







近来因为特殊需要,需要获得一定量的数据。这让我下意识的就想到了用网络爬虫来达成目的。
之前常听网络爬虫,也知道Python在这方面非常火热,但自我感觉还是对Java稍微熟悉一点,并且得知Java用来做爬虫也很方便,所以就去查了相关资料,在此分享我的心得。
没有枯燥的专业术语,文章的目的只是为了更好的理解其中的核心原理,帮助初学者快速入门!
一.网络三分游
网络爬虫网络爬虫,我们有必要简单了解下网络的相关知识。
1.URL
URL可被看作是一个互联网资源的名字。比如我们在浏览器地址栏输入https://www.baidu.com,这就是一个URL,用来告诉浏览器想要访问哪台机器上的哪个资源(网页,文件…)。浏览器根据这个名字去对应服务器找资源,服务器把对应的资源发送给浏览器,浏览器再展示给我们。
下面来看几个例子:
URL为:https://www.baidu.com/
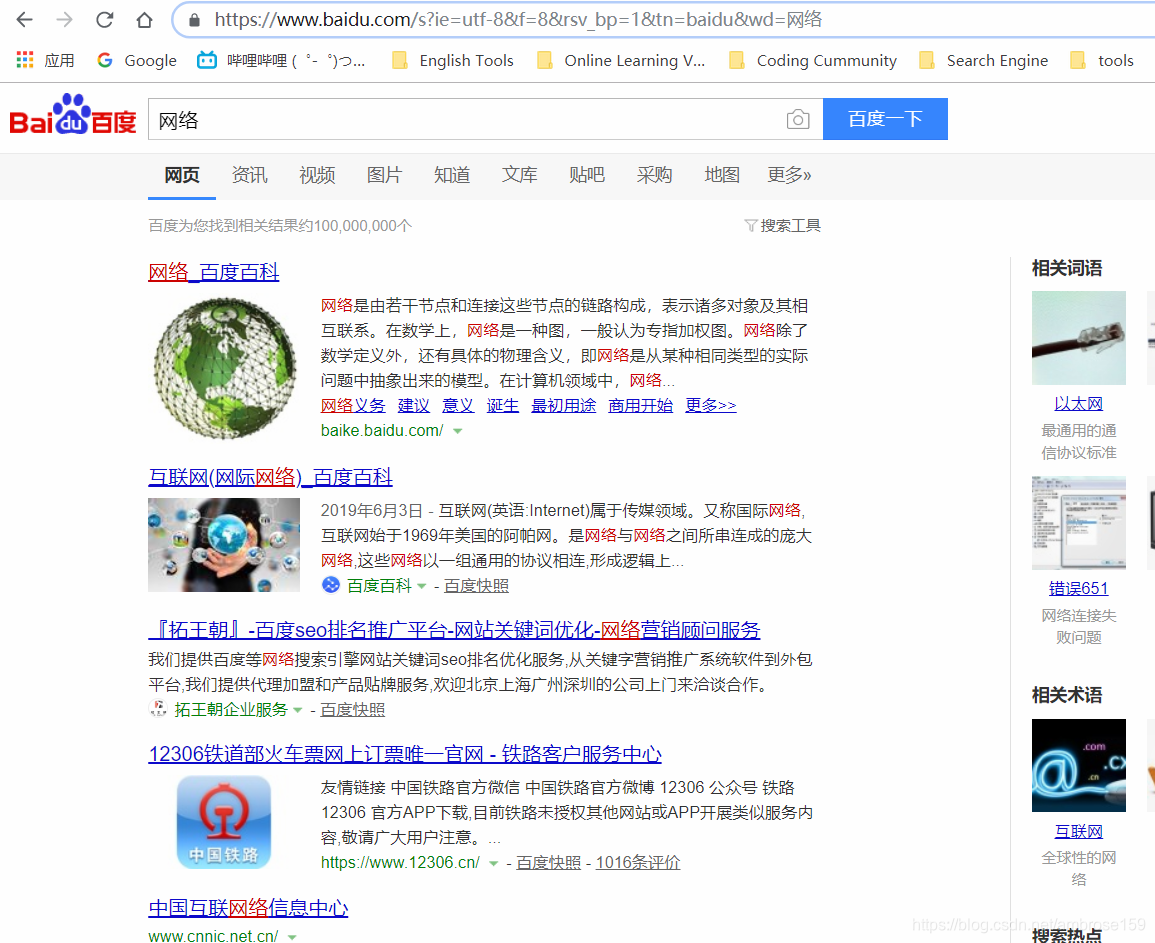
URL为:https://www.baidu.com/s?ie=utf-8&f=8&rsv_bp=1&tn=baidu&wd=网络
URL为:https://cn.bing.com/th?id=OHR.Montreux_ZH-CN5485205583_1920x1080.jpg&rf=LaDigue_1920x1080.jpg
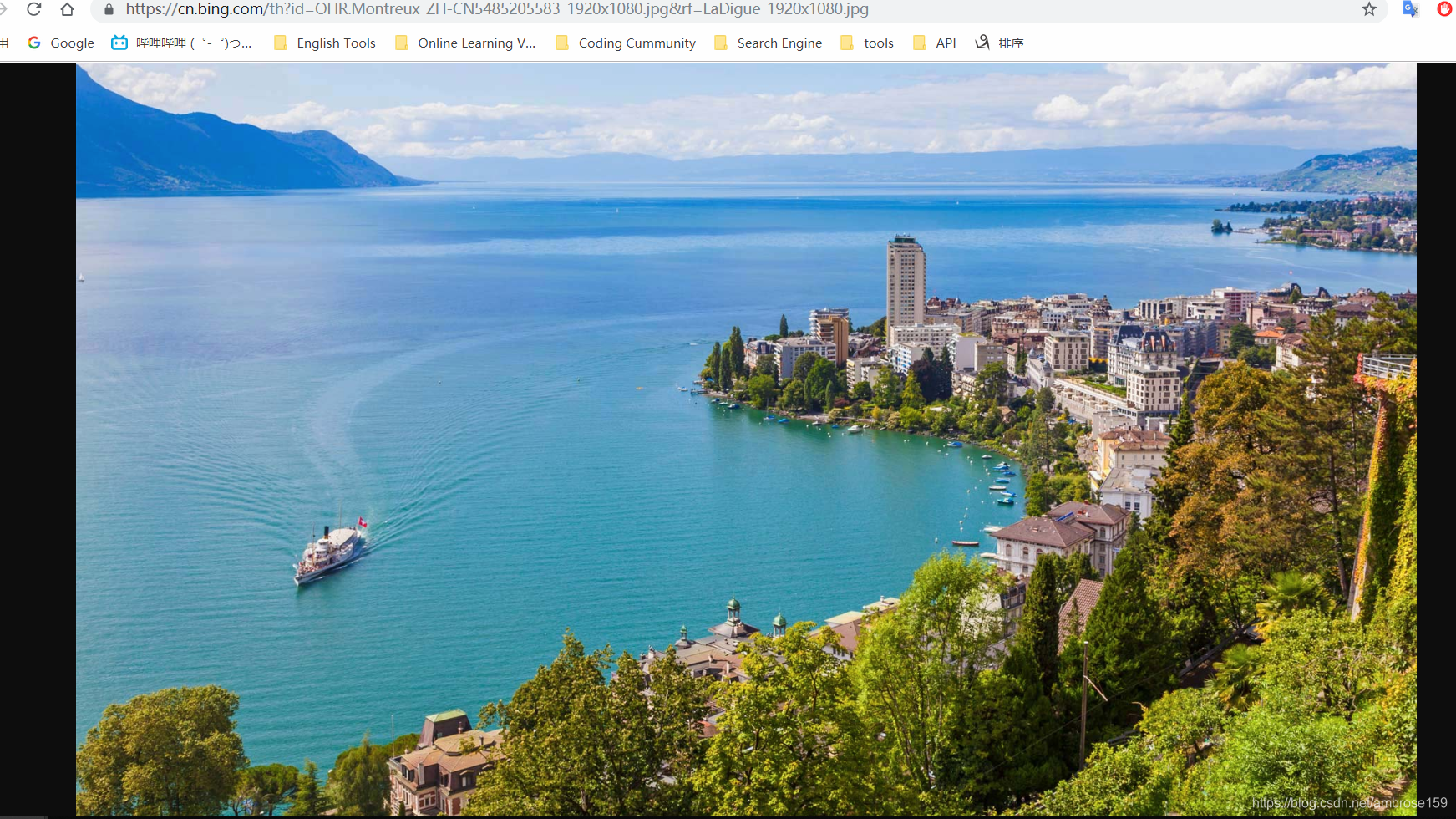
访问必应首页的背景图。
2.HTTP协议
当今,每天在浏览器地址栏上面输入要访问的URL,访问Web页面,几乎是我们所有人每天都会做的事(面向浏览器编程)。我们输入的URL中已经指定了数据交互的协议,如上面例子中URL的开头部分https。通俗的讲,协议就是一种规则,大家按这个规则来,不会乱,不易出错。
你就比如两个人要进行约一个地方碰头,共同约定了个暗号天王盖地虎…,晚上十点小巷子里碰面。时候已到,黑影之中,一声天王盖地虎,黑暗之中有人应道:到我是二百五。这时大家就知道人没错,可以现身碰头了。
同样,浏览器跟服务器交互,也需要一种约定,一种规则,HTTP协议就是其中的一种(HTTPS基于HTTP,安全性好)。说白了就是,浏览器向服务器要资源,怎么要?发个暗号,服务器给浏览器资源,怎么给?同样需要发个暗号。
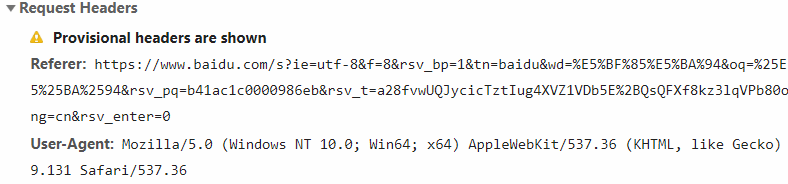
浏览器向服务器要资源时,发的暗号:(浏览器按F12可查看)
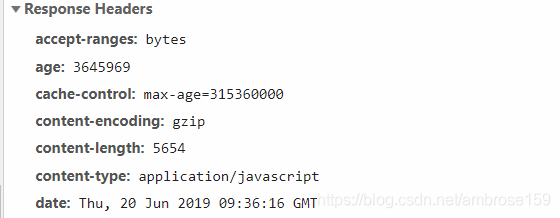
服务器给浏览器发资源时,发的暗号:(浏览器按F12可查看)
如果大家暗号对上了,就可以愉快的传数据(“碰头”)了,反映出来的就是我们可以看小视频了(学习视频),听歌了等等。
二.网络爬虫
简单理解,网络爬虫就是,通过代码,模拟出浏览器跟服务器交互的过程(碰头),以此获得服务器上的数据。
1.通过java的net包
既然要用代码模拟,那我们接下来就是代码。Java的net包中,包含模拟浏览器跟服务器的相关类。
Demo1
import java.io.InputStream;
import java.net.URL;
import java.net.URLConnection;
/**
* 模拟浏览器发送请求,接收数据
* @author luckyriver
*
*/
public class URL_Demo {
/**
* 以访问百度首页为例
* @throws Exception
*/
public static void main(String[] args) throws Exception {
//对应浏览器地址栏输入URL
URL url=new URL("https://www.baidu.com");//创建URL对象,相信大家已经知道了什么是URL,构造方法传入想要访问的URL
//对应地址栏输入后点击连接
URLConnection con=url.openConnection();//调用URL对象的openConnection()方法,字面意思,打开连接,获得连接对象
String type=con.getContentType();//content-type是浏览器回应我们的“暗号的一部分”
System.out.println("部分暗号:"+type);//
//这时,对过暗号之后,就可以开始发送请求的资源了。打开输入流,通过IO流,接收服务器发送的资源.
InputStream in=con.getInputStream();
byte[] buffer=new byte[1024];
int len=in.read(buffer,0,buffer.length);
System.out.println("资源内容:"+new String(buffer,0,len,"UTF-8"));//把资源以字符串的形式输出
}
}
执行结果:

我们看到,浏览器通过暗号告诉我们发送的资源类型是text/html文本。可以看到资源内容就是百度首页的源码。通过Java提供的IO流可以接受服务器发送的资源,但是我们的输出控制台只能显示这些文本(可能会乱码),而真正的浏览器可以把html文本配合JS等“翻译”成我们见到的飘飘亮亮的网页。
比如:

但是可以说,我们已经实现了爬虫。即----通过代码模拟浏览器向服务器请求资源,接受浏览器返回的资源。
Demo2
/**
* 模拟浏览器发送请求,接收数据
* @author luckyriver
*
*/
public class URL_Demo {
/**
* 以访问百度首页为例
* @throws Exception
*/
public static void main(String[] args) throws Exception {
//对应浏览器地址栏输入URL
URL url=new URL("https://cn.bing.com/th?id=OHR.Montreux_ZH-CN5485205583_1920x1080.jpg&rf=LaDigue_1920x1080.jpg");//创建URL对象,相信大家已经知道了什么是URL,构造方法传入想要访问的URL
//对应地址栏输入后点击连接
URLConnection con=url.openConnection();//调用URL对象的openConnection()方法,字面意思,打开连接,获得连接对象
String type=con.getContentType();//content-type是浏览器回应我们的“暗号的一部分”
System.out.println("部分暗号:"+type);//
//这时,对过暗号之后,就可以开始发送请求的资源了。打开输入流,通过IO流,接收服务器发送的资源.
InputStream in=con.getInputStream();
byte[] buffer=new byte[1024];
int len=in.read(buffer,0,buffer.length);
System.out.println("资源内容:"+new String(buffer,0,len,"UTF-8"));//把资源以字符串的形式输出
}
}
跟上面代码类似,只不过这次我们访问的URL变为必应首页的背景图
来看输出结果:
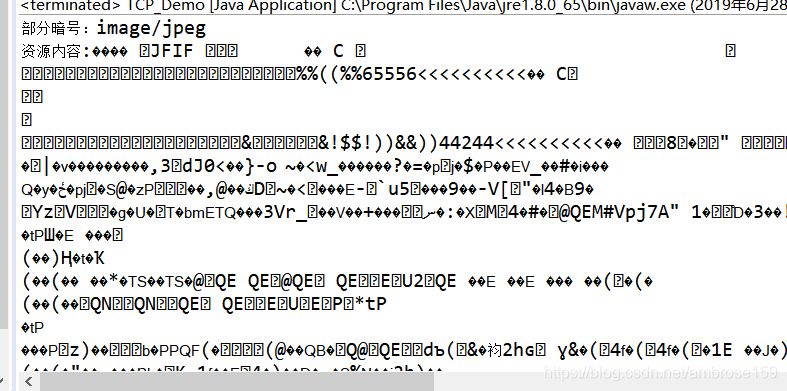
我们看到,服务器给我们的资源类型为image/jpeg,是图片资源,我们用字符串形式输出,肯定看不到图片,图片长这样。
那么我们如何得到这张图片呢?相信学过Java IO的你一定知道。
我们今天通过简单的例子阐述了爬虫的基本原理,下次我们来讨论更多的例子。














 780
780











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言










{kind=link}