






点击下方卡片,关注“CVer”公众号
AI/CV重磅干货,第一时间送达
添加微信号:CVer111,小助手会拉你进群!
扫描下方二维码,加入CVer学术星球!可以获得最新顶会/顶刊上的论文idea和CV从入门到精通资料,及最前沿应用!发论文/搞科研/涨薪,强烈推荐!

论文标题:FastDrag: Manipulate Anything in One Step
作者:Xuanjia Zhao, Jian Guan*, Congyi Fan, Dongli Xu, Youtian Lin, Haiwei Pan, Pengming Feng
论文链接:https://arxiv.org/abs/2405.15769
Project page: https://fastdrag-site.github.io/

摘要:基于拖拽的图像编辑通过生成模型可对图像内容进行精确控制,使得用户只需几次简单的点击即可操控图像中的任何内容。然而,现有方法通常采用n步迭代方式来进行潜在语义优化,以实现基于拖拽的图像编辑,这不仅耗费时间长,同时也限制了实际应用。本文提出了一种全新的基于拖拽的一步图像编辑方法——FastDrag,以实现极快的编辑过程。所提方法的核心是一种创新性的潜在翘曲函数(Latent Warpage Function, LWF),它通过模拟拉伸材料的行为,对潜在空间内各个像素的位置进行调整,由此实现潜在语义一步优化,从而显著提高编辑速度。同时,本文提出了一种双向最近邻插值(Bilateral Nearest Neighbor Interpolation, BNNI)策略,用以解决采用LWF可能出现的空区域问题。该策略通过邻近区域的相似特征对空值区域进行插值,从而增强了内容的语义完整性。此外,本文还引入了一种一致性保持(Consistency-preserving)策略,该策略采用扩散逆转(Diffusion Inversion)过程中所保存的原始图像中的语义信息来指导扩散采样(Diffusion Sampling),以保持编辑图像和原始图像之间的一致性。根据在DragBench数据集上的实验结果,FastDrag与现有方法相比,在显著提升处理效率降低处理时间的同时,可达到更好地编辑效果。
Abstract: Drag-based image editing using generative models provides precise control over image contents, enabling users to manipulate anything in an image with a few clicks. However, prevailing methods typically adopt n-step iterations for latent semantic optimization to achieve drag-based image editing, which is time-consuming and limits practical applications. In this paper, we introduce a novel one-step dragbased image editing method, i.e., FastDrag, to accelerate the editing process. Central to our approach is a latent warpage function (LWF), which simulates the behavior of a stretched material to adjust the location of individual pixels within the latent space. This innovation achieves one-step latent semantic optimization and hence significantly promotes editing speeds. Meanwhile, null regions emerging after applying LWF are addressed by our proposed bilateral nearest neighbor interpolation (BNNI) strategy. This strategy interpolates these regions using similar features from neighboring areas, thus enhancing semantic integrity. Additionally, a consistency-preserving strategy is introduced to maintain the consistency between the edited and original images by adopting semantic information from the original image, saved as key and value pairs in self-attention module during diffusion inversion, to guide the diffusion sampling. Our FastDrag is validated on the DragBench dataset, demonstrating substantial improvements in processing time over existing methods, while achieving enhanced editing performance.
整体网络结构
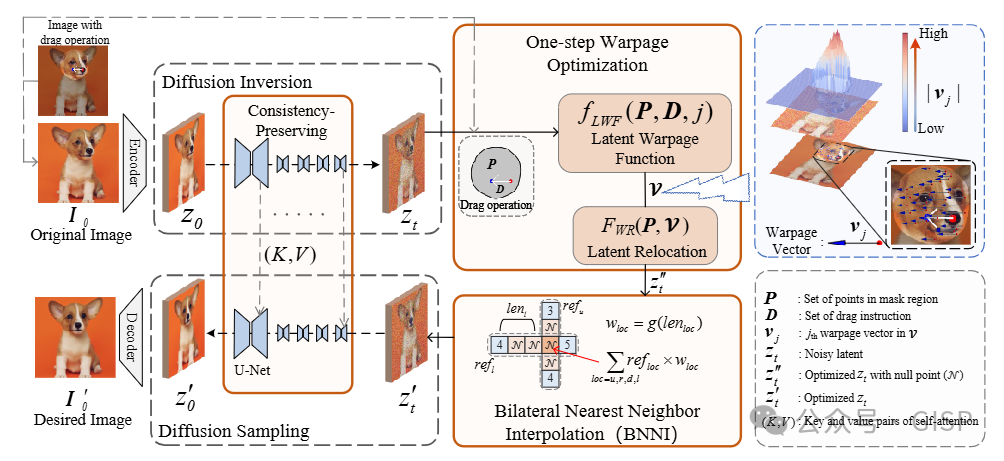
FastDrag方法整体网络结构图
演示视频
B站链接:https://www.bilibili.com/video/BV17WgDedEYt/
效果展示
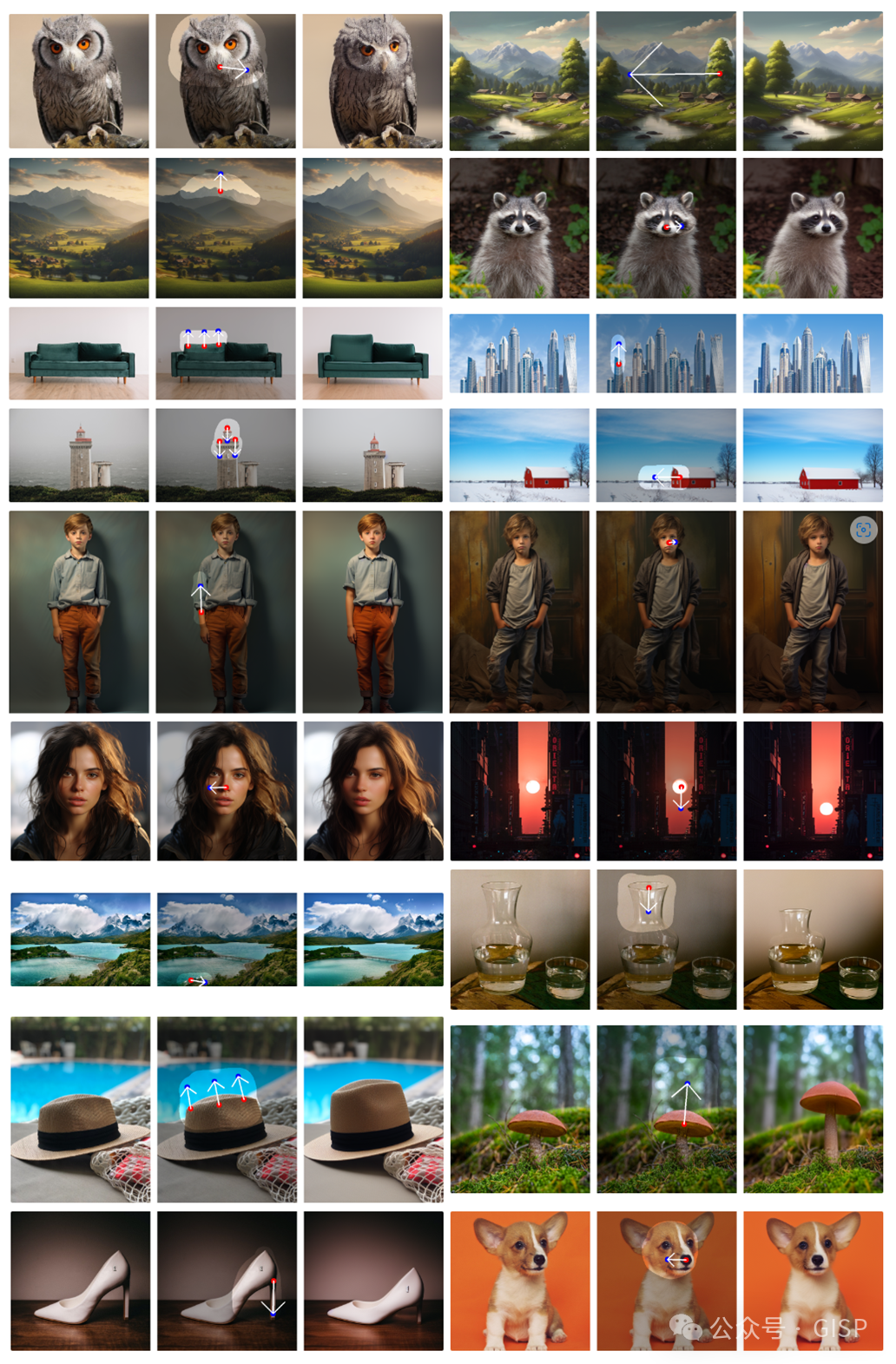
FastDrag方法图像编辑效果展示
对比实验
本文将FastDrag与当前最先进(state-of-the-art, SOTA)的方法在DragBench数据集上进行了定量比较。表中,MD值越小表示拖动结果越精确,而1-LPIPS值越大表示生成的图像和原始图像具有更高的相似性。时间指标为基于单块RTX 3090 GPU的每个操作点对所需的平均时间。Preparetion表示是否需要LoRA训练。†表示未利用Latent Consistency Model (LCM)技术作进一步加速的FastDrag。
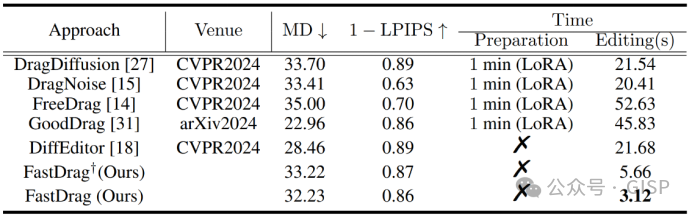
通过精心设计的一步潜在翘曲函数(LWF)优化和一致性保持策略,本文所提出的FastDrag不需要LoRA训练,从而显著减少了图像编辑的时间消耗(FastDrag仅需3.12秒完成图像编辑),比DiffEditor快近700%(DiffEditor需要21.68秒完成图像编辑),比经典的基于n步迭代的图像编辑方法(如:DragDiffusion)快2800%(DragDiffusion需要1分21.54秒完成图像编辑)。此外,即使没有使用LCM加速的情况下,所提出的FastDrag方法仍然比目前SOTA的方法快很多。
欢迎引用
@article{zhao2024fastdrag,
title={FastDrag: Manipulate Anything in One Step},
author={Zhao, Xuanjia and Guan, Jian and Fan, Congyi and Xu, Dongli and Lin, Youtian and Pan, Haiwei and Feng, Pengming},
journal={arXiv preprint arXiv:2405.15769},
year={2024}
}
何恺明在MIT授课的课件PPT下载
在CVer公众号后台回复:何恺明,即可下载本课程的所有566页课件PPT!赶紧学起来!
ECCV 2024 论文和代码下载
在CVer公众号后台回复:ECCV2024,即可下载ECCV 2024论文和代码开源的论文合集CVPR 2024 论文和代码下载
在CVer公众号后台回复:CVPR2024,即可下载CVPR 2024论文和代码开源的论文合集Mamba、多模态和扩散模型交流群成立
扫描下方二维码,或者添加微信号:CVer111,即可添加CVer小助手微信,便可申请加入CVer-Mamba、多模态学习或者扩散模型微信交流群。另外其他垂直方向已涵盖:目标检测、图像分割、目标跟踪、人脸检测&识别、OCR、姿态估计、超分辨率、SLAM、医疗影像、Re-ID、GAN、NAS、深度估计、自动驾驶、强化学习、车道线检测、模型剪枝&压缩、去噪、去雾、去雨、风格迁移、遥感图像、行为识别、视频理解、图像融合、图像检索、论文投稿&交流、PyTorch、TensorFlow和Transformer、NeRF、3DGS、Mamba等。
一定要备注:研究方向+地点+学校/公司+昵称(如Mamba、多模态学习或者扩散模型+上海+上交+卡卡),根据格式备注,可更快被通过且邀请进群▲扫码或加微信号: CVer111,进交流群
CVer计算机视觉(知识星球)来了!想要了解最新最快最好的CV/DL/AI论文速递、优质实战项目、AI行业前沿、从入门到精通学习教程等资料,欢迎扫描下方二维码,加入CVer计算机视觉(知识星球),已汇集上万人!
▲扫码加入星球学习▲点击上方卡片,关注CVer公众号
整理不易,请赞和在看

















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









