







一、安装Node.js
1. 关于npm
npm的全称是: Node Package Manager,可译为"Node包管理器"。
在早期没有npm时,如果需要在前端工程中使用某些框架(例如jQuery,Bootstrap等) ,需要找到相关的官网或资源站点,要么下载这些框架的文件,要么使用cdn在线引用这些文件,其过程相对烦琐,因为这些框架的具体表现可能不只是一个文件,如果下载,只能下载打包后的文件并自行解压缩,如果
在线引用,则需要自行添加多条源代码进行引用,同时,是这些框架也是在不停维护和更新的,即使开发人员在本地已经下载过这些框架文件,当需要新版本的框架时,又需要重新下载,或者上网搜索最新的cdn引用地址。
2. 安装
为了使用npm,首先需要下载Node.js安装包,下载地址可参考:
https://nodejs.org/dist/v16.14.2/node-v16.14.2-x64.msi
https://mirrors.njuedu.cn/nodejs/latest-V1 6.x/node-V16.14.2-x64.msi
https://mirrors.huna.tsinghua.edu.cn/nodejs-release/16.14.2/node-v16.14.2-x64.msi
Node.js的安装过程没有特别的注意事项,整个过程中都可以不必修改任何内容, 直至其自动安装完成。
安装完成后使用npm -v命令显示版本号。
3. 配置npm源
nmp源(即npm仓库,称之为: registry) 默认是境外服务器,在国内使用时,访问速度较慢,通常,在初次使用时,应该将npm源更换为国内的服务器地址,例如使用https://registry.npmmirror.com作为npm源。
3.1 配置npm源的命令如下:
npm config set registry https://registry.npmmirror.com
3.2 当配置成功后,可通过get命令可查看npm源:
npm config get registry
将显示当前生效的npm源(并不检查npm源的URL是否有效,所以,即使配置了错误的npm源,也不影响此步操作)。
注意:无论你使用哪种操作系统,必须保证当前登录的用户具有最高访问权限,例如,在Windows操作系统中,请使用管理员摸式的命令提示符.
4. 关于npm源的更新
原淘宝npm域名即将停止解析,正如在《淘宝NPM镜像站喊你切换新域名啦》中预告的那样: http://npm.taobao.org和http://registry.npm.taobao.org将在2022.06.30号正式下线和停止DNS解析。域名切换规则:
http://npm.taobao.org => http://npmmirror.com
http://registry.npm.taobao.org => http://registry.npmmirror.com
二、创建前端项目
1. 如何创建项目
1.1 安装vue脚手架客户端
Vue CLI是Vue框架的客户端工具,创建Vue项目、运行Vue项目都需要事先安装此工具。
npm install -g @vue/cli
以上命令执行完后,只要没有提示错误(Err或Error字样) ,即可视为成功!
当Vue CLI安装完成后,可以通过以下命令查看版本号并检查是否安装成功:
vue -V
1.2 创建项目
在命令提示符窗口中,执行vue create 项目名称的命令,就可以创建项目,创建出来的项目会在命令提示符窗口中提示的位置(即: 敲命令时左侧提示的位置)。
例如:创建demo-01项目:
vue create demo-01
选择创建选项如下:
Manually select features
Babel / Vuex / Router
2.x
直接回车
In package.json
直接回车
1.3 启动项目命令
当创建完成后,可以使用Intellij IDEA打开此项目,并且在Intellij IDEA的Terminal (终端)面板中,可以执行启动项目的命令:
npm run serve
2. 关于Vue脚手架项目
Vue脚手架项目是一个单页面的应用,即整个项目中只有1个htmI页面,它认为这个页面是由若干个视图组合而成的,每个视图都只是该页面中的一个部分,并且都是可以被替换的。
项目的文件夹结构:
[.idea]: 仅当使用Intellij IDEA打开此项目后,才会有这个文件夹,是Intellij IDEA管理项目时使用的,无需关注此文件
[node_modules]: 此项目中使用的各个库的文件,注意:通常,提交到GIT的项目代码中并不包含此文件夹,需要先执行npm install命令,则会自动下载此项目中的各个库的文件,然后才可以运行项目。
[public]: 此项目的静态资源文件夹,通常用于存放图片、自行编写的js、自行编写的css等文件, 此文件夹下的资源的访问路径都是根路径.
public/favicon.ico:此项目的图标文件,此文件必须在这个位置,且必须是这个文件名
public/index.html :此项目中唯一的html文件, 也是项目打开页面的入口.
[src]:源文件的文件夹
[src/assets]: 资源文件夹,此处的资源文件应该是不随程序运行而发生变化的
[src/components] :视图组件文件夹,此文件夹下的视图组件通常是被视为封装的视图,且将会被其它视图调用.
[src/router] :此项目中配置路由的文件所在的文件夹
src/router/index.js:默认的路由配置文件
[src/stroe] :此项目的配置全局共享变量的文件所在的文件夹
src/store/index.js:默认的配置全局共享变量的文件,此处声明的变量,在任何一个视图组件中均可使用
[views]: 一般的视图组件所在的文件夹
src/App.vue:默认绑定到index.html中的<div id="app"></div>的视图组件,可简单理解为页面的入口,此视图组件不需要配置路由,默认就会显示
src/main.js :此项目的主配置文件,通常,在项目中安装了软件之后,都需要在此文件中补充配置
.gitignore:使用GIT时的忽略文件清单,即:用于配置哪些文件不会提交到Git
package.json:项目的配置文件,例如配置了此项目的依赖项等
package-lock.json:锁定的配置文件,不需要,也不建议手动修改此文件中的任何内容
3. 关于视图组件
在Vue脚手架项目中,以.vue为作文件名后缀的,就是视图组件。
在视图组件中,源代码主要有3个部分:
3.1 <template>
设计界面的源代码部分,此标签下可以使用HTML或相关技术(例如Element UI)来设计界面。
注意:在<template>标签下,只能有1个直接子标签。
3.2 <script>
编写JavaScript代码。
3.3 <sty1e>
编写CSS代码。
在设计界面时,可以使用<router-view/>表示此视图组件不确定的内容!例如在App. vue中就使用了这个标签,此标签将显示的内容取决于URL (地址栏中的网址)。
4. 路由
在Vue脚手架项目中,使用“路由”来配置URL与视图组件的对应关系。通过src/router/index.js可以配置路由。
核心代码:
import HomeView from '../views/HomeView.vue'
const routes = [
{
path: '/',
name: 'home',
component: HomeView
},
{
path: '/about',
component: () => import('../views/AboutView.vue')
}
]
以上配置中,path 表示路径,name 表示名称,可以不必配置,component 表示视图组件。
关于component的值,可以使用静态导入的方式来确定,例如HomeView, 也可以使用import()函数导入,例如以上关于/about的配置。
通常,在每个项目中,只有1个视图组件是静态导入的。
5. 安装Element UI
在终端中执行以下命令安装Element UI:
npm i element-ui -S
安装完成后,需要在src/main.js中添加配置:
import ElementUI from 'element-ui';
import 'element-ui/lib/theme-chalk/index.css';
Vue.use(ElementUI);
至此,在项目中的任何一个视图组件中都可以直接使用Element UI, 不需要额外的声明或引用。
6. 安装axios
在终端执行安装axios的命令:
npm i axios -S
安装完成后,在main.js中添加配置:
import axios from 'axios';
Vue.prototype.axios = axios;
在Vue CLI项目中,使用axios时,在then()的回调内部,不可以使用匿名函数,必须使用箭头函数,例如:
this.axios.post(url,data).then((response) => {
});
7. 关于跨域问题
默认情况下,不允许向别的服务提交异步请求,例如,在http://localhost:9000服务上,向http://localhost:8080提交异步请求,这是不允许的.
在基于Spring Boo的项目中,要允许跨域访问,可以在启动类上实现WebMvcConfigurer接口,并重写addCorsMappings()方法:
@ServletComponentscan
@SpringBootAppication
public class CoolsharkApplication implements WebMvcConfigurer {
public static void main(string[] args) {
SpringApplication.run(CoolsharkApplication.class,args);
}
@override
public void addCorsMappings (CorsRegistry registry) {
registry.addMapping( pathPattern:"/**")
.allowCredentials(true)
.allowedHeaders("*")
.allowedMethods("*")
.allowed0riginPatterns("*")
.maxAge(3600);
}
}
8. 嵌套路由
当某个显示在<router-view/>位置的视图组件中也设计了<router-view/>,则出现了<router-view/>的嵌
套,在配置路由时,需要使用嵌套路由。
在配置router/index. js中的routes数组时,数组元素即是一个个的路由对象,这些路由对象都是应用于App.vue中的<router-view/>的,如果需要某个视图显示在另一个视图的<router-view/>中(例如添加相册的视图组件需要显示到Homeview的<router-view/>中),需在Homeview的路由对象中配children属性。这个children属性的配置方法与routes完全相同。
9. 前端页面方法
推荐mounted
methods: {
LoadALbumList() {
console.Log('loadALbumList ...');
}
},
mounted() {
console.LogC'mounted ...');
this.LoadALbumList();
},
created() {
console.logC'created ...');
}
</script>
三、创建后端项目
1. 创建项目,连接database
2. 实现数据库编程
Java语言是通过IDBC技术实现数据库编程的,但是, JDBC技术的应用相对比较繁琐,且编码步骤相对固定,所以,通常使用框架技术来实现,这些框架技术大多可以简化IDBC编程,使得实现数据库编程的代码更加简洁。
常见的数据库编程框架有: Mybatig、 Spring Data JPA、Hibernate等。
3. 使用Mybatis框架
<!-- Mybatis 整合Spring Boot的依赖项-->
<dependency>
<groupId>org.mybatis.spring.boot</groupId>
<artifactId>mybatis-spring-boot-starter</artifactId>
<version>2.2.2</version>
</dependency>
<!-- MySQL 的依赖项可能报错-->
<dependency>
<groupId>mysql</groupId>
<artifactId>mysqL-connector-java</artifactId>
<scope>runtime</scope>
</dependency>
<!-- MySQL 的依赖项-->
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<version>8.0.22</version>
</dependency>
在Spring Boot项目中,在src/main/resources下默认已经存在applicati on.properties配置文件,SpringBoot项目在启动时会自动读取此文件中的配置信息,如果配置信息中的属性名是特定的,Spring Boot还会自动应用这些属性值。
4. SQL语句
批量插入数据的SQL语句大致是:
INSERT INTO table (name,description,sort,gmt_create,gmt_modified) VALUES
('华为Mate50的相册','暂无',200,nu11,nu11),
('华为Mate50的相册','暂无',200,nu11,nu11),
('华为Mate50的相册','暂无',200,nu11,nu11);
批量删除数据的SQL语句大致是:
DELETE FROM table WHERE id=1 OR id=3 OR id=5;
DELETE FROM table WHERE id IN (1,3,5);
更新数据的SQL语句大致是: .
UPDATE table SET name='新的名称',description='简介' WHERE id=1;
count(*)必须使用星号。
统计查询的SQL语句大致是(例如:查询表中的数据的数量) :
SELECT count(*) FROM table;
在表查询中,一律不要使用 ‘*’ 作为查询的字段列表,需要哪些字段必须明确写明。
根据id查询数据详情的SQL语句大致是:
SELECT id,name FROM table WHERE id=1;
查询(所有)数据的列表的SQL语句大致是:
SELECT id,name,description,sort,gmt_craete,gmt_ modified
FROM table
ORDER BY id;
5. 关于实体类
5.1 概念
实体类是POJO的其中一种。
POJO: Plain Ordinary Java Object,简单的java对象。
在项目中,如果某个类的作用就是声明若干个属性,并且添加Setter & Getter方法等,并不编写其它的功能性代码,这样的类都称之POJO,用于表示项目中需要处理的数据。
5.2 关于POJO类, 其编写规范是:
5.2.1 所有属性都应该是私有的
5.2.2 所有属性都应该有对应的、规范名称的Setter、 Getter方法
5.2.3 必须重写equals()和hashcode(),并保证:
- 如果两个对象的各属性值完全相同,则equals()对比结果为true,且hashCode ()值相同
- 如果两个对象存在属性值不同的,则equals()对比结果为false,且hashCode ()值不同
- 如果两个对象的hashcode()相同,则equals ()对比结果必须为true
- 如果两个对象的hashcode()不同,则equals ()对比结果必须为false
5.2.4 必须实现Serializable接口
5.2.5 建议重写toString()方法
5.3 在数据表中的常见的字段类型与Java中的属性的数据类型的对应关系是:

5.4 lombok
5.4.1 相关信息
在项目中使用Lombok框架,可以实现:添加注解,即可使得Lombok在项目的编译期自动生成一些代码(例如Setter & Getter)。
5.4.2 关于Lombok框架的依赖项:
<!-- Lombok的依赖项,主要用于简化P0J0类的编写 -->
<dependency>
<groupId>org.projectlombok</groupId>
<artifactId>lombok</artifactId>
<version>1.18.20</version>
<scope>provided</scope>
</dependency>
5.4.3 @Data
在POJO类上添加Lombok框架的@Data注解,可以在编译期生成:
- 规范的Setter & Getter
- 规范的hashCode()与equals()
- 包含各属性与值的tostring()
注意:当使用了Lombok后,由于源代码中并没有Setter & Getter方法,所以,当编写代码时,Intellil IDEA不会提示相关方法,并且,即使强行输入调用这些方法的代码,还会报错,但是,并不影响项目的运行!为了解决此问题,需要安装Lombok插件!
6. 通过Mybatis实现数据库编程
6.1 关于Mybatis框架
Mybatis是目前主流的解决数据库编程相关问题的框架,主要是简化了数据库编程。
Mybatis框架的基础依赖项的artifactId是: mybatis。
Mybatis框架虽然可以不依赖于Spring等其它框架,但是,直接使用比较麻烦,需要自行编写大量的配置,所以,通常结合Spring起使用,需要添加的依赖项的artifactId是: mybatis-spring
在Spring Boot项目中,直接添加mybatis-spring-boot-starter将包含以上依赖项,和其它必要的、常用的依赖项。
Mybatis框架简化数据库编程的表现为:你只需要定义访问数据的抽象方法,并配置此抽象方法映射的SQL语句即可!
6.2 关于抽象方法
6.2.1 相关信息
使用Mybatis框架时,访问数据的抽象方法必须定义在接口中!因为Mybatis框架是通过"接口代理”的设计模式,生成了接口的实现对象!
关于Mybatis的抽象方法所在的接口,通常使用Mapper作为名称的最后一个单词!
则可以在项目的根包下创建mapper.UserMapper接口,例如:
public interface UserMapper {
}
6.2.2 关于抽象方法
- 返回值类型:如果要执行的SQL操作是增、删、改类型的,使用int作为返回值类型,表示"受影响的行数”,不建议使用void
- 方法名称:自定义的,但推荐遵循规范
- 参数列表:取决于需要执行的SQL语句需要哪些参数,在抽象方法中,可以将这些参数一一列举出来,也可以将这些参数封装到自定义类中,使用自定义类作为抽象方法的参数
- 抛出异常:无
6.2.3 关于抽象方法命名参考 :
- 获取单个对象的方法用get做前缀
- 获取多个对象的方法用list做前缀
- 获取统计值的方法用count做前缀
- 插入的方法用save / insert做前缀
- 删除的方法用remove / delete做前缀
- 修改的方法用update做前缀
6.3 (mapper)使得Mybatis框架能明确这个接口是数据访问接口:
6.3.1 在接口上添加@Mapper注解。每个数据访问接口上都需要此注解(不推荐)
6.3.2 在配置类上添加@Mapperscan注解,并配置数据访问接口所在的包(推荐)
- 在根包(含子孙包) 下的任何添加了@Configuration注解的类都是配置类。
- 只需要一次配置,各数据访问接口不必添加@Mapper注解。
即在根包下创建config.MybatisConfiguration类,配置@Mapperscan :
@Configuration
@MapperScan("com.luck.demo01back.mapper")
public class MabatisConfiguration {
}
6.4 关于配置SQL语句
6.4.1 直接使用注解
在Spring Boot中,整合了Mybatis框架后,可以在数据访问接口的抽象方法上使用@Insert等注解来配置SQL语句,这种做法是不推荐的!
在不是Spring Boot项目中,需要额外的配置,否则,将不识别抽象方法上的@Insert注解。
不推荐使用@Insert等注解配置SQL语句的主要原因有:
- 长篇的SQL语句不易于阅读
- 不便于实现特殊的配置
- 部分配置不易复用
- 不便于实现与DBA(Database Administrator)协作
6.4.2 XML文件
6.4.2.1 下载
建议使用XML文件来配置SQL语句,这类XML文件需要有固定的、特殊的声明部分,推荐通过复制粘贴得到此文件,或从http://doc.canglaoshi.org/config/Mapper.xml.zip下载得到。
6.4.2.2 使用
在srq/main/resources下创建mapper文件夹,并将以上压缩包中的SomeMapper. xml复制到此mapper文件夹中。
6.4.2.3 关于XML文件的配置:
-
根标签必须是
<mapper> -
在
<mapper>标签上必须配置namespace属性,此属性的值是接口的全限定名(包名与类名) -
在
<mapper>标签内部,使用<insert> / <delete> /<update> /<select>标签来配置增/删/改/查的SQL语句。 -
各配置SQL语句的标签必须配置id属性,取值为对应的抽象方法的名称
-
各配置SQL语句的标签内部是配置SQL语句的
SQL语句不需要使用分号表示结束
内部不可以随意添加注释 -
在配置
<select>标签时,必须配置resultType或resultMap这2个属性中的其中1个。
6.4.2.4 在application. properties中配置XML文件所在的位置:
#配置Mybatis的XML文件的位置
mybatis.mapper-locations=classpath:mapper/*.xml
6.4.2.5 常见错误
- 如果此前没有正确的配置’@Mapplerscan ,在执行测试时,将出现以下错误:
Caused by:org.springframework.beans.factory.NoSuchBeanDefinitionException:No qualifying bean of type '... mapper.XXMapper' available:expected at least 1 bean which qualifies as autowi re candi date. Dependency annotations:{@org. springframework.beans.factory.annotation.Autowi red(requi red=true)}
- 如果出现以下原因的操作错误:
在XML文件中,根标签<mapper>的namespace属性值配置有误
在XML文件中,配置SQL语句的<insert>或类似标签的id属性值配置有误
在application. properties配置文件中,没有正确的配置XML文件的位置,将出现以下错误:
org.apache.ibatis.binding.BindingException:Invalid bound statement(not found):cn.tedu.csma11.product . mapper.ATbumMapper.insert
6.5 插入
插入数据时获取自动编号的id值
在XML文件中,在<insert>标签上配置useGeneratedKeys="true"和keyProperty="属性名"这2个属性,就可获取插入的新数据的自动编号的主键值.
当成功插入数据后,Mybatis会自动获取自动编号的主键值,并封装到参数对象的id属性(由keyProperty指定)中。
6.6 查询
6.6.1 实体类封装查询结果可能存在问题
- 由于查询时,并不会查询全部字段的值,所以,实体类中的某些属性值会是null,当方法的调用者得到结果对象,对于为null的值,无法区分到底是"没有查询此字段的值"还是"查询了此字段,但是确实没有值”
- 在关联查询时,没有任何实体类可以封装多表查询结果
所以,会另外创建POJO类来封装查询结果。
6.6.2 关于POJO类的名称参考建议
数据对象: xxxDO, xXX即为数据表名
数据传输对象: xxxDTO, xxx 为业务领域相关的名称
展示对象: xxxVO, xxx一般为网页名称
POJO是DO/DTO/BO/VO的统称,禁止命名xxxPOJO
6.6.3 关于常见后缀:
DO: Data Object,即”数据对象”
DTO: Data Transfer Object, 即"数据传输对象”
VO: View Object, 即"视图对象”,或: Value Object, 即“值对象"
6.6.4 统计
抽象方法count命名
SELECT count(*) FROM table
6.6.5 根据id查询
抽象方法get命名,eg:getById(Long id)
SELECT 字段列表 FROM table WHERE id=?
当Mybatis处理查询的结果集时,会自动将列名(Column) 与属性名(Property) 相同的数据进行封装,例如,将查询结果集中名为name的数据封装到对象的name属性中,并且,默认情况下,对于列名与属性名不同的数据,不予处理!
提示:查询结果集中的列名(Column) 默认是字段名(Field) ,而字段名是设计数据表时指定的。
在XML文件中,可以配置<resultMap>标签,此标签的作用就是:指导Mybatis将查询结果集中的数据封装到对象中。
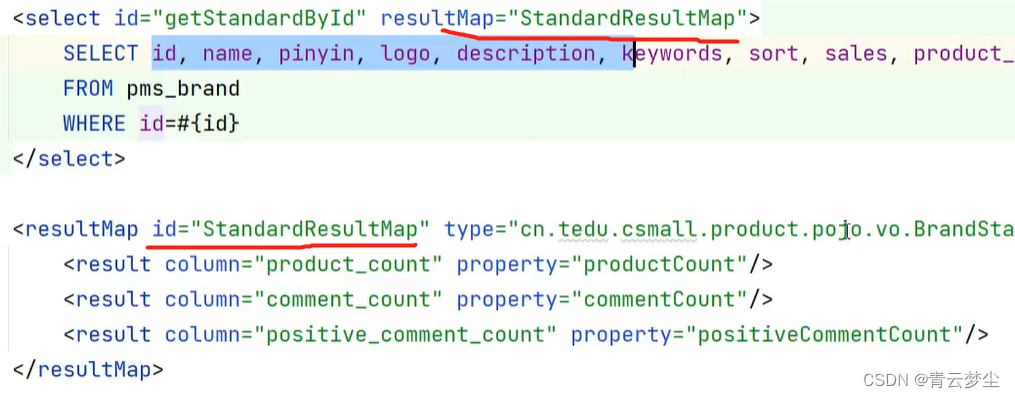

在许多数据的查询功能中,查询详情(标准信息)和查询列表时,需要查询的字段列表很可能是不同的,所以,应该使用不同的VO类(为了避免后续维护添加字段导致的调整,即使当前查询详情和查询列表的字段完全相同,也应该使用不同的VO类) !
6.7 动态SQL
Mybatis的动态SQL机制表现为:根据参数的不同,生成不同的SQL语句。
6.7.1 <foreach>
- 例如批量删除
//可以是
int deleteByIds(List<Long> ids);
//也可以是:
int deleteByIds(Long[] ids);
//还可以是可变参数,本质仍然是一个数组
int deleteByIds(Long... ids);
xml中配置SQL语句:
<!-- int deleteByIds(Long[] ids); -->
<delete id="deleteByIds">
DELETE FROM table WHERE id IN (
<foreach collection="array" item="id" separator=",">
#{id}
</foreach>
)
</delete>
2 . 关于<foreach>标签的属性配置:
collection: 表示被遍历的参数列表,如果抽象方法的参数只有1个,当参数类型是List集合类型时,当前属性取值为list,当参数类型是数组类型时,当前属性取值为array
item:用于指定遍历到的各元素的变量名,并且,在<foreach>的子级,使用#{}时的名称也是当前属性指定的名称
separator: 用于指定遍历过程中各元素的分隔符(或字符串等)
6.7.2 <if>
更新数据时,不传入值的字段会被修改成null,期望是传入了对应的值,则更新对应字段的值,对于没有传入参数的部分,也不更新表中对应字段的数据。
UPDATE
table
SET
<if test="name != null">
name=#{name},
</if>
<if test="description != null">
description=#{description}
</if>
WHERE
id=#{id}
6.7.3 其他
在Mybatis中,<if> 标签并没有对应的类似ava中的else标签!如果需要实现类似Java中if … else …的效果,可以使用2个条件完全相反的<if>标签。
以上做法的缺点在于:实际上执行了2次条件的判断,在性能略微有浪费。
或者,使用<choose>系列标签,以实现类似if ... else ... 的效果:
<choose>
<when test= "判断条件">
满足条件时的SQL片段
</when>
<otherwise>
不满足条件时的SQL片段
</otherwise>
</choose>
7. 日志
在Spring Boot项目中,spring-boot-starter 依赖项中已经包含日志框架!
在Spring Boot项目中,当添加了Lombok依赖项后,可以在任何类上添加@slf4j注解,则Lombok会在编译期声明一个名为log的日志对象变量,此变量可以调用相关方法来输出日志!
SLF4j的日志的可显示级别,根据信息的重要程度,从不重要到严重依次是:
trace:
debug:
info:一般信息
warn:警告信息
error:错误信息
调用log变量来输出日志时,可以使用以上级别对应的方法,则可以输出对应级别的日志!
在Spring Boot项目中,日志的默认显示级别是info,则默认情况下只会显示info及更加严重的级别日志!
如果需要修改日志的显示级别,需要在application.properties中配置logging. level的属性,例如:
#日志的显示级别
logging.level.com.luck=info
注意:在配置以上属性时,必须在logging.level右侧加.上要配置显示级别的包的名称,此包名就是配置日志显示级别的根包。
8. 配置
8.1 Profile
在配置中,许多配置值会因为当前环境不同,需要配置不同的值,例如,在开发环境中,日志的显示级别可以是trace这种较低级别的,而在测试环境、生产环境(项目部署.上线并运行)中可能需要改为其它值,再例如,连接数据库配置的相关参数,在不同环境中,可能使用不同的值,如果在appli cation.properties中反复修改大量配置值,是非常不方便的!
Spring框架支持Profile配置(个性化配置),Spring Boot简化了Profile配置的使用,它支持使用application-xxx.properties作为配置文件的名称,其中,xxx 部分是完全自定义的名称,你可以针对不同的环境,编写一组配置文件,这些配置文件中配置了相同的属性,但是值不同。
appliation.properties是始终加载的配置
application- xxx.properties是需要通过application.properties中的spring.profiles.active属性
来激活的
application-xxx.properties文件名中的xxx是自定义的名称,也是spring.profiles.active属性的值
需要自行评估哪些配置会因为环境不同而配置不同的值
8.2 关于YAML配置
8.2.1 相关信息
YAML是一种使用. yml作为扩展名的配置文件,这类配置文件在Spring框架中默认是不支持的,需要添加额外的依赖项,在Spring Boot项目中,默认已经集成了相关依赖项,所以,在Spring Boot项目中可以直接使用。
在Spring Boot项目中,可以使用.properties配置,也可以使用.yml配置。
8.2.2 相对.properties配置, YAML 的配置语法为:
- 在.properties 配置中,属性名使用小数点分隔的,改为使用冒号结束,并从下一行开始, 缩进2个空格
- 属性名与属性值之间使用1个冒号和1个空格进行分隔
- 多个不同的配置属性中,如果属性名中有相同的部分,可以不必重复配置,只需要将不同的部分缩进在相同位置即可
- 如果某个属性值是纯数字的, 但需要是字符串类型可以使用一对单引号框住。
例如在.properties中配置为:
spring.datasource.username=root
spring.datasource.password=root
spring:
datasource:
username: root
password: root
注意:每换行后,需要缩进2个空格,在Intellij IDEA中,编写. ym1文件时,Intellij IDEA会自动将按下的TAB键的字符替换为2个空格。
提示:如果.yml文件出现乱码(通常是因为复制粘贴文件导致的) ,则无法解析,项目启动时就会报错,此时,应该保留原代码(将代码复制到别处),删除报错的配置文件,并重新创建新文件,将保留下来的原代码粘贴回新文件即可。
9. 关于业务逻辑(service)
9.1 相关信息
业务逻辑:数据的处理应该有一定的处理流程, 并且,在此流程中,可能需要制定某些规则,如果不符合规则,不应该允许执行相关的数据访问!这套流程及相关逻辑则称之为业务逻辑。
例如:当用户尝试注册时,通常要求用户名(或类似的唯一标签,例如手机号码等)需要是"唯一的", 在执行插入数据(将用户信息插入到数据表中) 之前,应该先检查用户名是否已经被占用。
业务逻辑层的主要价值是设计业务流程及业务逻辑,以保证数据的完整性和安全性。
9.2 步骤
在代码的设计方面,业务逻辑层将使用service作为名称的关键词,并且,应该先自定义业务逻辑层接口,再自定义类实现此接口,实现类的名称应该在接口名称的基础上添加Impl后缀。
-
先在项目的根包下创建service.XxxService接口:
-
在service包下创建impl.XxxServiceImpl类,实现以上接口,并且在类上添加@service注解。
9.3 注意
业务方法的参数应该是自定义的POJO类型
业务方法的名称是自定义的
业务方法的返回值类型,是仅以“成功”为前提来设计的,不考虑失败的情况,因为失败将通过抛出异常来表现。
10. 关于控制器
在编写控制器相关代码之前,需要在项目中添加spring-boot-starter-web依赖项。
spring-boot-starter-web是基于(包含) spring-boot-starter的,所以,添加spring-boot-starter-web后,就不必再显式的添加spring-boot-starter了,则可以将原本的spring-boot-starter改成spring-boot-starter-web即可。
spring-boot-starter-web包含了一个内置的Tomcat, 当启动项目时,会自动将当前项目编译打包并部署到此Tomcat上。
在项目中,控制器表现为各个Controller,是由Spring MVC框架实现的相关数据处理功能,以上添加的spring-boot-starter-web包含了Spring MVC框架的依赖项(spring-webmvc)。
控制器的主要作用是接收请求,并响应结果。
11. 异常
11.1 异常继承结构
在Java语言中,异常的继承结构大致是:
Throwable
-- Error
-- -- outofMemoryError (OOM)
-- Exception
-- -- IOException
-- -- -- FileNotFoundException
-- -- RuntimeException
-- -- -- NullPointerException (NPE)
-- -- -- IllegalArgumentException
-- -- -- ClassNotFoundException
-- -- -- ClassCastException
-- -- -- ArithmetiCException
-- -- -- IndexoutofBoundsException
-- -- -- -- ArrayIndexoutofBoundsException
-- -- -- -- StringIndexoutofBoundsException
如果调用的某个方法抛出了非RuntimeException,则必须在源代码中使用try.. . catch或throws语法,否则,源代码将报错!而RuntimeException不会受到这类语法的约束!
在项目中,如果需要通过抛出异常来表示某种”错误",应该使用自定义的异常类型,否则,可能与框架或其它方法抛出的异常相同,在处理时,会模糊不清(不清楚异常到底是显式的抛出的,还是调用其它方法时由那些方法抛出的) !同时,为了避免抛出异常时有非常多复杂的语法约束,通常,自定义的异常都会是RuntimeException的子孙类异常。
11.2 Spring MVC框架的统一处理异常机制
11.2.1 相关信息
由于Service在处理业务,如果视为”失败",将抛出异常,并且,抛出时还会封装"失败”的描述文本,而Controller每次调用Service的任何方法时,都会使用try…catch进行捕获并处理,并且,处理的代码都是相同的(暂时是return e.getMessage()😉,这样的做法是非常固定的,导致在Controller中存在大量的 try…catch (处理任何请求,调用Service时都是这样的代码)。
Spring MVC提供了统一处理异常的机制, 它可以使得Controller不再处理异常,改为抛出异常,而Spring MVC在调用Controller处理请求时,会捕获Controller抛出的异常并尝试处理。
11.2.2 关于处理异常的方法:
-
访问权限:应该是public
-
返回值类型:参考处理请求的方法
-
方法名称:自定义
-
参数列表:至少需要添加1个异常类型的参数,表示你希望处理的异常,也是Spring MVC框架调用Controller的方法时捕获到的异常
-
注解:
@ExceptionHandler -
如果将处理异常的方法定义在某个Controller中,仅作用于当前Controller中所有处理请求的方法,对别的Controller中处理请求的方法是不生效的! Spring MVC建议将处理异常的代码写在专门的类中,并且,在类上添加@RestcontrollerAdvice注解,当添加此注解后,此类中处理异常的代码将作用于整个项目每次处理请求的过程中。
-
允许存在多个处理异常的方法,只要这些方法处理的异常类型不直接冲突即可
即:不允许2个处理异常的方法都处理同一种异常
即:允许多个处理异常的方法中处理的异常存在继承关系,例如A方法处理NullpointerException, B方法处理RuntimeException
13. 控制器Controller
13.1 相关信息
在Spring MVC框架,使用控制器( Controller) 来接收请求、响应结果。
在根包下的任何一个类,添加了@Controller注解,就会被视为控制器类。
在默认情况下,控制器类中处理请求的方法,响应的结果是”视图组件的名称",即:控制器对请求处理后,将返回视图名称,Spring MVC还会根据视图名称来确定视图组件,并且,由此视图组件来响应!这不是前后端分离的做法。
可以在处理请求的方法上添加@ResponseBody注解,则此方法处理请求后,返回的值就是响应到客户端的数据!这种做法通常称之为”响应正文"。
@ResponseBody注解还可以添加在控制器类上,则此控制器类中所有处理请求的方法都将是”响应正文"的!另外,还可以使用@RestController取代@Controller和@ResponseBody
可以看到,在@RestController的源代码上,添加了@Controller和@ResponseBody,所以,可以把@RestController称之为”组合注解",而@Controller和@ResponseBody可以称之为@RestController的“元注解”
与之类似的,在Spring MVC框架中,添加了@ControllerAdvice注解的类中的特定方法,将可以作用于每次处理请求的过程中,但是,仅仅只使用@ControllerAdvice时,并不是前后端分离的做法,还应该结合@ResponseBody一起使用或直接改为使用@RestControllerAdvice
13.2 方法设计
参数列表:按需设计,即需要客户端提交哪些请求参数,在此方法的参数列表中就设计哪些参数,如果参数的数量有多个,并且多个参数具有相关性,则可以封装,并使用封装的类型作为方法的参数,另外,可以按需添加Spring容器中的其它相关数据作为参数,例如HttpServletRequest、HttpservletResponse、HttpSession等。
异常:如果有,全部抛出
注解:需要通过@RequestMapping系列注解配置请求路径
13.3 关于@RequestMapping
13.3.1 相关信息
在Spring MVC框架中,@RequestMapping的主要作用是:配置请求路径与处理请求的方法的映射关系。
此注解可以添加在控制类上,也可以添加在处理请求的方法上。
通常,会在控制器类和处理请求的方法上都配置此注解。
@RestController
@RequestMapping("/users")
public class UserController {
@Autowired
UserService userService;
@RequestMapping("/insertUser")
public String insertUser(UserInsertDTO userInsertDTO){
userService.insertUser(userInsertDTO);
return "添加成功"; //添加成功
}
}
并且,在使用@RequestMapping配置路径时,路径值两端多余的/是会被自动处理的,在类上的配置值和方法上的配置值中间的/也是自动处理的,
@RequestMapping(value= "/add-new",method = RequestMethod.POST)
按照以上配置,以上请求路径只允许使用POST方式提交请求!
强烈建议在正式运行的代码中,明确的配置并限制各请求路径的请求方式!
13.3.2 相关注解
另外,在Spring MVC框架中,还定义了基于@RequestMapping的相关注解:
@Getmapping
@Postmapping
@putMapping
@DeleteMapping
@PatchMapping
所以,在开发实践中,通常:在控制器类上使用@RequestMapping配置请求路径的前缀部分,在处理请求的方法上使用@GetMapping、@PostMapping这类限制了请求方式的注解。
13.4 在Spring MVC中接收请求参数
如果客户端提交的请求参数数量较少,且参数之间没有相关性,则可以选择将各请求参数声明为处理请求的方法的参数,并且,参数的类型可以按需设计。
如果客户端没有提交对应名称的请求参数,则方法的参数值为null。
如果客户端提交了对应名称的请求参数,但是没有值,则方法的参数值为空字符串(“”),如果方法的参数是需要将字符串转换为别的格式,但无法转换,则参数值为null。
如果客户端提交对应名称的请求参数,且参数有正确的值,则方法的参数值为就是请求参数值,如果方法的参数是需要将字符串转换为别的格式,但无法转换,则会抛出异常
另外,还推荐将某些具有唯一性的参数设计到URL中,使得这些参数值是URL的一部分!
提示如果占位符{}中的名称,与处理请求的方法的参数名称不匹配,则需要在@pathvariable注解.上配置占位符中的名称,例如:
@RequestMapping(" /delete/{albumId} ")
public string delete(@pathvariable("albumId") Long id) {
//暂不关心方法内部的实现
}
在配置占位符时,可以在占位符名称的右侧,可以添加冒号,再加上正则表达式,对占位符的值的格式进行限制,例如:
@RequestMapping("/delete/{id:[0-9]+}")
如果按照以上配置,仅当占位符位置的值是纯数字才可以匹配到此URL
并且,多个不冲突有正则表达式的占位符配置的URL是可以共存的!例如: .
@RequestMapping("/delete/{id:[a-z]+}")
以上表示的是"占位符的值是纯字母的",是可以与以上”占位符的值是纯数字的"共存!
另外,某个URL的设计没有使用占位符,与使用了占位符的,是允许共存的.
Spring MVC会优先匹配没有使用占位符的URL,再尝试匹配使用了占位符的URL。
14. 关FRESTful
RESTful也可以简称为REST,是一种设计软件的风格。
RESTful既不是规定,也不是规范。
RESTful风格的典型表现主要有:
- 处理请求后是响应正文的
- 将具有唯一性的参数值设计在URL中
- 根据请求访问数据的方式,使用不用的请求方式
如果尝试添加数据,使用POST请求方式
如果尝试删除数据,使用DELETE请求方式
如果尝试修改数据,使用PUT请求方式
如果尝试查询数据,使用GET请求方式
在设计RESTful风格的URL时,建议的做法是:
- 查询某数据的列表: /数据类型的复数,并使用GET请求方式,例如/albums
- 查询某1个数据(通常根据id) : /数据类型的复数/id值,并使用GET请求方式,例如/albums/9527
- 对某1个数据进行操作(增、删、改) : /数据类型的复数/id值/操作,并使用POST请求方式,例如/albums/9527/delete
15. 关于响应正文的结果
通常,需要使用自定义类,作为处理请求的方法、处理异常的方法的返回值类型。
响应到客户端的数据中,应该包含“业务状态码”,以便于客户端迅速判断操作成功与否,为了规范的管理业务状态码的值,在根包下创建web.ServiceCode枚举类型
并且,修改ServiceException异常类的代码,要求此类异常的对象中包含业务状态码,可以通过构造方法进行限制。
然后,原本业务逻辑层中抛出异常的代码将报错,需要在创建异常对象时传入业务状态码参数。
接下来,还需要使用自定义类型,表示响应到客户端的数据,则在根包下创建web.JsonResult类。
在实际处理请求和异常时,Spring MVC框架会将方法返回的JsonResult对象转换成JSON格式的字符串。
通常,不需要在JSON结果中包含为null的属性,所以,可以在application. properties /application.yml中进行配置。
16. 实现前后端交互
目前,后端(服务器端)项目使用默认端口8080,建议调整,可以通过配置文件中的server.port属性来指定。
然后,还需要在后端项目中配置允许跨域访问,则需要在实现了WebMvcConfigurer接口的配置类中,通过重写addCorsMappings()方法进行配置!
则在根包下创建config.WebMvcconfiguration类,实现WebMvcConfigurer接口,添加@configuration注解,并重写方法配置允许跨域访问。
17. mapper、service、controller
17.1 mapper层(数据持久层)
mapper层的作用是对数据库进行数据持久化操作
17.1.1 使用Mybatis实现数据库编程时,必须要编写的配置
在配置文件中使用mybatis.mapper-locations属性配置XML文件的位置,则先在根包下创建config.Mybatisconfiguration类,在类上添加@Configuration注解,并在类上添加@Mapperscan(“mapper包位置”)
- 在application.yml中添加配置:
mybatis:
mapper-locations: classpath:mapper/*.xml
- 创建Configuration类
@Configuration
@MapperScan("com.luck.demo01back.mapper")
public class MabatisConfiguration {
}
17.1.2 在根包下创建实体类
17.1.3 在根包下创建mapper接口,并在接口中添加抽象方法
17.1.4 在src/main/resources下创建mapper文件夹,并在mapper文件夹下粘贴得到mapper.xml,配置以上抽象方法对应的SQL语句.
17.2 service层(业务逻辑层)
17.2.1 在根包下创建DTO/VO类,封装需要由客户端提交的参数:
@Data
public class AdminAddNewDTO implements Serializable {
//字段
}
17.2.2 在根包下创建service.IAdminService接口,并在接口中添加抽象方法。
17.2.3 在根包下创建service.impl.AdminserviceImpl类,实现以上接口,并在类上添加@service注解,在类中自动装配AdminMapper对象。
17.2.4 并在以上实现类中实现接口中的方法。
17.2.5 还可将对应的异常类,枚举类弄过来。
18. 关于FKnife4j框架
Knife4j是一款基于Swagger 2的在线API文档框架。
18.1 如何使用Knife4j?
18.1.1 添加依赖。
当前建议使用的Knife4j版本,只适用于Spring Boot 2.6以下版本,不含Spring Boot 2.6。
关于依赖项的代码:
<!-- Knife4j Spring Boot: 在线API -->
<dependency>
<groupId>com.github.xiaoymin</ groupId>
<artifactId>knife4j-spring-boot-starter</artifactId>
<version>2.0.9</version>
</dependency>
18.1.2 在主配置文件(application.yml)中开启Knife4j的增强模式。
必须在主配置文件中进行配置, 不要配置在个性化配置文件中。
在application. yml中添加配置:
knife4j:
enable: true
18.1.3 添加Knife4j的配置类,进行必要的配置。
必须指定控制器包
在根包下创建config.Knife4jConfiguration配置类:
18.2 关于Knife4j的在线API文档,可以过一系列注解来配置此件的显示:
18.2.1 @Api
@Api: 添在控制器类上,通过此注解的tags属性,可以指定模块名称,并且,在指定名称时,建议在名称前添加数字作为序号,Knife4j会根据这些数字将各模块升序排列。
@Api(tags = "1管理员管理模块")
18.2.2 @Apiopearation
@Apiopearation: 添枷在控制器类中处理请求的方法上, 过此注解的value属性,可以指定业务/请求资源的名称。
@ApiOperation("添加管理员")
18.2.3 @Apioperationsupport
@Apioperationsupport: 添加在控制器类中处理请求的方法上,通过此注解的order属性(int) ,可以指定排序序号,Knife4j会根据这些数字将各业务/请求资源升序排列,例如:
//建议给的数值大点。
@ApiOperationSupport(order = 100)
18.2.4 @ApiModelproperty
如果处理请求时,参数是封装的POJO类型,需要对各请求参数进行说明时,应该在此POJQ类型的各属性上使用@ApiModelproperty注解进行配置,通过此注解的value属性配置请求参数的名称,通过requeired属性配置是否必须提交此请求参数(并不具备检查功能)
@ApiModelproperty(value = "相册名称",example = "小米10的相册",required = true)
private String name;
18.2.5 @ApiImplicitParam
对于处理请求的方法的参数列表中那些未封装的参数(例如string、Long) ,需要在处理请求的方法上使用@ApiImplicitParam注解来配置参数的说明,必须配置name属性,此属性的值就是方法的参数名称,使得此注解的配置与参数对应上,然后,再通过value属性对参数进行说明,还要注意,此属性的requi red属性表示是否必须提交此参数,默认为false,即使是用于配置路径上的占位符参数,一旦使用此注解,required默认也会是false,则需要显式的配置为true,另外,还可以通过dataType配置参数的数据类型,如果未配置此属性,在API文档中默认显示为string,可以按需修改为int、long 等。例如:
@Api ImplicitParam(name = "id",value = "相册id", required = true, dataType = "long")
@PostMapping("/{id: [0-9]+}/delete")
public JsonResult delete (@PathVariable Long id) {
//暂不关心方法内部的代码
}
如果处理请求的方法上有多个未封装的参数,则需要使用多个@ApiImplicitparam注解进行配置,并且,这多个@ApiImplicitParam注解需要作为@ApiImplicitparams注解的参数
@ApiImplicitParams({
@ApiImplicitParam(xxx),
@ApiImplicitparam(xxx),
@ApiImplicitParam(xxx)
})
19. 关于@RequestBody
在Spring MVC框架中,在处理请求的方法的参数前:
19.1 添加了@RequestBody注解
当添加了@RequestBody注解,则客户端提交的请求参数必须是对象格式的,例如:
{
"name": "小米11的相册",
"description": "小米11的相册的简介"
"sort": 88
}
如果客户端提交的数据不是对象,而是FormData格式的,在接收到请求时将报错
19.2 没有添加@RequestBody注解
当没有添加@RequestBody注解,则客户端提交的请求参数必须是FormData格式的,例如:
name=小米11的相册&description=小米11的相册的简介&sort=88
如果客户端提交的数据不是FormData格式的,而是对象,则无法接收到参数(不会报错,控制器中各参数值为null)
另外,Knife4j框架的调试界面中,如果是对象格式的参数(使用了@RequestBody) , 将不会显示各请求参数的输入框,而是提供一个JSON字符串供编辑, 如果是FormData格式的参数(没有使用@RequestBody),则会显示各请求参数对应的输入框。
通常,更建议使用FormData格式的请求参数!则在控制器处理请求的方法的参数上不需要添加@RequestBody注解!
19.3 Vue脚手架便捷使用FormData
在Vue脚手架项目中,为了更便捷的使用FormData格式的请求参数,可以在项目中使用qs框架,此框架的工具可以轻松的将JavaScript对象转换成FormData格式!
19.3.1 在前端的Vue脚手架项目中,安装qs
npm i qs -S
19.3.2 在main. js中添加配置
import qs from 'qs';
Vue.prototype.qs = qs;
19.3.3 在提交请求之前,将对象转换成FormData格式
let formData =this.qs.stringify(this.ruLeForm);
20. 关于检查请求参数
在编写服务器端项目时,当接收到请求参数时,必须第一时间对各请求参数的基本格式进行检查,需要注意:既然客户端(例如网页)已经检查了请求参数,服务器端应该再次检查,因为:
- 客户端的程序是运行在用户的设备上的,存在程序被篡改的可能性,所以,提交的数据或执行的检查是不可信的。
- 在前后端分离的开发模式下,客户端的种类可能较多,例如网页端、手机端、电视端,可能存在某些客户端没有检查
- 升级了某些检查规则,但是,用户的设备上,客户端软件没有升级(例如手机APP还是此前的版本)
以上原因都可能导致客户端没有提交必要的数据,或客户端的检查不完全符合服务器端的要求!所以,对于服务器端而言,客户端提交的所有数据都是不可信的!则服务器端需要对请求参数进行检查!
即使服务器端已经对所有请求参数进行了检查,各个客户端仍应该检查请求参数,因为:
- 能更早的发现明显错误的数据,对应的请求将不会提交到服务器端,能够减轻服务器端的压力
- 客户端的检查不需要与服务器端交互,当出现错误时,能及时得到反馈,对于用户的体验更好
21. 通过Validation框架检查请求参数的基本格式
Spring Validation框架可用于在服务器端检查请求参数的基本格式(例如是否提交了请求参数、字符串的长度是否正确、数字的大小是否在允许的区间等)。
21.1 添加依赖项
<!-- Spring Boot Validation, 用于检查请求参数的基本格式-->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-validation</artifactId>
</dependency>
21.2 检查封装在POJO中的请求参数
21.2.1 检查基本格式
如果请求参数使用自定义的POJO类型进行封装,当需要检查这些请求参数的基本格式时,需要:
- 在处理请求的方法的参数列表中,在POJO类型前添加@Validated或@Valid注解,表示需要通过Spring Validation框架对此POJO类型封装的请求参数进行检查。
public JsonResult addNew(@Validated ALbumAddNewDT0 aLbumAddNewDT0)
- 在POJO类型的属性上,使用检查注解来配置检查规则,例如@NotNull注解就表示"不允许为null", 即客户端必须提交此请求参数。
@NotNull(message = "添加相册失败,必须提交相册名称! ")
private String name;
所有检查注解都有message属性,配置此属性,可用于向客户端响应相关的错误信息。
21.2.2 处理异常
由于Spring Validation验证请求参数格式不通过时,会抛出异常,所以,可以在全局异常处理器中对此类异常进行处理!
- 先在ServiceCode中添加对应的枚举值:
ERR_BAD_REQUEST(40000)
- 然后,在全局异常处理器中添加对org.springframework.validation.Bi ndException的处理:
@Excepti onHandler
public JsonResult handleBindException(BindException e) {
1og.debug("捕获到BindException: {}",e.getMessage());
//以下2行代码,如果有多种错误时,将随机获取其中1种错误的信息,并响应
// String message = e.getFieldError().getDefaultMessage();
// return JsonResult.fail(ServiceCode.ERR_ BAD_ REQUEST,message);
//以下代码,如果有多种错误时,将获取所有错误信息,并响应
StringBuilder stringBuilder = new StringBuilder();
List<FieldError> fieldErrors = e.getFieldErrors();
for (FieldError fieldError : fieldErrors) {
stringBuilder.append(fieldError.getDefaultMessage();
return JsonResult.fail(ServiceCode.ERR_BAD_ REQUEST,stringBuilder.tostring());
可以发现,Spring Validation在检查请求参数格式时,如果检查不通过,会记录下相关的错误,然后,继续进行其它检查,直到所有检查全部完成,才会返回错误信息!
检查全部的错误,相对更加消耗服务器资源,可以通过配置,使得检查出错时直接结束并返回错。创建配置类并写方法:
@Bean
public javax.validation.Validator validator() {
return Validation.byProvider(HibernateValidator.class)
.configure() //开始配置Validator
.failFast(true) //快速失败,即检查请求参数发现错误时直接
.buildValidatorFactory()
.getValidator();
}
21.3 关于检查注解,常用的有:
21.3.1 @NotNull
不允许为null,适用于所有类型的请求参数
21.3.2 @NotEmpty
不允许为空字符串(长度为0的字符串),仅适用于字符串类型的请求参数
此注解不检查是否为null,即请求参数为null将通过检查
此注解可以与@NotNull同时使用
21.3.3 @NotBlank
不允许为空白(形成空白的主要有:空格、TAB制表位、换行等),仅适用于字符串类型的请求参数
此注解不检查是否为null,即请求参数为null将通过检查
此注解可以与@NotNull同时使用
21.3.4 @pattern
要求被检查的请求参数必须匹配某个正则表达式,过此注解的regexp属性可以配置正则表达式,仅适用于字符串类型的请求参数
此注解不检查是否为null,即请求参数为null将通过检查
此注解可以与@NotNull同时使用
21.3.5 @Range
要求被检查的数值型请求参数必须在某个数值区间范围内,通过此注解的min属性可以配置最小值,通过此注解的max属性可以配置最大值,仅适用于数值类型的请求参数
此注解不检查是否为null,即请求参数为null将通过检查
此注解可以与@NotNull同时使用
另外,在org.hibernate.validator.constraints和javax.validation.constraints包还有其它检查注解。
如果请求参数是一些基本值, 没洧封装(例如string、Integer、 Long) , 则需要将检查注解添加在请求参数上。
@ApiImplicitParam(name = "id", value = "相册id", paramType = "query")
public string deleteTest (@Range(min = 1,message = "测试删除相册失败,id值必须是1或更大的有效整数! ") Long id) {}
然后,还需要在控制器类上添加@validated注解,以上方法参数前的检查注解才会生效!如果后续运行时没有通过此检查, Spring Validation框架将抛出ConstraintviolationException类型的异常。
最后在全局异常处理器添加处理以上异常的方法。
22. 迭代器
22.1 作用
在遍历过程中安全的移除元素
22.2 代码
List<AdminListItemV0> list = adminMapper.list();
// list.remove(0);
//将管理员列表中id=1的管理员数据移除
Iterator<AdminListItemVO> iterator = list.iterator();
while (iterator.hasNext()) {
AdminListItemVO item = iterator.next();
if (item.getId() == 1) {
iterator.remove () ;
break;
}
}
//返回
return list;
四、Spring框架
1. Spring框架的作用
Spring框架主要解决了创建对象、管理对象的相关问题。
1.1 创建对象
User user = new User();
1.2 管理对象
Spring会在创建对象之后,完成必要的属性赋值等操作,并且,还会持有所创建的对象的引用,由于持久大量对象的引用,所以,Spring框架也通常被称之为"Spring容器”。
2. Spring框架创建对象的做法
Spring框架创建对象有2种做法,第1种是通过配置类中的@Bean方法,第2种是通过组件扫描。
2.1 @Bean方法
@Bean方法:在任何配置类中,自定义返回对象的方法,并在方法上添加@Bean注解,则Spring会自动调用此方法,并且,获取此方法返回的对象,将对象保存在Spring容器中。
2.2 组件扫描
关于组件扫描:需要通过@componentscan注解来指定扫描的根包,则Spring框架会在此根包下查找组件的源文件,并且创建这些组件的对象。
根包:某个包及其子孙包
组件:在Spring框架中,添加了@Component及其衍生注解的,都是组件!常见的组件注解有:
@Component:通用组件注解
@Controller:应该添加在控制器类上
@Service:应该添加在处理业务逻辑的类上
@Repository:应该添加在处理数据访问(直接与数据源交互)的类上
@Configuration
以上5个组件注解,除了@Configuration以外,另外4个在功能、用法、执行效果方面,在Spring框架的作用范围内是完全相同的,只是语义不同!Spring框架在处理@Configuration注解时,会使用CGLib的代理模式来创建对象,并且,被Spring实际使用的是代理对象。
提示:在Spring Boot项目中,启动类上的注解@SpringBootApplication,此注解的元注解包含@ComponentScan注解,所以,Spring Boot项目启动时就会执行组件扫描,扫描的根包就是启动类所在的包!
在开发实践中,如果需要创建非自定义类(例如Java官方的类,或其它框架中的类)的对象,必须使用@Bean方法,毕竟你不能在别人声明的类上添加组件注解,如果需要创建自定义类的对象,则优先使用组件扫描的做法,因为这种做法更加简单!
3. Spring管理的对象的作用域
Spring管理的对象默认是"单例"的。则在整个程序的运行过程中,随时可以获取或访问Spring容器中的单例对象。
单例:单一实例(单一对象),即:在任意时间,某个类的对象最多只有1个。
如果需要Spring管理某个对象采取”非单例”的模式,可以通过@scope(“prototype”)注解来实现。
提示:如果是通过@Bean方法创建对象,则@scope(“prototype”)注解添加在@Bean方法上,如果是通过组件扫描创建对象,则@scope(“prototype”)注解添加在组件类上。
如果没有Spring框架,自己手动实现单例效果,大致需要:
//饿汉式单例
public class Singleton{
private Singleton(){}
private static Singleton instance = new Singleton();
public static Singleton getInstance(){
return instance;
}
}
//懒汉式单例
public class Singleton{
private Singleton(){}
private static Singleton instance;
public static Singleton getInstance(){
if(instance==null){
instance = new Singleton();
}
return instance;
}
}
Spring管理的单例对象,默认情况下预加载的!可以通过@Lazy注解配置为懒加载的!
提示:如果是通过@Bean方法创建对象,则@Lazy注解添加在@Bean方法上,如果是通过组件扫描创建对象,则@Lazy注解添加在组件类上。
4. 自动装配机制
Spring的自动装配机制表现为:当Spring管理的类的属性需要被自动赋值,或Spring调用的方法的参数需要值时,Spring会自动从容器中找到合适的值,为属性/参数自动赋值!
当类的属性需要值时,可以在属性上添加@Autowired注解。
关于被Spring调用的方法,主要表现为:构造方法、配置类中的@Bean方法等。
4.1 关于调用构造方法:
如果类中存在无参数构造方法(无论是否存在其它构造方法),Spring会自动调用无参数构造方法
如果类中仅有1个构造方法, Spring会自动尝试调用,且,如果此构造方法有参数, Spring会自动尝试从容器中查找合适的值用于调用此构造方法
如果类中有多个构造方法,且都是有参数的,Spring不会自动调用任何构造方法,且会报错
如果希望Spring调用特定的构造方法,应该在那一个构造方法上添加@Autowired注解
关于在属性上使用@Autowired时的提示: Field injection is not recommended, 其意思是"字段注入是不推荐的”,因为,开发工具认为,你有可能在某些情况下自行创建当前类的对象,例如自行编写代码:AlbumController albumController = new AlbumController());由于是自行创建的对象,Spring框架在此过程中是不干预的,则类的属性IAlbumService albumService将不会由Spring注入值,如果此时你也没有为这个属性赋值,则这个的属性就是null,如果还执行类中的方法,就可能导致NPE ( NullPointerException),这种情况可能发生在单元测试中。开发工具建议使用构造方法注入,即使用带参数的构造方法,且通过构造方法为属性赋值,并且类中只有这1个构造方法,在这种情况下,即使自行创建对象,由于唯一的构造方法是带参数的,所以,创建对象时也会为此参数赋值,不会出现属性没有值的情况,所以,通过构造方法为属性注入值的做法被认为是安全的,是建议使用的做法!但是,在开发实践,通常并不会使用构造方法注入属性的值,因为,属性的增、减都需要调整构造方法,并且,如果类中需要注入值的属性较多,也会导致构造方法的参数较多,不是推荐的。
4.2 关于合适的值:
Spring框架会查找容器中匹配类型的对象的数量:
4.2.1 0个
无法装配,需要判断@Autowired注解的required属性:
true :在加载Spring时直接报错NoSuchBeanDefini ti onException
false: 放弃自动装配,且尝试自动装配的属性将是默认值
4.2.2 1个
直接装配,且装配成功
4.2.3 超过1个
尝试按照名称来匹配,如果均不匹配,则在加载Spring时直接报错NoUniqueBeanDefinitionException,按照名称匹配时,要求被装配的变量名与Bean Name保持一致。
4.3 关于Bean Name
每个Spring Bean都有一个Bean Name,如果是通过@Bean方法创建的对象,则Bean Name就是方法名,或通过@Bean注解参数来指定名称,如果是通过组件扫描的做法来创建的对象,则Bean Name默认是将类名首字母改为小写的名称(例如,类名为A1bumServiceImpl,则Bean Name为al bumserviceImpl)(此规则只适用于类名中第1个字母大写、第2个字母小写的情况,如果不符合此情况,则Bean Name就是类名),Bean Name也可以通过@Component等注解的参数进行配置,或者,你还可以在需要装配的属性上使用@Qualifier注解来指定装配哪个Bean Name对应的Spring Bean。
另外,在处理属性的自动装配.上,还可以使用@Resource注解取代@Autowi red注解,@Resource 是先根据名称尝试装配,再根据类型装配的机制!
5. 关于lOC和DI
lOC = Inversion of Control,控制反转,表现为将对象的管理权交给了框架。
DI = Dependency Injection,依赖注入,表现为”为类中的属性自动赋值”。
Spring框架通过Dl实现了lOC。
6. 基于Spring JDBC框架的事务管理
6.1 @Transactional
事务: Transaction, 是数据库中的一种能够保证多个写操作要么全部成功,要么全部失败的机制!
在基于Spring JDBC的数据库编程中,在业务方法上添加@Transactional注解,即可使得这个业务方法是"事务性"的!
假设,存在某银行转账的操作涉及多次数据库的写操作,如果由于某些意外原因(例如停电、服务器死机等),导致第1条SQL语句成功执行,但是第2条SQL语句未能成功执行,就会出现数据不完整的问题!使用事务就可以解决此问题!
6.2 关于@Transationcal注解,可以添加在
- 业务实现类的方法上
仅作用于当前方法 - 业务实现类上
将作用于当前类中所有方法 - 业务接口的抽象方法上(推荐)
仅作用于当前方法
无论是哪个类重写此方法,都将是事务性的 - 业务接口上
将作用于当前接口中所有抽象方法
无论是哪个类实现了此接口,重写的所有方法都是将是事务性的
6.3 事务几个概念
开启事务: BEGIN
提交事务: COMMIT
回滚事务: ROLLBACK
在执行数据访问操作时,数据库有一个”自动提交”的机制。
事务的本质是会先将“自动提交"关闭,当业务方法执行结束之后,再一次性"提交"。
在基于Spring JDBC的程序设计中,通过@Transactional注解即可使得业务方法是事务性的,其实现过程大致为
开启事务
try {
执行业务方法
提交事务
} catch (RuntimeException e) {
回滚事务
}
可以看到,Spring JDBC框架在处理事务时,默认将根据RuntimeException进行回滚!
提示:可以配置@Transactional注解的rollbackFor或rollbackForclassName属性来指定回滚的异常类型,即根据其它类型的异常来回滚,例如:
@Transactional(rollbackFor = {IoException.class})
@Transactional(rollbackForClassName = {“java. io. IoException”})
另外,还可以通过noRollbackFor或noRollbackForclassName属性用于指定不回滚的异常!
建议在业务方法中执行了任何增、删、改操作后,都获取受影响的行数,并判断此值是否符合预期,如果不符合,应该及时抛出RuntimeException或其子孙类异常!
补充: Spring JDBC框架在实现事务管理时,使用到了Spring AOP技术及基于接口的代理模式,由于使用了基于接口的代理模式,所以,如果将@Transactional注解添加在实现类中自定义的方法(不是重写的接口中的抽象方法)上,是错误的做法!
五、处理密码加密
1. 处理密码加密
用户的密码必须被加密后再存储到数据库,否则,就存在用户账号安全问题。用户使用的原始密码通常称之为“原文”或”明文”,经过算法的运算,得到的结果通常称之为"密文”。
在处理密码加密时,不可以使用任何加密算法,因为所有加密算法都是可以被逆向运算的,也就是说,当密文、算法、加密参数作为已知条件的情况下,是可以根据密文计算得到原文的!
提示:加密算法通常是用于保障数据传输过程的安全的,并不适用于存储下来的数据安全!
2. 摘要算法
对存储的密码进行加密处理,通常使用消息摘要算法!
2.1 消息摘要算法的特点
消息(原文、原始数据)相同,则摘要相同
无论消息多长,每个算法的摘要结果长度固定
消息不同,则摘要极大概率不同
消息摘要算法是不可逆向运算的算法!即你永远不可能根据摘要(密文)逆向计算得到消息(原文) !
2.2 常见的消息摘要算法有:
SHA系列: SHA-1、 SHA-256、 SHA-384、 SHA-512
MD家族: MD2、 MD4、 MD5
Spring框架内有Digestutils的工具类,提供了MD5的API,例如:
String rawPassword = "123456";
String encodedPassword = DigestUtils.md5DigestAsHex (rawPassword.getBytes()) ;
System.out.printIn("原文:"+rawPassword) ;
System.out.println("密文:"+encodedPassword);
提示:在项目中添加commons-codec的依赖项,可以使用更多消息摘要算法的API。
2.3 消息碰撞
在算法的学术领域中,如果算法的计算结果的长度是固定,会根据结果是由多少位二进制数来组成,来确定是这多少位的算法,以MD5算法为例,其计算结果是由128个二进制数组成的,所以,MD5算法是128位算法,通常,会将二进制结果转换成十六进制来表示,所以,会是32位长度的十六进制数!
常见的消息摘要算法中,MD系列的都是128位算法,SHA-1 是160位算法,SHA-256是256位算法, SHA-384是384位算法,SHA-512是512位算法。
理论上来说,如果某个消息摘要算法的结果只是1位(1个二进制数), 最多使用2 + 1个不同的原文,必然发生"碰撞”(即完全不同的原文对应相同的摘要),同理,如果算法的结果有2位(2个二进制数组成), 最多使用4 + 1个不同的原文必然后发生碰撞。如果算法的结果有3位,最多使用23+ 1个不同的原文必然后发生碰撞。
s1 = 00
s2 = 01
s3 = 10
s4 = 11
s5 =
MD5是128位算法,理论上,最多需要使用2的128次方+ 1个不同的原文才能保证必然发生碰撞!
2的128次方的值是: 340282366920938463463374607431768211456。
当使用MD5处理密码加密时,理论上,需要尝试340282366920938463463374607431768211456 + 1个不同的原密码,才能试出2个不同的原密码都可以登录同一个账号!由于需要尝试的次数太多,按照目前的计算机的算力,这是不可能实现的! 所以,大致可以视为找不到2个不同的原文对应相同的结果。
目前,在网络上也有许多平台提供了这种机制的"破解"!而这些平台收录的原文密文对应关系不可能特别多,假设允许使用在密码中的字符有80种,则8位长度(含以下长度)的密码有约1677万亿种,大多平台不可能收录!
所以,只要原密码足够复杂,此原密码与密文的对应关系大概率是没有被‘破解”平台收录的,则不会被破解!
2.4 在编程时,如何保证密码安全
1.要求用户使用安全强度更高的原始密码
2.在处理加密的过程中,使用循环实现多重加密
String rawPassword = "123456";
System.out.println("原文: " + rawPassword);
String encodedPassword = rawPassword;
for(inti=0;i<1000;i++){
encodedPassword = DigestUtils.md5DigestAsHex(encodedPassword.getBytes());
System.out.println("密文: " + encodedPassword) ;
}
3.使用位数更长的算法
4.加盐
String salt = "kjhfdsi8uotjregikuj4t53798u5";
String rawPassword = "123456";
System.out.printLn("原文:”+ rawPassword) ;
// 123456k jhfdsi8uotjregikuj4t53798u5
String encodedPassword = DigestUtils
.md5DigestAsHex((rawPassword + salt).getBytes());
System. out.printLn("密文: " + encodedPassword) ;
5.综合以上做法
3. 如何实现
3.1 配置pom.xml
<!-- Spring Security -->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-security</artifactId>
</dependency>
3.2 在对应的serviceimpl中
// Admin对象中取出密码,进行加密处理,并将密文封装回Admin对象中
String rawPassword = admin.getPassword();
String encodedPassword = new BCryptPasswordEncoder().encode(rawPassword);
admin.setPassword(encodedPassword);
String rawPassword = "123456";
String encodedPassword = "$2a$10$n07GEum8P27F8SOEGEHryel7m89opm/AMdaqMBk.qdsdIpE/SWFwe" ;
BCryptPasswordEncoder passwordEncoder = new BCryptPasswordEncoder();
//matches方法可判断原文与密文是否相等返回值为boolean
System.out.printLn(passwordEncoder.matches(rawPassword,encodedPassword);
六、RBAC模型
1. RBAC模型
RBAC模型(Role-Based Access Control:基于角色的访问控制)模型是20世纪90年代研究出来的一种新模型,但其实在20世纪70年代的多用户计算时期,这种思想就已经被提出来,直到20世纪90年代中后期,RBAC才在研究团体中得到一些重视,并先后提出了许多类型的RBAC模型。其中以美国George Mason大学信息安全技术实验室(LIST) 提出的RBAC96模型最具有代表,并得到了普遍的公认。
2. 权限授权过程
RBAC认为权限授权的过程可以抽象地概括为: Who是否可以对What进行How的访问操作,并对这个逻辑表达式进行判断是否为True的求解过程,也即是将权限间题转换为What. How的问题,Who、What Hom构成了访问权限三元组。
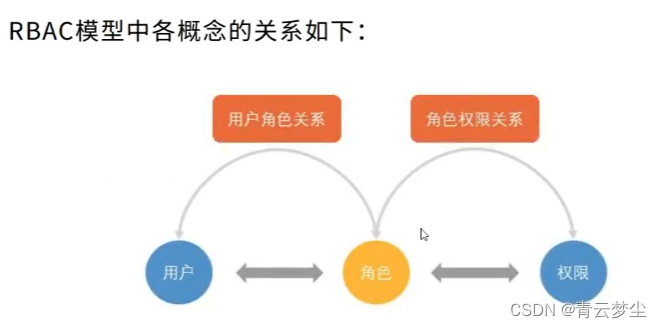
3. 基础组成
在RBAC模型里面,有3个基础组成部分,分别是:用户、角色和权限。
RBAC通过定义角色的权限,并对用户授予某个角色从而来控制用户的权限,实现了用户和权限的逻辑分离(区别于ACL模型),极大地方便了权限的管理。
4. RBAC模型中的核心概念包括
User (用户) :每个用户都有唯一的UID识别,并被授予不同的角色
Role(角色):不同角色具有不同的权限
Permission (权限) :访问权限
用户-角色映射:用户和角色之间的映射关系
角色-权限映射:角色和权限之间的映射
5. 各概念关系
七、
1. Session
HTTP协议是无状态的协议,即:从协议本身并没有约定需要保存用户状态!表现为:某个客户端访问了服务器之后,后续的每一次访问, 服务器都无法识别出这是前序访问的客户端!
在传统的解决方案中,可以从技术层面来解决服务器端识别客户端并保存相关数据的问题,例如使用Session机制。
Session的本质是保存在服务器端的内存中的类似Map结构的数据,每个客户端都有一个属于自己的Key,在服务器端有对应的value,就是Session。
关于客户端提交请求时的Key:当某客户端第1次向服务器端提交请求时,并没有可用的Key,所以并不携带Key来提交请求,当服务器端发现客户端没有携带Key时,就会响应一个Key到客户端,客户端会将这个Key保存下来,并在后续的每一次请求中自动携带这个Key。 并且,服务器端为了保证各个Key不冲突,会使用UUID算法来生成各个key。由于这些Key是用于访问Session数据的,所以,一般称之为Session ID。
1.1 基于Session的特点,在使用时,可能存在一些问题
1.1.1 不能直接用于集群甚至分布式系统
可以通过共享Session技术来解决
1.1.2 将占用服务器端的内存,则不宜长时间保存
2. Token
Token:票据,令牌
Token机制是目前主流的取代Session用于服务器端识别客户端身份的机制。
Token就类似于现实生活中的"火车票",当客户端向服务器端提交登录请求时,就类似于"买票"的过程,当登录成功后,服务器端会生成对应的Token并响应到客户端,则客户端就拿到了所需的"火车票",在后续的访问中,客户端携带火车票即可,并且,服务器端有验票机制,能够根据客户端携带的火车票识别出客户端的身份。
2.1 JWT
2.1.1 配置
JWT: JSON Web Token,是使用JSON格式来组织多个属性于值,主要用于Web访问的Token。
JWT的本质就是只一个字符串,是通过算法进行编码后得到的结果。
在项目中,如果需要生成、解析JWT,需要添加相关依赖项,能够实现生成、解析JWT的工具包较多,可以自由选择。
例如,在pom. xml中添加:
<!-- JJWT (Java JWT) -->
<dependency>
<groupId>io.jsonwebtoken</groupId>
<artifactId>jjwt</artifactId>
<version>0.9.1</version>
</dependency>
@Test
public void testGenerate() {
Map<String, Object> claims = new HashMap<>();
claims.put("id",9527);
claims.put("username", "liucangsong");
claims.put("email", "liucangsong@163.com");
Date expirationDate = new Date (System.currentTimeMillis() + 10*60*1000);
System.out.println("过期时间:"+ expirationDate);
String secretKey = "kns439a}fdLK34j smfd{MF5-8DJSsLKhJNFDSjn" ;
//核心代码
String jwt = Jwts.builder()
// Header
.setHeaderParam( s: "alg", o: "HS256")
.setHeaderParam( s: "typ", o: "JWT")
// Payload
.setClaims(claims)
.setExpiration(expirationDate)
// Signature
.signWith(SignatureAlgorithm.HS256, secretKey)
.//整合
.compact();
System.out.println(jwt);
Claims claims = Jwts.parser().setSigningKey(secretKey).parseClaimsJws(jwt).getBody();
Object id = claims.get("id");
System.out.println("id=" + id);
Object username = claims.get("username");
System.out.printLn("username=" + username);
}
2.1.2 JWT安全性
JWT是不安全的,因为在不知道secretKey的情况下,任何JWT都是可以解析出Header. Payload部分的, 这2部分的数据并没有做任何加密处理,所以,如果JWT数据被暴露,则任何人都可以从中解析出Header. Payload中的数据!
至于JWT中的secretKey,及生成JWT时使用的算法,是用于对Header、Payload执行签名算法的, JWT中的Signature是用于验证]WT真伪的。
当然,如果你认为有必要的话,可以自行另外使用加密算法,将Payload中应该封装的数据先加密,再用于生成JWT!
另外,如果JWT数据被泄露,他人使用有效的JWT是可以正常使用的!所以,通常,在相对比较封闭的操作系统(例如智能手机的操作系统)中,JWT的有效时间可以设置得很长,但是,不太封闭的操作系统(例如PC端的操作系统)中,JWT的有效时间应该相对较短。
2.1.3 使用JWT时,需注意
根据你所需的安全性,来设置JWT的有效时间
不要在JWT中存放敏感数据,例如:手机号码、身份证号码、明文密码
如果一定要在JWT中存放敏感数据,应该自行使用加密算法处理过后再用于生成WT















 2338
2338











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









