






点击下方卡片,关注“CVer”公众号
AI/CV重磅干货,第一时间送达
作者:LeolhYang(源:知乎,已授权)| 编辑:CVer
https://zhuanlan.zhihu.com/p/663587260
在CVer微信公众号后台回复:FreeMask,可以下载本论文pdf、代码,学起来!
在这里分享一下我们NeurIPS 2023的工作"FreeMask: Synthetic Images with Dense Annotations Make Stronger Segmentation Models"。在本工作中,我们从语义分割的mask产生大量的合成图像,并利用这些合成的训练图像以及他们对应的mask提升在全量真实数据上训练的语义分割模型的性能, e.g., 在ADE20K上,可以将Mask2Former-Swin-T从48.7提升至52.0 (+3.3 mIoU)。

代码:github.com/LiheYoung/FreeMask
论文:https://arxiv.org/abs/2310.15160
在上面的repo中我们也提供了处理过后的ADE20K-Synthetic数据集(包含ADE20K的20倍的训练图像)和COCO-Synthetic数据集(包含COCO-Stuff-164K的6倍的训练图像),以及结合合成数据训练后更好的Mask2Former、SegFormer、Segmenter模型的checkpoints。
TL;DR
不同于以往的一些工作利用合成数据提升few-shot performance(只用少量的真实数据),我们希望利用合成数据直接提升fully-supervised performance(用全量的真实数据),这更有挑战性。
我们利用semantic image synthesis模型来从semantic mask产生diverse的合成图像。然而,直接将这些合成图像加入训练,其实并不能提升real-image baseline,反而会损害性能。
因此,我们设计了一个noise filtering策略以及一个image re-sampling策略来更有效地学习合成数据,最终在ADE20K(20,210张真实图像)和COCO-Stuff(164K张真实图像)的各种模型上都能取得提升。此外,我们发现结合我们的策略后,只利用合成数据也可以取得和真实数据comparable的效果。
Take-home Messages
在全量真实数据的基础上,有效地利用合成数据并不容易,需要生成模型足够好以及设计合适的学习合成数据策略。
在初始阶段我们尝试了多个GAN-based从mask生成image的模型 (e.g., OASIS[1]),尽管他们的FID指标还不错,但迁移到真实数据集上的表现很差(这里的迁移性能,指在合成数据集上训练但在真实验证集上测试,ADE20K上的mIoU只有~30%)。
基于Stable Diffusion的mask-to-image synthesis model是更好的选择,如FreestyleNet[2]。
在生成质量比较高以及筛选策略比较合理的情况下,joint train合成数据和真实数据会优于先用合成数据pre-train再用真实数据fine-tune的效果。
扫码加入CVer知识星球,可以最快学习到最新顶会顶刊上的论文idea和CV从入门到精通资料,以及最前沿项目和应用!发论文强推!

Introduction

Stable Diffusion (SD)等模型已经取得了非常好的text-to-image生成效果,过去一年里,semantic image synthesis领域的工作也开始结合SD的预训练来从semantic mask生成对应的image。其中,我们发现FreestyleNet[2]的生成效果非常好,如上图所示。因此,我们希望用这些合成图像以及他们condition on的semantic mask组成新的合成训练样本对,加入到原有的真实训练集中,进一步提升模型的性能。
简单的失败尝试
我们首先检查了这些合成图像到真实图像的迁移性能,即用合成图像训练但在真实图像的验证集上测试。我们用SegFormer-B4在真实图像上训练可以取得48.5的测试mIoU,然而用比真实训练集大20倍的合成数据训练后,只得到了43.3 mIoU。此外,我们也尝试混合真实数据和合成数据(会对真实数据上采样到和合成数据一样多,因为其质量更高),然而也只取得了48.2 mIoU,依然落后于仅用真实图像训练的结果。
因此,我们希望能更有效地从这些合成数据中进行学习。
Motivation
由于上述合成数据的结果并不好,我们更仔细地观察了一下合成数据集,发现其中存在着很多合成错误的区域,如下图所示的红色框区域。这些合成错误的区域加入到训练集中后会严重损害模型的性能。

此外,不同的semantic mask对应着不同的场景,不同的场景的学习难度其实是不一样的,因此它们所需的合成训练图像的数量也是不一样的。如下图所示,大体上来看,从左至右semantic mask对应的场景的难度是逐渐增加的,如果对每张mask产生同样数量的合成图像去学习的话,那么这些简单的mask对应的图像就可能会主导模型的学习,模型的学习效率就会很低。

Method
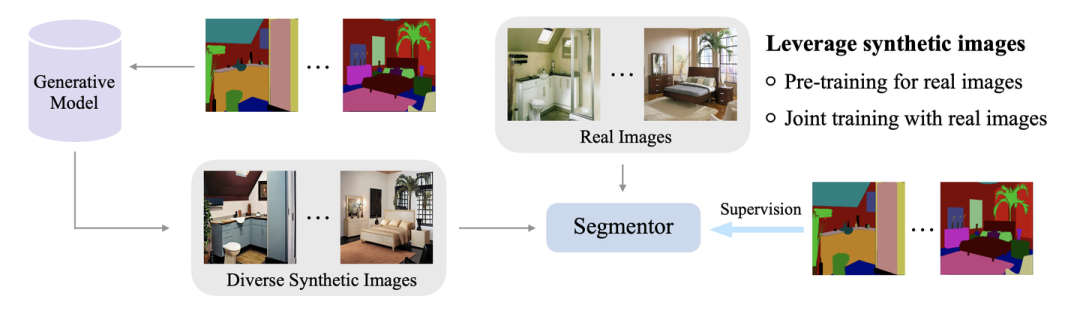
有了上述的两个motivation,具体的做法是非常简单的。
Filtering Noisy Synthetic Regions
针对第一点motivation,我们设计了一个noise filtering的策略,来忽略掉合成错误的区域。具体来说,我们利用一个在真实图像上训练好的模型去计算每张合成图像和它对应的semantic mask之间的pixel-wise loss,直观来看,合成错误的区域 (pixels)会呈现比较大的loss。此外,loss的大小也跟不同类别本身的难度有关。

Hardness-aware Re-sampling
针对第二点motivation,我们设计了一个hardness-aware re-sampling策略,来让我们的数据合成以及训练更加偏向比较难的场景 (semantic mask),如下图所示。


Learning Paradigms
我们探讨了两种从合成图像中进行学习的范式,分别是:
Pre-training: 用合成图像pre-training,然后用真实图像进一步fine-tuning
Joint training: 混合真实图像和合成图像(会对真实图像上采样到与合成图像同样的数量)一起训练
简单来说,我们发现在生成质量比较高以及筛选策略比较合理的情况下,joint training的表现会更好一些。
扫码加入CVer知识星球,可以最快学习到最新顶会顶刊上的论文idea和CV从入门到精通资料,以及最前沿项目和应用!发论文强推!

Experiment
对比合成图像和真实图像迁移到真实测试集的性能
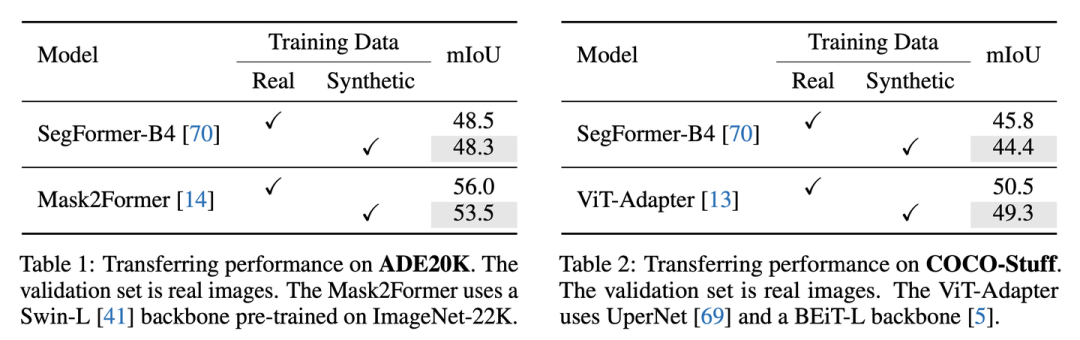
可以看到,在多种模型上,用合成图像迁移到真实验证集都可以取得和真实训练集comparable的效果。
用合成图像进一步提升全监督的分割模型性能
Joint training on ADE20K
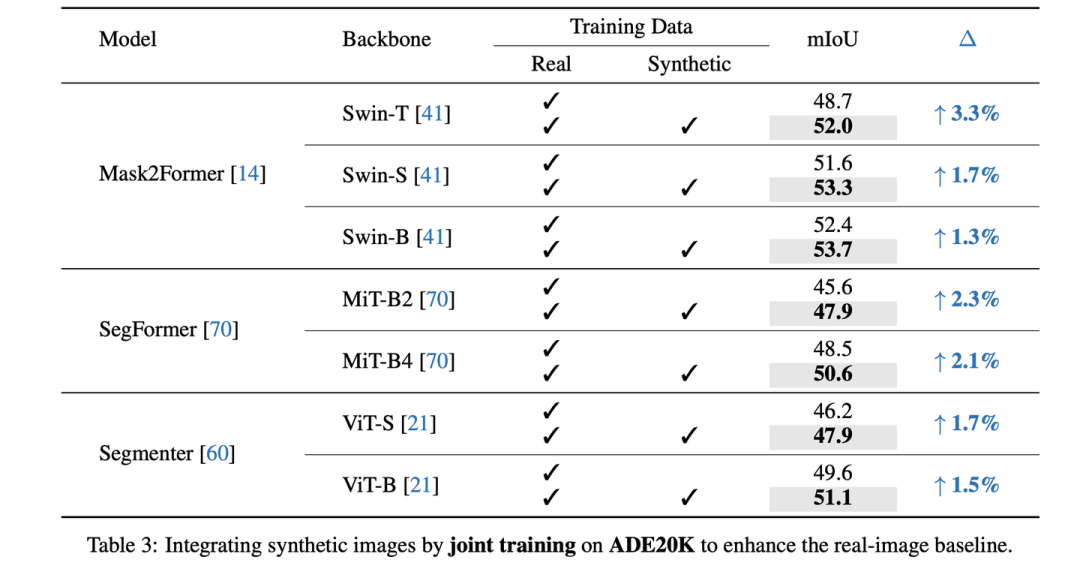
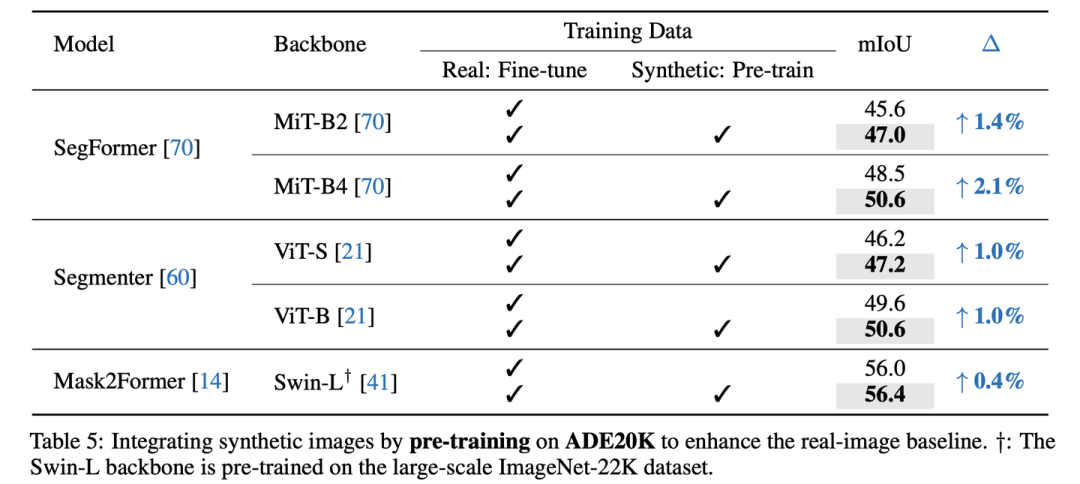
当加入了合成数据后,真实图像的全监督性能获得了显著的提升,特别是对于Mask2Former-Swin-T,我们将mIoU从48.7提升至了52.0 (+3.3);对于SegFormer-B4,从48.5提升至了50.6 (+2.1)。
Joint training on COCO-Stuff-164K
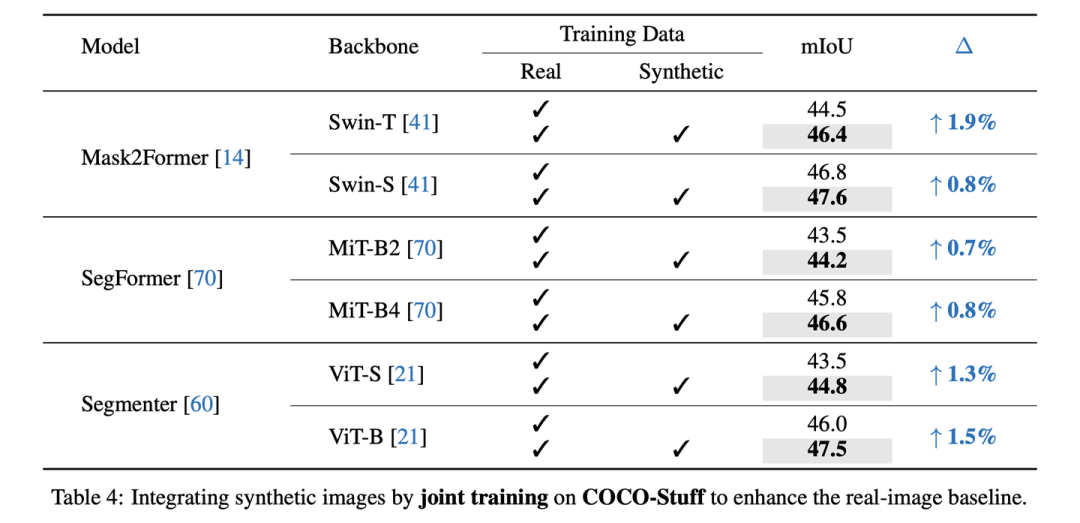
COCO-Stuff-164K由于原本的真实数据量很大,所以更难提升,但我们在Mask2Former-Swi-T上仍然取得了+1.9 mIoU的提升。
Pre-training with synthetic images on ADE20K
Ablation Studies
我们的noise filtering和hardness-aware re-sampling的必要性
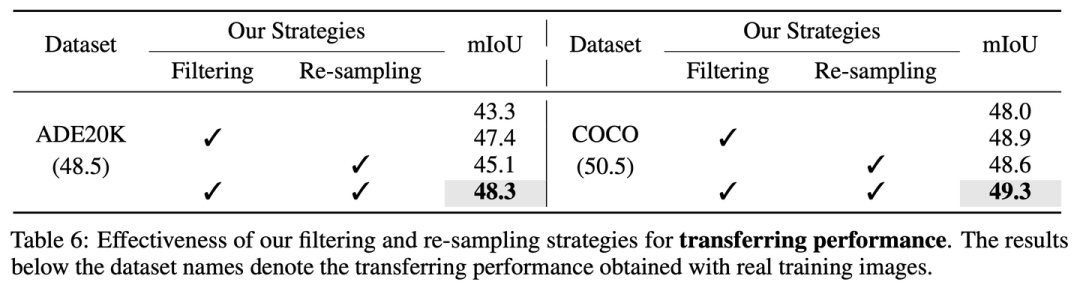
在没有filtering和re-sampling的情况下,FreestyleNet产生的合成图像在ADE20K和COCO的真实集上只能得到43.3和48.0的迁移性能,远远劣于真实训练图像的迁移性能(ADE20K: 48.5和COCO: 50.5),而应用我们的策略后,纯合成图像的迁移性能可以提升至48.3 (ADE20K)和49.3 (COCO),十分接近真实训练图像的表现。

在joint training下,我们的两项策略也是十分有效的,如果没有这两个策略,混合合成图像和真实图像只能取得48.2的mIoU (真实图像:48.5),而加入我们的策略后,可以将真实图像48.5的baseline提升至50.6。
合成图像的数量
 Nmax 控制单张mask最多产生多少张合成图像,在没有filtering和re-sampling的情况下,增加合成图像的数量反而带来了更差的迁移性能;而在经过filtering和re-sampling后,
Nmax 从6增加到20可以带来稳定的迁移性能的提升。
Nmax 控制单张mask最多产生多少张合成图像,在没有filtering和re-sampling的情况下,增加合成图像的数量反而带来了更差的迁移性能;而在经过filtering和re-sampling后,
Nmax 从6增加到20可以带来稳定的迁移性能的提升。
更多的ablation studies请参考我们的文章。
Conclusion
在本工作中,我们通过从semantic mask产生合成图像,组成大量的合成训练数据对,在ADE20K和COCO-Stuff-164K上显著提升了多种语义分割模型在全监督设定下的性能。
在CVer微信公众号后台回复:FreeMask,可以下载本论文pdf、代码,学起来!
参考
^Sushko, Vadim, et al. "You only need adversarial supervision for semantic image synthesis." ICLR 2021. https://arxiv.org/abs/2012.04781
^abXue, Han, et al. "Freestyle Layout-to-Image Synthesis." CVPR 2023. https://arxiv.org/abs/2303.14412
ICCV / CVPR 2023论文和代码下载
后台回复:CVPR2023,即可下载CVPR 2023论文和代码开源的论文合集
后台回复:ICCV2023,即可下载ICCV 2023论文和代码开源的论文合集图像分割和Transformer交流群成立
扫描下方二维码,或者添加微信:CVer444,即可添加CVer小助手微信,便可申请加入CVer-图像分割或者Transformer 微信交流群。另外其他垂直方向已涵盖:目标检测、图像分割、目标跟踪、人脸检测&识别、OCR、姿态估计、超分辨率、SLAM、医疗影像、Re-ID、GAN、NAS、深度估计、自动驾驶、强化学习、车道线检测、模型剪枝&压缩、去噪、去雾、去雨、风格迁移、遥感图像、行为识别、视频理解、图像融合、图像检索、论文投稿&交流、PyTorch、TensorFlow和Transformer、NeRF等。
一定要备注:研究方向+地点+学校/公司+昵称(如图像分割或者Transformer+上海+上交+卡卡),根据格式备注,可更快被通过且邀请进群▲扫码或加微信号: CVer444,进交流群
CVer计算机视觉(知识星球)来了!想要了解最新最快最好的CV/DL/AI论文速递、优质实战项目、AI行业前沿、从入门到精通学习教程等资料,欢迎扫描下方二维码,加入CVer计算机视觉(知识星球),已汇集近万人!
▲扫码加入星球学习▲点击上方卡片,关注CVer公众号















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









