






点击下方卡片,关注“CVer”公众号
AI/CV重磅干货,第一时间送达
添加微信:CVer5555,小助手会拉你进群!
扫描下方二维码,加入CVer学术星球!可以获得最新顶会/顶刊上的论文idea和CV从入门到精通资料,及最前沿应用!发论文/搞科研/涨薪,强烈推荐!

转载自:极市平台 | 作者:科技猛兽
导读
应用与语言模型完全相同的 "next-token prediction" 的原始自回归模型也能够实现最先进的图像生成性能。
本文目录
1 LlamaGen:自回归模型击败扩散
(来自香港大学,字节跳动)
1 LlamaGen 论文解读
1.1 LlamaGen 的诞生背景
1.2 LlamaGen 总览
1.3 图像分词器
1.4 自回归模型生成图像
1.5 模型缩放
1.6 推理速度优化
1.7 图像分词器实验结果
1.8 图像生成实验结果
1.9 文生图实验结果
1.10 推理速度
太长不看版
LlamaGen 是一系列将大语言模型中 "next token prediction" 范式应用于生成领域的图像生成模型。LlamaGen 坚定地回答了这个问题,即:原始的自回归模型,比如 Llama[1][2](它没有 2D 视觉信号的归纳偏置),在缩放适当的前提下究竟能不能达到 SOTA 的图像生成性能。
在 LlamaGen 中,作者重新检查了 image tokenizers 的设计空间,图像生成模型的缩放性能,以及训练数据的质量,探索得到的结论包括:(1) 一个下采样率为 16 的 image tokenizer,重建质量为 0.94 rFID,ImageNet benchmark 的 codebook 使用率为 97%;(2) 一系列参数量从 111M 到 3.1B 的 class-conditional 图像生成模型,在 ImageNet 256×256 benchmarks 上得到了 2.18 的 FID,超过了 LDM[3], DiT[4]等扩散模型;(3) 一个 775M 参数的 text-conditional 图像生成模型,在 LAION-COCO 和美学数据集上使用两阶段训练,在视觉质量和文本对齐上实现了极具竞争力的性能;(4) 作者验证了 LLM serving 在优化图像生成模型推理速度方面的有效性,并实现了 326% - 414% 的加速。
本文做了哪些具体的工作
图像分词器 (Image tokenizer): 一个下采样率为 16 的 image tokenizer,重建质量为 0.94 rFID,ImageNet benchmark 的 codebook 使用率为 97%。当采样率为 8 时,本文的 tokenizer 甚至比扩散模型中常用的 continuous VAE[5][6][7]更好。这说明 image tokenizer 中的离散表征不再是图像重建的瓶颈。
可扩展的图像生成模型: 一系列参数量从 111M 到 3.1B 的,基于 Llama 开发的 class-conditional 图像生成模型,最大的在 ImageNet 256×256 benchmarks 上得到了 2.18 的 FID,超过了 LDM, DiT 等扩散模型。这表明,一个普通的,没有视觉信号归纳偏置的自回归模型,是可以作为图像生成基础模型的。
高质量训练数据: 首先在 LAION-COCO[8]的 50M 子集上训练具有 775M 参数的文本条件图像生成模型,然后在10M 内部高美学质量图像上进行微调。这个过程展示了视觉质量和文本对齐方面极具竞争力的性能。
优化的推理速度: 作者采用 vLLM[9]这个最流行的LLM服务框架之一,来优化图像生成模型的推理速度,实现了 326% - 414% 的加速。
1 LlamaGen:自回归模型击败扩散
论文名称:Autoregressive Model Beats Diffusion: Llama for Scalable Image Generation (Arxiv 2024.06)
论文地址:
http://arxiv.org/pdf/2406.06525
代码链接:
http://github.com/FoundationVision/LlamaGen
1.1 LlamaGen 的诞生背景
基于自回归模型,大语言模型 (LLM) 通过预测序列中的下一个 token 来生成文本。这种 "next-token prediction" 的范式在以类人对话方式解决语言任务方面表现出前所未有的能力,展示了迈向通用人工智能模型的有前途的途径。
受到了自回归模型在大型语言模型上的可扩展性的启发,一些开创性的工作试图探索图像生成中的自回归模型,例如 VQVAE[10],VQGAN[11],DALL-E[12]等。这些工作引入图像分词器将连续图像转换为离散标记,并应用自回归模型以 "next-token prediction" 的方式生成图像 tokens。虽展示出很好的性能,但其开源社区却未得到很好的开发,在很大程度上限制了其进一步改进。
同时,另一种图像生成方法,Diffusion model 的发展迅速。扩散模型的开源社区主导着当今视觉生成的领域。然而,扩散模型与自回归语言模型拥有着不同的范式,对于构建语言和视觉之间的统一模型提出了巨大的挑战。
本文中,作者致力于进一步推动自回归模型在图像生成上的研究。回顾 2024 年前图像生成的文献,作者确定了现有先进模型的3个关键点:1) 设计良好的图像压缩器,2) 可扩展的图像生成模型和 3) 高质量的训练数据。受此启发,作者重新检查了图像分词器 (自回归模型的图像压缩器)、图像生成模型的可扩展性属性和训练数据的影响的设计。
为了实现语言和视觉之间模型的统一,本文的设计也致力于减少视觉信号的归纳偏差,采用与 LLM 相同的架构。这与最近的工作 MaskGIT[13],MAGVIT[14]15和 VAR[16]的思想类似。MaskGIT,MAGVIT 采用掩码图像建模策略,VAR 使用分层多尺度属性。虽然它们已经成功地实现了领先的图像生成性能,甚至比扩散模型更好,但尚不清楚vanilla 语言模型架构是否能够做到这一点。相反,本文表明,应用与语言模型完全相同的 "next-token prediction" 的原始自回归模型也能够实现最先进的图像生成性能。作者可以利用 LLM 社区的技术以优化模型的训练配方和推理速度。
1.2 LlamaGen 总览
首先, 输入图片 通过图像分词器 (Image Tokenizer) 被量化成了离散 tokens , 其中 。其中, 是图像分词器的下采样率, 为 image codebook 的索引。然后, 这些图像 tokens 被重新整形为光栅扫描排序中的一系列 tokens, 并用于训练基于 Transformer 的自回归模型。
生成过程:图像 tokens (𝑞1,𝑞2,.,𝑞ℎ⋅𝑤) 由自回归模型以 next-token prediction 的方式 ∏𝑡=1ℎ⋅𝑤𝑝(𝑞𝑡∣𝑞<𝑡,𝑐) 生成,其中 𝑐 是类标签 embedding 或文本 embedding。最后, 这些图像 tokens 通过图像分词器的解码器转换为图像像素。
1.3 图像分词器
Quantized-Autoencoder 架构:作者使用与 VQGAN 相同的架构,一个 Encoder,一个 Quantizer, 一个 Decoder。Encoder 和 Decoder 是下采样率为 的 ConvNet。Quantizer 包含一个码本 具有 个可学习的向量。Encoder 将图像像素 投影到特征图 中。量化过程将特征映射中的每个向量 映射到 codebook 中其最近向量 的代码索引 。在解码过程中, 代码索引 被重新映射到特征向量 , 解码器将这些特征向量转换回图像像素 。
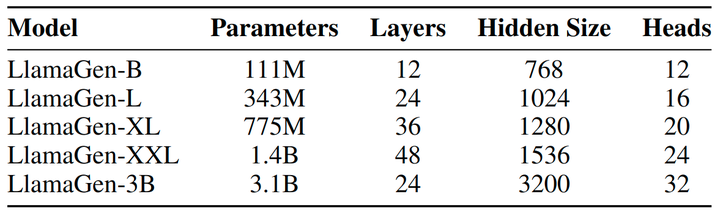
codebook 对图像分词器的性能有重要影响。作者对 codebook 向量、向量维度 和码本大小 使用 归一化。这些设计显着提高了重建质量和码本使用。
训练目标函数: 由于量化是一种不可微的操作, 因此作者使用直通梯度估计器 将梯度从解码器保留到编码器 是停止梯度操作。对于 codebook 的学习, , 其中第二项是 Commitment Loss, 强制从编码器中提取的特征向量接近 codebook 向量, 是 Commitment Loss 权重。
对于图像重建训练, , 其中 是图像像素上的重建损失, 是 LPIPS 的感知损失 是 PatchGAN 的判别器与图像标记器同时训练的对抗性损失, 是对抗性损失权重。
1.4 自回归模型生成图像
Llama 架构: 本文模型架构主要基于 Llama,使用 RMSNorm、SwiGLU 激活函数和旋转位置编码 RoPE。具体而言,按照[21][22]的实现,在模型的每一层使用 2D RoPE。不使用 AdaLN 的技术来保持我们的结构与 LLM 相同。
Class-conditional image generation: class embedding 是由一组可学习的嵌入索引用作预填充 token embedding。从这个 token embedding 开始,模型通过 next-token prediction 方式生成图像 token 序列,并在预定义的最大长度的位置停止。
Text-conditional image generation: 为了将文本条件集成到自回归模型中,作者使用 FLAN-T5 XL[23]作为文本编码器,编码的文本特征由额外的 MLP[24][25]投影,并用作自回归模型中的预填充 token embedding。
Classifier-free guidance: 扩散模型社区中开发,该技术可提高视觉质量和文本图像对齐。作者也采用了。在训练期间,conditional 被随机丢弃,并被 null unconditional embedding 替换。在推理中, 对于每个 token, 其 logit 由 形成, 其中 是 conditional logit, 是 unconditional logit, 是无分类器指导的 scale。
值得注意的是,到目前为止讨论的所有设计选择在很大程度上受到以前的工作的启发,例如,图像分词器来自[3][26],图像生成来自 DiT[4],PixArt-α[24],VQGAN[11]等。这些技术的很大一部分在扩散模型中得到了很好的研究,但在自回归模型中却很少。本文将这些高级设计集体适配自回归的视觉生成模型。
1.5 模型缩放
本文的模型架构与 Llama 几乎相同,这也使模型能够无缝地采用 LLM 的优化技术[27][28][29]和训练配方[30][31][32]。如图1 所示,在这项工作中作者将模型大小扩展到 3.1B 的参数。所有模型都使用 PyTorch 2 实现,并在 80GB A100 GPU 上训练。为了训练参数低于 1.4B 的模型,直接使用 DDP,否则采用 PyTorch FSDP 来优化 GPU 内存使用量。
1.6 推理速度优化
自回归模型总是受到其推理速度低的影响。随着大型语言模型的快速发展,LLM 社区中提出了很多高级推理技术[33][34][35]来优化推理速度。
与训练类似,LLM 社区开发的推理技术也可以用于优化模型。作者在图像生成方法上验证了 vLLM[36]的有效性,这是最流行的 LLM 服务框架之一。与基线相比设置实现了 3.26% - 4.14% 的加速。
1.7 图像分词器实验结果
训练设置: 使用 ImageNet 训练集,使用 256×256 的分辨率和 random crop 作为数据增强。当下采样率分别为16 和 8 时,图像分词器的模型大小分别为 72M 和 70M。所有模型都使用相同的设置进行训练:恒定学习率为,AdamW 优化器,weight decay 为 0.05,Batch Size 为 128,训练周期为 40。对于训练损失,commitment loss 权重为0.25,对抗性损失权重为 0.5。对抗性损失是在 20K 训练迭代后使用的。
评测指标: 使用常见的 ImageNet benchmark,图像分辨率 256×256。图像重建质量由 256×256 ImageNet 50k 验证集上的 r-FID 来衡量。codebook usage 为在整个大小为 65536 的 codebook 中使用代码的百分比。
codebook 设计的影响: 如图 2 所示,当 codebook 向量维度从 256 减少到 32 到 8 时,可以实现更好的重建质量和 codebook usage。对于 codebook 大小,从 4096 到 16384 的更大大小有利于整体性能。这些观察结果与之前的工作[37]一致。
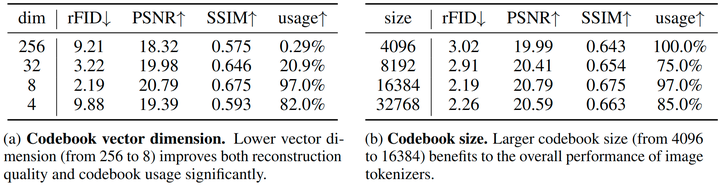
token 数量对图像表征的影响: 图3研究了图像标记数对图像重建质量的影响。例如,使用相同的图像分词器,下采样比为 16,只有 256 个 token (16×16) 的图像不足以获得良好的重建质量。而将 token 的数量增加到 576 (24×24) 可以大大提高图像质量,rFID 从 2.19 到 0.94。
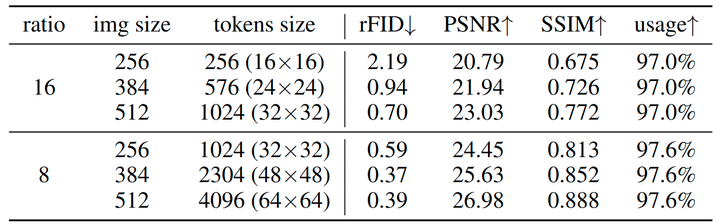
与其他图像分词器的比较: 作者比较了其他图像分词器,包括 VQGAN、MaskGIT、ViT-VQGAN。如图 4 所示,本文的分词器优于以前的图像分词器。作者还在 256×256 分辨率的 COCO val2017 上评估了本文的分词器,以验证其图像重建质量,因为 COCO 图像包含更复杂的场景。比较结果与 ImageNet 验证集中的结果一致。这表明本文图像分词器的可泛化性。
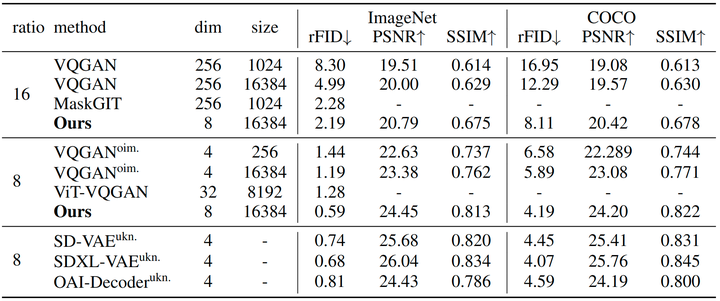
而且,本文的分词器与连续 latent space 的表征相比也具有竞争力,例如 SD VAE、SDXL VAE 和 OpenAI 的 Consistency Decoder。这表明图像标记器中的离散表征不再是图像重建的瓶颈。
1.8 图像生成实验结果
训练设置: 使用 ImageNet 训练集,所有模型都使用类似的设置进行训练:每个 256 Batch Size 的基本学习率为,AdamW 优化器,weight decay 0.05,梯度裁剪为 1.0。输入标记嵌入、注意力模块和 FFN 模块的 dropout 始终为 0.1。classifier-free guidance 的类条件嵌入 dropout 为 0.1。
图像 code 的预计算: 为了加速模型训练,作者使用图像分词器在训练期间预先计算图像 code。为了实现随机裁剪数据增强的类似效果,提取了原始图像十个 crop 的图像 code。训练期间从十个增强中随机选择一个复制代码。
图像 token 的影响: 虽然增加图像 token 会带来更好的图像重建质量,但它与图像生成质量没有很强的相关性。如图 5 所示,当模型参数小于 1B 时,256 (16×16) 个 tokens 会比 576 (24×24) 带来更好的图像生成性能。这显示了扩大模型参数和 token 数的协同作用。然而,更少的图像 token 将限制图像生成性能,例如 256 (16×16) 标记将 FID 限制在 3.06 FID,而 576 (24×24) 可以进一步将 FID 提升到较低的值。
模型尺寸的影响: 作者在5个模型大小 (B, L, XL, XXL, 3B) 上训练模型,并在使用或者不使用 classifier-free guidance 的情况下评估。图 5 说明了随着模型大小和训练时期的增加,FID 如何变化。当将模型从 LlamaGen-B 扩展到 LlamaGen-XXL 时,可以观察到 FID 的显着改进。进一步扩展到 3B 只会产生边际的改进。对这种现象的合理解释可能是数据集大小的限制:ImageNet 仅包含大约 100 万张图像,扩展数据集或使用更强的数据增强可能会带来更进一步的改进。
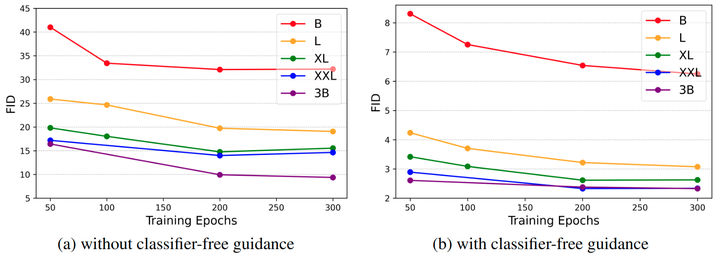
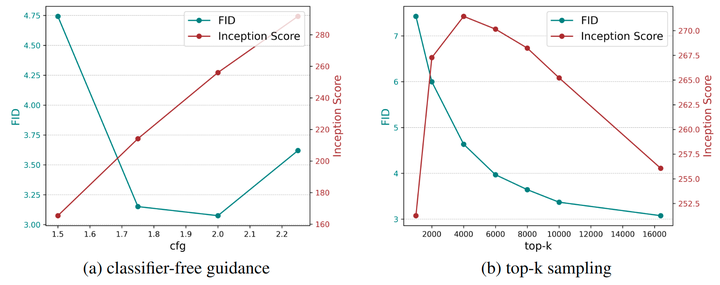
classifier-free guidance (CFG) 的影响: 首先,如图 5 所示,使用 classifier-free guidance 可以显着提高所有模型大小的视觉质量。此外,图 6(a) 说明了该模型在 CFG = 2.0 时实现了最佳 FID,进一步增加 CFG 将导致 FID 的恶化,这与之前的发现一致。此外,CFG 的增加导致多样性和保真度之间的权衡,如图 7 所示。
top-k 采样的影响: 如图 6(b) 所示,一个小的 top-k 值不利于 FID 和 IS。增加 top-k 会对 FID 有提升但又会减少 IS,这样会为了多样性而牺牲掉保真度。作者在改变 top-p 的参数和温度时观察到类似的趋势。由于 FID 是主要指标,因此使用最大值作为默认的 top-k 值,这是整个 codebook 大小。
与其他图像生成模型的对比: 在图 7 中,作者与流行的图像生成模型做了对比,包括 GAN、扩散模型和掩码预测模型。本文模型在所有 FID、IS、Precision 和 Recall 指标中表现出有竞争力的性能。值得注意的是,LlamaGen-3B 模型优于扩散模型 LDM, DiT。这表明 vanilla 的自回归模型是可以作为图像生成系统的基座模型的。
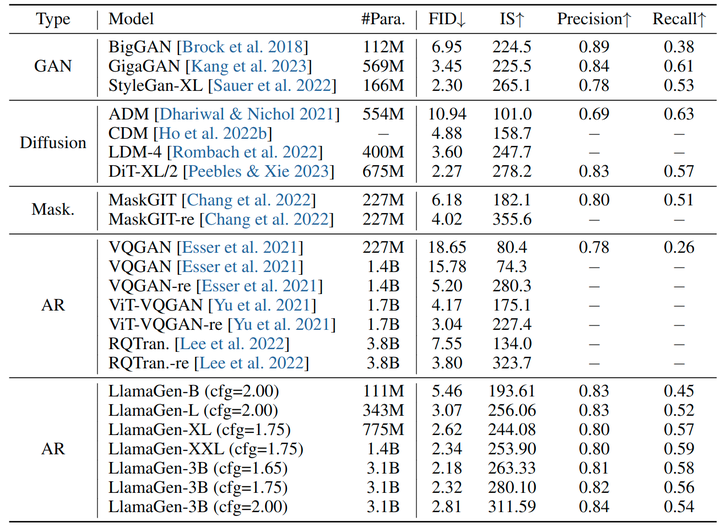
与自回归模型比较,本文模型在不同级别的模型参数上都优于所有先前的模型。这受益于更好的图像分词器设计以及更好的图像生成模型可扩展性。作者希望 LlamaGen 可以作为一个坚实的基线,并有助于促进未来对图像生成自回归模型的研究。
1.9 文生图实验结果
训练设置: 作者采用两阶段训练策略。在 stage1 中,模型在分辨率为 256×256 的 LAION-COCO 的 50M 子集上进行训练。在 stage2 中,该模型在 10M 内部高美学质量图像上进行微调,图像分辨率为 512×512。text token embedding 的最大长度设置为 120,左填充用于使能批处理。classifier-free guidance 的文本条件嵌入 dropout 为 0.1。所有模型都使用类似的设置进行训练:模型参数为 775M,基础学习率为,256 的 Batch Size,使用 AdamW 优化器,weight decay 0.05,梯度裁剪为 1.0。
预计算图像 code 和文本嵌入: 作者使用预训练的 FLAN-T5 XL 来预先计算图像标题的文本嵌入。对于图像 code,作者只提取文本条件模型训练中原始图像中心裁剪的图像代码。
微调图像分词器: 在文本条件图像生成模型的两阶段训练之前,作者首先在 50M LAION-COCO 和 10M 内部高美学质量数据的联合上微调图像分词器。
在图 8 中,作者从 COCOPrompts 中选择文本 prompts,在 stage1 训练和 stage2 训练后使用模型生成图像。在 stage1 训练后,模型捕获文本图像对齐,而表示图像细节的能力尚不清楚。stage2 的训练在很大程度上提高了视觉审美质量。作者从2个方面进行解释:高美学质量图像改变了 domain,高分辨率图像带来更好的视觉细节。作者也注意到,进一步将图像分辨率提高到 1024×1024 可以带来更好的视觉质量,作者将其留待未来的研究。

1.10 推理速度
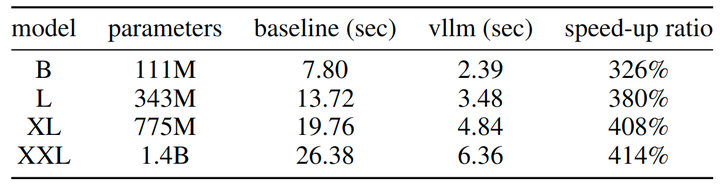
作者验证了 vLLM 服务框架在本文方法中的有效性。由于本文模型使用与 vllm 已经支持的 Llama 相同的架构,因此可以无缝地采用它的实现。如图 9 所示,与从 111M 到 1.4B 参数的模型中的基线设置相比,作者实现了 3.26% - 4.14% 的加速。请注意,baseline 已经集成了 KV-Cache 技术。
参考
^Llama: Open and efficient foundation language models
^Llama 2: Open foundation and fine-tuned chat models
^abHigh-Resolution Image Synthesis with Latent Diffusion Models
^abScalable Diffusion Models with Transformers
^Highresolution image synthesis with latent diffusion models
^ Sdxl: Improving latent diffusion models for high-resolution image synthesis
^https://github.com/openai/consistencydecoder
^https://laion.ai/blog/laion-coco/
^Efficient Memory Management for Large Language Model Serving with PagedAttention
^Neural Discrete Representation Learning
^abcdTaming Transformers for High-Resolution Image Synthesis
^Zero-shot text-to-image generation
^MaskGIT: Masked Generative Image Transformer
^Magvit: Masked generative video transformer
^Language model beats diffusion– tokenizer is key to visual generation
^Visual autoregressive modeling: Scalable image generation via next-scale prediction
^Vector-quantized Image Modeling with Improved VQGAN
^Estimating or Propagating Gradients Through Stochastic Neurons for Conditional Computation
^The Unreasonable Effectiveness of Deep Features as a Perceptual Metric
^Image-to-Image Translation with Conditional Adversarial Networks
^Unified-io 2: Scaling autoregressive multimodal models with vision, language, audio, and action
^EVA-02: A Visual Representation for Neon Genesis
^Scaling Instruction-Finetuned Language Models
^abPixart: Fast training of diffusion transformer for photorealistic text-to-image synthesis
^Gentron: Delving deep into diffusion transformers for image and video generation
^Vector-quantized Image Modeling with Improved VQGAN
^Root Mean Square Layer Normalization
^GLU Variants Improve Transformer
^RoFormer: Enhanced Transformer with Rotary Position Embedding
^FlashAttention: Fast and Memory-Efficient Exact Attention with IO-Awareness
^DeepSpeed
^Megatron-LM: Training Multi-Billion Parameter Language Models Using Model Parallelism
^Accelerating Large Language Model Decoding with Speculative Sampling
^Efficient Memory Management for Large Language Model Serving with PagedAttention
^https://github.com/TimDettmers/bitsandbytes
^Efficient Memory Management for Large Language Model Serving with PagedAttention
^Language model beats diffusion– tokenizer is key to visual generation
何恺明在MIT授课的课件PPT下载
在CVer公众号后台回复:何恺明,即可下载本课程的所有566页课件PPT!赶紧学起来!CVPR 2024 论文和代码下载
在CVer公众号后台回复:CVPR2024,即可下载CVPR 2024论文和代码开源的论文合集Mamba、多模态和扩散模型交流群成立
扫描下方二维码,或者添加微信:CVer5555,即可添加CVer小助手微信,便可申请加入CVer-Mamba、多模态学习或者扩散模型微信交流群。另外其他垂直方向已涵盖:目标检测、图像分割、目标跟踪、人脸检测&识别、OCR、姿态估计、超分辨率、SLAM、医疗影像、Re-ID、GAN、NAS、深度估计、自动驾驶、强化学习、车道线检测、模型剪枝&压缩、去噪、去雾、去雨、风格迁移、遥感图像、行为识别、视频理解、图像融合、图像检索、论文投稿&交流、PyTorch、TensorFlow和Transformer、NeRF、3DGS、Mamba等。
一定要备注:研究方向+地点+学校/公司+昵称(如Mamba、多模态学习或者扩散模型+上海+上交+卡卡),根据格式备注,可更快被通过且邀请进群▲扫码或加微信号: CVer5555,进交流群
CVer计算机视觉(知识星球)来了!想要了解最新最快最好的CV/DL/AI论文速递、优质实战项目、AI行业前沿、从入门到精通学习教程等资料,欢迎扫描下方二维码,加入CVer计算机视觉(知识星球),已汇集近万人!
▲扫码加入星球学习▲点击上方卡片,关注CVer公众号
整理不易,请赞和在看
















 556
556

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









