






摘要 · 看点
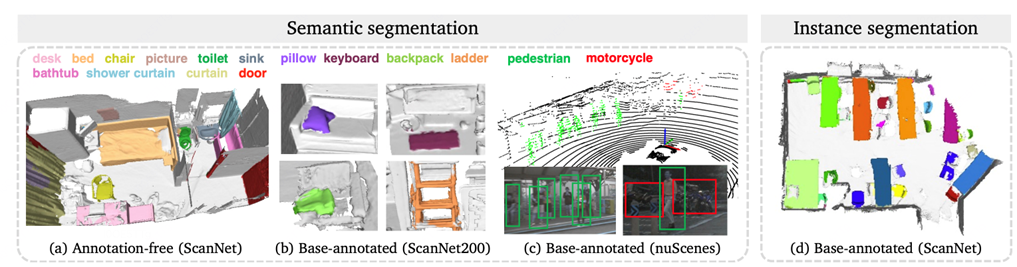
场景级别的 3D 开放世界感知一直是一个饱受关注的问题,是具身智能和机器人领域非常重要的一个能力。
在模型测试阶段,如果能够对于任意指定的类别进行语义和物体级别的分割,就能够帮助非常多下游的应用。
最近,来自香港大学和商汤科技的研究团队,提出了一种直接结合点云和自然语言的新开放世界理解算法 RegionPLC (RegionPLC 能够在未训练过的类别上都得到很好的分割结果)。
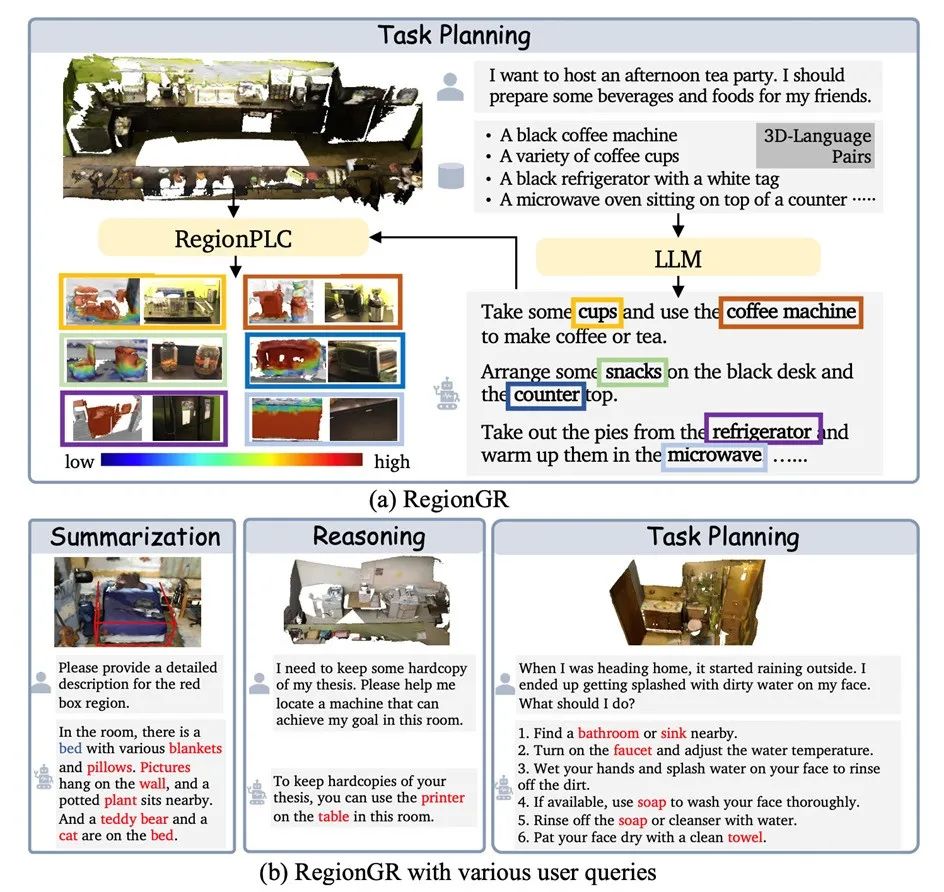
而且无需额外训练,RegionPLC 就可以和大语言模型如 GPT4 结合进行一些场景级别的开放问答,并借助 RegionPLC 的 grounding 能力分割出相应的类别,相应的和大语言模型结合的版本,被称之为 RegionGR 。
论文名称:RegionPLC: Regional Point-Language Contrastive Learning for Open-World 3D Scene Understanding

RegionPLC具体算法

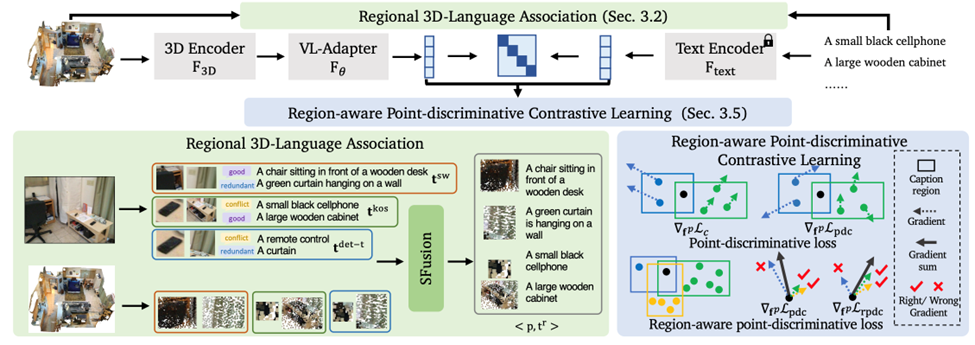
RegionPLC 在前作 PLA 的基础上,扩展到了更细粒度的区域级别点云和语言的结合,能够生成更密集和细粒度的描述。
如下图,RegionPLC 会利用不同的 2D VLM 生成对于图片的区域级别描述,包括 2D 开放语言目标检测器、滑动窗口 +2D captioning 模型,以及 2D dense captioning 模型。
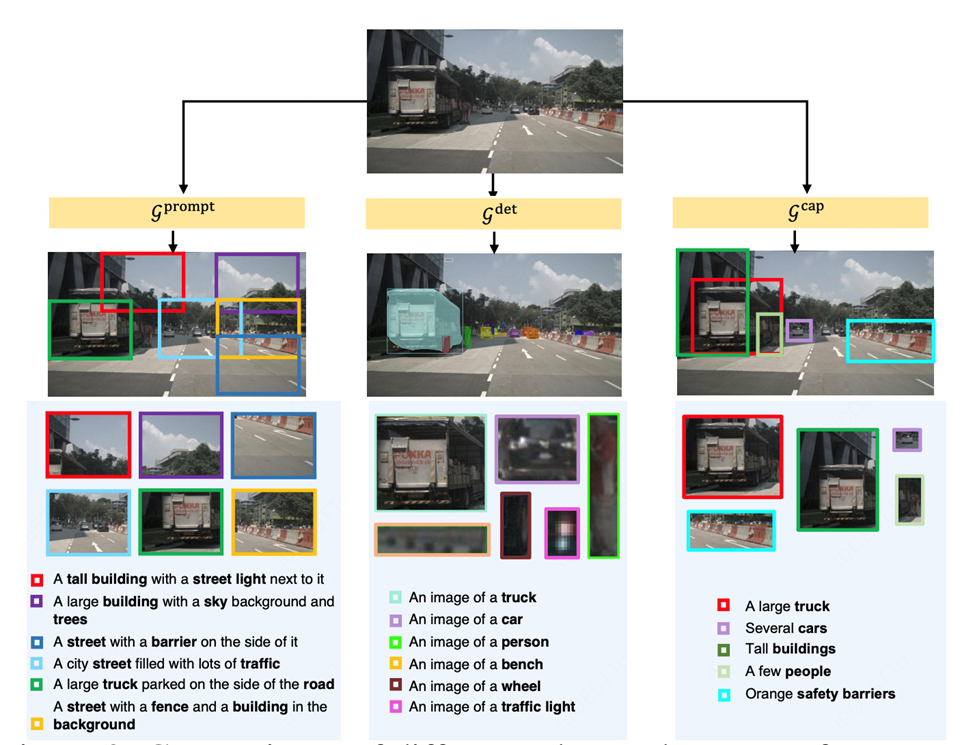
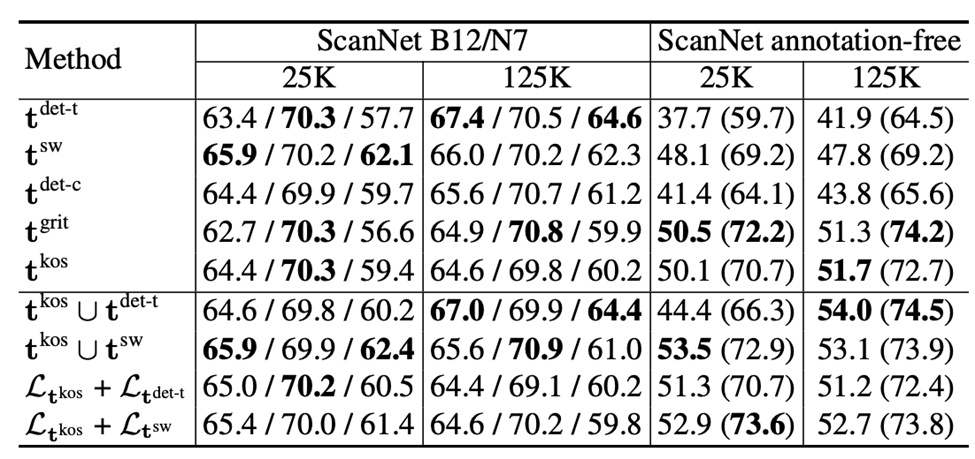
在得到各种 2D 大模型给出的文本描述后,RegionPLC 通过点云和图片的投影关系,文本和点云直接关联起来。为了具体了解不同 2D 大模型的能力区别,RegionPLC 构建了一个 benchmark 直接比较它们的性能差异:
SFusion

研究人员发现不同模型能够在不同的实验设置下取得最好性能,这意味着每种模型有自己独特的优势,而且直接在数据和 loss 方面进行混合的效果并不好。
因此,研究人员设计了一种基于互补的数据混合策略 SFusion。这种混合策略只会混合在 3D 空间中互补的 3D-text pairs,因此减少了不同模型产生的 3D-text pairs 在优化时产生冲突的概率。这样的设计使得 RegionPLC 可以结合不同 2D 大模型的优势,从而达到更好的性能。
Region-aware PDC Loss

除此之外,研究人员针对 3D 开放世界理解的任务特特性,设计了一个新的优化函数-- Region-aware PDC Loss,这种损失函数能够尽可能隔绝不相关点云的影响,而且让每个 3D-text pair 的对最终梯度的贡献接近。
因此,相比于应用于 PLA 的 CLIP contrastive loss,这种新的优化函数能够极大地提升性能,特别是对于 dense prediction 任务,比如语义及实例分割。
实验性能

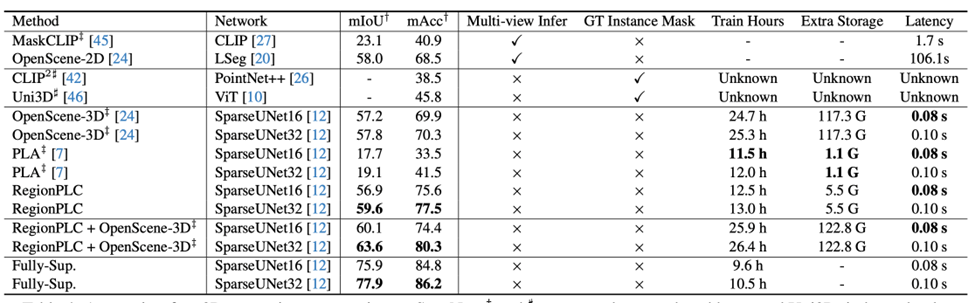
RegionPLC 在多个室内室外数据集 ScanNet、ScanNet200、nuScenes 进行了大量的实验,都取得了很好的效果,远超之前的 SOTA 算法 PLA。

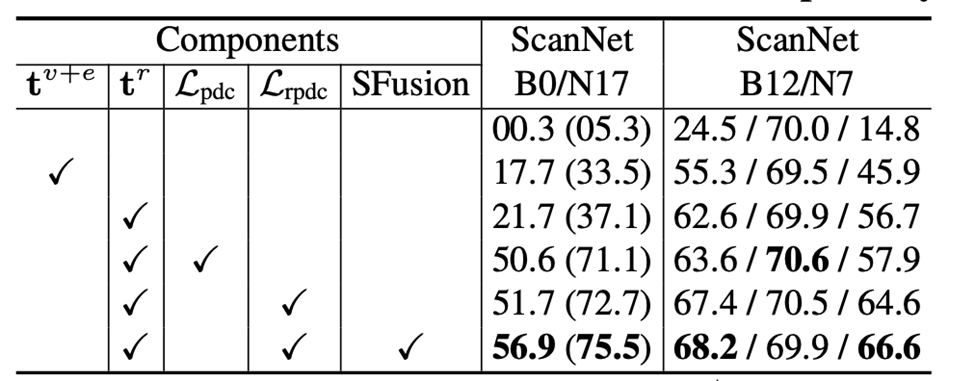
充分的消融实验也证明了其设计模块的有效。
结论

我们提出了 RegionPLC,一个综合的区域点云-语言对比学习框架,用于识别和定位开放世界 3D 场景理解中的未知类别。通过利用先进的视觉语言模型和我们的 SFusion 策略,RegionPLC 有效地构建了全面的区域点云-语言对。此外,我们的区域感知点云-语言对比损失有助于从区域性描述中学习出具有独特性和鲁棒性的特征。
大量实验证明,RegionPLC 在室内和室外场景中明显优于先前的开放世界方法,并在具有挑战性的长尾或无注释场景中表现出色。

相关资料
论文地址:
https://arxiv.org/pdf/2304.00962
项目主页:
https://jihanyang.github.io/projects/RegionPLC
GitHub链接:
https://github.com/CVMI-Lab/PLA
何恺明在MIT授课的课件PPT下载
在CVer公众号后台回复:何恺明,即可下载本课程的所有566页课件PPT!赶紧学起来!CVPR 2024 论文和代码下载
在CVer公众号后台回复:CVPR2024,即可下载CVPR 2024论文和代码开源的论文合集Mamba、多模态和扩散模型交流群成立
扫描下方二维码,或者添加微信:CVer5555,即可添加CVer小助手微信,便可申请加入CVer-Mamba、多模态学习或者扩散模型微信交流群。另外其他垂直方向已涵盖:目标检测、图像分割、目标跟踪、人脸检测&识别、OCR、姿态估计、超分辨率、SLAM、医疗影像、Re-ID、GAN、NAS、深度估计、自动驾驶、强化学习、车道线检测、模型剪枝&压缩、去噪、去雾、去雨、风格迁移、遥感图像、行为识别、视频理解、图像融合、图像检索、论文投稿&交流、PyTorch、TensorFlow和Transformer、NeRF、3DGS、Mamba等。
一定要备注:研究方向+地点+学校/公司+昵称(如Mamba、多模态学习或者扩散模型+上海+上交+卡卡),根据格式备注,可更快被通过且邀请进群▲扫码或加微信号: CVer5555,进交流群
CVer计算机视觉(知识星球)来了!想要了解最新最快最好的CV/DL/AI论文速递、优质实战项目、AI行业前沿、从入门到精通学习教程等资料,欢迎扫描下方二维码,加入CVer计算机视觉(知识星球),已汇集近万人!
▲扫码加入星球学习▲点击上方卡片,关注CVer公众号
整理不易,请赞和在看

















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









