







很早之前学习的决策树写一下,作为学习记录。
决策树
决策树学习是应用最广的归纳推理算法之一。 用逼近离散值函数的方法,对有噪声的数据处理,健壮性好,并且能够学习析取表达式。
决策树的学习算法很多,包括ID3, ASSISTANT, C4.5 这些。
学习到的决策树可以表示为多个if-then的规则。
决策树的适应问题
- 实例是由『属性-值』对表示的,例如:( Temperature -> Hot ) 这样的。
- 目标函数具有离散的输出值, 例如一个实例有bool分类为( yes , no ),这样就很容易扩展为两个以上的输出值函数。
- 可能需要析取的描述,这个就是说,决策树代表的析取表达式。
- 训练数据可以包含错误,因为决策树对错误数据的健壮性很好,所以容错率高。
ID3算法
ID3 ( Examples, Target_attribute, Attributes )
Examples 是训练样集。Target_attribute是这棵树要预测的目标属性。Attributes是除目标属性外功学习到的句册数测试的属性列表。
- 创建树的Root节点
- 如果Examples都为正,那么返回label = + 的单节点树Root
- 如果Examples都为反,那么返回label = - 的单节点树Root
- 如果Attributes为空,那么返回单节点树Root, label = Examples 中最普遍的Target_attribute值。
5.否则开始:
5.1 A<- Attributes 中分类Examples能力最好的属性
5.2 Root决策属性 <- A
5.3 对于A的每个可能的值V_i
5.3.1 在Root下加一个新的分支对应测试A = V_i
5.3.2 令Examples(V_i)为Examples中满足A属性值为V_i的子集
5.3.3 如果Examples(V_i)为空
5.3.3.1 在这个新分支下加一个叶子节点,节点的label = Examples中最普遍的Target_attribute值
5.3.3.2 否则在这个新分支下加一个子树ID3 ( Examples(V_i), Target_attribute, Attributes-{A} )- 结束
- 返回root
这里最重要的是找到:最高信息增益 ( information gain ) 的属性是最好的属性
用熵来衡量
为了精确定义上面说的信息增益,这里使用熵来衡量信息增益的程度:
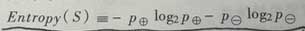
其中P+是S中的正例占的比例,P-是S中的反例占的比例。Entropy是表示熵。其中 0log0 = 0.
假设Entropy([9 +, 5 -]) = -(9/14)log(9/14) - (5/14)log(5/15) = 0.940
这是bool型的熵函数,假如更一般的情况,S有c个状态。熵定义为:
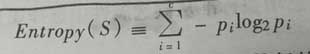
这里P_i代表状态为i所占的比例。
我自己的理解是:ID3算法就是用来构造整个决策树,来决定每个属性所在决策树的位置。
优势和不足
- ID3算法中的假设空间包含所有的决策树,关于现有属性的有限离散值函数的一个完整空间。
- 当遍历决策树空间时,ID3仅仅维护单一的当前假设。例如:它不能判断有多少个其他的决策树也是与现有的训练数据一致的。
- 基本的ID3算法在搜索中不进行回溯。就是说假如在某一个层次选择了一个属性,那么就不会再回溯重新考虑这个选择了。
- ID3算法在搜索的每一步都使用当前的所有训练样例,以统计为基础决定怎样精化当前的假设。
决策树学习的归纳偏置
我的理解就是:1. 选择较短的树。 2. 选择信息增益高的属性,让它离根节点更近的树。
其实就是从一个空的树,进行广度优先遍历搜索,考虑所有深度为1的,然后2的。。。
决策树学习方法的问题
其实在决策树学习的这个算法中,实际问题有很多的,例如:
- 确定决策树的增长的深度;
- 处理连续值的属性;
- 选择一个适当的属性筛选度量标准;
- 处理属性值不完整的训练数据;
- 处理不同代价的属性;
- 提高计算效率;
避免过度拟合数据
这里有个问题,就是我们训练数据的策略并不是一定能行得通的!就是说数据中有噪声或者数量不太多的情况,不能产生目标函数有代表性的采样,那么这个策略就很麻烦了。这种情况有有可能过度拟合。
就是说在假设空间里h的错误率小于H的,但是在整个实例上,H错误率更小,那么就是过度拟合了。
机器学习书上的定义:
给定一个假设空间H,一个假设h 属于 H,如果存在其他假设h’ 属于H, 使得训练样例上h 的错误率小于h’,但是在整个实例的分布上h’的错误率小于h,那么就是假设h过度拟合训练数据了。
原因比较多啊,就是有可能是有噪声(没噪声的数据太少了…)还有就是有可能数据里有错误数据啊,或者数据少没法完全代表整个实例。就像抛硬币一样,抛10次 100次 1000次 10万次的数据分布的代表性是不一样的。
那么如何避免呢?
- 早点停止树的增长,就是在完美分类数据之前就停止树的增长。
- 后修剪法,就是把树后面的数据修剪掉。
这里面涉及到一个问题!那就是度的问题,什么时候停止,修剪掉多少。
- 使用训练样例不同的分离阳历,评估通过上面两个方法的效用。类似评估函数。
- 使用所有可用数据训练。
- 或者订一个明确的标准衡量复杂度。
方法比较麻烦~~有时间再写吧。
结语
为什么我先写决策树呢,因为这个是用的比较多的,而且难度不大~~ 多交流















 3992
3992

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









