






点击下方卡片,关注“CVer”公众号
AI/CV重磅干货,第一时间送达
添加微信号:CVer111,小助手会拉你进群!
扫描下方二维码,加入CVer学术星球!可以获得最新顶会/顶刊上的论文idea和CV从入门到精通资料,及最前沿应用!发论文/搞科研/涨薪,强烈推荐!

本文是对 ECCV 2024 Oral 的论文《Knowledge-enhanced Visual-Language Pretraining for Computational pathology》的中文解读。作者来自上海人工智能实验室和上海交通大学。第一作者是来自上海人工智能实验室的周晓。

简述:本研究旨在利用医学病理知识改善病理视觉语言模型的图文表征能力。本研究的主要贡献包括:1)构建了包含4718种疾病的50,470项疾病属性,包括疾病名称及同义词、疾病定义、组织学特征以及细胞学特征等。2)利用语言模型将病理知识编码至表征空间,指导病理图像-文本对的跨模态对齐,从而达到改善病理视觉表征的效果。3)本研究在多项下游任务中开展了充分的实验验证,包括检索、零样本病理图像块分类以及在全切片图像上的零样本癌症亚型识别任务等。实验结果表明本研究提出的知识增强病理图文预训练方法能够显著提高模型在下游任务中的性能。
数据、代码和模型均以开源。
Paper link:https://arxiv.org/pdf/2404.09942
Code link: https://github.com/MAGIC-AI4Med/KEP
Webpage: https://astaxanthin.github.io/KEP/
背景与研究现状
组织病理学诊断是癌症诊断的“金标准”,其诊断结果将直接影响到癌症患者的治疗方案和预后状况。其诊断结果将直接影响到癌症患者的治疗方案和预后状况。然而计算病理学的发展极大受限于稀少的标注样本。最近的研究[1,2,3]从互联网上(如Twitter、Youtube 视频等)爬取大规模病理图像-文本对来构建病理视觉语言模型。然而,网络图文对充斥着大量数据噪声,其中的文本描述通常很短,非结构化,粒度不统一且缺乏专业知识。仅以简单对比学习方法对齐从网络上爬取的病理图文对,并没有向视觉模型中注入领域知识,导致模型在下游任务中的泛化能力非常有限。因此,本研究提出了知识增强的病理图文预训练方法,如图1所示,旨在利用专业医学领域知指导病理视觉语言模型预训练过程,改善模型在下游各项任务上的性能。
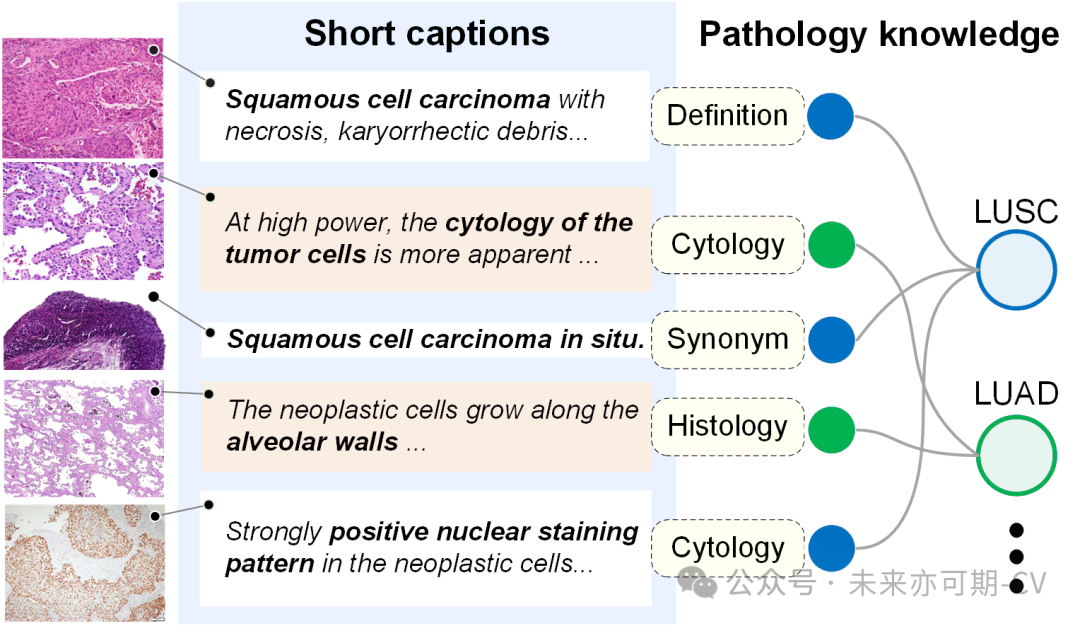
图1. 知识增强的病理图文对齐。病理图像与其简短文本描述之间的对齐需要病理知识的指导,才能有效改善病理图像及其潜在疾病类别之间的关联关系。
方法
第一阶段:病理知识树(PathKT)构建
本研究从公开的教育资源(例如教科书、专业网站和结构化数据库OncoTree)中收集病理学特定知识。具体而言,本研究从 OncoTree, 教科书和专业网站中提取了 4360 种疾病的病理描述,包括临床场景中 KEP 诊断所需的所有领域知识,即疾病名称/同义词、定义、组织学特征和细胞学特征等。经过重复数据删除和去噪后,最终的组织病理学知识树包含来自 32 类组织的 4718 种疾病。每个疾病节点的属性由不同数量的同义词、定义以及组织学和细胞学描述构成。如图2所示。
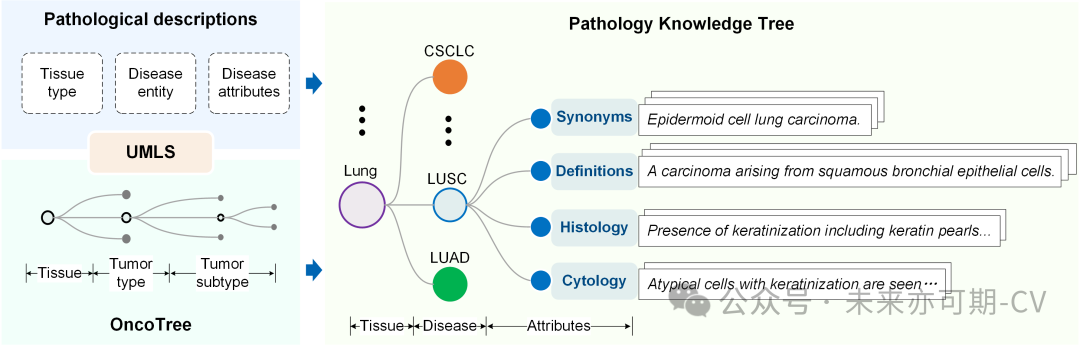
图2. 病理知识树的构建。利用UMLS将病理描述文本关联到OncoTree的节点上,并拓展至包含32类组织共4718种疾病的病理知识树。在该知识树中,第一级节点(如Lung)表示组织,第二级节点(如CSCLC)表示疾病,第三级节点表示疾病属性,包括疾病名称同义词、定义、组织学和细胞学特征。
该病理知识树的统计结果如表1和图3所示:
表1. 病理知识树的节点统计结果。Syn.,Def.,His和Cyt分别表示疾病名称同义词、定义、组织学和细胞学特征。

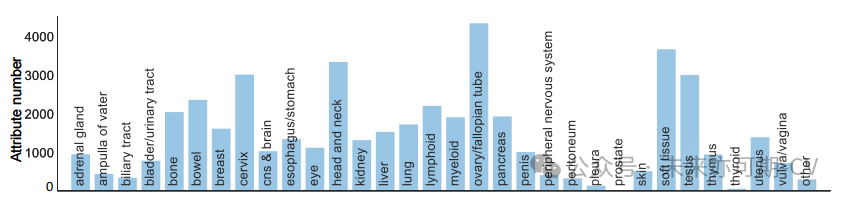
图3. 病理知识树中每种组织的疾病数量分布
第二阶段:病理知识编码预训练
利用语言模型将结构化病理知识投影到表征空间中。具体来说,本研究通过度量学习将不同的疾病实体与其相应的自由文本属性对齐,使得同义词、定义和相应的组织学/细胞学特征在嵌入空间中接近, 如图4所示。由于图像文本对中的自由格式文本描述可能包含疾病属性,例如病理特征和疾病定义,这些属性已经与疾病名称/同义词对齐,因此该模型可以在视觉语言关联过程中将病理图像与其隐含的疾病标签联系起来,以便在诊断过程中获得更好的性能。
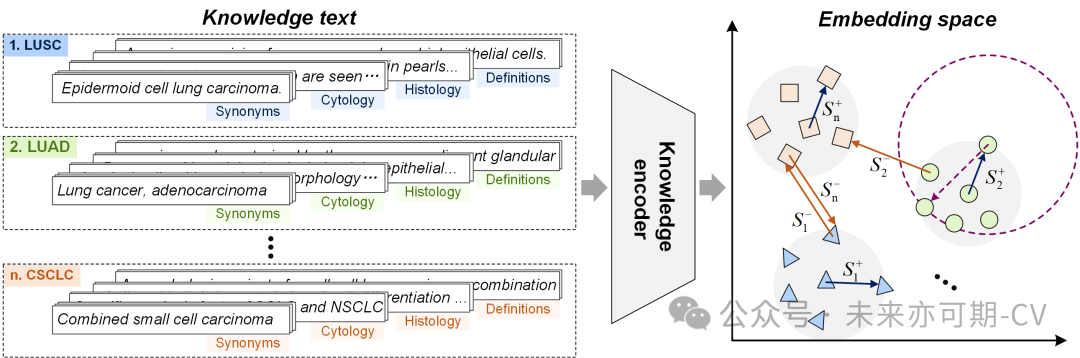
图4. 基于度量学习的知识编码器预训练。利用度量学习将不同的疾病实体与其相应的自由文本属性对齐,使得同一疾病的名称同义词、定义和相应的组织学/细胞学特征在表征空间中接近。
第三阶段:知识增强病理图文预训练
在该阶段,我们利用已建立的知识编码器来指导病理视觉语言模型的预训练(简称KEP)。其目标在于构建一个视觉语言嵌入空间,其中成对的图像文本具有相似的表示。具体而言,预训练知识编码器的权重首先用于初始化文本编码器。然后,为了保持知识空间内图像和自由格式文本之间的对齐,从而将图像链接到其隐含的疾病实体,本研究还采用了额外的冻结知识编码分支来不断将病理学知识蒸馏到打开训练的文本编码器中,如图5所示。
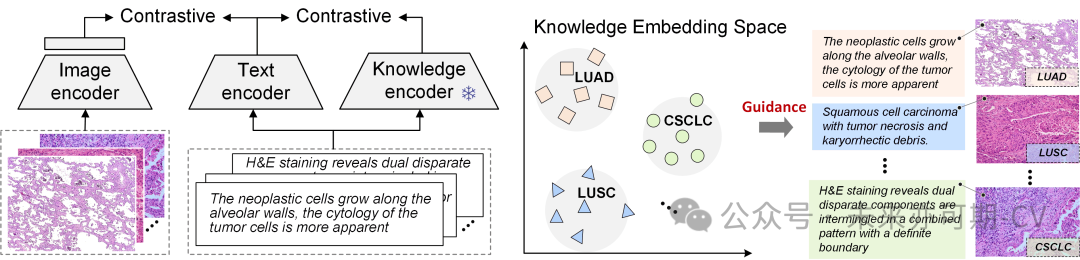
图5. 知识增强的病理视觉语言模型预训练框架
实验
训练数据和下游任务
用于知识编码器预训练的数据集是本研究构建的PathKT,用于KEP训练的病理图文数据集包括OpenPath和Quilt1M。下游测试任务包括检索(跨模态检索和疾病检索)、零样本病理图像块分类和在全切片病理图像上的癌症亚型识别。所用到的数据集如表2所示。
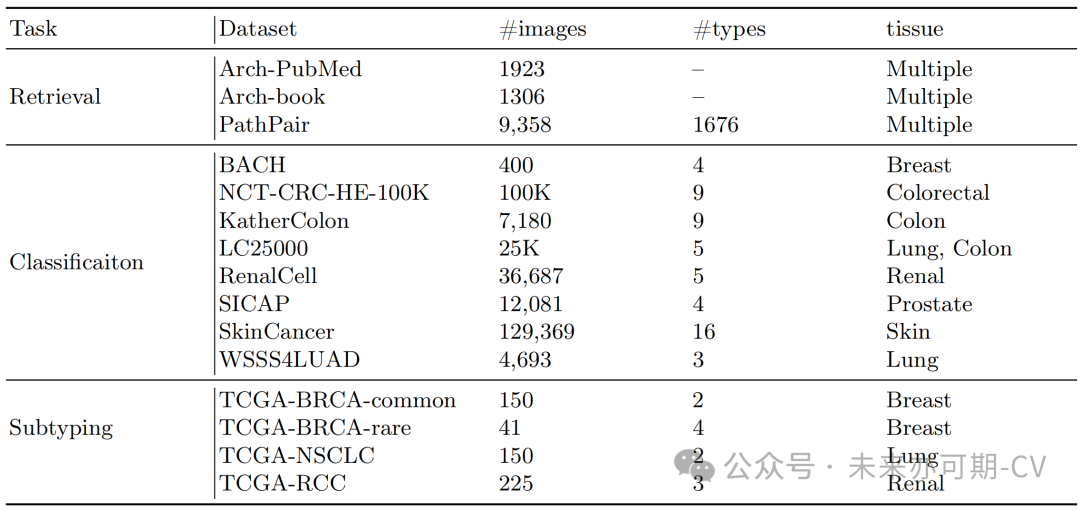
表2. 下游测试任务以及数据集分布
实验结果
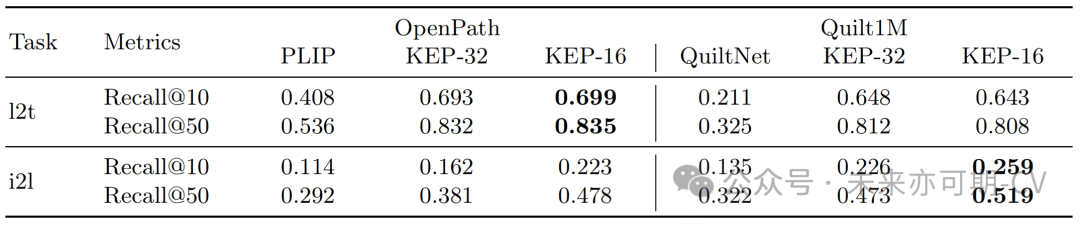
检索:对于对于跨模态检索任务,本研究在三个数据集上进行了测试。实验结果如表3所示,KEP-32 和 KEP-16 表示本研究使用不同视觉编码器的变体。实验结果表明,KEP-32 在几乎所有数据集上的表现都优于 PLIP 和 QuiltNet。KEP-16 进一步大幅提高了跨模态检索性能。本研究还在疾病检索任务上进行了评测,该任务旨在检索对应于疾病标签的正确文本描述或图像。实验结果如表4所示,可以看出,在标签到文本和图像到标签任务上KEP都显著优于 PLIP 和 Quilt1M。
表3. 跨模态检索任务实验结果
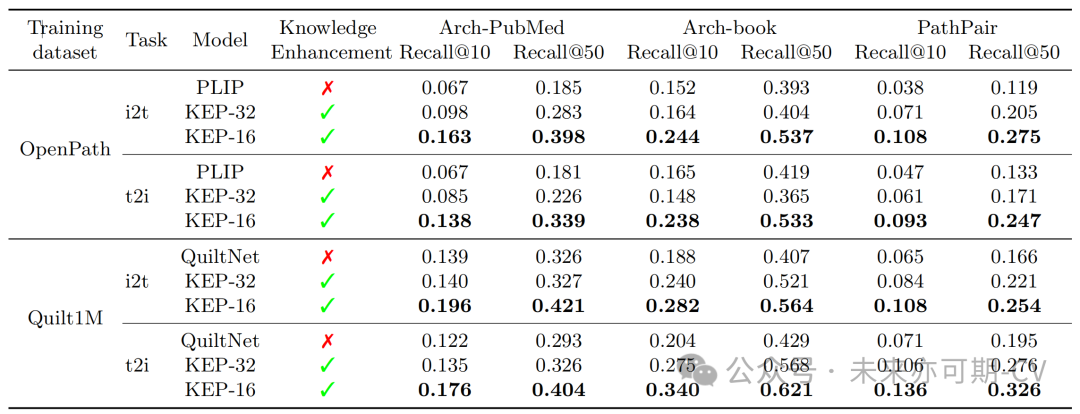
表4. 疾病检索实验结果
零样本病理图像块分类:本研究在8 个数据集上测试了上不同模型的性能,如图6所示,该图报告了性能分布,其中每个点表示一个单个文本提示的性能。可以看出,本研究的方法 KEP-32 和 KEP-16 在除 LC25000 之外的所有数据集上都比 PLIP 和 QuiltNet 实现了更好的零样本分类性能。为了验证本方法的文本编码器对不同文本提示的鲁棒性,图7可视化了不同类别提示的嵌入。可以看出,与 PLIP 和 QuiltNet 相比,KEP-32 的文本编码器生成了不同类别的良好分离的提示嵌入。
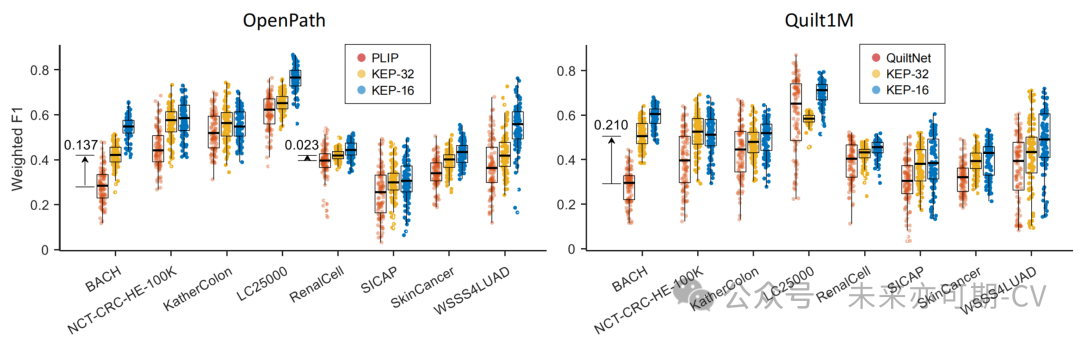
图6. 零样本病理图像块分类性能比较
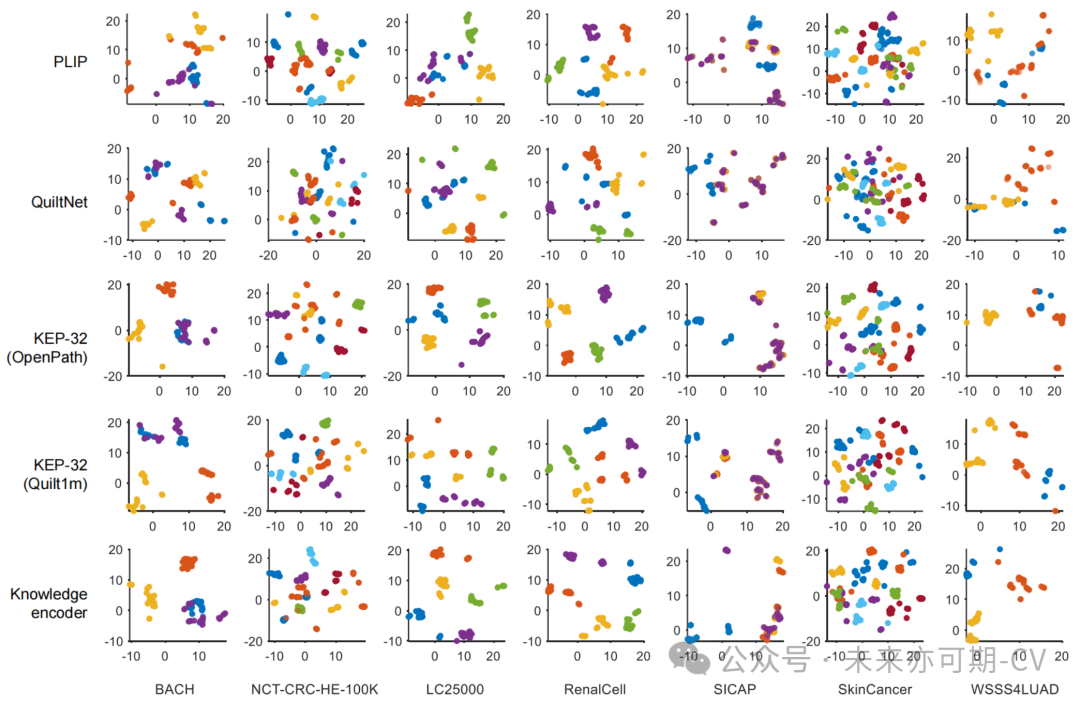
图7. 不同文本编码器对于不同文本提示的表征鲁棒性可视化结果
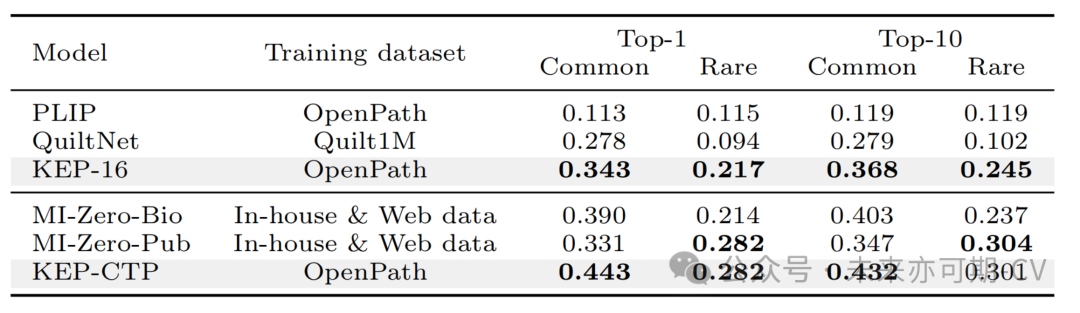
零样本肿瘤亚型识别:本研究评估了不同模型对常见和罕见癌症肿瘤亚型的识别能力,实验结果如图8所示。常见癌症的肿瘤亚型包括 TCGA-BRCA(常见)、TCGA-NSCLC 和 TCGA-RCC WSI。可以看出,KEP-16 在所有 WSI 数据集上的表现都优于 PLIP 和 QuiltNet。KEP-CTP 的性能优于或接近 MI-Zero-Bio 和 MI-Zero-Pub,后两者使用内部数据进行预训练。对于罕见癌症,本研究评估了其在六种 BRCA 亚型上的性能,包括 2 种常见癌症和 4 种罕见癌症。实验结果如表5所示。可以看出,KEP-16 方法在常见和罕见乳腺癌上的表现都远远优于 PLIP 和 QuiltNet。
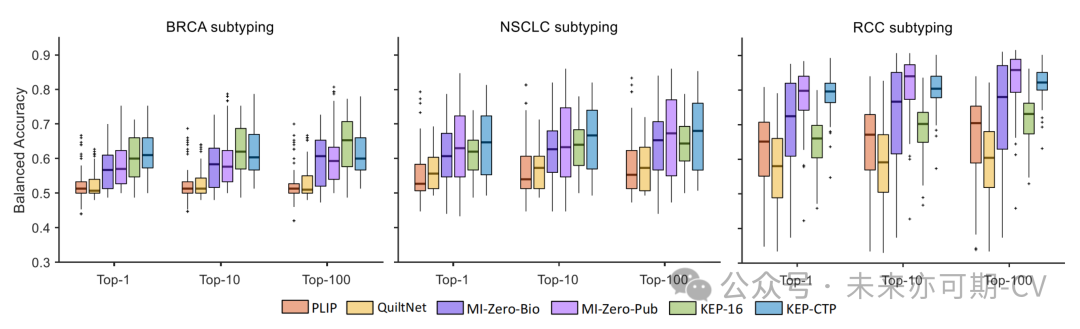
图8. 零样本常见癌症亚型识别性能比较
表5. 在乳腺癌上的零样本罕见癌症亚型识别性能比较
总结
本研究旨在解决计算病理学知识增强的视觉语言预训练问题。首先构建一个了病理知识树,该树整合了需要病理诊断的疾病的信息属性。进而提出了一种基于度量学习的新型知识编码方法来建模结构化病理知识。最后在预训练知识编码器的指导下对病理图像-文本对齐训练以提高图文表征能力。
参考文献
[1] Huang, Z., Bianchi, F., Yuksekgonul, M., Montine, T.J., Zou, J.: A visual–language foundation model for pathology image analysis using medical twitter. Nature medicine 29(9), 2307–2316 (2023)
[2] Ikezogwo, W., Seyfioglu, S., Ghezloo, F., Geva, D., Sheikh Mohammed, F., Anand, P.K., Krishna, R., Shapiro, L.: Quilt-1m: One million image-text pairs for histopathology. Advances in Neural Information Processing Systems 36 (2024)
[3] Lu, M.Y., Chen, B., Zhang, A., Williamson, D.F., Chen, R.J., Ding, T., Le, L.P., Chuang, Y.S., Mahmood, F.: Visual language pretrained multiple instance zeroshot transfer for histopathology images. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 19764–19775 (2023)
何恺明在MIT授课的课件PPT下载
在CVer公众号后台回复:何恺明,即可下载本课程的所有566页课件PPT!赶紧学起来!
ECCV 2024 论文和代码下载
在CVer公众号后台回复:ECCV2024,即可下载ECCV 2024论文和代码开源的论文合集CVPR 2024 论文和代码下载
在CVer公众号后台回复:CVPR2024,即可下载CVPR 2024论文和代码开源的论文合集Mamba和医学影像交流群成立
扫描下方二维码,或者添加微信号:CVer111,即可添加CVer小助手微信,便可申请加入CVer-Mamba和医学影像微信交流群。另外其他垂直方向已涵盖:目标检测、图像分割、目标跟踪、人脸检测&识别、OCR、姿态估计、超分辨率、SLAM、医疗影像、Re-ID、GAN、NAS、深度估计、自动驾驶、强化学习、车道线检测、模型剪枝&压缩、去噪、去雾、去雨、风格迁移、遥感图像、行为识别、视频理解、图像融合、图像检索、论文投稿&交流、PyTorch、TensorFlow和Transformer、NeRF、3DGS、Mamba等。
一定要备注:研究方向+地点+学校/公司+昵称(如Mamba和医学影像+上海+上交+卡卡),根据格式备注,可更快被通过且邀请进群▲扫码或加微信号: CVer111,进交流群
CVer计算机视觉(知识星球)来了!想要了解最新最快最好的CV/DL/AI论文速递、优质实战项目、AI行业前沿、从入门到精通学习教程等资料,欢迎扫描下方二维码,加入CVer计算机视觉(知识星球),已汇集上万人!
▲扫码加入星球学习▲点击上方卡片,关注CVer公众号
整理不易,请赞和在看

















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









