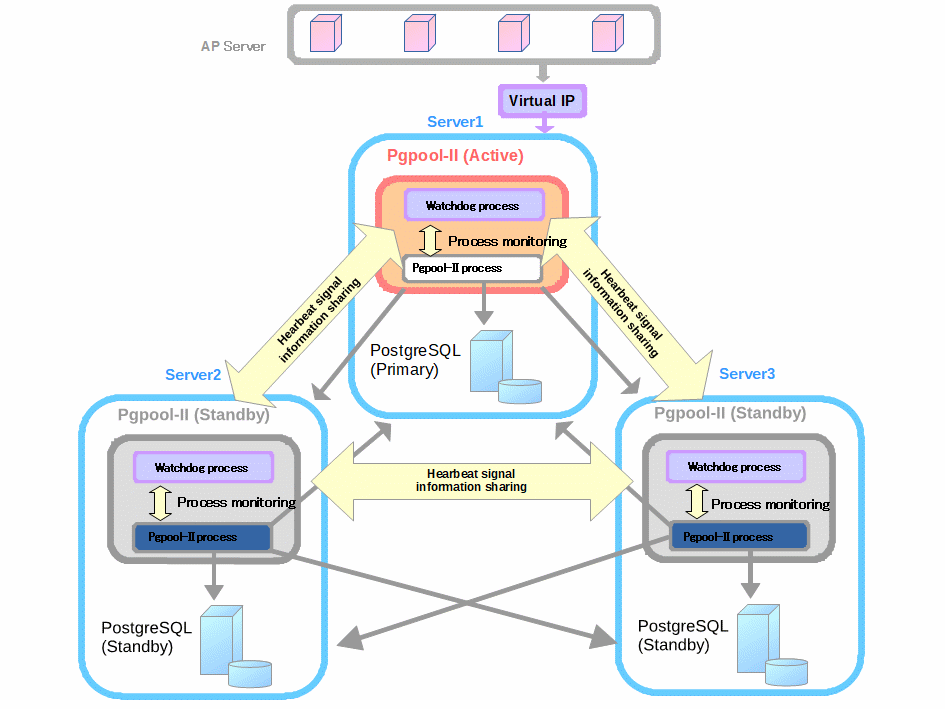
PostgreSQL 集群
| 节点名 | 主机名 | IP:Port | 版本 | 操作系统 |
|---|---|---|---|---|
| 主 | M62 | 172.19.129.62:5432 | postgres:13-alpine | Centos7.6 |
| 从1 | M68 | 172.19.129.68:5432 | postgres:13-alpine | Centos7.6 |
| 从2 | M69 | 172.19.129.69:5432 | postgres:13-alpine | Centos7.6 |
PGPool-II中间件集群
机器足够可以将PGPool集群与PostgresSQL集群分开部署
| 主机名 | IP:Port | 版本 | 操作系统 | |
|---|---|---|---|---|
| 活 | M62 | :9000/9898/9000/9694 | pgpool/pgpool:4.2 | Centos7.6 |
| 备1 | M68 | :9000/9898/9000/9694 | pgpool/pgpool:4.2 | Centos7.6 |
| 备2 | M69 | :9000/9898/9000/9694 | pgpool/pgpool:4.2 | Centos7.6 |
PGPool-II Virtual IP:192.19.129.100
当存在≥2个以上集群节点时,通过配置PGPool-II的Watchdog组件建立高可用集群,客户端通过虚拟IP访问集群中间件。但是需要注意,当只有1个集群节点有效时,虚拟IP自动失效。
PostgreSQL 主从配置
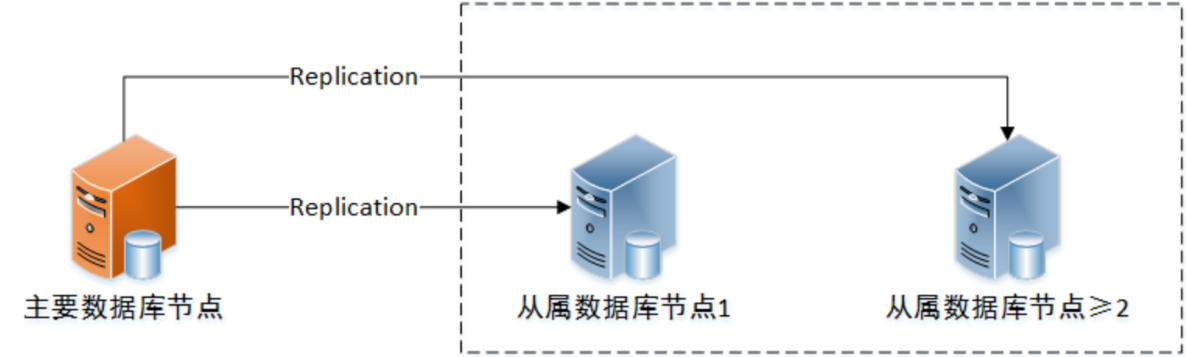
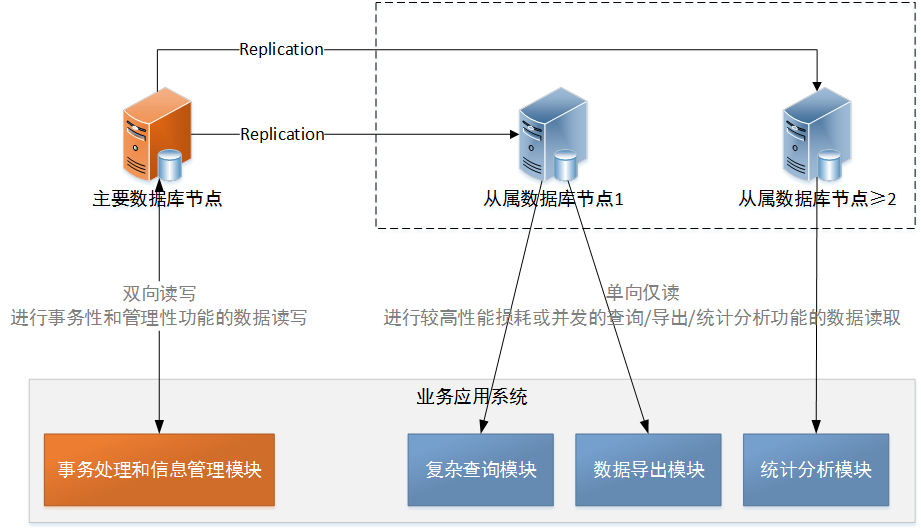
各个从库节点实现了数据库的实时备份,当主库节点服务器的磁盘或文件故障时,能够避免数据损失并为主库节点提供恢复副本,提高数据安全性。
应用系统事务性的插入/更新/删除/查询类操作可以通过主库节点完成,而较高性能损耗和高并发的查询/统计/分析/导出类操作可以通过多个从库节点完成,实现读写分离,提高应用系统性能。
应用
按说明一步步操作,[all servers]表示3台服务器同时操作,[server1]表示操作server1,未明确的也是操作server1。#表示root命令 $表示postgres命令。
系统环境
# 关闭防火墙
[all servers]# systemctl disable firewalld
# 关闭selinux 重启生效
[all servers]# sed -i '/^SELINUX=.*/ s//SELINUX=disabled/' /etc/selinux/config
[all servers]# setenforce 0 && reboot
# hosts
[all servers]#
echo "172.19.129.62 server1" >> /etc/hosts
echo "172.19.129.68 server2" >> /etc/hosts
echo "172.19.129.69 server3" >> /etc/hosts
# 修改 hostname
[server1]# hostnamectl set-hostname server1
[server2]# hostnamectl set-hostname server2
[server3]# hostnamectl set-hostname server3
PostgreSQL-13
安装
yum install -y https://download.postgresql.org/pub/repos/yum/reporpms/EL-7-x86_64/pgdg-redhat-repo-latest.noarch.rpm
yum install -y postgresql13-server
# 下载文件
# yum install -y --downloadonly --downloaddir=$PWD postgresql13-server
# 服务
systemctl enable postgresql-13
离线
# 内网安装
rpm -ivh *.rpm
# 服务
systemctl enable postgresql-13
数据初始化
[all servers]# su - postgres
[all servers]$ vi ~/.bash_profile
export PGHOME=/usr/pgsql-13
export PGUSER=postgres
export LD_LIBRARY_PATH=$PGHOME/lib:$LD_LIBRARY_PATH
export PATH=$PGHOME/bin:$PATH
export PGDATA=/var/lib/pgsql/13/data
[all servers]$ source ~/.bash_profile
[all servers]$ initdb
[all servers]$ exit
设置
权限
[all servers]# vi ~/.bashrc
alias ll='ls -h -l --color=always'
export PS1='[\u@\h \t \w]$ '
export PGDATA=/var/lib/pgsql/13/data
[all servers]# vi $PGDATA/postgresql.conf
listen_addresses = '*'
[all servers]# vi $PGDATA/pg_hba.conf
# 权限尽量放开,samenet同网段
host all all samenet md5
host replication all samenet md5
开启 WAL archiving
[all servers]# su - postgres
[all servers]$ mkdir /var/lib/pgsql/archivedir
[servers1]# vi $PGDATA/postgresql.conf
archive_mode = on
archive_command = 'cp "%p" "/var/lib/pgsql/archivedir/%f"'
on server1 (primary) as follows. Enable wal_log_hints to use pg_rewind. Since the Primary may become a Standby later, we set hot_standby = on.
# 在文件最后添加以下内容
[servers1]# vi $PGDATA/postgresql.conf
max_wal_senders = 10
max_replication_slots = 10
wal_level = replica
hot_standby = on
wal_log_hints = on
开启postgres服务
[all servers]# systemctl start postgresql-13
# pg库中postgres密码(postgres)
# 默认md5加密,可用命令查询 sudo -u postgres psql -c "show password_encryption"
# 官方文档是scram-sha-256算法,此处仍用md5
[all servers]# sudo -u postgres psql -U postgres -p 5432
postgres=# CREATE ROLE pgpool WITH LOGIN;
postgres=# CREATE ROLE repl WITH REPLICATION LOGIN;
postgres=# \password pgpool
postgres=# \password repl
postgres=# \password postgres
# pgpool_status中显示
postgres=# GRANT pg_monitor TO pgpool;
# 查看结果 replication_state
postgres=# \du
postgres=# exit

从节点配置(弃)
改用官方文档的方法,在配置好pgpool后启用。此方法导致 replication_state不生效,是否有其他影响未知。
[server2 server3]# systemctl stop postgresql-13
[server2 server3]# rm $PGDATA -rf
[server2 server3]# sudo -u postgres /usr/pgsql-13/bin/pg_basebackup -h server1 -U postgres -p 5432 -D $PGDATA -Fp -Xs -P -R
[server2 server3]# systemctl start postgresql-13
密码
# 设置 postgres用户密码(postgres)
[all servers]# passwd postgres
检查
[all servers]# sudo -u postgres psql -c "select pg_is_in_recovery()"
# f-主 t-从
[server1]# sudo -u postgres psql -x -c "select * from pg_stat_replication" -d postgres
SSH 互信
[all servers]# cd ~/.ssh
[all servers]# ssh-keygen -t rsa -f id_rsa_pgpool
[all servers]# ssh-copy-id -i id_rsa_pgpool.pub postgres@server1
[all servers]# ssh-copy-id -i id_rsa_pgpool.pub postgres@server2
[all servers]# ssh-copy-id -i id_rsa_pgpool.pub postgres@server3
[all servers]# su - postgres
[all servers]$ cd ~/.ssh
[all servers]$ ssh-keygen -t rsa -f id_rsa_pgpool
[all servers]$ ssh-copy-id -i id_rsa_pgpool.pub postgres@server1
[all servers]$ ssh-copy-id -i id_rsa_pgpool.pub postgres@server2
[all servers]$ ssh-copy-id -i id_rsa_pgpool.pub postgres@server3
# 为数据库repl online-recover配置免密,最后一列为数据库中配置的密码
[all servers]$ vi /var/lib/pgsql/.pgpass
server1:5432:replication:repl:repl
server2:5432:replication:repl:repl
server3:5432:replication:repl:repl
server1:5432:postgres:postgres:postgres
server2:5432:postgres:postgres:postgres
server3:5432:postgres:postgres:postgres
[all servers]$ chmod 600 /var/lib/pgsql/.pgpass
测试
ssh postgres@server1 -i ~/.ssh/id_rsa_pgpool ls /home
PGPool-II
安装
# 采用7.6 不支持 7.8
yum install -y https://www.pgpool.net/yum/rpms/4.2/redhat/rhel-7-x86_64/pgpool-II-release-4.2-1.noarch.rpm
yum install -y pgpool-II-pg13-*
# 下载文件
# yum install --downloadonly --downloaddir=$PWD pgpool-II-pg13-*
# 服务
systemctl enable pgpool
离线
# 需要依赖项,待确认
rpm -ivh *.rpm
# 服务
systemctl enable pgpool
pgpool.conf
[all servers]# \cp -p /etc/pgpool-II/pgpool.conf.sample-stream /etc/pgpool-II/pgpool.conf
# [CONNECTIONS]
listen_addresses = '*'
port = 9999
socket_dir = '/var/run/postgresql'
## - Backend Connection Settings -
backend_hostname0 = 'server1'
backend_data_directory0 = '/var/lib/pgsql/13/data'
backend_application_name0 = 'server1'
backend_flag0 = 'ALLOW_TO_FAILOVER'
backend_port0 = 5432
backend_weight0 = 1
backend_hostname1 = 'server2'
backend_data_directory1 = '/var/lib/pgsql/13/data'
backend_application_name1 = 'server2'
backend_flag1 = 'ALLOW_TO_FAILOVER'
backend_port1 = 5432
backend_weight1 = 1
backend_hostname2 = 'server3'
backend_data_directory2 = '/var/lib/pgsql/13/data'
backend_application_name2 = 'server3'
backend_flag2 = 'ALLOW_TO_FAILOVER'
backend_port2 = 5432
backend_weight2 = 1
## - Authentication -
enable_pool_hba = on
pool_passwd = 'pool_passwd'
# [LOGS]
logging_collector = on
log_directory = '/var/log/pgpool_log'
log_filename = 'pgpool-%Y-%m-%d_%H%M%S.log'
log_file_mode = 0600
log_truncate_on_rotation = on
log_rotation_age = 1d
log_rotation_size = 10MB
# [FILE LOCATIONS]
pid_file_name = '/var/run/pgpool/pgpool.pid'
## 此目录用来存放 pgpool_status 文件,此文件保存集群状态(刷新有问题时会造成show pool_status不正确)
logdir = '/tmp'
# [NATIVE REPLICATION MODE]
sr_check_user = 'pgpool'
## 为''时查找 pool_passwd
sr_check_password = 'pgpool'
follow_primary_command = '/etc/pgpool-II/follow_primary.sh %d %h %p %D %m %H %M %P %r %R'
# [HEALTH CHECK GLOBAL PARAMETERS]
health_check_period = 5
health_check_timeout = 30
health_check_user = 'pgpool'
## 为''时查找 pool_passwd
health_check_password = 'pgpool'
health_check_max_retries = 3
# [FAILOVER AND FAILBACK]
failover_command = '/etc/pgpool-II/failover.sh %d %h %p %D %m %H %M %P %r %R %N %S'
# [ONLINE RECOVERY]
recovery_user = 'postgres'
recovery_password = 'postgres'
recovery_1st_stage_command = 'recovery_1st_stage'
# [WATCHDOG]
use_watchdog = on
hostname0 = 'server1'
wd_port0 = 9000
pgpool_port0 = 9999
hostname1 = 'server2'
wd_port1 = 9000
pgpool_port1 = 9999
hostname2 = 'server3'
wd_port2 = 9000
pgpool_port2 = 9999
wd_ipc_socket_dir = '/var/run/postgresql'
## - Virtual IP control Setting -
delegate_IP = '172.19.129.100'
## - Behaivor on escalation Setting -
wd_escalation_command = '/etc/pgpool-II/escalation.sh'
## - Lifecheck Setting -
wd_lifecheck_method = 'heartbeat'
### -- heartbeat mode --
heartbeat_hostname0 = 'server1'
heartbeat_port0 = 9694
heartbeat_device0 = ''
heartbeat_hostname1 = 'server2'
heartbeat_port1 = 9694
heartbeat_device1 = ''
heartbeat_hostname2 = 'server3'
heartbeat_port2 = 9694
heartbeat_device2 = ''
操作
pool_passwd
[all servers]# pg_md5 -p -m -u postgres pool_passwd
[all servers]# pg_md5 -p -m -u pgpool pool_passwd
[all servers]# cat /etc/pgpool-II/pool_passwd

Create pgpool_node_id
From Pgpool-II 4.2, now all configuration parameters are identical on all hosts. If watchdog feature is enabled, to distingusish which host is which, a pgpool_node_id file is required. You need to create a pgpool_node_id file and specify the pgpool (watchdog) node number (e.g. 0, 1, 2 …) to identify pgpool (watchdog) host.
[server1]# echo 0 > /etc/pgpool-II/pgpool_node_id
[server2]# echo 1 > /etc/pgpool-II/pgpool_node_id
[server3]# echo 2 > /etc/pgpool-II/pgpool_node_id
follow_primary_command
为follow_primary.sh中PCP_USER=pgpool配置免密登录
# pg_md5 密码
[all servers]# echo 'pgpool:'`pg_md5 pgpool` >> /etc/pgpool-II/pcp.conf
[all servers]# su - postgres
[all servers]$ echo 'localhost:9898:pgpool:pgpool' > ~/.pcppass
[all servers]$ chmod 600 ~/.pcppass
enable_pool_hba
# enable_pool_hba = on
[all servers]# vi /etc/pgpool-II/pool_hba.conf
# 官方文档为 scram-sha-256,改为md5
host all pgpool 0.0.0.0/0 md5
host all postgres 0.0.0.0/0 md5
Failover configuration
[all servers]# cd /etc/pgpool-II
[all servers]# cp -p /etc/pgpool-II/failover.sh{.sample,}
[all servers]# cp -p /etc/pgpool-II/follow_primary.sh{.sample,}
[all servers]# chown postgres:postgres /etc/pgpool-II/{failover.sh,follow_primary.sh}
- 修改FAILED_NODE_HOST,不能用IP的BUG。
# ``drop` `replication slot
ssh -T -o StrictHostKeyChecking=``no` `-o UserKnownHostsFile=/dev/``null` `postgres@${NEW_MASTER_NODE_HOST} -i ~/.ssh/id_rsa_pgpool ``"
${PGHOME}/bin/psql -p ${NEW_MASTER_NODE_PORT} -c \"SELECT pg_drop_replication_slot('${FAILED_NODE_HOST//./_}')\""
Online Recovery Configurations
[all servers]# cp -p /etc/pgpool-II/recovery_1st_stage.sample /var/lib/pgsql/13/data/recovery_1st_stage
[all server1]# cp -p /etc/pgpool-II/pgpool_remote_start.sample /var/lib/pgsql/13/data/pgpool_remote_start
[all server1]# chown postgres:postgres /var/lib/pgsql/13/data/{recovery_1st_stage,pgpool_remote_start}
In order to use the online recovery functionality, the functions of pgpool_recovery, pgpool_remote_start, pgpool_switch_xlog are required, so we need install pgpool_recovery on template1 of PostgreSQL server server1.
[server1]# sudo -u postgres psql template1 -c "CREATE EXTENSION pgpool_recovery"
wd_escalation_command
[all servers]# cd /etc/pgpool-II
[all servers]# cp -p /etc/pgpool-II/escalation.sh{.sample,}
[all servers]# chown postgres:postgres /etc/pgpool-II/escalation.sh
# 修改 $VIP/24为$VIP/20 掩码
[all servers]# vi /etc/pgpool-II/escalation.sh
...
PGPOOLS=(server1 server2 server3)
VIP=172.19.129.100
DEVICE=eth0
for pgpool in "${PGPOOLS[@]}"; do
[ "$HOSTNAME" = "$pgpool" ] && continue
ssh -T -o StrictHostKeyChecking=no -o UserKnownHostsFile=/dev/null postgres@$pgpool -i ~/.ssh/id_rsa_pgpool "
/usr/bin/sudo /sbin/ip addr del $VIP/20 dev $DEVICE
"
done
exit 0
logging 相应操作
[all servers]# mkdir /var/log/pgpool_log/
[all servers]# chown postgres:postgres /var/log/pgpool_log/
启动PGPool
- /etc/sysconfig/pgpool Configuration
# -d表示debug
[all servers]# vi /etc/sysconfig/pgpool
...
OPTS=" -D -n"
- 启动pgpool
# 按顺序启动
[servers1]# systemctl start pgpool
[server2 server3]# systemctl start pgpool
主从模式
# 备节点停pg,删除相应文件(否则报错:pre-existing shared memory block)
[server2 server3]# systemctl stop postgresql-13
# 查看有没有活动进程,有则kill -9杀掉,否则后面操作不成功。
[server2 server3]# ps wax | grep `head -1 /var/lib/pgsql/13/data/postmaster.pid`
# 主节点操作
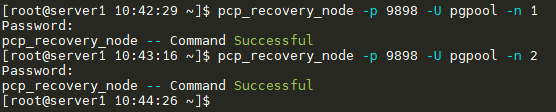
[server1]# pcp_recovery_node -h 172.19.129.100 -p 9898 -U pgpool -n 1
[server1]# pcp_recovery_node -h 172.19.129.100 -p 9898 -U pgpool -n 2
# 备节点启pg
## 不要做[server2 server3]# systemctl start postgresql-13
# 检查 f-主 t-从
[all servers]# sudo -u postgres psql -c "select pg_is_in_recovery()"
# 主节点查看复制信息,此处为验证是否成功的关键
[server1]# sudo -u postgres psql -x -c "select * from pg_stat_replication" -d postgres
后记
虚拟IP问题
-
由于用的服务器是ECS云虚拟主机,所以只在抢到虚拟IP的主机才能连接虚拟IP。相关测试只在相应的主机上进行。
-
虚拟IP默认掩码为24,我的是20,修改配置(注意/20):
[all servers]# vi /etc/pgpool-II/pgpool.conf if_up_cmd = '/usr/bin/sudo /sbin/ip addr add $_IP_$/20 dev eth0 label eth0:0' if_down_cmd = '/usr/bin/sudo /sbin/ip addr del $_IP_$/20 dev eth0'
关于logdir
默认值 /tmp,改为 /var/log/pgpool_log (日志目录)。会提示file not exists,如下处理后,重启服务。提示discarded,可查看内容(为up等状态)。
touch /var/log/pgpool_log/pgpool_status
chown postgres:postgres /var/log/pgpool_log/pgpool_status
关于主从模式
主从模式建立有两种方式,1.手动执行 pg_basebackup,2.用pcp_recovery_node
方法2能避免一些隐性问题,如show pool_nodes时eplication_state不显示。
故障恢复(弃)
以下为手动恢复方案,慎用。尽量采用集群管理的命令。
在复制模式中,数据库的任一节点发生故障后会自动离线,离线之后的数据库不论是否仍然可用,都会脱离集群成为单点数据库,只有重新启动集群后,才会恢复成在线数据库。
故障节点恢复的思路是:将已离线的节点通过流复制的方式从在线节点中同步最新数据后,重启集群服务,将离线节点重新恢复在线。
1、禁止所有节点的对外请求响应。
关闭集群,通过关闭防火墙策略或定义数据库实例目录中"pg_hba.conf"文件的策略,使所有节点受限访问,固定数据库快照。
2、开启任一在线节点的 Replication 访问策略,作为故障节点恢复的数据库参照节点。
3、故障(离线)节点通过 Replication 同步最新数据。
假设故障节点为server2
# 停止数据库服务(默认已经停止)。
[server2]# systemctl stop postgresql-13
# 清空数据库实例目录中的数据(注意删除隐藏文件)。
[server2]# rm -rf /var/lib/pgsql/13/data
# 从主要数据库(假设此时为server1)执行备份并还原到本地。
[server2]# sudo -u postgres /usr/pgsql-13/bin/pg_basebackup -h server1 -U postgres -p 5432 -D /var/lib/pgsql/13/data -Fp -Xs -P -R
# 重新启动数据库。
[server2]# systemctl start postgresql-13
# 验证当前数据库节点是否为从属节点,查询结果为"t"表示当前数据库节点为从属节点。
[server2]# sudo -u postgres /usr/pgsql-13/bin/psql -c "select pg_is_in_recovery()"
4、恢复新主要节点的对外请求响应。
集群管理
PGPool 集群
查看集群配置信息
pcp_pool_status -h 172.19.129.100 -p 9898 -U pgpool -v
查看集群节点详情
# -h 表示集群IP,-p 表示PCP管道端口(默认是9898),-U 表示 PCP管道用户,-v表示查看详细内容
pcp_watchdog_info -h 172.19.129.100 -p 9898 -U pgpool -v
查看节点数量
pcp_node_count -h 172.19.129.100 -p 9898 -U pgpool
查看指定节点信息
pcp_node_info -h 172.19.129.100 -p 9898 -U pgpool -n 0 -v
增加一个集群节点
# -n 表示节点序号(从0开始)
pcp_attach_node -h 172.19.129.100 -p 9898 -U pgpool -n 0 -v
脱离一个集群节点
pcp_detach_node -h 172.19.129.100 -p 9898 -U pgpool -n 0 -v
提升一个备用节点为活动节点
pcp_promote_node -h 172.19.129.100 -p 9898 -U pgpool -n 0 -v
恢复一个离线节点为集群节点
pcp_recovery_node -h 172.19.129.100 -p 9898 -U pgpool -n 0 -v
PostgresSQL集群
连接集群
[all servers]$ psql -h 172.19.129.100 -p 9999
查看集群状态
# 可加参数 -h 172.19.129.100 通过 VIP
[all servers]$ psql -p 9999 -U postgres postgres -c "show pool_nodes"

测试
主节点故障
-
[server1]# systemctl stop postgresql-13 -
正常迁移
-
恢复数据
- 方案1
pcp_recovery_node -h 172.19.129.100 -p 9898 -U pgpool -n 0
-
方案2(弃)
参照上面的故障恢复,但是会清除之前复制到master里的 recovery_1st_stage 和 pgpool_remote_start 文件。同时从节点中另一个没有升级为主节点的数据会被清除,$PGDATA目录消失。
[server1 server3]# rm -rf /var/lib/pgsql/13/data [server1 server3]# sudo -u postgres /usr/pgsql-13/bin/pg_basebackup -h server1 -U postgres -p 5432 -D /var/lib/pgsql/13/data -Fp -Xs -P -R [server1 server3]# systemctl start postgresql-13 [server1 server3]# sudo -u postgres /usr/pgsql-13/bin/psql -c "select pg_is_in_recovery()" # 重启所有pgpool,解决状态不更新的问题 [all servers]# systemctl restart pgpool
常见错误与处理
集群状态不更新
在测试过程中,stop server1的pg后,迁移至server2,但server3显示status为down,修复后server1和server3的status仍为down。
原因
集群状态是用pgpool_stauts文件来判断的,此文件在pg重启后未更新。
解决
-
logdir = /tmp
重启pgpool,/tmp/pgpool_status文件会被自动清除。
[all servers]# systemctl restart pgpool -
lodir != /tmp
文件不会自动清除,需手动删除。
# 停止所有pgpool,删除状态文件,重启所有pgpool [all servers]# systemctl stop pgpool [all servers]# rm -f /${logdir}/pgpool_status [all servers]# systemctl start pgpool
show pgpool_status 时replication_state为空
见关于主从模式
















 3553
3553











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











