







仿真+AI ?
企业的仿真工程师大部分时间都是在面对相似的模型。例如空调管路CFD,汽车保险杠CAE的仿真工作,通过DOE设计迭代,不断的优化尺寸参数,产品外形,从而使得管路流动阻力减小,风速均匀性提高,或者结构的轻量化、安全性和耐久性的提高。
通常项目完成后,计算服务器上的大量结果文件会被删除,即使做了备份,也很少有机会被再次利用。而每次来了一个新项目,仿真工程师从几何清理,网格划分,求解分析这个流程又会做一遍。
有没有可能,当设计部门给出一个新的设计,仿真工程师立刻预测结果?
physicsAI利用仿真的历史数据作为机器学习的训练样本,每当输入新的CAD数据或面网格,快速预测出压力、温度、应力、变形等场值结果。
physicsAI 的价值
-
基于几何深度学习,无需手工参数化。(许多CAE模型参数化很困难,而且手工制作的参数集可能不是最佳的)。
-
无需用户编程或编辑脚本。
-
可以在面网格或 CAD 上直接预测,省略了复杂的建模流程。
-
比仿真求解器快得多的预测速度,并支持设计探索。
-
可以基于任意物理场的仿真预测(结构、流体、电磁等)。
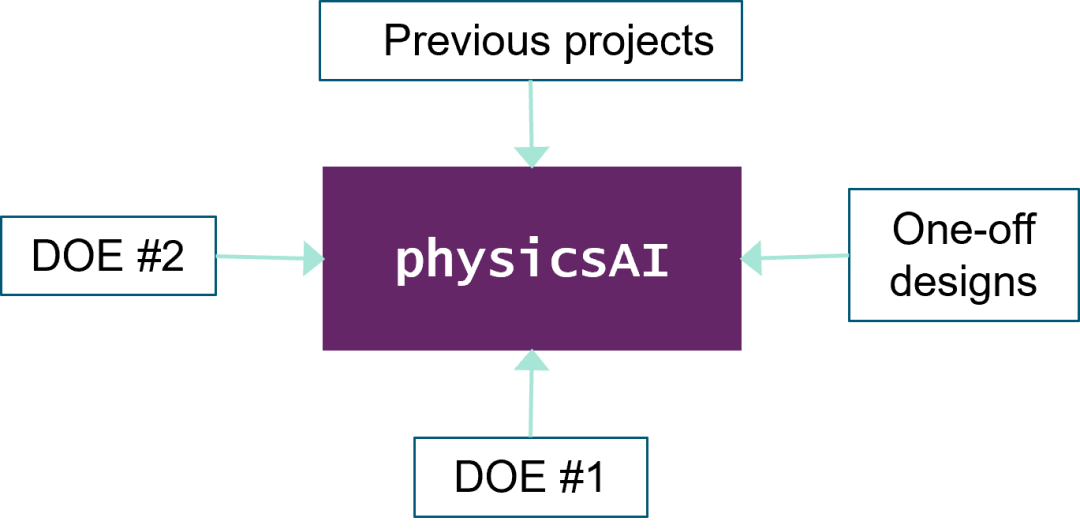
physicsAI 的使用
-
安装HyperWorks Desktop v2023 版本。
-
支持Nvidia GPU训练,至少8G以上的显存。
-
训练时间和样本的数量以及每个样本的网格数量有关,小模型训练半小时,大的模型可能超过一天。
-
支持本地或远程HPC训练样本。
-
训练样本需要.h3d .fem .rad仿真结果格式, 预测可以用 parasolid 或面网格。

接下来通过一个空调管路的模型演示如何使用physicsAI,基本操作共分为 4 步:
-
创建数据集
-
模型训练
-
模型测试
-
模型预测
最后,求解器验证步骤是可选的。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 647
647

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









