






点击下方卡片,关注“CVer”公众号
AI/CV重磅干货,第一时间送达
作者:王利民(源:知乎,已授权)| 编辑:CVer
https://zhuanlan.zhihu.com/p/662160485
在CVer微信公众号后台回复:MeMOTR,可以下载本论文pdf、代码,学起来!

代码:https://github.com/MCG-NJU/MeMOTR
论文:https://arxiv.org/abs/2307.15700
研究动机
多目标跟踪(Multiple Object Tracking,MOT)是计算机视觉尤其是视频理解中的一个重要任务,主要目标是定位目标并且在连续的视频帧中保持他们各自的身份信息(ID)。其可以用于包括动作识别、行为分析、运动估计在内的诸多下游任务中,同时在许多应用场景中的关键技术,例如自动驾驶、安防监控等。
多目标跟踪作为一个连续的视频处理任务,时序信息自然是至关重要的。但是在目前的绝大多数方法中,他们往往只显式利用了相邻两帧的视觉信息,这样缺失了对更长时的视觉信息的利用。在 Transformer-based(query-based)方法中,track query 承担了表示和向后传递已跟踪目标的任务,我们认为对于每一个目标的 track query 来说,其应该具有如下良好的特性:
同一个 ID 所对应的 track query 随时间的变化应该尽可能平滑,因为对于视频中的目标来说,他们在帧与帧之间的变化往往是缓慢细微的、不易突变的。
不同 ID 所对应的 track query 应该尽可能可区分,这样有利于在后续帧中对不同目标进行更好的定位,减少 ID 错误的情况。
从以上两点出发,我们基于现有的 query-based 多目标跟踪方法(MOTR[1])提出了如下的主要改进:
将长时记忆(Long-Term Memory)注入到 track query 中,以获取更加稳定的特征表示。
构建了 Memory-Attention Layer,利用 self-attention 使不同 ID 的目标之间进行响应,从而获取更加可区分的特征表示。
此外,我们还观察到了在现有框架下,detect query 和 track query 之间的特征语义不对齐问题。因此将第一层 DETR Decoder 作为 detection only 模式,使其与来自上一帧的 track query 尽可能对齐,从而减少特征不对齐所产生的负面影响。
背景介绍
多目标跟踪的流程拆分成为目标检测和目标关联(object association)两个部分,在很长一段时间内,Tracking-by-Detection(TBD)范式都广受好评,并且在行人跟踪数据集上(MOT17、MOT20)取得了傲人的成绩。但是这些数据集中目标的运动模式往往都较为简单(行人的运动接近线性运动),致使许多 Tracking-by-Detection 方法都陷入了线性运动的强先验中。尤其是在近期的一些更加复杂和多变的场景中(如 DanceTrack),简单的线性运动假设无法取得令人满意的效果。
而随着 DETR 范式在目标检测领域的火爆,其代表的 query-based 思想也被许多研究者扩展到了多目标跟踪领域,例如 TrackFormer[2]、MOTR[1]、TransTrack[3] 等工作。尽管在传统的行人跟踪数据集上,由于目标密度等问题,并没能超过现有最优的 Tracking-by-Detection 算法(例如 ByteTrack[4],OC-SORT[5]),但是得益于 Transformer 的灵活性以及较少的特定先验,其在 DanceTrack 这类复杂场景下取得了较好的成绩。
Transformer-based(query-based)的现有做法一般所示如下:
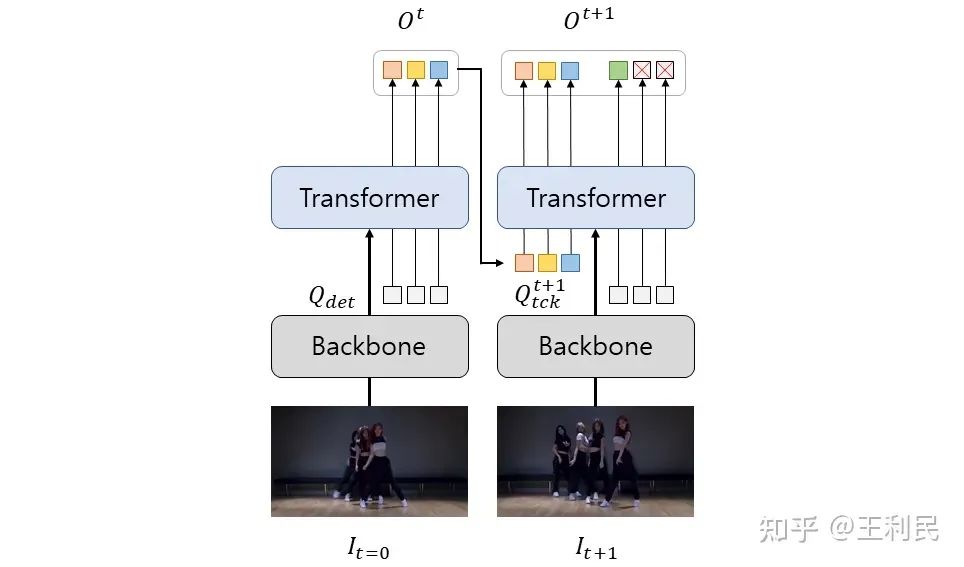
对于每一帧的处理可以视作一个独立的 DETR(图中 Transformer 部分)。对于视频第一帧,由于不存在已经跟踪的目标,因此仅仅输入可学习的 detect query(Qdet),对输出的内容通过分类阈值进行筛选,超过阈值的输出向量会被保留下来,记作 Ot;而后经过一些后续处理(例如 MOTR 中的 QIM),转化成为输入到下一帧同样的 DETR 结构中的 track query;随后,将其和每一帧共用的 detect query(Qdet)一起输入到 DETR Decoder 中进行逐层处理,最终输出对应的向量:每一个 track query 所对应的目标自然继承来自上一帧的 ID 信息,而 Qdet对应的目标再次经过阈值筛选,用于检测新生目标(newborn object),并且将其添加到已跟踪的目标列表中,如此往复。
如果当前帧的目标被遮挡,则对应的 track query 的期望输出置信度应该低于阈值,并且将该 track query 标记为不活跃(inactive);当目标再一次出现的时候,其置信度应该高于阈值,并且将该 track query 的不活跃标记去除;如果一个目标在一定帧数Tmiss之后都没有重新出现,则将该 track query 彻底丢弃。
方法介绍
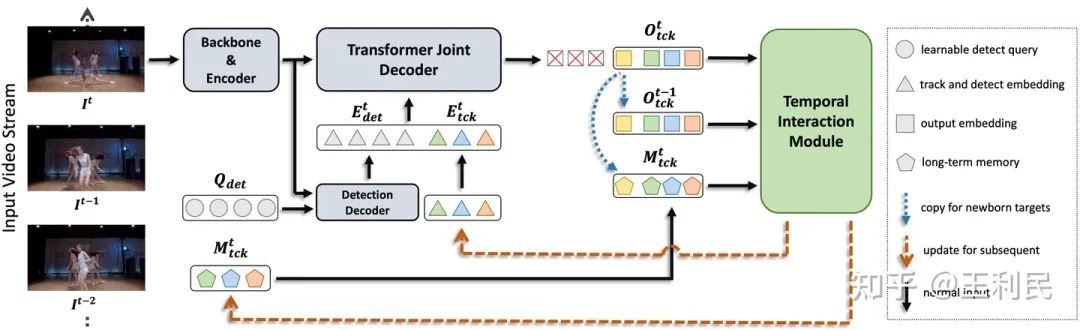
Detection Only Decoder
在现有的 Transformer-based(query-based)多目标跟踪框架中,如前一节所述,detect query 和 track query 被同时输入到 DETR Decoder 中,进行六层的连续解码,得到最终目标的定位(bounding box)和分类(classification)。
但是正如许多有关 DETR 的文章所讨论的,DETR 中的 detect query 扮演了一个类似于可学习 anchor 的角色,它往往不具备丰富的语义信息;但是 track query 是来自于上一帧的 DETR Decoder 的输出,其具有用于表示该目标的丰富语义信息。因此从直觉上来说,将这两者同时输入到一个模块中,由于两者的语义信息无法对齐,因此很可能引起冲突,从而对网络带来负面影响。
因此,我们将 DETR Decoder 划分成为两部分(如主图所示),第一层命名为 Detection Decoder,只输入可学习的 detect query,输出包含了语义信息的 detect query,并且与来自上一帧的 track query 一同输入到后续五层的 Joint Decoder 中进行同步解码,以减少语义不对齐带来的影响。为了加以区分,我们将没有携带语义信息的可学习目标检测 query 称为 detect query(记作Qdet),将经过第一层 Decoder 之后携带了语义信息的对应输出称为 detect embedding,同时,将来自上一帧的 track query 称作 track embedding 以对齐。
Long-Term Memory

Temporal Interaction Module

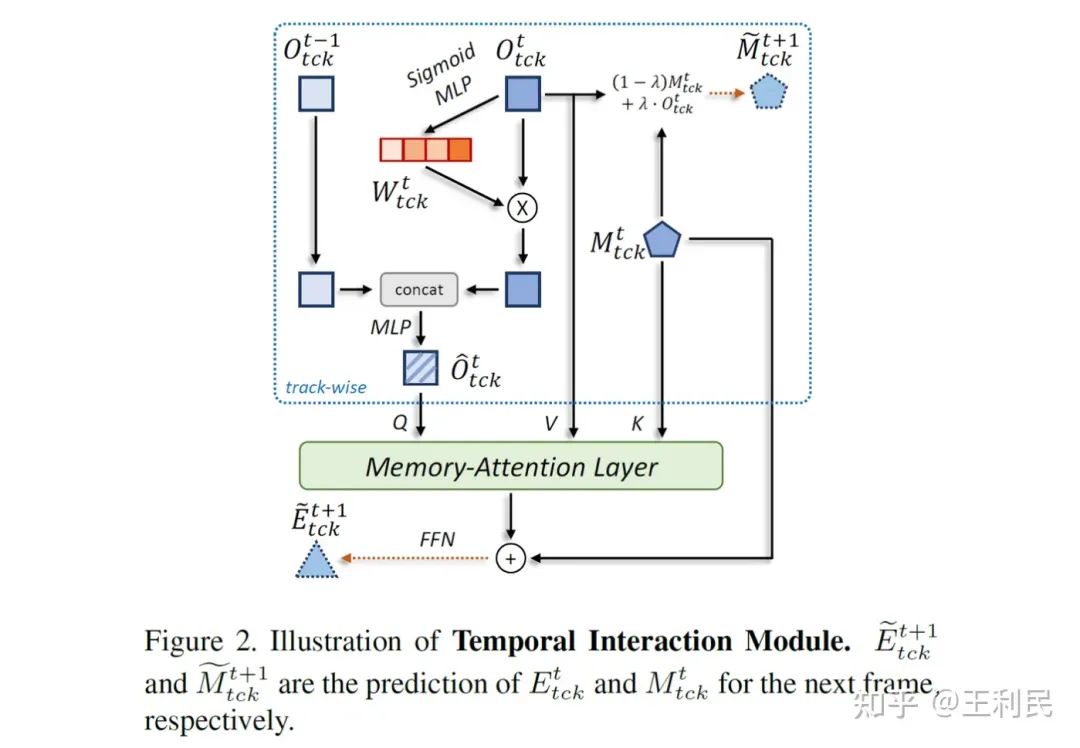
其主要结构可以视作三个部分:

实验
实验细节
我们采用了 DAB-Deformable-DETR 作为我们的主体结构,并且采用 ResNet-50 作为 Backbone,我们采用在 COCO 上预训练的权重作为网络初始化;我们还在 DanceTrack 上提供了采用标准 Deformable-DETR 作为主要结构的实验结果,用于公平对比之前的工作以验证方法的有效性。
我们的实验主要在 8 张 V100-32 GB 上进行,不过在我们的开源仓库中,通过 PyTorch 官方的显存压缩技术(gradient checkpoint),所有实验也可以在 10 GB 以下的 GPU 上运行。
SOTA 比较
我们在多个现有的数据集上与当前已发表的众多方法进行对比。
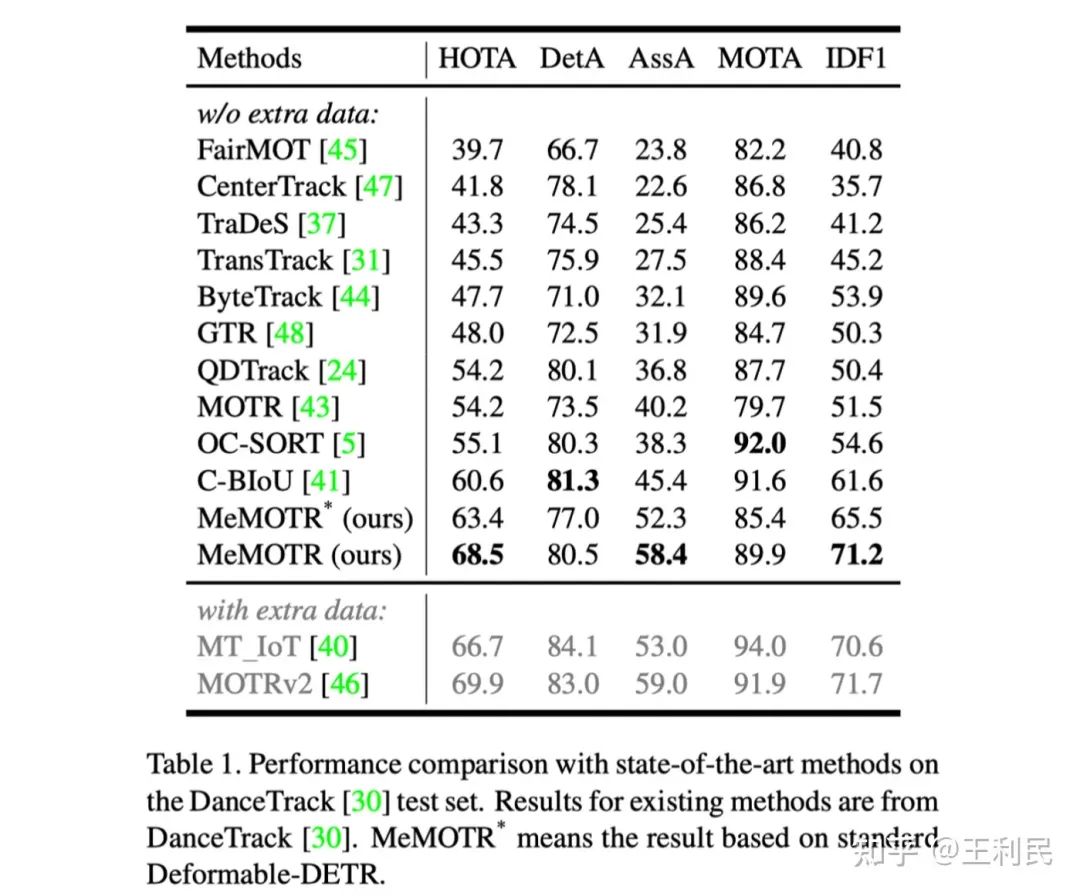
在 DanceTrack 数据集上,我们达到了 68.5 HOTA 的成绩,大幅超过了过往方法,尤其是在代表目标关联性能的 AssA 指标上(58.4)。我们同时提供了基于标准 Deformable DETR 结构的实验结果(MeMOTR*),其在公平对比的情况下仍然大幅超过(63.4 HOTA vs. 54.2 HOTA)了其余使用 Deformable DETR 作为主体结构的方法,例如 MOTR、TransTrack。
然而,在检测性能上,我们的方法对比最先进的 Tracking-by-Detection 方法仍有落后(80.5 DetA vs. 81.3 DetA),我们认为这源自于他们所采用的 YOLOX-X 检测器本身更加优异的检测性能。
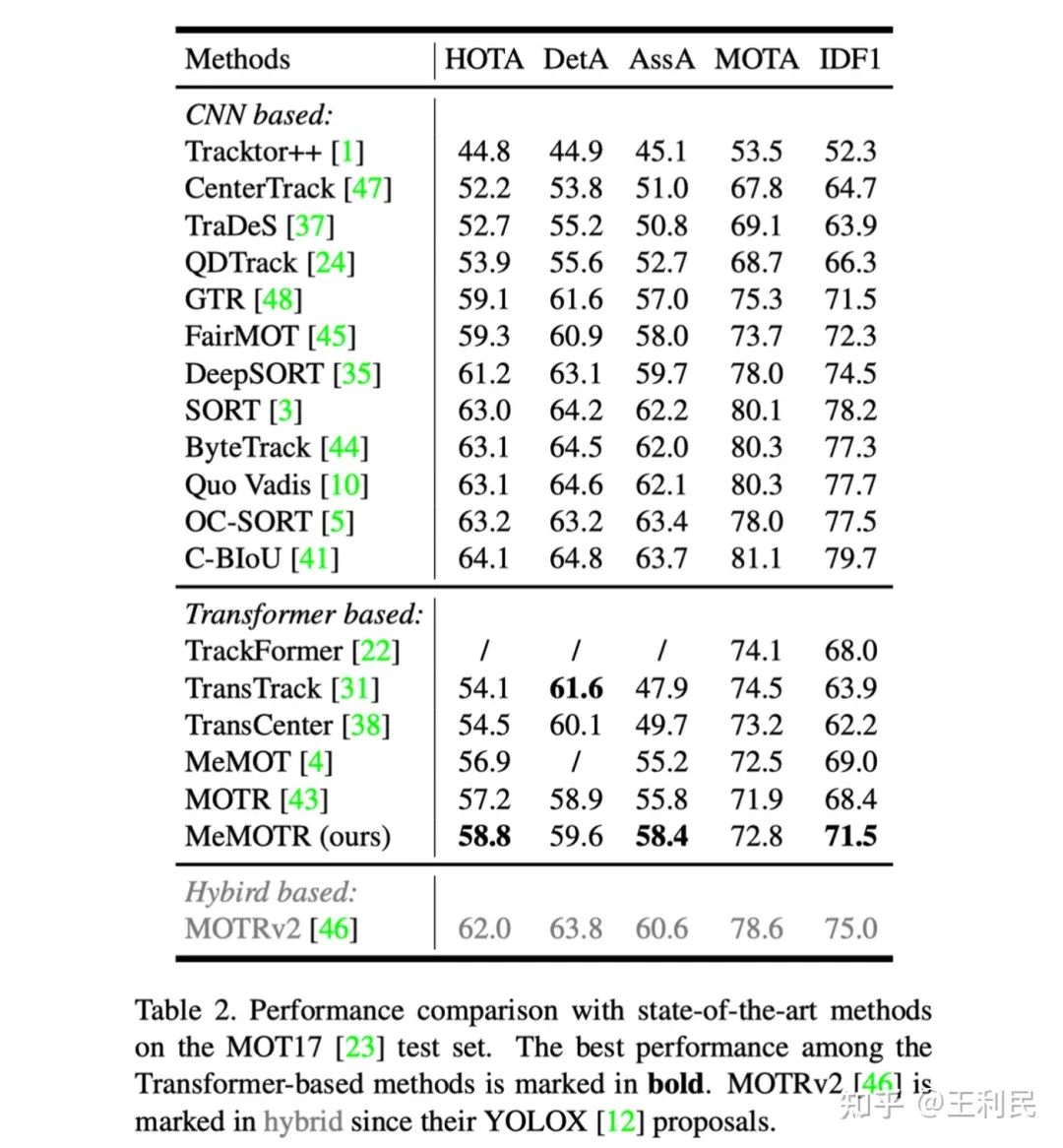
MOT17 数据集上,在 query-based 方法中,我们的方法也取得了提升。尤其是在目标关联性能(AssA)中,对比过往方法有了较大的提升。但是对比传统的 Tracking-by-Detection 方法,仍然有较大的差距,我们认为可能的原因如下:
DETR 本身对于密集小目标检测的效果会略逊于 YOLO 系列检测器,导致在 MOT17 上检测性能存在落后。
在 query-based 多目标跟踪方法中,detect query 和 track query 在 DETR Decoder 内部可能存在相互干扰的问题,尤其是 track query 对 detect query 的抑制,这导致该类方法在推理阶段对新生目标(newborn object)的捕获能力较差,从而导致产生了较多的 FN 样本。这一点在近期的部分工作中也有讨论,如 CO-MOT[6]、MOTRv3[7]。
query-based 方法对数据多样性和数量要求较高。MOT17 本身的训练集不到 DanceTrack 的 1/10,我们在训练的时候也发现了严重的过拟合现象,在 MOT17 训练集上可以达到 90.0~ HOTA,我们认为这对于模型训练是不利的。
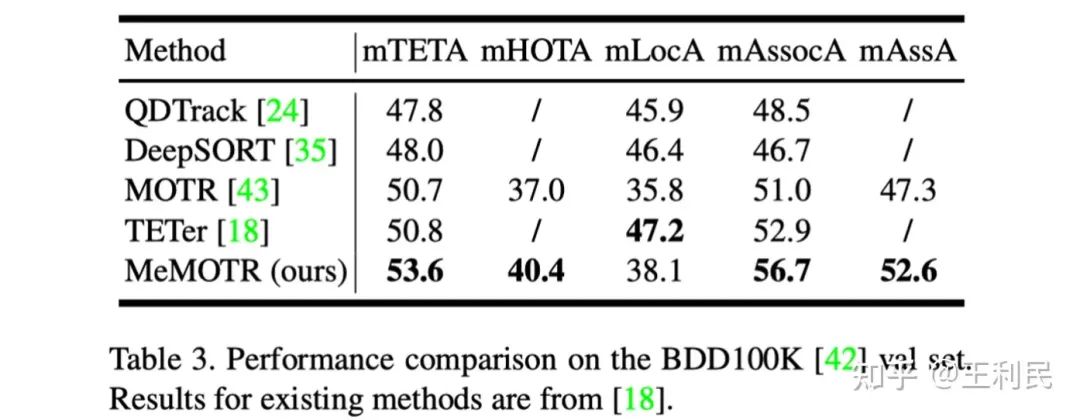
同时我们还进一步在 BDD100K 上进行了实验,结果表明我们的方法在多类别多目标跟踪上也有较好的泛化能力。
消融实验
在这部分实验(4.6节)中我们主要探究了各类设计的有效性。
首先,我们对 Detection Decoder 进行探究,如下所示:
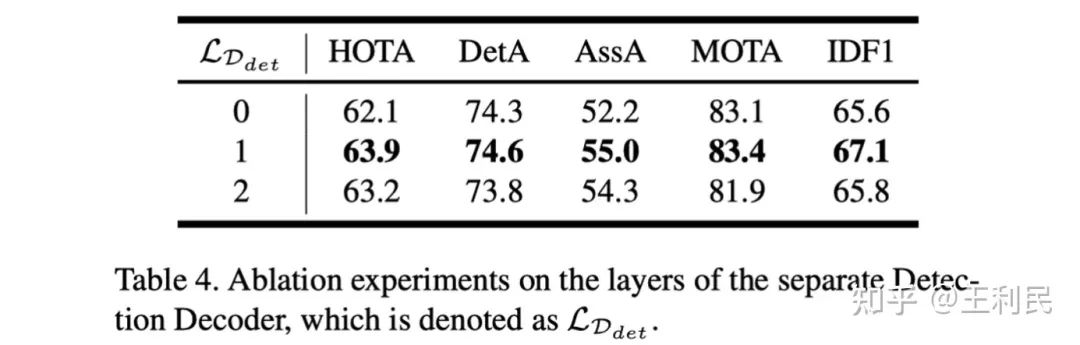
在实验中,我们尝试了不同层数的 Detection Decoder。可以看到,当我们采用独立的 Detection Decoder 时,其指标对比默认设定(0层)有明显上升,我们认为这是因为 Detection Decoder 所产生的 detect embedding 由于携带了针对某一目标的明确语义信息,因此更好地与来自之前帧的 track embedding 对齐,从而提升了模型性能。我们对这一猜想进行了一个可视化展示:

可以看到,在经过 Detection Decoder 之前(左侧),detect query 与 track embedding 所对应的参考点(reference points)存在较大差异(红色实现与绿色虚线对比);而经过 Detection Decoder 之后(右侧),两者都可以较好的近似一个明确的目标,我们认为此时 detect embedding 中携带一定的特定语义信息。
此外,我们还对提出的长时记忆力机制进行了探究:
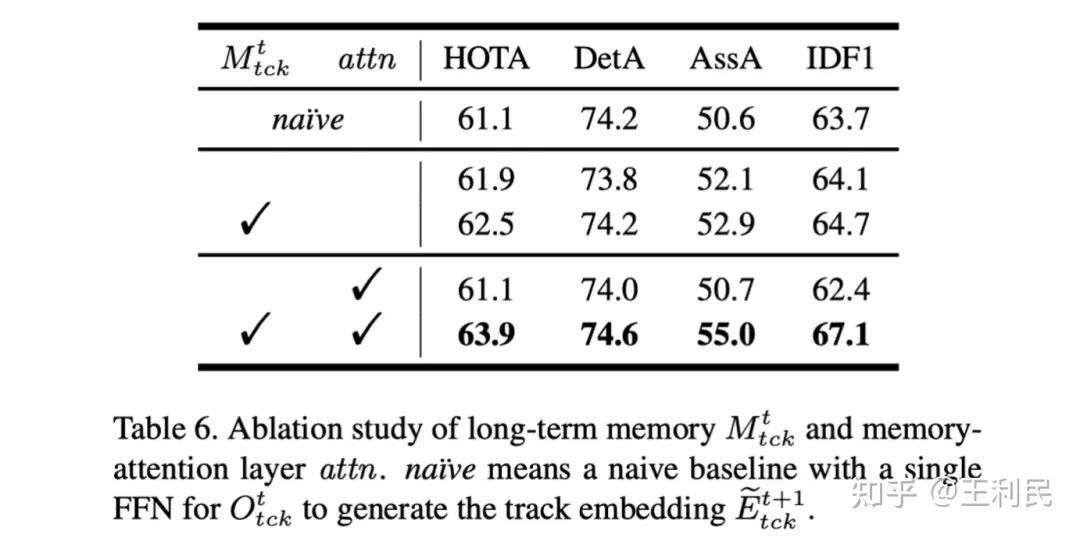
可以看到,当采用了 Memory Injection 之后(表中Mtck),跟踪指标都有了明显的提升;而如果进一步使用 Memory-Attention Layer(表中attn),性能仍会有提升。为了解释这一结果,我们对这几种设定下的多帧 track embedding 向量进行了降维可视化如下,其中不同颜色和形状代表的散点代表来自不同目标(ID)的 track embedding:
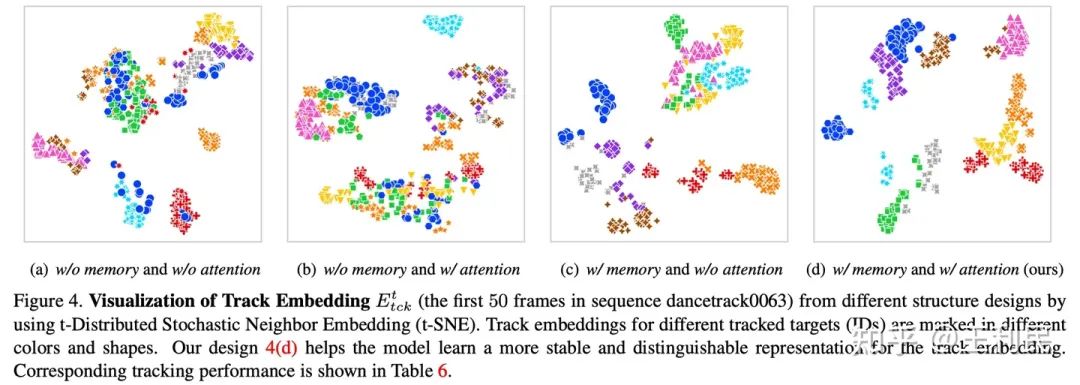
可以看到,当不使用任何我们的设计时(a),散点的分布是较为凌乱的;当我们采用了 Memory Injection 注入长时记忆信息之后(c),同一个目标的散点分布更加紧实,我们认为这是由于长时记忆向量本身是缓慢平滑更新的,因此将其注入到 track embedding 中可以使其变得更加稳定,减少在时序上突变的情况,这是有助于模型在连续帧中跟踪同一目标的;而当我们进一步采用 Memory-Attention Layer 之后(d),track embedding 的编码进一步变得可区分,各自的边界愈发清晰,我们认为这是由于 self-attention 的引入有助于在不同目标之间学习到可区分的特征表示。
总结讨论
在这篇文章中,我们提出了一个使用长时记忆向量增强的 query-based 多目标跟踪器,将更长的时序信息注入到跟踪过程中,从而显著提升了多目标跟踪的性能,充分的实验验证了我们所提出方法的有效性。我们希望可以通过这一简单且有效的改进,使更多人关注到时序信息在多目标跟踪场景中的重要性。
此外,尽管我们的方法提供了大幅的跟踪性能增益,但是仍然有一些问题和局限:
检测性能仍然相较于 Tracking-by-Detection 而言所有落后,尤其是在拥挤场景中。根据可视化分析,一个主要的问题是新生目标(newborn object)被已跟踪目标(tracked object)抑制。这一点在近期的部分文章中已有讨论,如 CO-MOT[6]、MOTRv3[7]。
在传统的行人跟踪场景下(如 MOT17),受限于数据量,过拟合仍然成为了彻底释放模型潜力的一个巨大阻碍,引入更好的联合训练或许可以解决这一问题。
参考
^abFangao Zeng, Bin Dong, Yuang Zhang, Tiancai Wang, Xiangyu Zhang, and YichenWei. MOTR: end-to-end multipleobject tracking with transformer. In ECCV (27), volume 13687 of Lecture Notes in Computer Science, pages 659– 675. Springer, 2022.
^Tim Meinhardt, Alexander Kirillov, Laura Leal-Taix´e, and Christoph Feichtenhofer. Trackformer: Multi-object tracking with transformers. In CVPR, pages 8834–8844. IEEE, 2022.
^Peize Sun, Yi Jiang, Rufeng Zhang, Enze Xie, Jinkun Cao, Xinting Hu, Tao Kong, Zehuan Yuan, Changhu Wang, and Ping Luo. Transtrack: Multiple-object tracking with transformer. CoRR, abs/2012.15460, 2020.
^Yifu Zhang, Peize Sun, Yi Jiang, Dongdong Yu, Fucheng Weng, Zehuan Yuan, Ping Luo, Wenyu Liu, and Xinggang Wang. Bytetrack: Multi-object tracking by associating every detection box. In ECCV (22), volume 13682 of Lecture Notes in Computer Science, pages 1–21. Springer, 2022.
^Jinkun Cao, Xinshuo Weng, Rawal Khirodkar, Jiangmiao Pang, and Kris Kitani. Observation-centric SORT: rethinking SORT for robust multi-object tracking. CoRR, abs/2203.14360, 2022.
^abFeng Yan, Weixin Luo, Yujie Zhong, Yiyang Gan, Lin Ma. Bridging the Gap Between End-to-end and Non-End-to-end Multi-Object Tracking. arXiv 2305.12724.
^abEn Yu, Tiancai Wang, Zhuoling Li, Yuang Zhang, Xiangyu Zhang, Wenbing Tao. MOTRv3: Release-Fetch Supervision for End-to-End Multi-Object Tracking. arXiv 2305.14298.
在CVer微信公众号后台回复:MeMOTR,可以下载本论文pdf、代码,学起来!
ICCV / CVPR 2023论文和代码下载
后台回复:CVPR2023,即可下载CVPR 2023论文和代码开源的论文合集
后台回复:ICCV2023,即可下载ICCV 2023论文和代码开源的论文合集目标跟踪和Transformer交流群成立
扫描下方二维码,或者添加微信:CVer444,即可添加CVer小助手微信,便可申请加入CVer-目标跟踪或者Transformer 微信交流群。另外其他垂直方向已涵盖:目标检测、图像分割、目标跟踪、人脸检测&识别、OCR、姿态估计、超分辨率、SLAM、医疗影像、Re-ID、GAN、NAS、深度估计、自动驾驶、强化学习、车道线检测、模型剪枝&压缩、去噪、去雾、去雨、风格迁移、遥感图像、行为识别、视频理解、图像融合、图像检索、论文投稿&交流、PyTorch、TensorFlow和Transformer、NeRF等。
一定要备注:研究方向+地点+学校/公司+昵称(如目标跟踪或者Transformer+上海+上交+卡卡),根据格式备注,可更快被通过且邀请进群▲扫码或加微信号: CVer444,进交流群
CVer计算机视觉(知识星球)来了!想要了解最新最快最好的CV/DL/AI论文速递、优质实战项目、AI行业前沿、从入门到精通学习教程等资料,欢迎扫描下方二维码,加入CVer计算机视觉,已汇集数千人!
▲扫码进星球▲点击上方卡片,关注CVer公众号

















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









