







DIGIX 赛道B-整理
写在前面:本文是笔者最近参加华为举办的 2020 DIGIX赛道B 数码设备图像检索 的整理,本次比赛任务为基于图像的通用商品检索。笔者队伍最终取得亚军成绩。笔者对图像检索任务了解有限,如有理解错误的地方欢迎指正,不胜感激。
比赛主页:link
代码开源:link
0 团队介绍
- 团队名称:WEARE
- 团队成员:
- 刘洁锐:中国科学院自动化所,2019级研究生
- 林宏辉:华南理工大学电信学院,2019级研究生
- 柳宇非:华南理工大学电信学院,2019级研究生
1. 赛题简介
任务:给定商品图像,完成商品检索任务(以图搜图);
指标:score = 0.5 * top-1 acc + 0.5 * mAP10;
数据:官网详细描述
- 训练集:68811图像,共3097类;
- 选拔赛TestA:query 9600,gallery 49804;
- 选拔赛TestB:query 41574,gallery 95120;
- 精英赛: query 55168,gallery 29758;
限制:
- 不允许参赛选手对大赛测试数据集进行额外标注;
- 允许使用在ImageNet数据上训练的图像分类模型作为特征提取模型初始化,不允许使用除此之外的外部数据集或外部数据集训练的预训练模型;
- 测试数据集只允许用于测试,禁止在训练阶段以任何形式使用测试数据集;
- 模型大小限制500M上限;
难点:
- 区别于人脸、行人重认证等任务背景相对干净,视角比较统一,商品成像视角、旋转有多样性,特征对齐困难;
- 比赛数据集仅提供分类的标签,无法引入主体检测优化背景干扰较严重、或多主体时场景;
- 粗细粒度结合,手机、笔记本等商品外观高度相似,检索难度较大;
- 数据集中存在多种模式等噪声和非正常视角的商品旋转(主办方刻意添加),进一步加大检索难度;
- 买家秀、卖家秀存在较大的 gap;
- 训练集中存在ID重复问题,对 Triplet Loss、Arcface 等训练影响严重;

图1-1 商品旋转角度多样

图1-2 细粒度:左iPhone6,右iPhone6s

图1-3 多主体场景

图1-4 买家秀与卖家秀
2. 整体方案
本次比赛部分代码参考了 Strong Baseline[1]、 Fast ReID[2]、PyRetri[3],在此基础上,针对本次商品检索数据的特点进行拓展。下面将从数据预处理、模型和训练、模型推理、后处理四个方面展开。

图2-1 算法模块
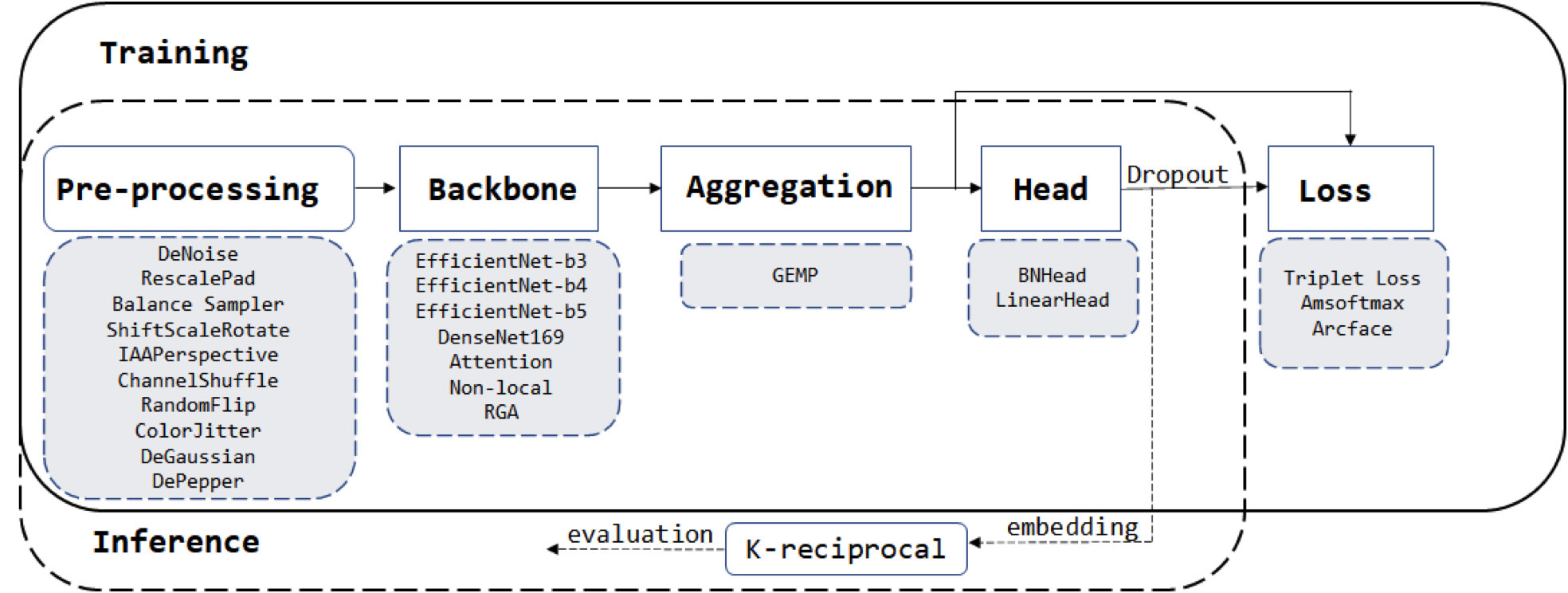
图2-2 整体算法框架
2.1 数据预处理
细粒度商品检索是一个较难的任务,数据预处理的目的是简化学习目标,修正样本分布、提高网络的泛化能力。
2.1.1 RescalePad
针对训练集中图像分辨率不统一问题,我们在保持物体形变情况下进行resize。具体操作是:padding 短边至长边相同大小,再resize到指定尺寸。本次比赛用了较大patch来保证图像细节信息,选拔赛时使用的显卡为1080Ti小水管,网络输入patch为512,决赛华为提供了较大显存的V100,使用了576、640等更大的分辨率。
2.1.2 Balance Sampler
针对数据中存在的类别不平衡问题,我们过滤了类别数少于2的样本,网络训练时,以类别为基本单位进行采样,每次采样 n 个类别,每个类别采样 m 个样本,所有类别采样,保证每个类别以相同的概率被抽样。实验中,不同的 n x m 采样的 batchsize 对实验结果有较大影响(2.2中讨论)。

图2-3 训练集类别不平衡
2.1.3 DeNoise
本次比赛数据中,存在较多人为添加的高斯噪声和椒盐噪声,还有少量模式未知的噪声。我们对模式较为固定的高斯噪声、椒盐噪声图像进行离线修复。
噪声图像修复:
-
对给定图像进行均值滤波,计算滤波前后图像 SSIM 相似度,若滤波前后 SSIM 相似度仍接近1,则大概率为正常图像,反之为噪声图像;
-
整图计算SSIM较为耗时,对分辨率较大的图像从原图 RandomCrop 500x500 patch;
-
高斯与椒盐的进一步区分可通过滤波前后像素绝对值差异,设置阈值进行区分,对高斯噪声图像进行双边滤波,对椒盐噪声图像进行中值滤波;
-
本方案优点是快,无需额外训练时间,遍历10+w 图像仅需 2h,缺点是对纹理丰富图像可能误检;

图2-4 中值滤波修复椒盐噪声图像

图2-5 双边滤波修复高斯噪声
2.1.4 数据增强
数据增强除了模拟商品颜色、旋转、形状、尺度等变化多样性外,针对2.1.3中噪声图像修复可能带来的边缘结构破坏问题(下图第2行,去噪后边缘信息被破坏),我们引入了DeGaussian和DePepper来提高网络的鲁棒性。本次比赛使用的数据增强有(图2-6第1行从左到右):IAAPerspective、ShiftScaleRotate、ChannelShuffle、RandomFlip、ColorJitter、DeGaussian。
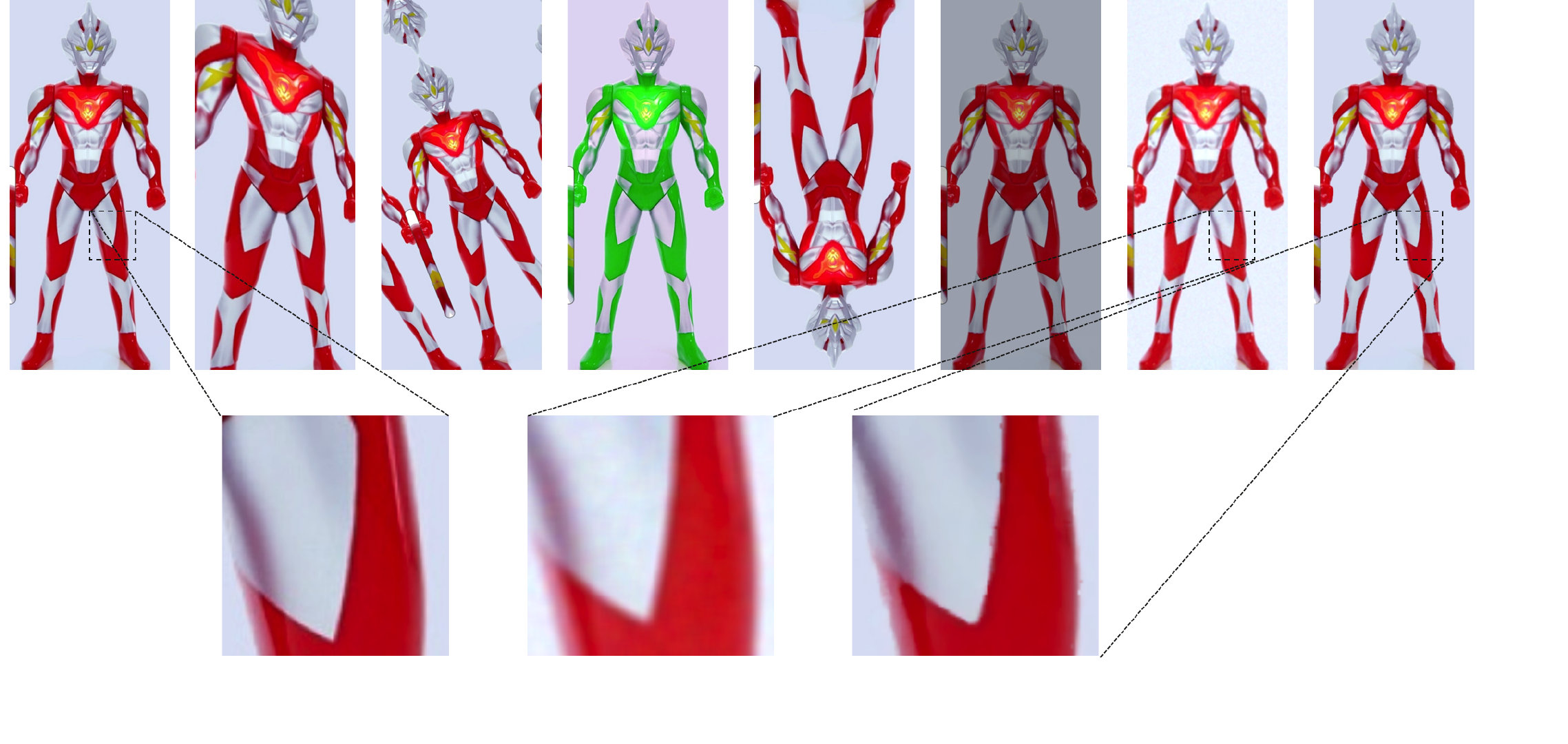
图2-6 第1行:数据增强可视化;第2行:噪声修复可能带来边缘结构破坏的问题
2.2 模型和训练
2.2.1 模型设计
由于比赛模型大小的限制,Backbone选择时优先考虑了参数量较少的EfficientNet和DenseNet。我们也测试过ResNet、ResNext、RegNet等网络,但在这次的数据中性能并不佳;Dropout 在这次的任务中提升显著,加上dropout和数据增强后,基本可以通过本地训练集acc预估线上分数。决赛时我们单模EfficientNet-B4,初赛时最佳单模是DenseNet169-RGA。
- BackBone: EfficientNet、DenseNet
- Pool:Generalized Mean Pooling[5]
- Head : BNHead[1]
- Loss : Triplet Loss + Arcface or Triplet Loss + Amsoftmax
- 正则化:dropout
- 其它组件:
- RGA[6]
- Nonlocal[7]
- IBN[8]
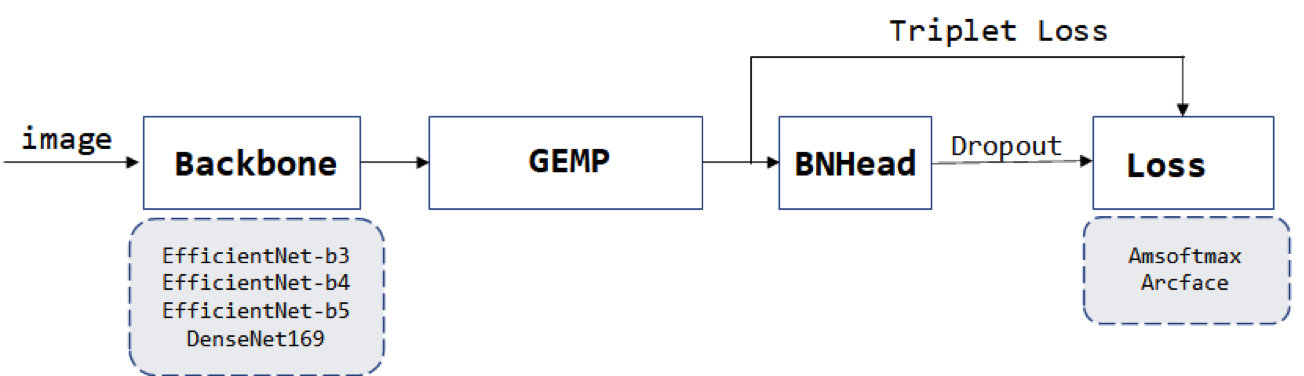
图2-7 模型结构
2.2.2 模型训练
2.2.2.1 mini-batch
对于Triplet Loss 这类损失函数,增大 mini-batch,更有利于困难样本的挖掘,加速网络收敛。但显存制约着batchsize增加。我们使用XBM[]来增大训练batch但有趣的实验现象:
- 开启XBM后,网络收敛确实加快,但并没有带来性能提升(甚至掉了一点点),在网络收敛的后期Triplet Loss依旧很高;
- 训练时,先开启XBM训练一段时间后,再关闭XBM(减小了batchsize)训练则网络性能有提升;
这里我们做了两个假设,一个是小batchsize训练的网络泛化性能更加,但在后续的对比实验证明并非如此。另一个假设是训练集可能存在重复的ID,盲目增大batchsize也增大了冲突概率。
我们通过一个简单的实验进行验证:对于Arcface、Amsoftmax训练收敛的分类网络,全连接层的每一行都可以视为网络学到的一个类别中心,各个类别中心余弦距离表征着类别之间的相似度。设置阈值对余弦相似度较高的类别中心进行聚类可视化可以发现,训练数据集中确实存在大量的重复ID。比如 ID-1908、ID-1528、ID-363、ID-2979(见图2-8)、ID-1475都为同款诺基亚手机,ID-770、ID-1205、ID-1082(见图2-9)都为同款华为手机。
由于本次比赛不允许选手进行额外的标注,咨询了官方人员是否可以进行数据清洗也没有得到明确的答复,在确定数据集含有重复ID的情况下,我们也无法对数据集进行清洗我们采取的方案是降低mini-batch中每次抽样的类别数n,而增大每个类别抽样数量m的方式来增大mini-batch。此外,由于重复ID的存在,Triplet Loss、Arcface等Loss margin取值也不应过大。

图2-8 同款手机但ID不同

图2-9 同款手机但ID不同
2.2.2.2 实验细节
超参数:根据选拔赛A榜进行调优。
- Triplet Loss:margin = 0.6,权重为1;
- Amsoftmax : margin = 0.35,scale = 30,权重为 0.25;
- Arcface : margin = 0.35,scale = 30,权重为 0.25;
- Dropout : p = 0.2;
训练加速:
- 使用 Pytorch 1.6 自动混合精度加速;
- 将 jpg 转 npy 加速IO;
- 参数冻结:DenseNet169只解冻最后2个Stage, Efficient-B3 冻结 15/25 block,B4冻结16/31 block, b5冻结20/38 block;
2.3 模型推理
2.3.1 尺度增强
推理时,增大 patch 为训练阶段1.1倍,以较小的计算代价换稳定的性能提升;
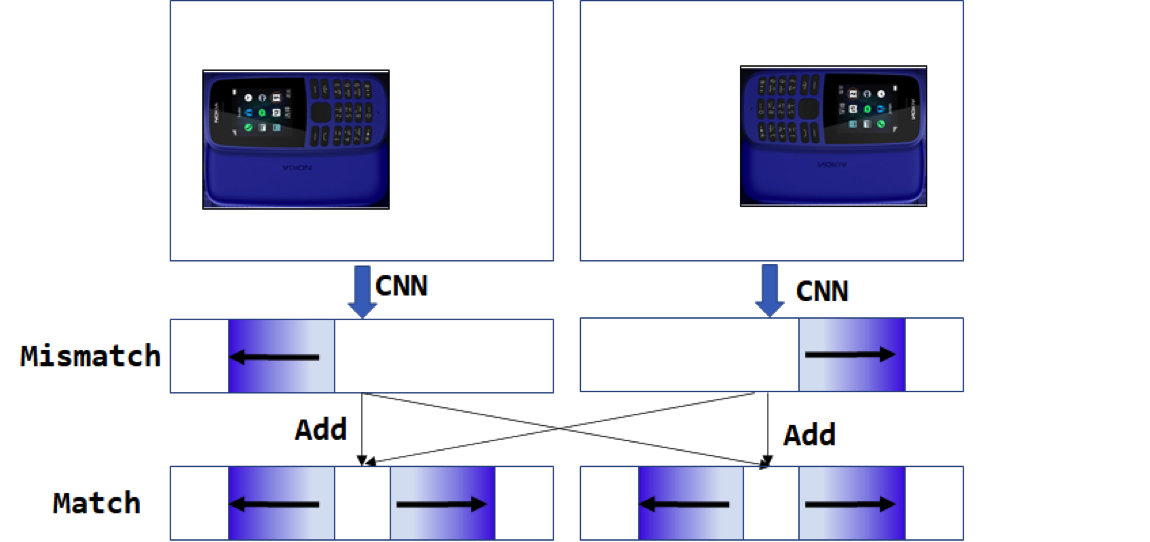
2.3.2 旋转特征对齐
商品角度旋转多样,而CNN对旋转不鲁棒,推理时将图像进行多个角度旋转预测,对得到的特征进行相加。
2.3.3 多主体场景优化
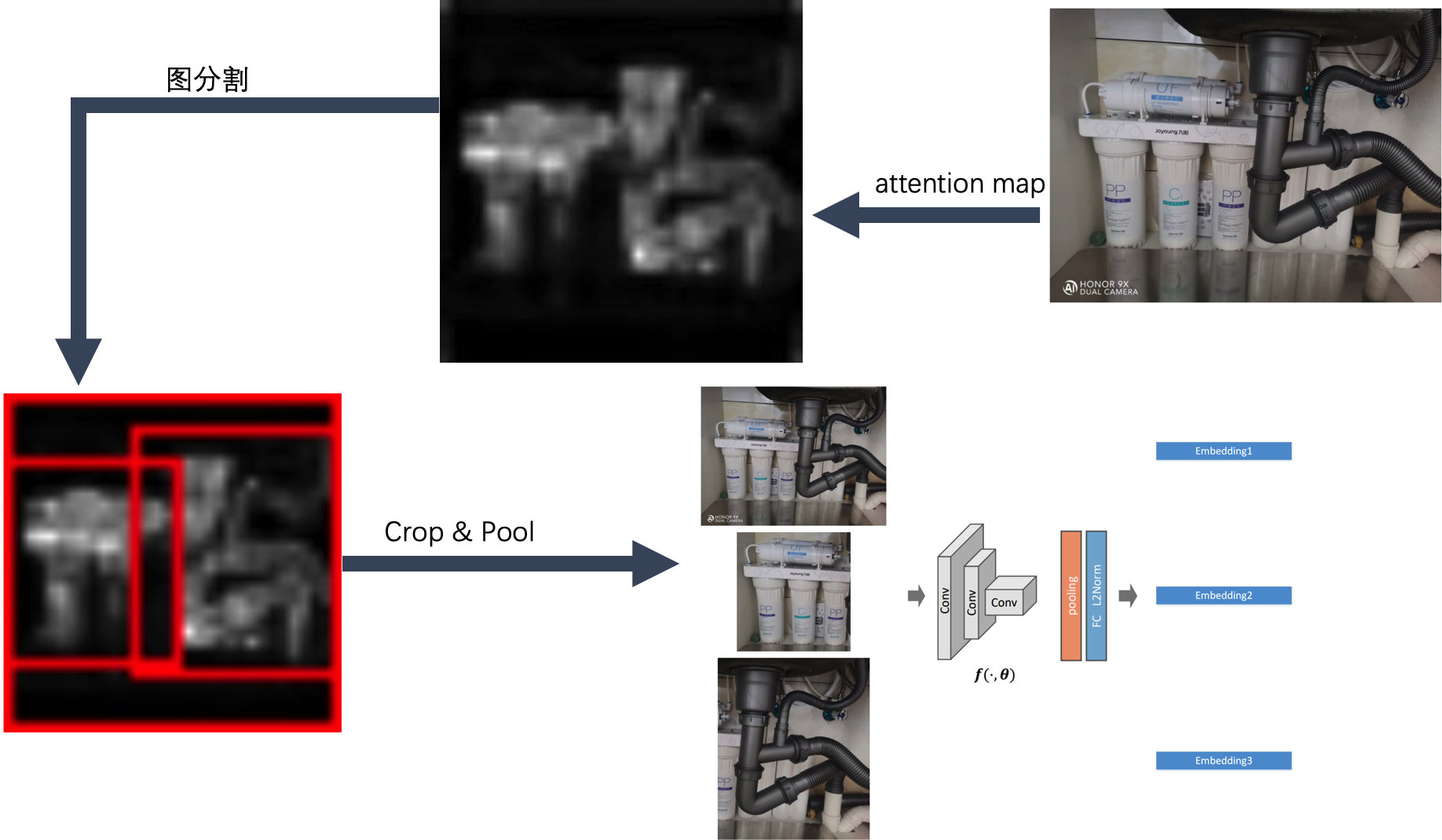
比赛后期上分到瓶颈期,通过统计发现存在部分样本,所有模型检索结果Top10几乎都不一致,这部分数据大概100+张,通过可视化总结,这部分样本大多为同个图像中存在多个主体、或者主体较小背景干扰严重。由于本次比赛不能引入额外的标注,我们无法引入额外的检测器进行主体检测再检索。我们尝试在仅使用attention map进行谱聚类的情况下进行主体检测,具体操作为:对于给定图像,计算attention map后进行阈值化处理,过滤出高响应的区域,对高响应区域像素进行 k=3 对最近邻建图,然后通过图切割得到多个子图,每个子图则大概率为一个主体,对切割得到的主体所在位置,对feature map 重新Crop & Pooling 再进行检索,最后对所有检测结果进行重排序。这部分优化虽然直接带来的结果提升不大,但对模型融合时提分显著。

优化前后检索结果差异:

2.4 后处理&模型融合
后处理:我们只做了 K-reciprocal,在 PyRetri基础上实现GPU加速(约加速3倍)和半精度优化(32g内存以内);
模型融合:我们使用加权投票的融合方式,统计检索结果中top10图像出现的频率及顺序(e.g. top1权重为1,top2权重为1/2 … );
3. 性能分析
性能:我们队伍取得了初赛第三、决赛第二的成绩,区别于其它队伍使用ResNest101、ResNest200 等较大网络的方案,我们的最佳单模 EfficientNet-B4参数量约为ResNet50的2/3,线上成绩为0.656;
时间:在提供的华为云线上环境中(16G V100),以EfficientNet-B4为例,我们训练时间约12h,推理时间约56min,检索&后处理约18min。
| 排名 | 队伍 | Score |
|---|---|---|
| 1 | 小天天 | 0.6622 |
| 2 | WEARE | 0.6614 |
| 3 | 保倒数第一,争倒数第二 | 0.6612 |
| 4 | 乘风破浪的妹妹们 | 0.6600 |

4. 引用
[1] Luo H, Jiang W, Gu Y, et al. A strong baseline and batch normalization neck for deep person re-identification[J]. IEEE Transactions on Multimedia, 2019.
[2] He L, Liao X, Liu W, et al. FastReID: a pytorch toolbox for general instance re-identification[J]. arXiv preprint arXiv:2006.02631, 2020.
[3] PyRetri: A PyTorch-based Library for Unsupervised Image Retrieval by Deep Convolutional Neural Networks[J]. arXiv preprint arXiv:2005.02154, 2020.
[4] Wang X, Zhang H, Huang W, et al. Cross-Batch Memory for Embedding Learning[C]. CVPR 2020.
[5] Radenović F, Tolias G, Chum O. Fine-tuning CNN image retrieval with no human annotation[J]. TPAMI 2018.
[6] Zhang Z, Lan C, Zeng W, et al. Relation-Aware Global Attention for Person Re-identification[C]. CVPR 2020.
[7] Wang X, Girshick R, Gupta A, et al. Non-local neural networks[C]. CVPR 2018.
[8] Pan X, Luo P, Shi J, et al. Two at once: Enhancing learning and generalization capacities via ibn-net[C]. ECCV 2018















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









