






点击下方卡片,关注“CVer”公众号
AI/CV重磅干货,第一时间送达
国庆节最大福利来了!CVer学术星球新人50元优惠券(左图)!老用户7折+20元续费券(右图)!已汇集数万人!每天分享最新顶会/顶刊上的论文idea和CV从入门到精通资料!发论文/搞科研/涨薪,强烈推荐大家加入学习!

SURE-OOD:ECCV’24 Semantic Shifts Benchmark挑战赛Open-Set Recognition track(SSB-OSR)冠军方案

在这篇文章中,我们将介绍刚刚结束的2024年ECCV上Semantic Shifts Benchmark挑战赛中Open-Set Recognition track的冠军方案,此次比赛的冠军由专注边缘侧AI英特灵达人工智能实验室(Intellindust AI Lab)获得。
• Code SURE:
https://yutingli0606.github.io/SURE/• Code SURE-OOD:
https://github.com/LIYangggggg/SSB-OSR• Tech. Report:
https://github.com/LIYangggggg/SSB-OSR/blob/main/docs/SURE_OOD.pdf• 知乎链接:
https://zhuanlan.zhihu.com/p/747137520
SSB-OSR的背景
开放集识别 (Open-Set Recognition, OSR) 是分布外检测(Out-of-Distribution, OOD)的一个子问题。不同的是OSR限定了不会借助额外的OOD 数据进行模型训练。
如下图:
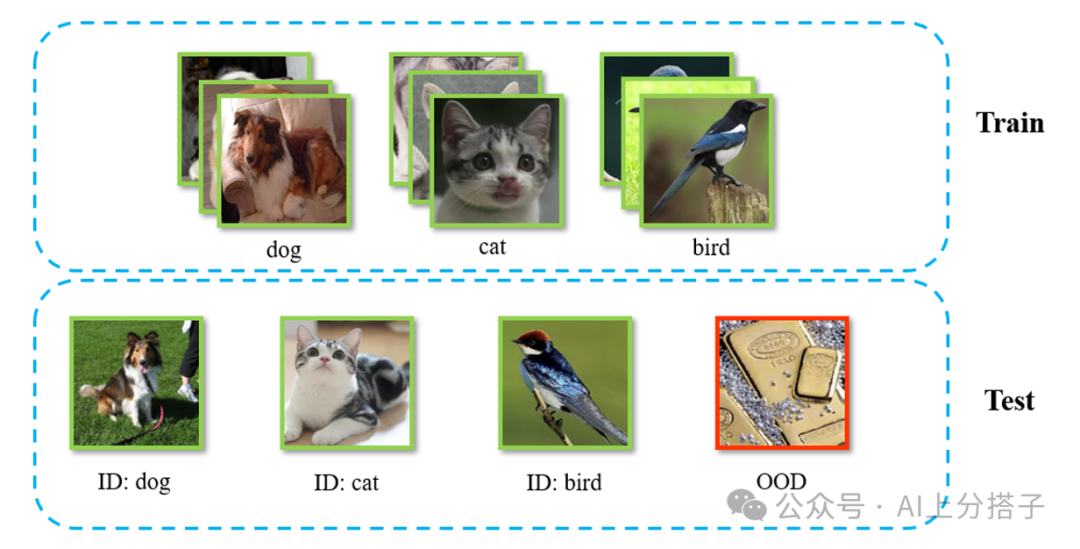
在这个问题中,数据分布的偏移通常分为两类:语义偏移 (Semantic Shift) 和 协变量偏移 (Covariate Shift)。语义偏移是指样本的类别超出了模型的训练范围,例如猫狗分类器遇到了鸟类图片;协变量偏移则是指输入特征发生变化,但类别本身未变,例如图片风格发生改变。

本次challenge聚焦在语义偏移上,故简称为SSB-OSR.
比赛限制 比赛规定,只能用ImageNet-1K [10] 训练集来训练模型,测试集则包括ImageNet-1K的验证集作为ID样本和ImageNet-21K中筛选出来的OOD 样本。
SURE-OOD [2]
SURE [1]
作者基于CVPR 2024的工作 SURE [1] 搭建了baseline,SURE [1] 的目标是训练一个reliable和robust的分类器。该方法集成了多项技术,包括 RegMixup [3]、Correctness Ranking Loss (CRL [4])、Cosine Similarity Classifier (CSC [5])、Stochastic Weight Averaging (SWA [6]) 和 Sharpness-aware Minimization (SAM [7])。
RegMixup [3]. Basic idea 是不将Mixup [8] 当做单纯的data augmentation,而是将mixed images 的损失作为额外的regularization,正则的程度由一个hyper-parameter来控制。
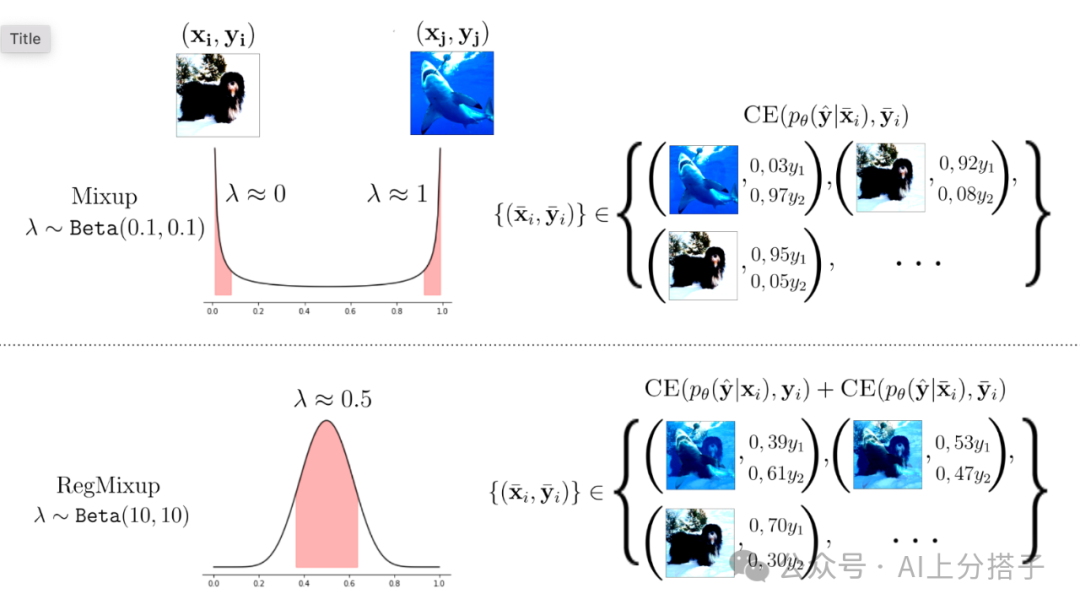
注意Mixup时Beta distribution需要sample的权重接近0 和 1 的值,也就是上面提到的Beta(0.1, 0.1),而在RegMixup中,sample的权重可以更flexible,对应的Beta(10, 10)。
Mixup [8] 的细节可见:https://github.com/YutingLi0606/SURE/blob/main/train.py#L7-L24
其实完整的代码也不长,我们直接Po出来看看,注意这里实现的细节在一个batch 里直接mix不同的sample,相对于在dataloader里做,效率会高很多:
class Mixup_Criterion(nn.Module):
def __init__(self, beta, cls_criterion):
super().__init__()
self.beta = beta
self.cls_criterion = cls_criterion
def get_mixup_data(self, image, target) :
beta = np.random.beta(self.beta, self.beta)
index = torch.randperm(image.size()[0]).to(image.device)
shuffled_image, shuffled_target = image[index], target[index]
mixed_image = beta * image + (1 - beta) * shuffled_image
return mixed_image, shuffled_target, beta
def forward(self, image, target, net):
mixed_image, shuffled_target, beta = self.get_mixup_data(image, target)
pred_mixed = net(mixed_image)
loss_mixup = beta * self.cls_criterion(pred_mixed, target) + (1 - beta) * self.cls_criterion(pred_mixed, shuffled_target)
return loss_mixup作为Regularization的代码可见:https://github.com/YutingLi0606/SURE/blob/main/train.py#L97
代码也不复杂,我们可以看看:
...
loss_ce = cls_criterion(output, target)
mixup_criterion.get_mixup_data(image, target)
loss_mixup = mixup_criterion(image, target, net)
loss_crl = rank_criterion(output, image_idx, correct_log)
loss = loss_ce + args.mixup_weight * loss_mixup + args.crl_weight * loss_crl
...CRL [4]. 一个非常有意思的想法。作者发现,样本在训练过程中,统计的正确预测(correctness statistics)的次数,和样本的难易程度由一定关联,于是期望在训练过程中,对齐样本正确次数和预测的置信度。具体的优化损失如下公式:
其中
• 正比于样本正确预测的次数统
• 是通过神经网络预测的概率
• g是一个符号函数,
if c_i > c_j :
g(c_i, c_j) = 1
elif c_i == c_j :
g(c_i, c_j) = 0
else:
g(c_i, c_j) = -1简单的理解,其实是当时,希望神经网络预测的也要比大。
具体的实现,在这里 https://github.com/YutingLi0606/SURE/blob/main/train.py#L26-L88
CSC [5]. CSC 在few-shot learning 中用得很多,enforce 网络学compact representation,这样给了几个samples,通过提取了特征,就能当做class embedding 从而得到class 的得分。
具体的操作也不复杂,对class 的weight 和 样本的feature算cosine 相似度。由于cosine相似度的范围在,这作为logits输出做cross-entropy损失会让优化过程比较困难,故会乘上一个temperature的超参数将logits 的范围scaling一下:
具体的代码,可参照:
...
feature = F.normalize(feature, p=2, dim=1, eps=1e-12)
weight = F.normalize(weight, p=2, dim=0, eps=1e-12)
cls_score = tau * (torch.mm(feature, weight)) ## tau is the temperatual
...完整代码可参照:https://github.com/YutingLi0606/SURE/blob/main/model/classifier.py#L20-L26
SWA [6]. SWA本质上在模型训练的后期,做model ensemble。是非常有效的提升模型泛化性的trick, 具体包括:
1. 训练阶段:在训练过程中,随着迭代的进行,在后期从不同的学习率阶段采样权重。
2. 权重平均:将这些采样的权重进行平均,以得到更加鲁棒的最终模型权重。
公式表达为:
其中, 为每次训练迭代采样的模型权重, 为采样次数。
SWA 可以减少模型陷入“尖锐”局部最优解的风险,提高泛化性能。关于SWA,Pytorch也专门出了blog来介绍, 见 https://pytorch.org/blog/stochastic-weight-averaging-in-pytorch/ 值得一提的是,SWA需要learning rate稍大一些,例如在SURE中,--swa-lr 被设置为0.05。
可见:https://github.com/YutingLi0606/SURE/blob/main/utils/option.py#L55-L56
SAM [7]. SAM旨在提高深度学习模型的泛化能力。与传统的优化方法不同,SAM 通过在损失函数的邻域中寻找最小值来增强模型对输入扰动的鲁棒性。具体而言,SAM 通过以下步骤进行优化:
1. 计算损失:首先计算模型在当前参数下的损失 。
2. 计算扰动:寻找一个小的扰动 ,使得损失在该点附近的最大值最小化,即:使得
3. 更新参数:使用计算出的扰动更新参数:
通过这种方式,SAM 使得模型在损失函数的“尖锐”区域变得更加平滑,从而提高了其在未见样本上的表现。
具体SAM代码可见:https://github.com/YutingLi0606/SURE/blob/main/utils/sam.py 使用SAM优化需要参照:https://github.com/YutingLi0606/SURE/blob/main/optim.py#L21-L36 以及 https://github.com/YutingLi0606/SURE/blob/main/train.py#L136-L139
实验结果 由于计算资源有限,作者使用DeiT3 [9]中的Base模型作为baseline,在ImageNet-1K [10] 使用SURE微调,使用 RP + GradNorm [11, 12]作为post-hoc分数,在challenge 的测试数据上,对比DeiT-B的性能如下:
| Methods | AUROC ↑ | FPR@TPR95 ↓ |
| DeiT-B [9] | 34.28 | 96.86 |
| DeiT-B [9] +SURE [1] | 79.97 | 68.03 |
OOD 的指标得到了大幅度的提升,我们可视化一下ID 和 OOD 样本的分数分布,可得到图:
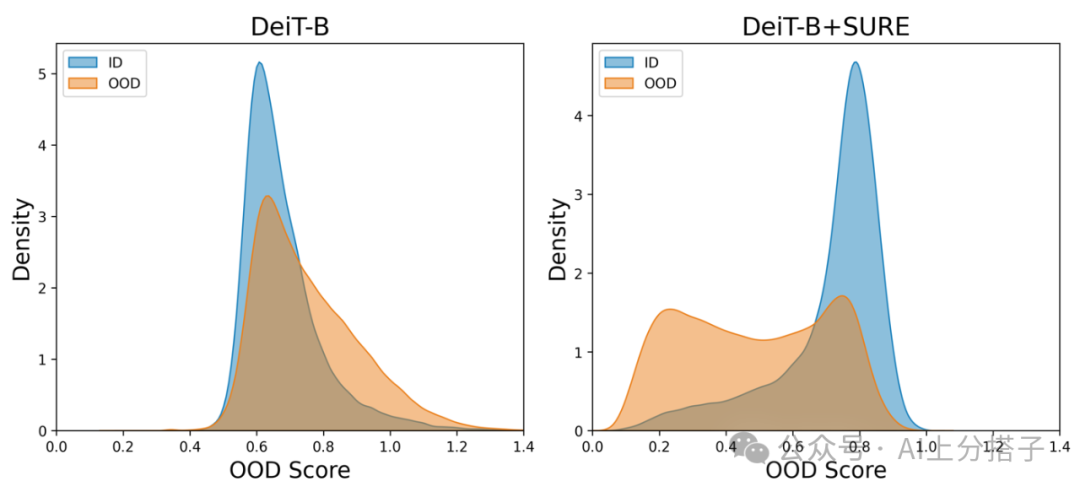
可看出来,加上SURE以后,ID 和 OOD 分数会相对更容易分开。
Post-hoc Ablation
Post-hoc方法指的是在模型训练后对已有模型进行分析和调整,以提高其在未见样本上的表现。这类方法通常不需要重新训练模型,而是基于模型的输出进行后处理。 作者测试了几种经典的Post-Hoc 的方法:
1. MSP (Maximum Softmax Probability) [15]:
• 通过计算模型输出的最大softmax概率来进行 OOD 检测。若最大概率低于设定阈值,则标记为 OOD。
•
2. ODIN [15]:
• 在模型输出后应用温度缩放和小扰动,以提高对 OOD 样本的识别能力。使用优化后的置信度作为判断依据。
•
• 其中, 是模型输出, 是温度参数。
3. ENERGY [16]:
• 基于模型输出的能量(通常是未进行softmax的 logits),通过计算能量值来判断样本是否为 OOD。
•
• OOD 样本的能量通常较高。
4. GradNorm [11]:
• 利用梯度信息来评估样本的 OOD 性。通过计算输入样本对模型输出的梯度,异常样本的梯度会表现出较大的不确定性。
•
5. Class Prior [12]:
• 利用类别的先验分布来调整模型输出。通过引入每个类别的先验概率,来判断样本是否为 OOD。
•
• 其中, 是类别的先验概率。
实验结果 这里作者使用DeiT3 [9]中的Base模型加上SURE [1]微调作为训练好的模型来测试不同post-hoc方法,在challenge 的测试数据[13]上结果如下:
| Methods | AUROC ↑ | FPR@TPR95 ↓ |
| MSP [15] | 76.09 | 73.02 |
| ODIN [16] | 77.79 | 71.76 |
| Energy [17] | 77.16 | 70.01 |
| GradNorm [11] | 57.29 | 70.35 |
| RP + MSP [15, 12] | 76.12 | 73.19 |
| RW + ODIN [16, 12] | 76.49 | 71.88 |
| RW + Energy [17, 12] | 77.71 | 71.08 |
| RP + GradNorm [11, 12] | 79.97 | 68.03 |
RP + GradNorm 的代码如下:https://github.com/LIYangggggg/SSB-OSR/blob/main/utils/test_osr_ood.py#L25-L55
其他tricks
此外,还有一些常见的tricks可以用来提升效果:提升测试图片到480*480,test-time augmentation (Five Crop),model ensemble等等。使用 RP + GradNorm [11, 12]作为post-hoc分数,在challenge 的测试数据上,作者得到以下结果:
| Methods | AUROC ↑ | FPR@TPR95 ↓ |
| SURE | 79.97 | 68.03 |
| SURE w/o LN | 80.25 | 64.59 |
| SURE(480p) w/o LN | 80.31 | 64.25 |
| SURE(480p) w/o LN + Ensemble | 80.61 | 63.58 |
| SURE(480p) w/o LN + Ensemble + FCrop | 81.54 | 61.72 |
值得一提的是,作者发现,去掉最后的Layer Normalization (LN [16]) 会有很明显的提升。这也和LogitNorm [18] 的发现一致:去除归一化可以帮助生成更具可区分性的置信度评分 (more distinguishable confidence scores),从而更好地区分ID和OOD。
总结
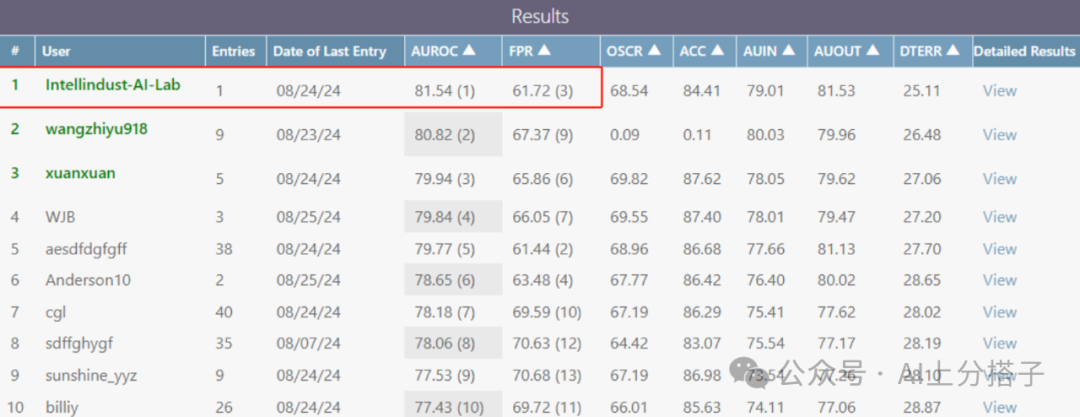
最终,作者取得了81.54的AUROC和61.72的FPR,综合表现位列第一,同时ID的准确率保持在84.41。值得注意的是,这一成果仅依赖于DeiT-B这种相对较小的模型。可以预期,结合更强大的模型,这套方案将会取得更佳效果。
参考文献
• [1] SURE; Li et al. "SURE: SUrvey REcipes for building reliable and robust deep networks", CVPR 2024.
• [2] SURE-OOD; Li et al. "SURE-OOD: Detecting OOD samples with SURE", ECCV 2024 SSB-OSR Winner.
• [3] RegMixup; Pinto et al. "RegMixup: Mixup as a Regularizer Can Surprisingly Improve Accuracy and Out Distribution Robustness", NeurIPS 2022.
• [4] CRL; Moon et al. "Confidence-aware learning for deep neural networks", ICML 2020.
• [5] CSC; Gidaris and Komodakis. "Dynamic few-shot visual learning without forgetting" CVPR, 2018.
• [6] SWA; Izmailov et al. "Averaging weights leads to wider optima and better generalization" UAI 2018.
• [7] SAM; Foret et al. "Sharpness-aware minimization for efficiently improving generalization" ICLR, 2021.
• [8] Mixup; Zhang et al. "mixup: Beyond empirical risk minimization" ICLR 2018.
• [9] DeiT; Touvron et al. "Deit iii: Revenge of the vit." ECCV, 2022.
• [10] ImageNet-1K; Deng et al. "Imagenet: A large-scale hierarchical image database." CVPR, 2009.
• [11] GradNorm; Huang et al. "On the importance of gradients for detecting distributional shifts in the wild." NeurIPS, 2021
• [12] RP; Jiang et al. "Detecting out-of-distribution data through in-distribution class prior." ICML, 2023.
• [13] ImageNet-21K; Ridnik et al. "Imagenet-21k pretraining for the masses." NeurIPS Track on Datasets and Benchmarks, 2021
• [14] MSP; Dan et al. "A baseline for detecting misclassified and out-of-distribution examples in neural networks." ICLR, 2017.
• [15] ODIN; Liang et al. "Enhancing the reliability of out-of-distribution image detection in neural networks." ICLR, 2018.
• [16] Energy; Liu et al. "Energy-based Out-of-distribution Detection." NeurIPS, 2020.
• [17] LN; Ba et al.. "Layer normalization." arXiv, 2016.
• [18] LogitNorm; Wei et al. "Mitigating neural network overconfidence with logit normalization." ICML, 2022.
国庆节最大福利来了!CVer学术星球新人50元优惠券(左图)!老用户7折+20元续费券(右图)!已汇集数万人!每天分享最新顶会/顶刊上的论文idea和CV从入门到精通资料!发论文/搞科研/涨薪,强烈推荐大家加入学习!

何恺明在MIT授课的课件PPT下载
在CVer公众号后台回复:何恺明,即可下载本课程的所有566页课件PPT!赶紧学起来!
ECCV 2024 论文和代码下载
在CVer公众号后台回复:ECCV2024,即可下载ECCV 2024论文和代码开源的论文合集CVPR 2024 论文和代码下载
在CVer公众号后台回复:CVPR2024,即可下载CVPR 2024论文和代码开源的论文合集Mamba、多模态和扩散模型交流群成立
扫描下方二维码,或者添加微信号:CVer111,即可添加CVer小助手微信,便可申请加入CVer-Mamba、多模态学习或者扩散模型微信交流群。另外其他垂直方向已涵盖:目标检测、图像分割、目标跟踪、人脸检测&识别、OCR、姿态估计、超分辨率、SLAM、医疗影像、Re-ID、GAN、NAS、深度估计、自动驾驶、强化学习、车道线检测、模型剪枝&压缩、去噪、去雾、去雨、风格迁移、遥感图像、行为识别、视频理解、图像融合、图像检索、论文投稿&交流、PyTorch、TensorFlow和Transformer、NeRF、3DGS、Mamba等。 一定要备注:研究方向+地点+学校/公司+昵称(如Mamba、多模态学习或者扩散模型+上海+上交+卡卡),根据格式备注,可更快被通过且邀请进群▲扫码或加微信号: CVer111,进交流群 CVer计算机视觉(知识星球)来了!想要了解最新最快最好的CV/DL/AI论文速递、优质实战项目、AI行业前沿、从入门到精通学习教程等资料,欢迎扫描下方二维码,加入CVer计算机视觉(知识星球),已汇集上万人! ▲扫码加入星球学习▲点击上方卡片,关注CVer公众号 整理不易,请赞和在看


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









