






点击下方卡片,关注“CVer”公众号
AI/CV重磅干货,第一时间送达
添加微信:CVer5555,小助手会拉你进群!
扫描下方二维码,加入CVer学术星球!可以获得最新顶会/顶刊上的论文idea和CV从入门到精通资料,及最前沿应用!发论文/搞科研/涨薪,强烈推荐!

PYRA:超轻量级ViT适应&推理高效微调模块

论文:https://arxiv.org/abs/2403.09192
最近,Transformer的规模迅速增长,这向基础模型的下游任务适应中引入了相当大的训练开销和推理效率方面的挑战。现有的工作,即参数高效微调(Parameter-Efficient Fine-Tuning,PEFT)和模型压缩,分别研究了这两部分挑战。然而,PEFT不能保证原始骨干网络的推理效率,特别是对于大规模模型。模型压缩需要显著的训练成本进行结构搜索和重新训练。因此,它们的简单组合不能保证以最小的成本同时实现训练效率和推理效率。在本文中,我们提出了一种新颖的并行生成重激活(Parallel Yielding Re-Activation,PYRA)方法,以应对训练-推理高效任务适应的挑战。PYRA首先利用并行生成的自适应权重来全面感知下游任务中的数据分布。之后,PYRA应用一种重激活策略进行token调制,以合并tokens,从而校准token特征。广泛的实验表明,PYRA在低压缩率和高压缩率下均优于所有竞争方法,证明了其在大模型微调当中的训练效率和推理效率方面的有效性和优越性。
简介
视觉Transformer(ViT)模型[1]在各个计算机视觉领域产生了深远的影响,例如图像分类、对象检测、图像分割等。近年来,视觉Transformers的规模已发展至十亿参数级别[2]。因此,将如此大规模的模型适应到下游任务中,呈现出越来越复杂的挑战,特别是在实际部署场景中。当将大规模Transformer应用于下游应用时,研究者们广泛认为有两个关键问题阻碍了这一点:(1)在下游任务上进行微调时的训练开销,以及(2)模型部署后的推理效率。
具体来说,首先,传统的微调方法(即全参数微调,Full Fine-Tuning)需要调整模型的所有参数,鉴于基础模型的广泛规模,这导致了GPU资源和训练时间的巨大消耗。近些年,针对第一个问题,研究人员已深入研究参数高效微调(Parameter-Efficient Fine-Tuning,PEFT)[3]算法,这些算法通常冻结预训练模型并且只调整额外的小参数,导致训练时间和存储开销的大幅度减少。第二个问题涉及到推理效率,要求部署的模型能够迅速处理输入数据。模型的计算复杂性显著影响到达满意的推理吞吐量。代表性的解决方案包括模型压缩方法,包括模型剪枝、知识蒸馏、模型量化等。
在现有工作当中,这两个问题被分别进行了研究:(1)针对第一个问题,现有的PEFT方法要么识别骨干中可调参数的子集以进行微调(BitFit [4]),要么在微调过程中向冻结的骨干引入可学习参数(LoRA [5], Consolidator [6])。虽然有效地减少了训练成本,但这些方法中的大多数不可避免地增加了计算复杂性,导致推理效率低下。(2)针对第二个问题,模型压缩方法经常需要大量的计算资源来识别修剪的最优结构。修剪后,使用大量数据的全面重新训练过程对于防止性能显著下降至关重要。因此,模型压缩方法在训练效率方面通常是低效的。
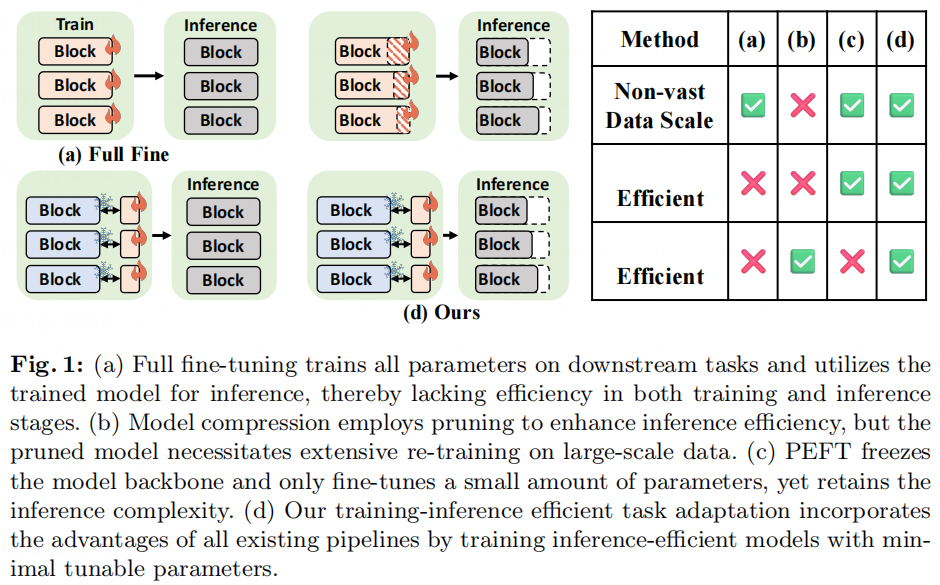
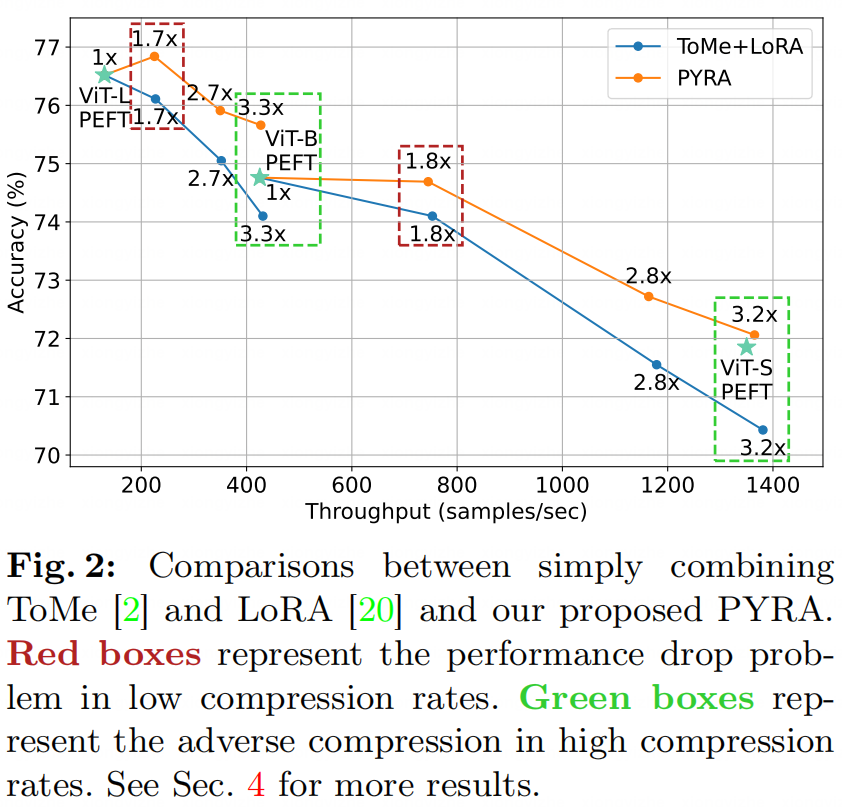
这些观察自然引出了一个问题:我们能否同时实现下游任务的训练效率和推理效率? 我们将这一挑战称为训练-推理高效任务适应(Training-Inference Efficient Task Adaptation)。探索这个问题可以使我们方便地以最小的成本部署先进的大规模基础模型到现实世界的下游应用中,这对于基础模型的广泛实现是极为必要的。一个直接的解决方案是结合PEFT和模型压缩。然而,对于高效的任务适应,一个完整的重新训练(Re-Training)阶段是不可承受的。因此,简单地结合PEFT和模型压缩容易遭受显著性能下降。例如,我们可以将常用且高效的LoRA [5],与ToMe [7],一个针对视觉transformers的无参数模型压缩技术结合起来(实际上,ToMe+LoRA是一个简洁而极为强大的解决方案,这一点在实验部分有所说明)。如图2所示,在较低的压缩率(大约1.7)下,两个Transformer骨干(ViT-L/16和ViT-B/16)的性能相较于直接在做PEFT,表现出轻微下降(<1%),这表明尽管方案需要进一步的性能改进,但ToMe+LoRA组合在较低压缩率范围内可以作为一个基础解决方案。在高压缩率(>3.0)下,ToMe+LoRA的性能迅速下降,其性能甚至不如直接对相应吞吐量的小规模Transformer进行直接PEFT。我们将这种现象称为逆压缩。这两种现象表明,直接结合现有工作无法有效应对新挑战。
本文提出了一种针对视觉Transformer进行训练-推理高效任务适应设计的并行生成重激活方法(Parallel Yielding Re-Activation,PYRA)。PYRA采用token合并范式以提高推理效率。为了进行有效的任务适应,我们从token特征和通道特征两方便分别进行特征调制,并通过轻量级的的调制权重生成器并行生成待合并tokens的调制权重。这些并行生成的权重可以全面感知下游任务中的数据分布。然后,通过重激活,将它们应用于特征调制,从而实现自适应的token调制。得益于这样一种token调制策略,PYRA能够以低计算复杂度自适应地校准下游任务的特征分布学习,最终实现有效的训练和高效的推理。
实验证明,在低倍压缩率下,PYRA的性能和压缩前的模型相差无几,在高倍压缩率下,PYRA可以达到和对应小模型PEFT相当的性能,彻底消除逆压缩现象。在实际应用中,下游任务所支持的模型大小很可能并不能找到对应大小的模型架构进行微调,因此用更大的模型做高倍压缩到对应FLOPs具有很大的应用价值。消除逆压缩的现象证明PYRA的训练-推理高效路径切实可行。
我们在不同大小模型、不同预训练范式的模型、不同模型架构上的实验证明,PYRA是一种广泛有效的方法。
方法
Preliminaries
ViT模型。本文主要关注ViT模型 [1]的训练-推理高效任务适应。一个ViT模型包含个相同的Encoder,每个Encoder由一个多头自注意力(MHSA)模块和一个前馈网络(FFN)组成。形式上,输入图像被重塑并线性投影为个维的tokens 。为简化,我们省略了分类token([CLS])和蒸馏token。对于Encoder,我们将输入表示为,输出表示为。对于MHSA,输入tokens首先被三个FC层处理以生成,和矩阵,输出通过计算后被另一个FC层投影。对于FFN,tokens被两个FC层投影。我们的方法主要关注在输入tokens 送入MHSA模块之前。
LoRA。LoRA [5] 是一种广泛使用的PEFT方法。ViT包含大量的密集参数矩阵。当适应特定任务时,对这些矩阵的更新位于小的子空间中,可以用低秩分解来建模。LoRA在微调过程中只训练分解后的矩阵。具体来说,对于密集矩阵和输入,更新后的的修改前向传播为:
其中且。在推理过程中,可以与合并,不产生额外的计算开销。
Token合并。Token合并 [7-9] 是一种针对ViT的无参数压缩技术。这类方法与Transformer结构正交,且能够灵活地改变压缩率。具体来说,第个ViT块的输入tokens 在MHSA之前被随机分成两组:
. 然后,通过余弦相似度,为每个 token匹配最相似的 token。之后,从中,选择与中tokens有最相似连接的个tokens形成token对,其中,,且。形式上可以表示为:.当前工作 [7-9] 通常通过平均池化合并tokens。
我们采用上述技术作为我们的基线方法,在其中我们在微调LoRA进行任务适应时附加了token合并。选择这些方法是因为它们的优势与训练-推理高效任务适应高度兼容。首先,token合并是无参数和无需训练的,并且不改变模型结构,这保留了PEFT的存储高效优势。此外,我们选择LoRA因其受欢迎度、简单性以及合并性(在推理期间不引入额外的FLOPs)。实验结果表明ToMe+LoRA是一个强大的基线。
PYRA: Parallel Yielding Re-Activation
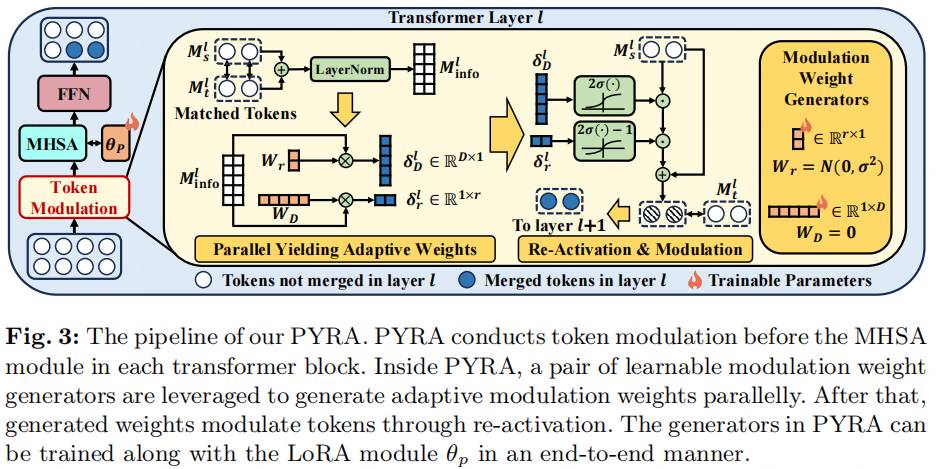
传统的微调方法通过大量微调参数,指导模型动态地与下游任务的目标数据分布对齐。然而,在训练-推理高效任务适应的背景下,只能微调一部分参数,这在准确捕捉数据分布的细微差别方面提出了重大挑战。虽然通过token合并减少模型复杂性在提高推理效率上卓有成效,但它引入了在ViT的逐层处理过程中的信息丢失风险。由于在高效任务适应场景中高效微调限制了数据分布的理解,这种损失难以纠正。因此,直接结合token合并和PEFT算法以实现训练-推理高效任务适应可能不会产生最优结果。我们提出PYRA,以自适应调制token特征,在token合并过程中增强对数据分布的感知。具体来说,在PYRA内部,首先通过每个ViT块中的一对轻量级可学习向量以并行方式生成自适应合并的权重。然后,这些生成的权重通过重激活应用于待合并的tokens以进行调制。PYRA使得以低计算复杂度自适应校准学习到的特征分布成为可能。**(1)并行生成的自适应调制参数** 我们旨在优化每对选定token对的合并过程。受到特征调制[9-10]的启发,我们在合并前调制token特征。形式上,对于具有对待合并的维tokens的Encoder ,我们将和 tokens分组为token矩阵和,其中。我们学习一个调制矩阵,以自适应地在每个通道的粒度上调制tokens。我们强调,直接学习是冗余的,并且不能自适应地满足不同图像和token对的条件。因此,我们进一步将目标具体化为分别学习特征通道的解耦权重和特征tokens的解耦权重,其中。我们以并行生成的方式生成和。具体来说,对于层中要合并的个tokens,我们在Encoder块内部创建两个可学习向量作为调制权重生成器:和。为了保证和从token对中的两个tokens提取特征信息,我们首先计算token信息矩阵:
我们通过利用操作来归一化 tokens的分布,以在训练和时实现更平滑的梯度。有了token信息矩阵,我们之后并行生成自适应权重和:
(2)重激活Token调制
通过矩阵乘法简单生成和仍然面临一些可能的问题。首先,没有措施确保和保持在正常范围内。其次,将权重解耦到特征tokens和特征通道导致调制权重矩阵具有低秩性,这显示出有限的表达能力,因此可能无法在复杂的数据分布中最优地调制tokens。为了应对这些问题,我们采用重激活策略进行token调制。具体来说,我们首先将广播到并在其上进行sigmoid激活,然后调制以获得中间调制结果:
其中表示Hadamard乘积。 然后再次用sigmoid激活的广播权重调制以获取调制后的tokens:
我们使用原始tokens 创建一个残差连接以在训练期间保持梯度流。然后将调制后的 tokens与通过平均池化合并。我们使用随机高斯初始化生成器和零初始化生成器,所以在训练开始时重激活等同于恒等变换。Token调制只在上进行,以保证训练和推理中的并行性,这是因为在token合并过程中 tokens是独特的,而不同的可能指向相同的 token。
进一步讨论
我们的PYRA有效增强了对下游任务特征的校准。具体来说,通过利用并行生成的自适应权重,PYRA有效地将调制权重从特征token和特征通道解耦,即和,使其能够全面感知下游任务中的特征分布。此外,考虑到在参数高效限制下准确捕捉特征分布的挑战,重激活的平滑操作可以限制由特征分布有限感知带来的权重值负面影响,从而进行更好的token调制,进而改善下游任务中的特征表示。我们提出的PYRA可以在token合并过程中最大程度地保持判别信息,从而在实现复杂度降低的同时提高性能。
复杂度分析
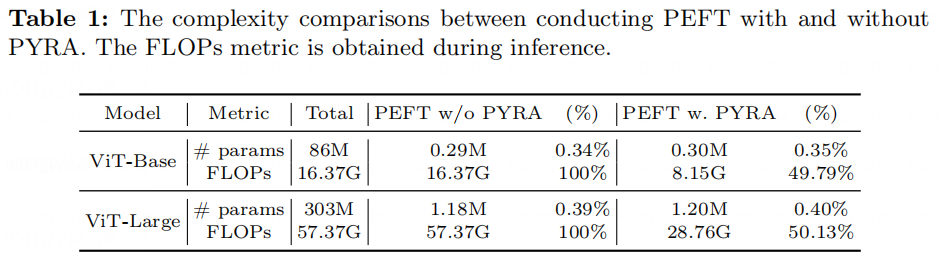
我们展示了将PYRA引入PEFT进行任务适应的参数和计算复杂性。在每个ViT块中,PYRA引入了个训练参数和额外的FLOPs。对于一个具有层和个总合并tokens的ViT模型,总体来说,我们的PYRA引入了个额外训练参数,并在PEFT之外执行了额外FLOPs。
为了更好地展示我们PYRA的训练-推理效率,我们比较了通过PEFT(这里我们使用LoRA [5])附加PYRA进行任务适应与仅进行PEFT而不使用PYRA的复杂性。如表1所示,PYRA通过引入极少量的训练参数保持了PEFT的训练效率特性,然而,这在推理效率上带来了显著的提升,即对于ViT-B和ViT-L模型来说大约是50%。后续实验结果也显示,PYRA达到了与没有PYRA的PEFT(更多的FLOPs)相当的性能。这表明,PYRA是一种有效的训练-推理高效任务适应方法。
实验结果
实现细节。 我们选择LoRA [5] 作为所有方法的PEFT模块,因为它简单且可以在推理阶段合并至网络骨干当中。为了方便解释,当比较不同方法时,我们省略了“+LoRA”这一标注。我们只在、和投影矩阵上添加LoRA,并按照 [6] 的训练超参数训练LoRA。PYRA的生成器与LoRA模块一起训练。在推理过程中,我们将LoRA模块合并到骨干网络中。所有吞吐量均在单张GeForce RTX 3090 GPU上完成测量。
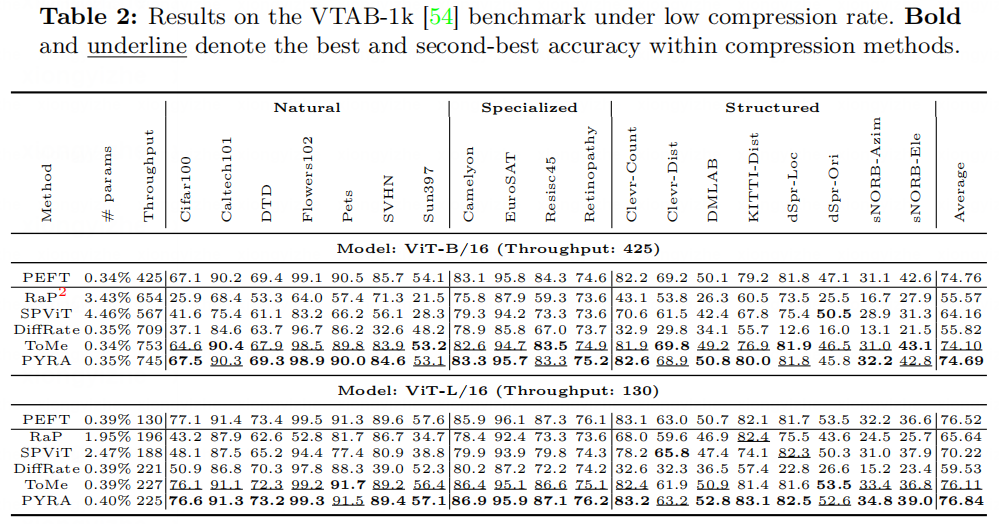

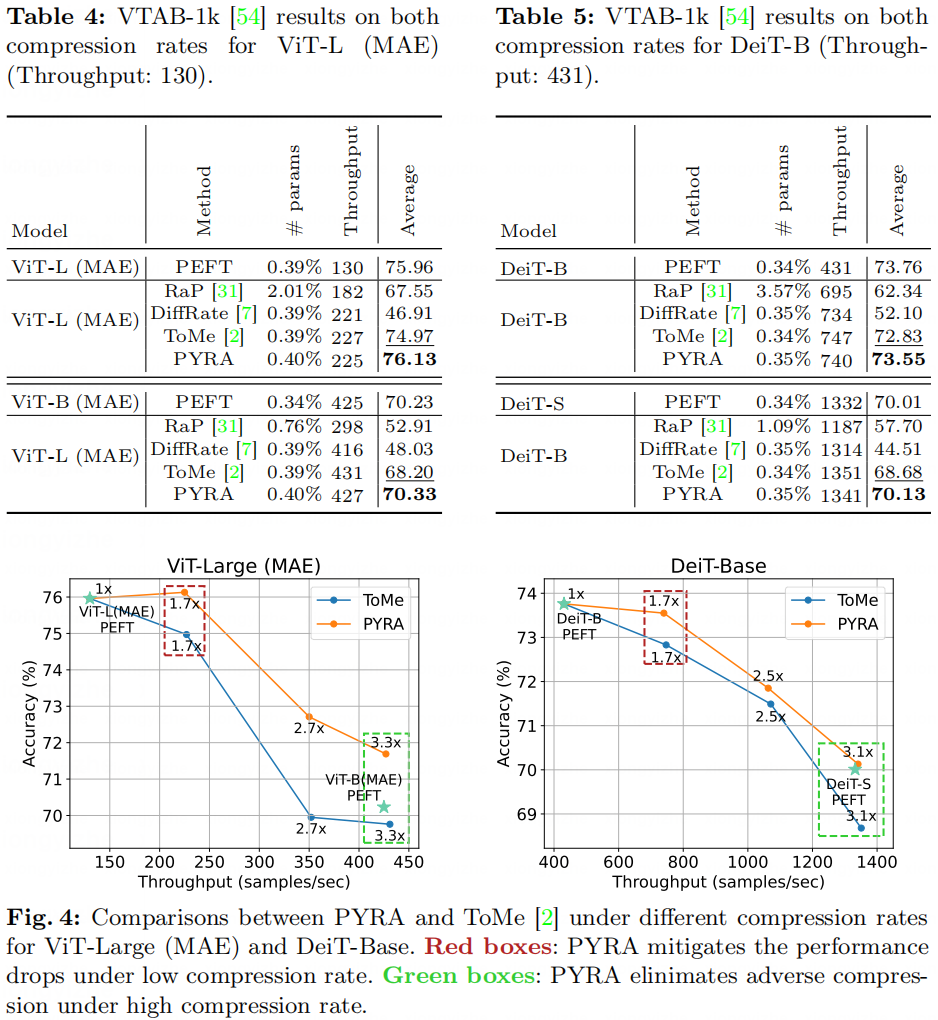
上述实验结果表明,在低倍压缩率下(大约1.8倍吞吐率左右,对应50%稀疏率压缩),PYRA的性能和压缩前的模型相差无几,在高倍压缩率下(3倍以上吞吐率,压缩到更小一级别的网络骨干对应FLOPs),PYRA可以达到和对应小模型PEFT相当的性能,彻底消除逆压缩现象。这说明PYRA是一个极为有效的训练-推理高效任务适应方法。
参考文献
[1] An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale, ICLR 2021
[2] Scaling vision transformers, CVPR 2022
[3] Parameter-efficient transfer learning for NLP, ICML 2019
[4] BitFit: Simple Parameter-efficient Fine-tuning for Transformer-based Masked Language-models, ACL 2022
[5] LoRA: Low-Rank Adaptation of Large Language Models, ICLR 2022
[6] Consolidator: Mergeable Adapter with Grouped Connections for Visual Adaptation, ICLR 2023
[7] Token Merging: Your ViT But Faster, ICLR 2023
[8] DiffRate : Differentiable Compression Rate for Efficient Vision Transformers, CVPR 2023
[9] Group Normalization, ECCV 2018
[10] Film: Visual reasoning with a general conditioning layer, AAAI 2018
何恺明在MIT授课的课件PPT下载
在CVer公众号后台回复:何恺明,即可下载本课程的所有566页课件PPT!赶紧学起来!CVPR 2024 论文和代码下载
在CVer公众号后台回复:CVPR2024,即可下载CVPR 2024论文和代码开源的论文合集Mamba、多模态和扩散模型交流群成立
扫描下方二维码,或者添加微信:CVer5555,即可添加CVer小助手微信,便可申请加入CVer-Mamba、多模态学习或者扩散模型微信交流群。另外其他垂直方向已涵盖:目标检测、图像分割、目标跟踪、人脸检测&识别、OCR、姿态估计、超分辨率、SLAM、医疗影像、Re-ID、GAN、NAS、深度估计、自动驾驶、强化学习、车道线检测、模型剪枝&压缩、去噪、去雾、去雨、风格迁移、遥感图像、行为识别、视频理解、图像融合、图像检索、论文投稿&交流、PyTorch、TensorFlow和Transformer、NeRF、3DGS、Mamba等。
一定要备注:研究方向+地点+学校/公司+昵称(如Mamba、多模态学习或者扩散模型+上海+上交+卡卡),根据格式备注,可更快被通过且邀请进群▲扫码或加微信号: CVer5555,进交流群
CVer计算机视觉(知识星球)来了!想要了解最新最快最好的CV/DL/AI论文速递、优质实战项目、AI行业前沿、从入门到精通学习教程等资料,欢迎扫描下方二维码,加入CVer计算机视觉(知识星球),已汇集近万人!
▲扫码加入星球学习▲点击上方卡片,关注CVer公众号
整理不易,请赞和在看

















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









