







文章目录
感谢极客时间-透视HTTP协议罗剑锋老师~
REST概念
REST,即Representational State Transfer的缩写。“表现层状态转化”。
如果一个架构符合REST原则,就称它为RESTful架构。
资源(Resources)
REST的名称"表现层状态转化"中,省略了主语。“表现层"其实指的是"资源”(Resources)的"表现层"。
所谓"资源",就是网络上的一个实体,或者说是网络上的一个具体信息。它可以是一段文本、一张图片、一首歌曲、一种服务,总之就是一个具体的实在。你可以用一个URI(统一资源定位符)指向它,每种资源对应一个特定的URI。要获取这个资源,访问它的URI就可以,因此URI就成了每一个资源的地址或独一无二的识别符。
所谓"上网",就是与互联网上一系列的"资源"互动,调用它的URI。
表现层(Representation)
“资源"是一种信息实体,它可以有多种外在表现形式。我们把"资源"具体呈现出来的形式,叫做它的"表现层”(Representation)。
比如,文本可以用txt格式表现,也可以用HTML格式、XML格式、JSON格式表现,甚至可以采用二进制格式;图片可以用JPG格式表现,也可以用PNG格式表现。
URI只代表资源的实体,不代表它的形式。严格地说,有些网址最后的".html"后缀名是不必要的,因为这个后缀名表示格式,属于"表现层"范畴,而URI应该只代表"资源"的位置。它的具体表现形式,应该在HTTP请求的头信息中用Accept和Content-Type字段指定,这两个字段才是对"表现层"的描述。
状态转化(State Transfer)
访问一个网站,就代表了客户端和服务器的一个互动过程。在这个过程中,势必涉及到数据和状态的变化。
互联网通信协议HTTP协议,是一个无状态协议。这意味着,所有的状态都保存在服务器端。因此,如果客户端想要操作服务器,必须通过某种手段,让服务器端发生"状态转化"(State Transfer)。而这种转化是建立在表现层之上的,所以就是"表现层状态转化"。
客户端用到的手段,只能是HTTP协议。具体来说,就是HTTP协议里面,四个表示操作方式的动词:GET、POST、PUT、DELETE。它们分别对应四种基本操作:GET用来获取资源,POST用来新建资源(也可以用于更新资源),PUT用来更新资源,DELETE用来删除资源。
HTTP
网络分层模型
1、OSI七层模型
- 第一层:物理层,网络的物理形式,例如电缆、光纤、网卡、集线器等等;
- 第二层:数据链路层,它基本相当于 TCP/IP 的链接层;
- 第三层:网络层,相当于 TCP/IP 里的网际层;
- 第四层:传输层,相当于 TCP/IP 里的传输层;
- 第五层:会话层,维护网络中的连接状态,即保持会话和同步;
- 第六层:表示层,把数据转换为合适、可理解的语法和语义;
- 第七层:应用层,面向具体的应用传输数据。

2、TCP/IP 四层模型

- 第一层:链路层,MAC 层的传输单位是帧(frame)
- 第二层:网络层,IP 层的传输单位是包(packet)
- 第三层:传输层,TCP 层的传输单位是段(segment)
- 第四层:应用层,HTTP 的传输单位则是消息或报文(message)
请求方法
标准请求方法
对于资源的具体操作类型,由HTTP动词表示。
目前 HTTP/1.1 规定了八种方法,单词都必须是大写的形式
- GET:获取资源,可以理解为读取或者下载数据;
- HEAD:HEAD 方法是轻量级的 GET,用来获取资源的元信息;
- POST:向资源提交数据,相当于写入或上传数据(理解成sql中的insert);
- PUT:基本上是 POST 的同义词,多用于更新数据(可以理解成sql中的update);
- DELETE:删除资源;
- CONNECT:建立特殊的连接隧道;
- OPTIONS:列出可对资源实行的方法;
- TRACE:追踪请求 - 响应的传输路径。
安全与幂等
1.安全
在 HTTP 协议里,所谓的“安全”是指请求方法不会“破坏”服务器上的资源,即不会对服务器上的资源造成实质的修改。
按照这个定义,只有 GET 和 HEAD 方法是“安全”的,因为它们是“只读”操作,只要服务器不故意曲解请求方法的处理方式,无论 GET 和 HEAD 操作多少次,服务器上的数据都是“安全的”。
而 POST/PUT/DELETE 操作会修改服务器上的资源,增加或删除数据,所以是“不安全”的。
2.幂等
所谓的“幂等”实际上是一个数学用语,被借用到了 HTTP 协议里,意思是多次执行相同的操作,结果也都是相同的,即多次“幂”后结果“相等”。
很显然,GET 和 HEAD 既是安全的也是幂等的,DELETE 可以多次删除同一个资源,效果都是“资源不存在”,所以也是幂等的。
POST 和 PUT 的幂等性质就略费解一点。 按照 RFC 里的语义,
POST 是“新增或提交数据”,多次提交数据会创建多个资源,所以不是幂等的;
而 PUT 是“替换或更新数据”,多次更新一个资源,资源还是会第一次更新的状态,所以是幂等的。
报文结构
1、请求/响应报文结构

HTTP 协议的请求报文和响应报文的结构基本相同,由三大部分组成:
- 起始行(start line):描述请求或响应的基本信息;
- 头部字段集合(header):使用 key-value 形式更详细地说明报文;
- 消息正文(entity):实际传输的数据,它不一定是纯文本,可以是图片、视频等二进制数据。
2、请求行
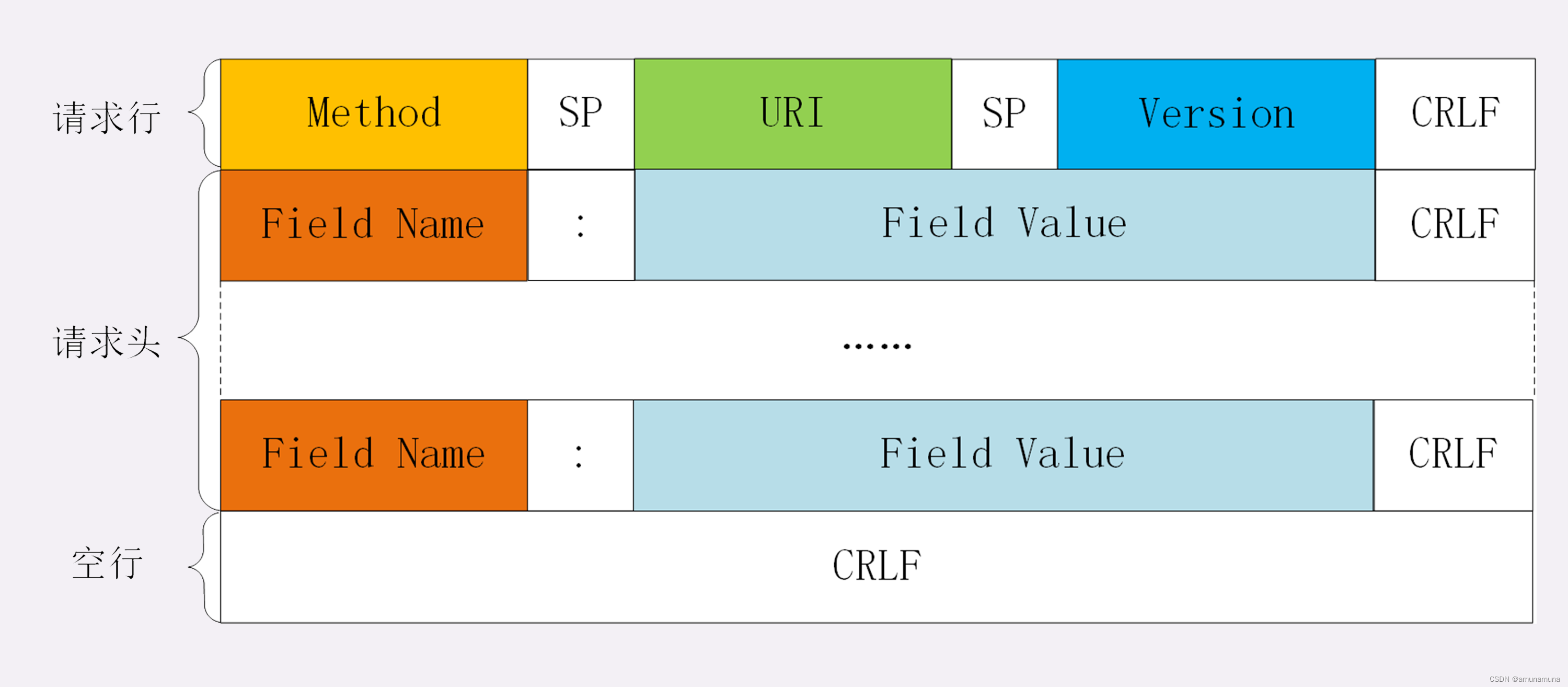
请求行由三部分构成:
- 请求方法:是一个动词,如 GET/POST,表示对资源的操作;
- 请求目标:通常是一个 URI,标记了请求方法要操作的资源;
- 版本号:表示报文使用的 HTTP 协议版本。
3、状态行-服务器响应的状态
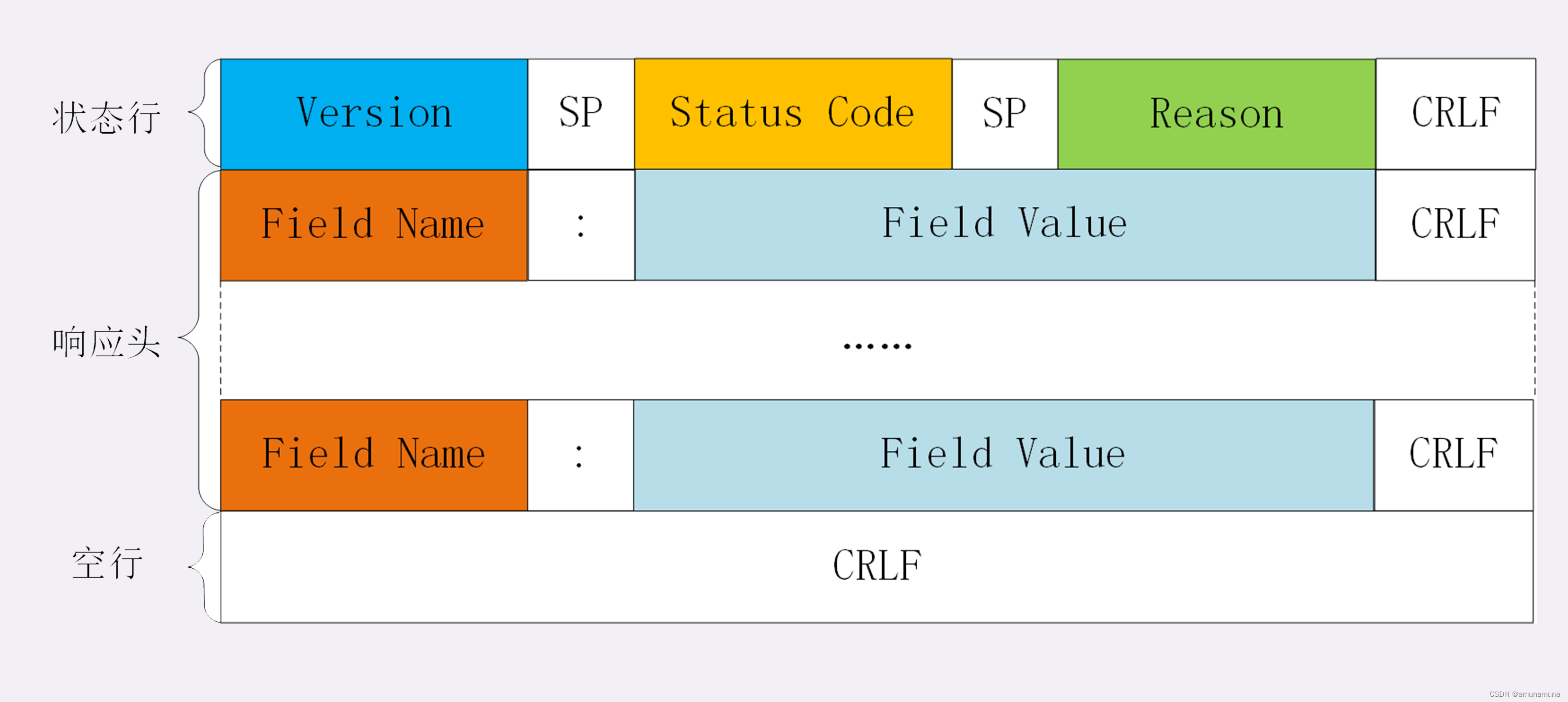
状态行由三部分构成:
- 版本号:表示报文使用的 HTTP 协议版本;
- 状态码:一个三位数,用代码的形式表示处理的结果,比如 200 是成功,500 是服务器错误;
- 原因:作为数字状态码补充,是更详细的解释文字,帮助人理解原因。
4、头部字段
头部字段是 key-value 的形式,key 和 value 之间用“:”分隔,最后用 CRLF 换行表示字段结束。
HTTP的实体数据
MIME type
多用途互联网邮件扩展”(Multipurpose Internet Mail Extensions),简称为 MIME。
MIME 是一个很大的标准规范,但 HTTP 只“顺手牵羊”取了其中的一部分,用来标记 body 的数据类型,这就是我们平常总能听到的“MIME type”。
- text:即文本格式的可读数据,我们最熟悉的应该就是 text/html 了,表示超文本文档,此外还有纯文本 text/plain、样式表 text/css 等。
- image:即图像文件,有 image/gif、image/jpeg、image/png 等。
- audio/video:音频和视频数据,例如 audio/mpeg、video/mp4 等。
- application:数据格式不固定,可能是文本也可能是二进制,必须由上层应用程序来解释。常见的有 application/json,application/javascript、application/pdf 等,另外,如果实在是不知道数据是什么类型,像刚才说的“黑盒”,就会是 application/octet-stream,即不透明的二进制数据。
Encoding type
但仅有 MIME type 还不够,因为 HTTP 在传输时为了节约带宽,有时候还会压缩数据,为了不要让浏览器继续“猜”,还需要有一个“Encoding type”,告诉数据是用的什么编码格式,这样对方才能正确解压缩,还原出原始的数据。
比起 MIME type 来说,Encoding type 就少了很多,常用的只有下面三种:
- gzip:GNU zip 压缩格式,也是互联网上最流行的压缩格式;
- deflate:zlib(deflate)压缩格式,流行程度仅次于 gzip;
- br:一种专门为 HTTP 优化的新压缩算法(Brotli)。
HTTP的长连接与短连接
- 早期的 HTTP 协议使用短连接,收到响应后就立即关闭连接,效率很低;
- HTTP/1.1 默认启用长连接,在一个连接上收发多个请求响应,提高了传输效率;
- 服务器会发送“Connection: keep-alive”字段表示启用了长连接;
- 报文头里如果有“Connection: close”就意味着长连接即将关闭;
- 过多的长连接会占用服务器资源,所以服务器会用一些策略有选择地关闭长连接;
- “队头阻塞”问题会导致性能下降,可以用“并发连接”和“域名分片”技术缓解。
HTTP的重定向和跳转
- 重定向是服务器发起的跳转,要求客户端改用新的 URI 重新发送请求,通常会自动进行,用户是无感知的;
- 301/302 是最常用的重定向状态码,分别是“永久重定向”和“临时重定向”;
- 响应头字段 Location 指示了要跳转的 URI,可以用绝对或相对的形式;
- 重定向可以把一个 URI 指向另一个 URI,也可以把多个 URI 指向同一个 URI,用途很多;
- 使用重定向时需要当心性能损耗,还要避免出现循环跳转。
HTTP的cookie机制
- Cookie 是服务器委托浏览器存储的一些数据,让服务器有了“记忆能力”;
- 响应报文使用 Set-Cookie 字段发送“key=value”形式的 Cookie 值;
- 请求报文里用 Cookie 字段发送多个 Cookie 值;
- 为了保护 Cookie,还要给它设置有效期、作用域等属性,常用的有 Max-Age、Expires、Domain、HttpOnly 等;
- Cookie 最基本的用途是身份识别,实现有状态的会话事务。
HTTP的缓存控制
- 缓存是优化系统性能的重要手段,HTTP 传输的每一个环节中都可以有缓存;
- 服务器使用“Cache-Control”设置缓存策略,常用的是“max-age”,表示资源的有效期;
- 浏览器收到数据就会存入缓存,如果没过期就可以直接使用,过期就要去服务器验证是否仍然可用;
- 验证资源是否失效需要使用“条件请求”,常用的是“if-Modified-Since”和“If-None-Match”,收到 304 就可以复用缓存里的资源;
- 验证资源是否被修改的条件有两个:“Last-modified”和“ETag”,需要服务器预先在响应报文里设置,搭配条件请求使用;
- 浏览器也可以发送“Cache-Control”字段,使用“max-age=0”或“no_cache”刷新数据。
URI与URL的区别
URL——统一资源定位符(Uniform Resource Locator)
URI-统一资源标识符(Uniform Resource Identifier)
URI常用格式
scheme 😕/ host:port path ? query
- scheme:协议名
- host:port 资源所在主机名,地址+端口,如果不写端口,浏览器使用默认的端口
- path:资源所在位置,必须以“/”开始
- query: 查询参数,以“?”开始,但不包含“?”。key=value字符串,用&连接
状态码
- 1××:提示信息,表示目前是协议处理的中间状态,还需要后续的操作;
- 2××:成功,报文已经收到并被正确处理;
- 3××:重定向,资源位置发生变动,需要客户端重新发送请求;
- 4××:客户端错误,请求报文有误,服务器无法处理;
- 5××:服务器错误,服务器在处理请求时内部发生了错误。
URI包含动词
因为"资源"表示一种实体,所以应该是名词,URI不应该有动词,动词应该放在HTTP协议中。
URI中加入版本号
http://www.example.com/app/1.0/foo
http://www.example.com/app/1.1/foo
http://www.example.com/app/2.0/foo
因为不同的版本,可以理解成同一种资源的不同表现形式,所以应该采用同一个URI。
版本号可以在HTTP请求头信息的Accept字段中进行区分(参见Versioning REST Services):
Accept: vnd.example-com.foo+json; version=1.0
Accept: vnd.example-com.foo+json; version=1.1
Accept: vnd.example-com.foo+json; version=2.0















 4516
4516











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









