







目录
爬虫一定要用Python么?
用Java也行,C也可以.编程语言只是工具.抓到数据是目的.
用什么工具去达到你的目的都是可以的.和吃饭一样,可以用叉子也可以用筷子,最终的结果都是你能吃到饭.那为什么大多数人喜欢用Python呢?答案:因为Python写爬虫简单.不理解?问:为什么吃米饭不用刀叉?用筷子?因为简单!好用!
而Python是众多编程语言中,小白上手最快,语法最简单.更重要的是,有非常多的关于爬虫能用到的第三方支持库.
爬虫的矛与盾
反爬机制
门户网站。可以通过制定相应的策略或者技术手段,防止爬虫程序进行网站数据的爬取。
反反爬策略
爬虫程序可以通过制定相关的策略或者技术手段,破解门户网站中具备的反爬机制,从而可以获取门户网站中相关的数据。
软件:
jupyter notebook
python3.8
pycharm
安装python注意配置环境变量:
Python环境变量的配置 - 知乎 (zhihu.com)![]() https://zhuanlan.zhihu.com/p/108436994可以参考如上
https://zhuanlan.zhihu.com/p/108436994可以参考如上
在cmd上输入python
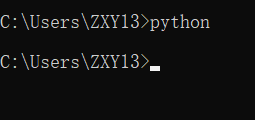
如果弹到商店页面:
在路径上将python路径调至第一位即可。
入门小案例:
展示百度页面:
from urllib.request import urlopen
url = "http://www.baidu.com"
resp = urlopen(url)
# print(resp.read().decode("utf-8"))#转换为解码
with open("mybaidu.html", mode="w") as f:
f.write(resp.read().decode("utf-8"))
print("over!")生成的文件可以在浏览器打开,即就是百度的页面。















 5237
5237











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











