






点击下方卡片,关注“CVer”公众号
AI/CV重磅干货,第一时间送达
作者:zt1999(源:知乎)| 编辑:CVer
https://zhuanlan.zhihu.com/p/645334685
更详细的对比结果如下:

PR一下团队 ICCV2023 中稿的视频实例分割工作DVIS。DVIS在OVIS、YouTube-VIS、VIPSeg等数据集上均取得了SOTA表现。DVIS在OVIS数据集上从2月霸榜至今,并在CVPR 2023的 2nd Pixel-level Video Understanding in the Wild Challenge (Video Panoptic Segmentation Track) 中取得了冠军。
DVIS: Decoupled Video Instance Segmentation Framework
Paper:https://arxiv.org/pdf/2306.03413
Code:https://github.com/zhang-tao-whu/DVIS
主要特性
DVIS可以实现视频通用分割,可以处理视频实例分割(VIS)、视频语义分割(VSS)以及视频全景分割(VPS)三大任务。
DVIS可以在online以及offline模式下运行。
解耦的设计使得DVIS训练所需要的计算资源较少。
DVIS在多个VIS以及VPS的数据集上均取得SOTA性能。
效果展示:

任务简介
视频实例分割(Video Instance Segmentation, VIS)由图像实例分割任务扩展而来,旨在同时分割、检测、追踪视频中的所有实例,是一项比图像实例分割更具挑战的基础任务,对于自动驾驶、图像编辑等下游任务有着重要作用。视频语义分割(Video Semantic Segmentation, VSS)同样由图像语义分割扩展而来,其要求对视频所有的语义类进行分割并在时间维度上保持时序稳定性。视频全景分割(Video Panoptic Segmentation, VPS)可以看做视频实例分割与视频语义分割的结合,对于视频中的"thing"与"stuff"目标都要求进行分割与追踪。
研究背景以及Motivation
近年来,Transformer[1]在CV中各个领域被广泛应用。DETR[2]作为基于Transformer的经典工作之一,在图像目标检测、图像实例分割领域展现出了强大的潜力。相比于基于ROI的实例表征方式,DETR所采用的基于Query的实例表征方式展现出了更强劲的表征能力以及灵活性。受到图像目标检测领域进展的启发,VisTR首次将Transformer应用于VIS领域,展现出了巨大的性能提升。随后基于Transformer的方法在VIS领域成为了主流。
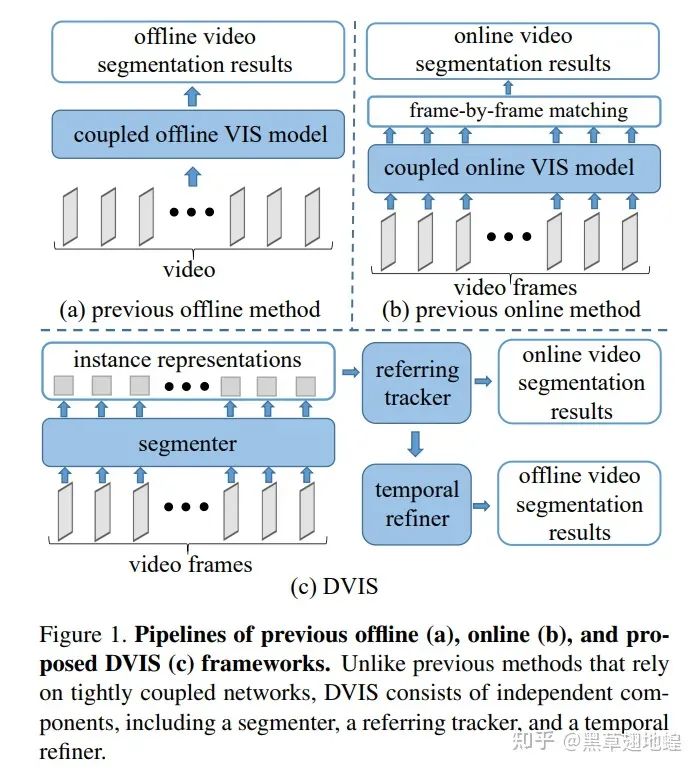
目前视频分割领域的方法可以分为在线(online)与离线(offline)方法。在线方法在预测当前帧结果时以当前帧及历史帧作为输入,主要应用于需要实时处理的需求场景,如自动驾驶中的实时感知。离线方法在预测当前帧结果时可以利用视频中任意帧作为输入,主要应用于离线处理的需求场景,如视频编辑等。
现有的SOTA的online方法(MinVIS[3]、IDOL[4]等)遵循着先执行图像分割后逐帧关联实例的技术路线。这种技术路线并未根据其他帧的信息来优化当前帧的分割结果,因此缺乏对于视频信息的有效利用。
现有的SOTA的offline方法(SeqFormer[5]、Mask2Former-VIS[6]、VITA[7]、IFC[8]等)采用一个紧耦合网络来端到端地处理视频分割任务。虽然这种技术路线理论上可以更加有效地利用视频信息,但是在长视频以及复杂场景中,性能却不尽人意。如以下视频所示,当视频中出现很多个同类目标发生相互遮挡换位等情况时,Mask2Former-VIS的目标跟踪结果出现错乱,分割精度也受到影响。

offline方法相比于online方法可以利用更多的信息,因此理论上应该有着更好的表现。然而事实并非如此,在复杂场景下现有的offline方法的性能显著低于online方法。我们认为这是由于现有的offline方法对实例表征的设定所导致的。现有的offline方法采用单一的可学习的query来表征视频中的一个实例,这种可学习的query可以被看作位置以及大小先验。然而在实际场景中,某个实例的表观和空间位置都可能发生大幅变化,因此仅靠位置与大小先验很难从所有帧中都探测到该实例的正确特征。正如上面视频demo所示,3号query(红色掩码覆盖)学习到的先验位置信息处在视频的右侧,然而视频前段所标记的大象在视频结束时已运动至视频左侧。
那么如何充分利用视频信息以使得offline方法发挥出理论上应有的潜力?我们尝试在DVIS中回答了该问题。既然直接建模实例在整个视频上的表征是困难的,那么是否可以首先在单帧中建模实例,然后逐帧关联实例来获取同一实例在所有帧的表征,最后再对实例的时序信息加以利用。毫无疑问,逐帧关联的难度要比直接关联所有视频帧上的同一实例小得多。在给出时间上良好对齐的实例特征的情况下,有效地对这些特征加以利用也是轻而易举的。
此时,DVIS的架构呼之欲出,我们将VIS任务分解为图像分割、物体关联、时序精化三个子步骤,相应的我们分别设计segmenter、tracker和refiner三个网络模块来处理这三个子步骤。其中图像分割即为在单帧中分割出目标并获取目标的表征。物体关联即为关联相邻帧的目标表征,为refiner提供一个良好对齐的初值。时序精化即为基于对齐好的物体时序信息来优化物体的分割结果以及追踪结果。
方法简介
当DVIS的架构确定好后,我们需要针对图像分割、物体关联、时序精化三个子步骤分别设计合理的segmenter、tracker以及refiner网络。图像分割子步骤中,我们采用了SOTA的图像通用分割网络Mask2Former作为segmenter来提取物体的表征;物体关联子步骤中,我们将追踪建模为参考去噪/重建任务,并设计了Referring Tracker来进行稳健的目标关联;在时序精化子步骤中,我们基于1D卷积以及Self Attention实现了Temporal Refiner来有效地利用物体的时序信息。
1. Referring Tracker
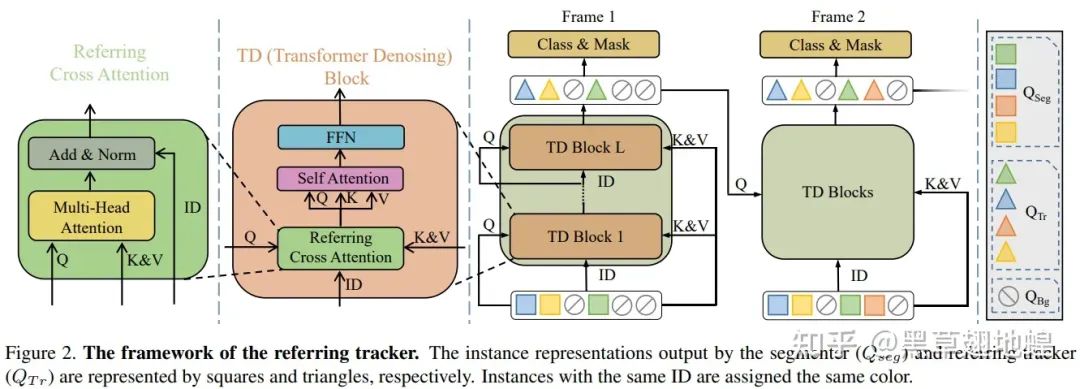
DVIS将相邻帧物体的关联任务建模为根据上一帧物体query来重建当前帧对应的物体query,即给定上一帧物体的query作为reference query,然后从segmenter输出的当前帧的object query中聚合信息,最后输出reference query相应的实例在当前帧的掩码和类别。Referring Tracker通过Referring Cross Attention来学习以上过程。Referring Cross Attention充分利用refrence query来指导信息的聚合并阻隔了reference query与当前信息的混杂,其由标准Cross Attention稍作改动而得到:
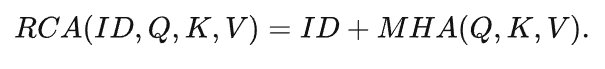
2. Temporal Refiner
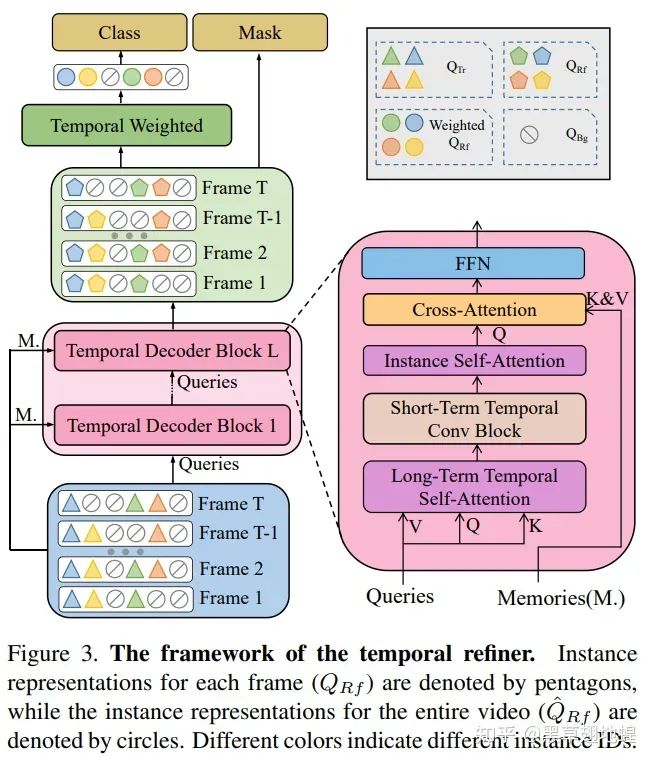
在Referring Tracker输出在时间维度上基本对齐的目标query后,就可以很容易的通过标准操作(如1D卷积以及Self Attention)来对时序特征进行有效利用。我们设计的Temporal Refiner也非常简单,由1D卷积以及Self Attention来聚合时序特征。Temporal Refiner基于物体的时序特征来优化分割结果以及追踪结果。
值得一提的是DVIS的设计很灵活,Referring Tracker可以叠加于任何query-based的图像分割器来实现在线的视频分割,Temporal Refiner同样可以叠加于任何在线的视频分割器来获取更强大的分割性能。
实验结果
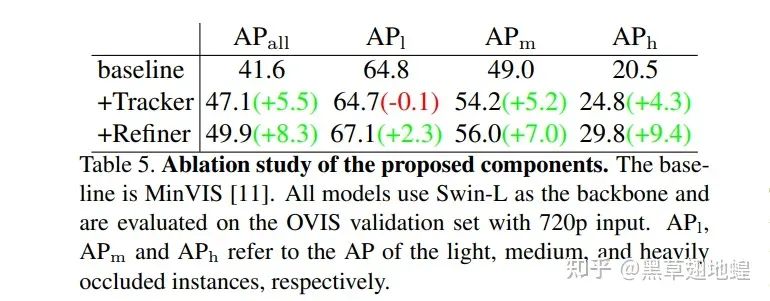
我们在OVIS数据集上对于Referring Tracker和Temporal Refiner的作用进行了消融实验。Tracker的主要作用是实现更鲁棒的目标关联,尤其是对于中度遮挡和重度遮挡的物体有较大改善(如下表所示,为中度遮挡以及重度遮挡的目标分别带来了5.2 AP和4.3 AP的性能提升)。Refiner的主要作用是充分利用时序信息,结果显示由于时序信息的有效利用,Temporal Refiner对于被轻度、中度、重度遮挡物体的性能都有显著提升(如下表所示,为轻度、中度以及重度遮挡的目标分别带来了2.4 AP和1.8 AP和5.1 AP的性能提升)。
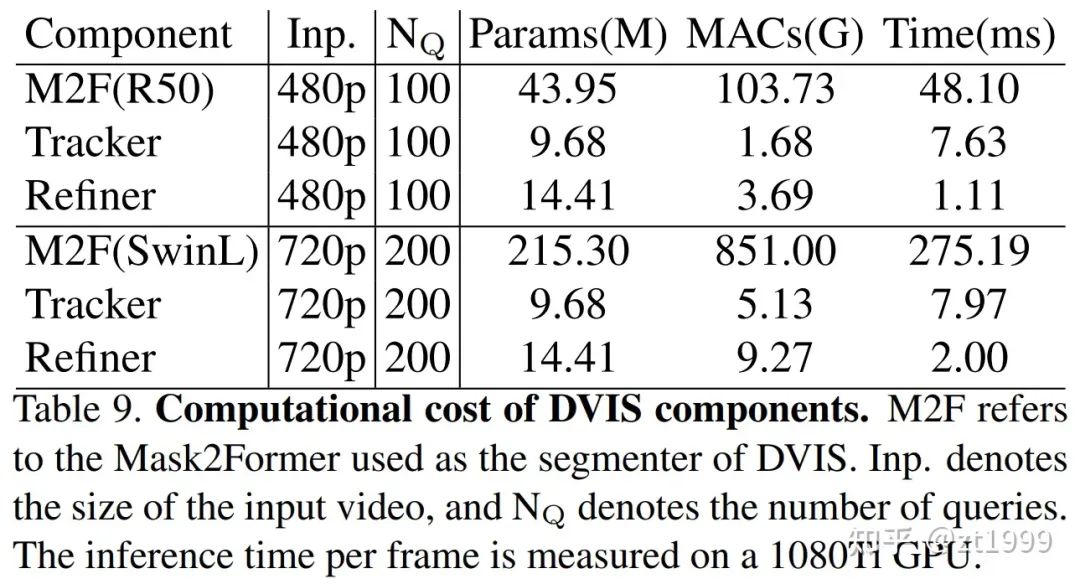
并且,由于Referring Tracker和Temporal Refiner仅处理object query,因此计算代价很小,计算量总和少于Segmenter的5%(见下表):
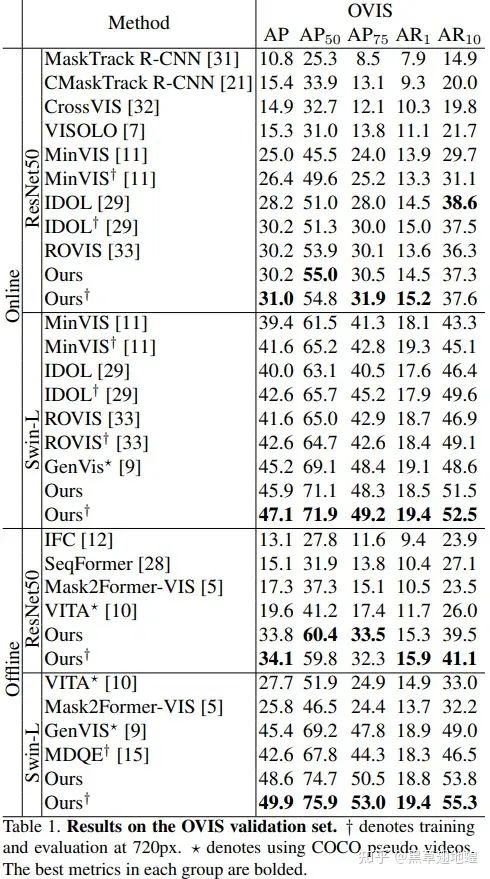
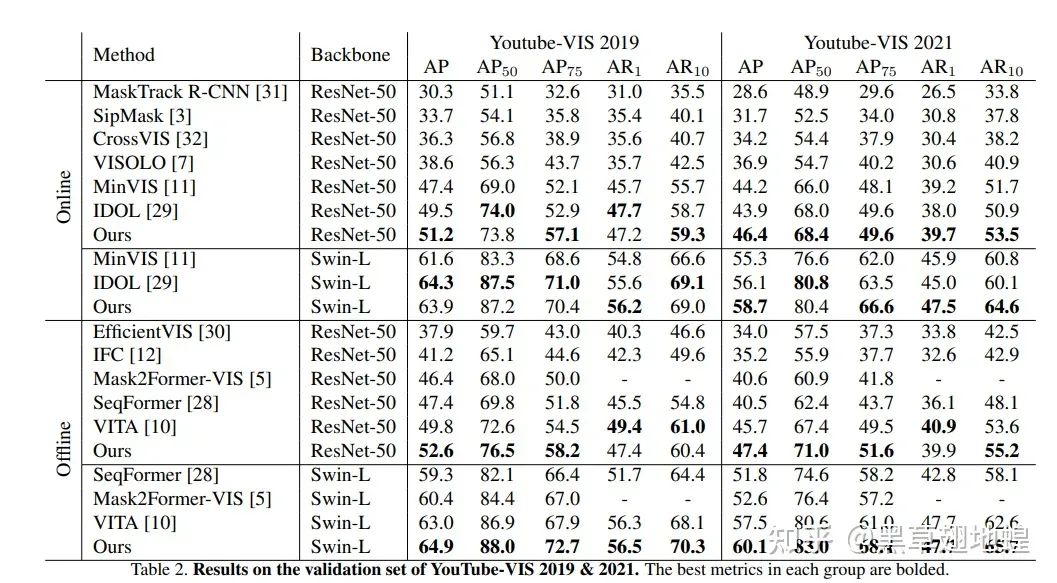
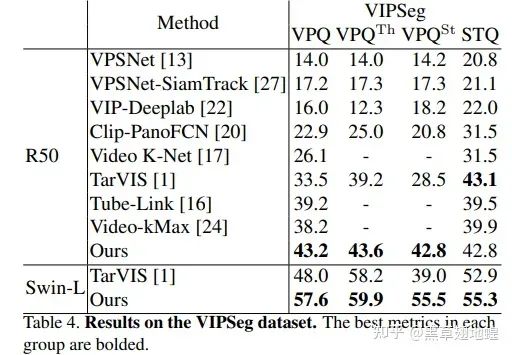
DVIS在OVIS、YouTube-VIS(2019,2021)以及VIPSeg等数据集上均取得SOTA:
| Dataset | OVIS | YTVIS19 | YTVIS21 | VIPSeg |
|---|---|---|---|---|
| 之前SOTA | 45.4 AP (GenVIS,CVPR2023) | 64.3 AP (IDOL,ECCV2022) | 59.6 AP (GenVIS, CVPR2023) | 48.0 VPQ (TarVIS, CVPR2023) |
| DVIS | 49.9 AP | 64.9 AP | 60.1 AP | 57.6 VPQ |
| 涨幅 | +4.5 | +0.6 | +0.5 | +9.4 |
结论
在本文中,我们提出了DVIS,一种将VIS任务解耦的框架,将VIS任务分为三个子任务:分割,跟踪和细化。我们的贡献有三个方面:1)我们将解耦策略引入了VIS任务并提出了DVIS框架,2)我们提出了Referring Tracker,通过将帧间关联建模为引用去噪来增强跟踪的鲁棒性,3)我们提出了Temporal Refiner,利用整个视频的信息来精化分割结果,弥补了之前工作在这方面的缺失。结果表明,DVIS在所有VIS数据集上实现了SOTA性能。
虽然DVIS的设计来源于对VIS领域内既有方法不足的反思,但是DVIS的设计并不局限于视频实例分割领域,其可以无任何改动的在VIS,VPS和VSS上都取得SOTA性能,这证明了DVIS的通用性与强大潜力。我们希望,DVIS将成为一个强大且基础的基准,并且我们的解耦洞见将激发在线和离线VIS领域的未来研究。
参考文献
[1] Attention Is All You Need. NeurIPS2017
[2] End-to-End Object Detection with Transformers. ECCV2020
[3] MinVIS: A Minimal Video Instance Segmentation Framework without Video-based Training. NeurIPS2022
[4] In Defense of Online Models for Video Instance Segmentation.ECCV 2022
[5] SeqFormer: a Frustratingly Simple Model for Video Instance Segmentation. ECCV 2022
[6] Mask2Former for Video Instance Segmentation.
[7] Video Instance Segmentation via Object Token Association. NeurIPS2022
[8] Video Instance Segmentation using Inter-Frame Communication Transformers. NeurIPS2021
[9] A generalized framework for video instance segmentation. CVPR2023.
[10] Tarvis: A unified approach for target-based video segmentation. CVPR2023.
ICCV / CVPR 2023论文和代码下载
后台回复:CVPR2023,即可下载CVPR 2023论文和代码开源的论文合集
后台回复:ICCV2023,即可下载ICCV 2023论文和代码开源的论文合集图像分割和论文投稿交流群成立
扫描下方二维码,或者添加微信:CVer333,即可添加CVer小助手微信,便可申请加入CVer-图像分割或者论文投稿 微信交流群。另外其他垂直方向已涵盖:目标检测、图像分割、目标跟踪、人脸检测&识别、OCR、姿态估计、超分辨率、SLAM、医疗影像、Re-ID、GAN、NAS、深度估计、自动驾驶、强化学习、车道线检测、模型剪枝&压缩、去噪、去雾、去雨、风格迁移、遥感图像、行为识别、视频理解、图像融合、图像检索、论文投稿&交流、PyTorch、TensorFlow和Transformer等。
一定要备注:研究方向+地点+学校/公司+昵称(如图像分割或者论文投稿+上海+上交+卡卡),根据格式备注,可更快被通过且邀请进群
▲扫码或加微信号: CVer333,进交流群
CVer计算机视觉(知识星球)来了!想要了解最新最快最好的CV/DL/AI论文速递、优质实战项目、AI行业前沿、从入门到精通学习教程等资料,欢迎扫描下方二维码,加入CVer计算机视觉,已汇集数千人!
▲扫码进星球
▲点击上方卡片,关注CVer公众号整理不易,请点赞和在看![]()


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









