







 本文详细介绍了numpy库中的np.newaxis用法,展示了如何通过增加轴来改变数组形状。接着,讨论了np.argsort()函数在排序数组中的应用。此外,通过实例演示了如何绘制正态分布图,包括fit、norm、hist、kde等参数的使用。最后,提到了pandas的get_dummies()函数在处理离散特征时的one-hot编码过程,用于将分类数据转化为数值型数据。
本文详细介绍了numpy库中的np.newaxis用法,展示了如何通过增加轴来改变数组形状。接着,讨论了np.argsort()函数在排序数组中的应用。此外,通过实例演示了如何绘制正态分布图,包括fit、norm、hist、kde等参数的使用。最后,提到了pandas的get_dummies()函数在处理离散特征时的one-hot编码过程,用于将分类数据转化为数值型数据。
文章目录
一、np.newaxis的用法
np.newaxis的作用就是在这一位置增加一个一维,这一位置指的是np.newaxis所在的位置,比较抽象。我们举一个例子:
array=np.random.rand(3,4)
array输出为:
array([[0.8673345 , 0.87058519, 0.20251628, 0.72928923],
[0.4078268 , 0.6191882 , 0.97035328, 0.82620661],
[0.42866612, 0.22471408, 0.96583487, 0.0179457 ]])
对其进行增加维度操作:
array_axis=array[:,np.newaxis]
array_axis输出为:
array([[[0.8673345 , 0.87058519, 0.20251628, 0.72928923]],
[[0.4078268 , 0.6191882 , 0.97035328, 0.82620661]],
[[0.42866612, 0.22471408, 0.96583487, 0.0179457 ]]])
二、np.argsort的用法
功能: 将矩阵a按照axis排序,并返回排序后的下标
参数: a:输入矩阵, axis:需要排序的维度
返回值: 输出排序后的下标
import numpy as np
x = np.array([3,2,5,-1,0,-2])
x.argsort()
输出:
array([5, 3, 4, 1, 0, 2], dtype=int64)
三、正态分布图的使用
我们假设有10个随机数
x=np.random.randn(100)
x输出:
array([-2.19357637, 1.03864796, -0.95104507, -0.1690344 , 0.29648262,
-0.7640752 , 0.15905589, 2.07249912, 0.70312816, 0.80070306,
1.29612653, -2.63874574, -0.26189042, 2.12564216, 0.56861835,
-0.18943274, -0.75601323, 1.38344496, -0.50702103, -0.22910088,
0.20479167, -0.61120173, -0.20090225, 1.43568298, 2.61950641,
0.09446892, -0.07709098, 0.2491735 , -0.80481997, 0.58523034,
1.16017998, 0.4407353 , -0.71009153, 0.55810077, 0.05271944,
0.43614988, -1.21586415, -1.17084382, -0.58393395, 0.55245063,
0.56418961, 0.57940085, 0.40388583, 0.34791926, -0.27173782,
0.59384357, 0.77583612, 1.79353976, 0.0375357 , -1.16605167,
1.13151166, -0.09720373, -1.24091957, -0.93924176, -0.30345863,
0.69050871, -1.46066651, -1.49576727, 0.14752057, 1.65639365,
-0.49901977, -2.7017122 , 0.65861852, -0.58167033, 0.07877699,
1.41603824, 1.68265432, -0.48303618, -0.63860605, 0.56478839,
-1.1148248 , -0.17799165, -2.0899294 , 1.03159286, -0.25805355,
1.53186054, 0.4414223 , -0.86584869, -0.18172099, -0.59000996,
1.02228194, -0.67097503, -0.738751 , -0.69504748, 0.19968444,
-0.1421462 , -0.1564683 , -0.25207852, -0.14746825, -0.11764128,
0.50018846, -0.55975806, 1.31112595, 1.03395372, 0.82508084,
1.44772972, 1.25995543, 0.99525077, 0.00513235, 0.24114059])先简单处理一下
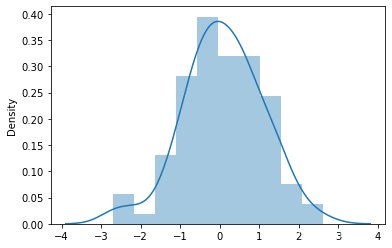
sns.distplot(x)输出为:
我们对参数进行调节,首先是fit:
#fit:控制拟合的参数分布图形,能够直观地评估它与观察数据的对应关系(黑色线条为确定的分布)
from scipy.stats import *
sns.distplot(x,hist=False,fit=norm) #拟合标准正态分布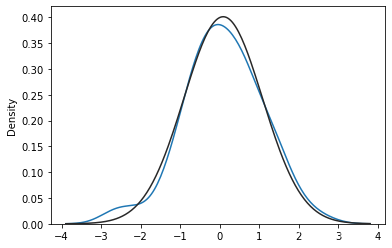
对比参数:
#通过hidt和kde参数调节是否显示直方图和核密度估计((默认hist,kde均为True)
fig,axes = plt.subplots(1,3) # 创建一个1行3列的图片
sns.distplot(x,ax=axes[0]) # ax=axex[0]表示该图片在整个画板中的位置
sns.distplot(x,hist=False,ax=axes[1]) #不显示直方图
sns.distplot(x,kde=False,ax=axes[2]) #不显示核密度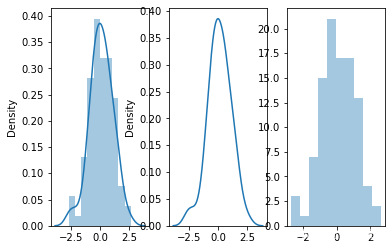
接下来进行对比,更加直观看出预测的变化趋势,检测是正态分布。
from scipy import stats
res = stats.probplot(x, plot=plt)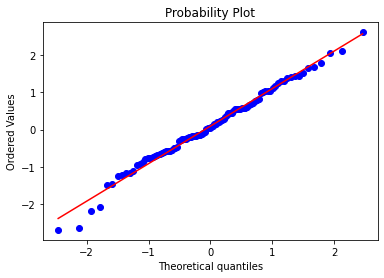
红色线条表示正态分布,蓝色线条表示样本数据,蓝色越接近红色参考线,说明越符合预期分布(这是是正态分布)
四、get_dummies ()用法
将离散型特征的每一种取值都看成一种状态,若你的这一特征中有N个不相同的取值,那么我们就可以将该特征抽象成N种不同的状态,one-hot编码保证了每一个取值只会使得一种状态处于“激活态”,也就是说这N种状态中只有一个状态位值为1,其他状态位都是0。
例子:
import pandas as pd
df = pd.DataFrame([
['1' , 'A'],
['2' , 'B'],
['3' , 'A']])
df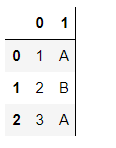
当我们进行get_dummies()操作后:
import pandas as pd
df = pd.DataFrame([
['1' , 'A'],
['2' , 'B'],
['3' , 'A']])
df.columns = ['num', 'class']
pd.get_dummies(df) 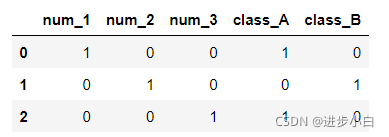



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











