






点击下方卡片,关注“CVer”公众号
AI/CV重磅干货,第一时间送达
添加微信:CVer2233,助手会拉你进群!
扫描下方二维码,加入CVer学术星球!可获得最新顶会/顶刊上的论文idea和CV从入门到精通资料,及最前沿应用!发论文/搞科研/涨薪必备!

转载自:机器之心
本文一作为唐正纲,目前为博士生,就读于伊利诺伊大学厄巴纳 - 香槟分校,本科毕业于北京大学。通讯作者是严志程,Meta Reality Labs 高级科研研究员 (Senior Staff Research Scientist),主要研究方向包括三维基础模型,终端人工智能 (On-device AI) 和混合现实。
近期,Fei-Fei Li 教授的 World Labs 和 Google 的 Genie 2 展示了 AI 从单图生成 3D 世界的能力。这技术让我们能步入任何图像并以 3D 形式探索,预示着数字创造的新未来。
Meta 也加入了这场构建世界模型的竞赛,推出并且开源了全新的世界模型构建基座模型 MV-DUSt3R+。Meta 的技术通过 Quest 3 和 Quest 3S 头显,快速还原 3D 场景。只需几张照片,用户就能在 Meta 头显中体验不同的混合环境。
在这一领域,DUSt3R 曾是 SOTA 的标杆。其 GitHub 上的 5.5k star 证明了它在 3D 重建领域的影响力。然而,DUSt3R 每次只能处理两张图。处理更多图时,需要使用 bundle adjustment,这非常耗时,限制了它在复杂场景上的应用。
现在,Meta Reality Labs 和伊利诺伊大学厄巴纳 - 香槟分校(UIUC)推出了新工作《MV-DUSt3R+: Single-Stage Scene Reconstruction from Sparse Views In 2 Seconds》。这项研究全面提升了 DUSt3R。通过全新的多视图解码器块和交叉视图注意力块机制,MV-DUSt3R + 可以直接从稀疏视图中重建复杂的三维场景。而且重建只需 2 秒钟!
MV-DUSt3R + 是由 Meta 的严志程团队开发。严志程在 Meta 任 Senior Staff Research Scientist 一职,UIUC 博士,目前负责 Meta 的混合现实开发工作。文章的第一作者唐正纲,本科毕业于北京大学,目前在 UIUC 攻读博士学位,专注于 3D 视觉研究。团队其他成员在 3D 场景重建和生成模型领域也经验丰富。
MV-DUSt3R + 的技术贡献包括:
单阶段场景重建:2 秒内完成复杂三维场景的重建。
多视图解码器块:无需相机校准和姿态估计,处理任意数量的视图。
交叉视图注意力块:增强对不同参考视图选择的鲁棒性。

论文链接:https://arxiv.org/abs/2412.06974
项目主页:https://mv-dust3rp.github.io/
代码仓库:https://github.com/facebookresearch/mvdust3r/
MV-DUSt3R+ 效果演示
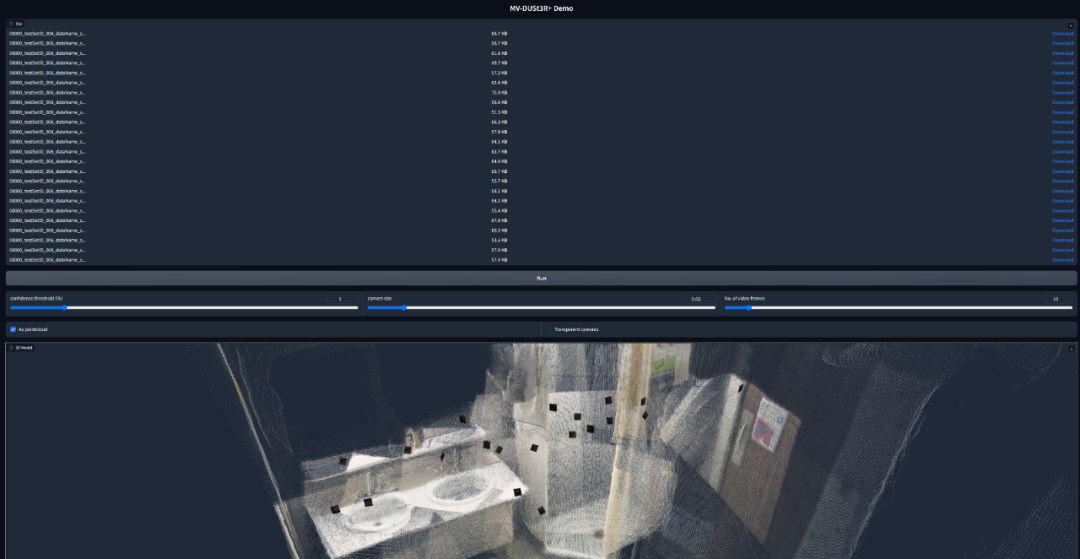
MV-DUSt3R + 的 Github 代码仓库里还包含一个基于 Gradio 的互动演示。用户可以输入多张视图或者一个场景视频。演示能够显示由 MV-DUSt3R + 重建的点云和各个输入视图的相机姿态。
方法概述
单阶段场景重建
2 秒内完成复杂三维场景的重建。传统方法通常采用分阶段处理流程,包括相机姿态估计、局部重建,以及全局优化来对齐各个局部重建结果。这种方法不仅流程繁琐,而且容易在多个步骤中累积误差。此外,全局优化步骤需要大量计算资源,尤其在处理大规模场景时,计算时间往往从几十秒延长到数分钟,难以满足实时应用的需求。
为了解决这些问题,MV-DUSt3R+ 提出了单阶段场景重建框架,通过一次前向推理即可完成整个重建流程。这种方法完全摒弃了传统方法中的全局优化步骤,而是通过高效的神经网络架构直接输出全局对齐的三维点云。
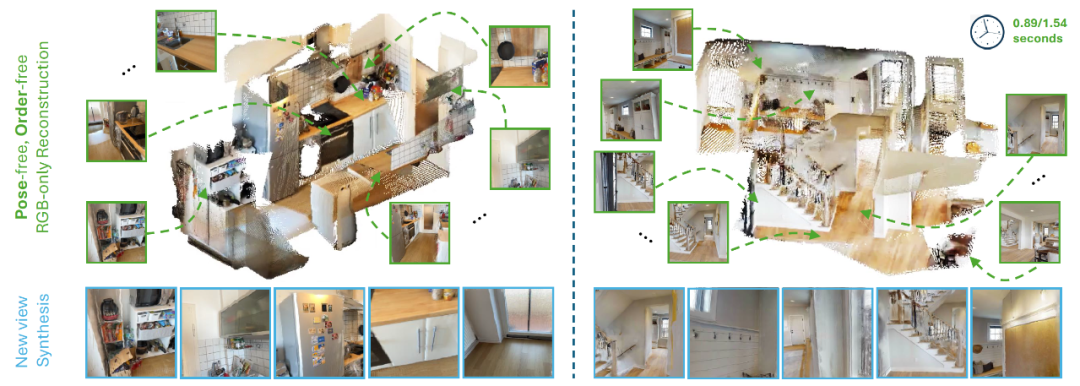
在实验中,MV-DUSt3R+ 展现了效率优势:在处理 12 至 24 个视角输入时,仅需 0.89 至 1.54 秒即可完成大规模、多房间场景的重建。这一性能比传统的 DUSt3R 方法快了 48 至 78 倍,同时在重建质量上也显著提升。单阶段的设计不仅提升了计算效率,还降低了硬件资源的消耗,为实时三维场景重建在混合现实、自动驾驶、机器人导航等领域的应用铺平了道路。
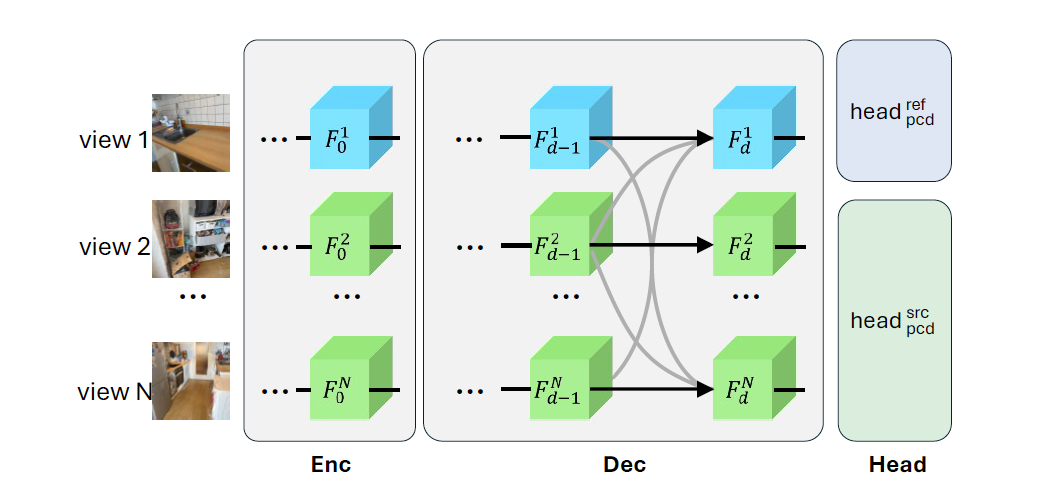
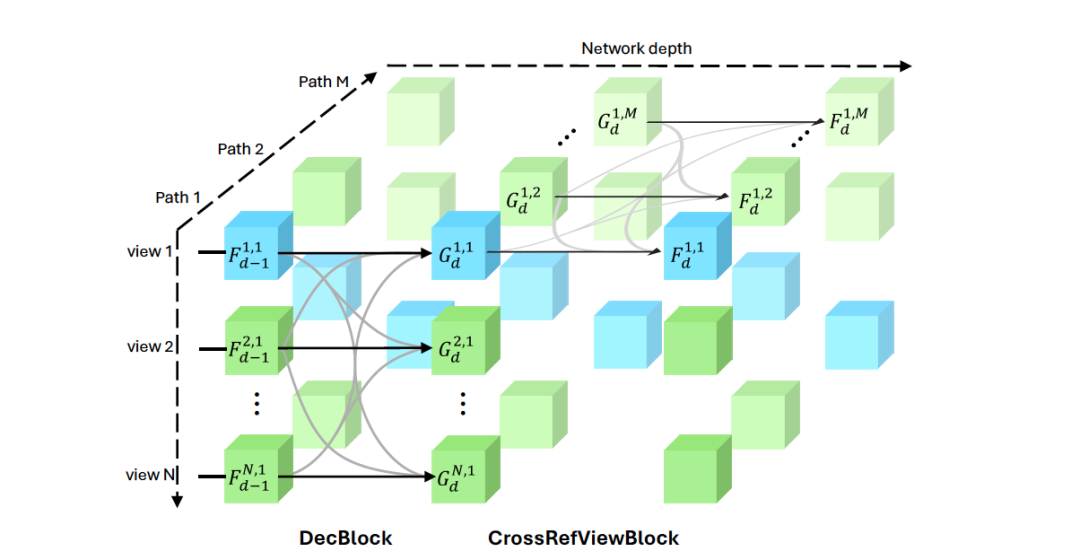
多视图解码器块
无需相机校准和姿态估计,处理任意数量的视图。在多视角重建任务中,传统方法通常依赖于相机内参和外参的精确估计,这需要额外的相机校准步骤,增加了系统复杂性和误差风险。
即便是一些最新的学习方法,如 DUSt3R 和 MASt3R,也只能处理两视角重建,并需要在后续步骤中进行全局优化来对齐多视角信息。这种方法在处理大场景和稀疏视角输入时,表现出明显的局限性。
MV-DUSt3R+ 通过引入多视图解码器块,彻底摆脱了对相机参数的依赖,能够直接处理任意数量的视角输入。具体来说,多视图解码器块在网络中充当信息融合的关键角色,通过注意力机制在参考视图和所有其他视图之间进行高效信息交换。
与传统的两视角方法不同,MV-DUSt3R+ 可以一次性处理多达 24 个视角,并在所有视角之间联合学习空间关系。这种设计确保了重建结果在全局范围内的一致性和准确性。
多视图解码器块的设计还具有极高的灵活性:无论输入视角数量多少,网络都能保持高效运行,而无需重新训练或调整参数。这使得 MV-DUSt3R+ 能够适应各种实际应用场景,从小型单房间到大型多房间甚至室外场景,均能实现高质量的三维重建。
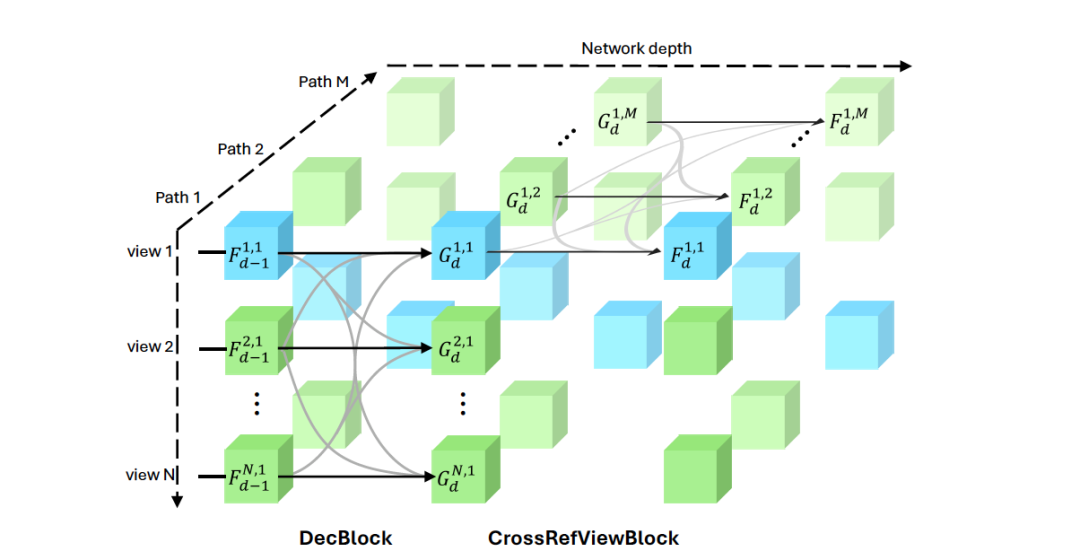
交叉视图注意力块
增强对不同参考视图选择的鲁棒性。在大规模场景重建中,单一参考视图往往无法覆盖所有细节,特别是在视角变化较大的情况下,重建质量容易出现区域性偏差。为了克服这一挑战,MV-DUSt3R+ 在多视图解码器的基础上引入了交叉视图注意力块,以增强对不同参考视图选择的鲁棒性。
交叉视图注意力块通过在多个参考视图之间进行信息融合,有效缓解了单一视图信息不足的问题。具体而言,该模块在网络的多个路径中运行,每条路径对应一个不同的参考视图。通过在不同参考视图路径之间交换和融合特征,交叉视图注意力块能够捕获长距离的几何信息,确保在大场景重建中,所有区域的重建质量都能保持一致。
这种机制的优势在于,即使某些输入视图与单一参考视图之间的立体信息较弱,也可以从其他参考视图中获取补充信息,从而提高整体重建精度。在实验中,MV-DUSt3R+ 展现了出色的鲁棒性:在多房间和稀疏视角设置下,重建结果的误差显著降低,同时在新视角合成任务中生成的图像也更为精确,真实感更强。
主要实验结果
大量实验验证了 MV-DUSt3R+ 在多视角立体重建、多视角相机位姿估计和新视图合成任务中的性能提升。请参考文章详细的实现细节以及表格对比,实验结果如下所示。
数据集
训练数据包括 ScanNet、ScanNet++、HM3D 和 Gibson,测试数据为 MP3D、HM3D 和 ScanNet。以下为数据集特性表(表 1):
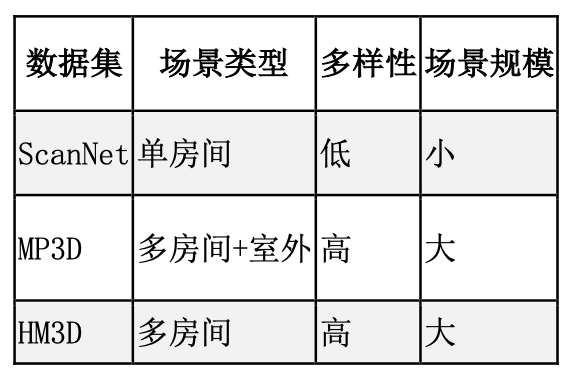
表 1: 训练与测试数据集对比
该团队采用与 DUSt3R 相同的训练 / 测试划分,训练数据为其子集(详见附录)。通过随机选择初始帧并逐步采样候选帧(点云重叠率在 [t_min, t_max] 范围内),生成输入视图集合 {Iₙ}。
轨迹采样
ScanNet 和 ScanNet++ 每场景采样 1,000 条轨迹,总计 320 万条;HM3D 和 Gibson 每场景采样 6,000 条,总计 780 万条。具体实现细节请参考论文原文。
多视角立体重建
采用 Chamfer Distance (CD)、Normalized Distance (ND) 和 Distance Accuracy@0.2 (DAc) 作为评估指标。结果显示:
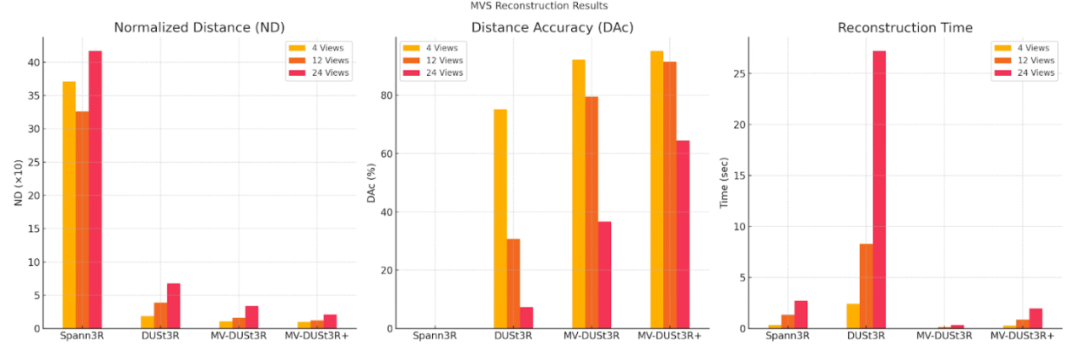
MV-DUSt3R:在 HM3D 数据集上,与 DUSt3R 相比,ND 降低 1.7 至 2 倍,DAc 提升 1.2 至 5.3 倍。随着输入视图数量增加,重建质量显著提升。
MV-DUSt3R+:12 视图输入下,ND 降低 1.3 倍,DAc 提升 1.2 倍。24 视图输入下,ND 降低 1.6 倍,DAc 提升 1.8 倍,表现更优。
零样本测试:在 MP3D 数据集上,MV-DUSt3R 和 MV-DUSt3R+ 始终优于 DUSt3R,展现了强大的泛化能力。
多视角相机位姿估计
MV-DUSt3R 和 MV-DUSt3R+ 在相机位姿估计中显著优于基线。
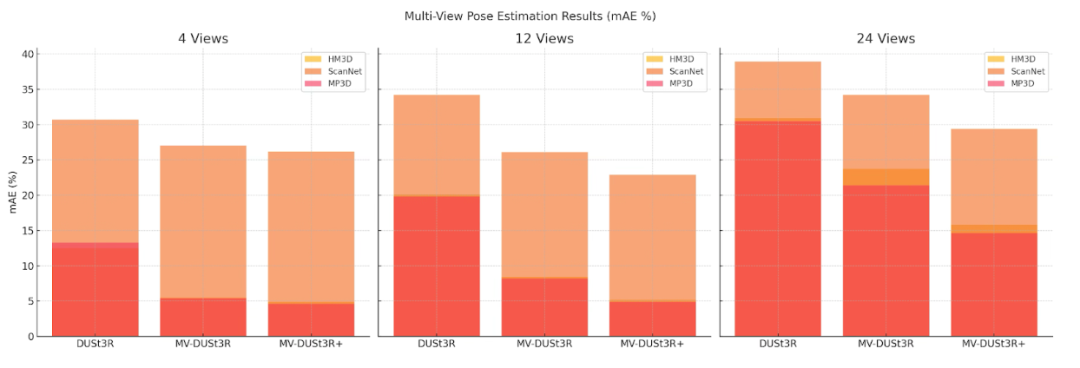
HM3D:MV-DUSt3R 的 mAE 相比 DUSt3R 降低 2.3 至 1.3 倍,MV-DUSt3R+ 降低 2.6 至 2.0 倍。
其他数据集:MV-DUSt3R+ 始终优于 DUSt3R,表现最佳。
新视图合成
该团队采用了 PSNR、SSIM 和 LPIPS 来评估生成质量。
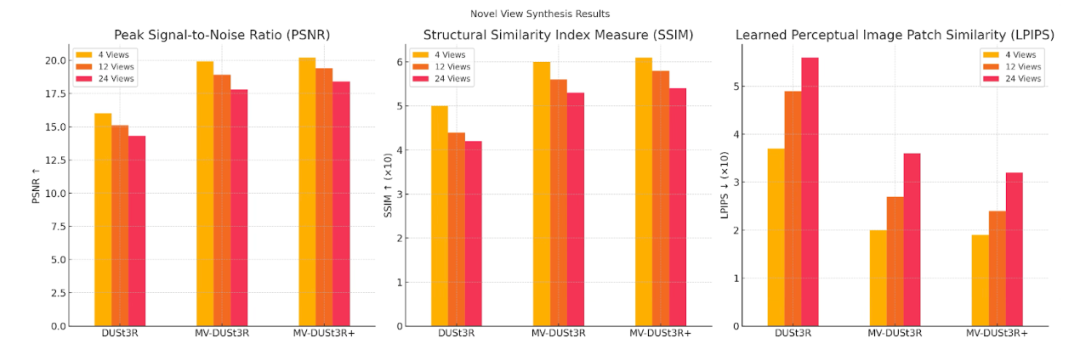
PSNR:MV-DUSt3R+ 在所有视图设置下表现最佳,显著提升重建质量。
SSIM:MV-DUSt3R+ 结构相似性最高,随着视图增加视觉保真度进一步提高。
LPIPS:MV-DUSt3R+ 感知误差最低,生成的新视图最接近真实图像。
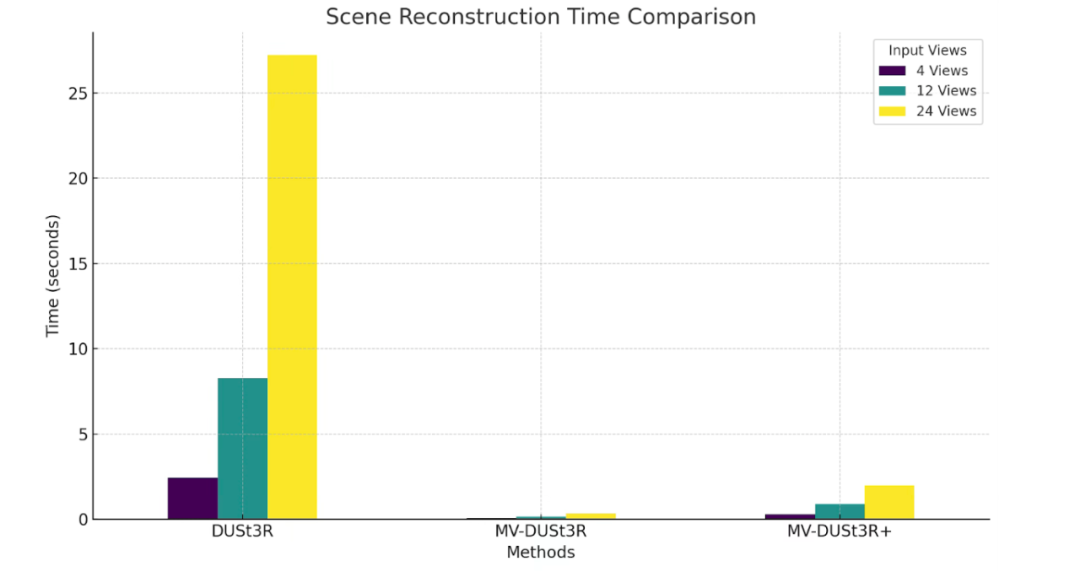
场景重建时间
MV-DUSt3R+ 的单阶段网络在 GPU 上运行,无需全局优化(GO),显著减少了重建时间。
MV-DUSt3R+:在 24 视图输入下,仅需 1.97 秒,速度比 DUSt3R 快 14 倍。
MV-DUSt3R:时间更短,仅需 0.35 秒,比 DUSt3R 快 78 倍。
DUSt3R:重建时间明显更长,24 视图输入需 27.21 秒。
MV-DUSt3R+ 在不到 2 秒内即可完成大场景重建,展现出卓越的效率与实用性。
总结和开放讨论
最近一年以来,三维基座模型的新工作层出不穷,包括三维重建(比如 DUSt3R, MASt3R, MASt3R-SfM)和三维生成(比如 World Labs 3D Gen, Stability AI Stable Point Aware 3D)。
这些工作在模型创新上和实际效果上都取得了令人印象深刻的进步,使得三维感知和生成技术更容易在混合现实,自动驾驶,大规模数字城市这些领域被广泛应用。
在这些工作当中,MV-DUSt3R + 凭借其简洁有效的模型设计,快速的推理,不依赖于相机参数的先验知识和显著提高的重建质量脱颖而出,正在学界和开源社区获得越来越广泛的关注。
作者简介
唐正纲:伊利诺伊大学厄巴纳 - 香槟分校博士生,本科毕业于北京大学。研究方向是三维视觉,场景重建,变换和编辑。

严志程: Meta 高级科研研究员,博士毕业于美国伊利诺伊大学厄巴纳 - 香槟分校,本科毕业于浙江大学。主要研究方向包括三维基础模型,终端人工智能 (On-device AI) 和混合现实。

范雨晨: Meta 科研研究员,博士毕业于美国伊利诺伊大学厄巴纳 - 香槟分校。研究方向包括三维生成,视频理解和图像复原。

Dilin Wang: Meta 科研研究员,博士毕业于美国得克萨斯大学奥斯汀分校。研究方向包括场景感知和三维生成。

许弘宇:Meta 科研研究员,博士毕业于美国马里兰大学。研究方向包括混合现实和视觉感知。

Alexander Schwing: 副教授,现任教于美国伊利诺伊大学厄巴纳 - 香槟分校,博士毕业于瑞士苏黎世理工学院。主要研究方向包括深度学习中的预测和学习,多变量结构化分布,以及相关应用。

Rakesh Ranjan: Meta 人工智能研究主任(Research Director),主管混合现实和三维生成。

何恺明在MIT授课的课件PPT下载
在CVer公众号后台回复:何恺明,即可下载本课程的所有566页课件PPT!赶紧学起来!
ECCV 2024 论文和代码下载
在CVer公众号后台回复:ECCV2024,即可下载ECCV 2024论文和代码开源的论文合集CVPR 2024 论文和代码下载
在CVer公众号后台回复:CVPR2024,即可下载CVPR 2024论文和代码开源的论文合集Mamba、多模态和扩散模型交流群成立
扫描下方二维码,或者添加微信号:CVer2233,即可添加CVer小助手微信,便可申请加入CVer-Mamba、多模态学习或者扩散模型微信交流群。另外其他垂直方向已涵盖:目标检测、图像分割、目标跟踪、人脸检测&识别、OCR、姿态估计、超分辨率、SLAM、医疗影像、Re-ID、GAN、NAS、深度估计、自动驾驶、强化学习、车道线检测、模型剪枝&压缩、去噪、去雾、去雨、风格迁移、遥感图像、行为识别、视频理解、图像融合、图像检索、论文投稿&交流、PyTorch、TensorFlow和Transformer、NeRF、3DGS、Mamba等。
一定要备注:研究方向+地点+学校/公司+昵称(如Mamba、多模态学习或者扩散模型+上海+上交+卡卡),根据格式备注,可更快被通过且邀请进群▲扫码或加微信号: CVer2233,进交流群
CVer计算机视觉(知识星球)来了!想要了解最新最快最好的CV/DL/AI论文速递、优质实战项目、AI行业前沿、从入门到精通学习教程等资料,欢迎扫描下方二维码,加入CVer计算机视觉(知识星球),已汇集上万人!
▲扫码加入星球学习▲点击上方卡片,关注CVer公众号
整理不易,请赞和在看

















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









