






点击下方卡片,关注“CVer”公众号
AI/CV重磅干货,第一时间送达
添加微信号:CVer2233,小助手会拉你进群!
扫描下方二维码,加入CVer学术星球!可以获得最新顶会/顶刊上的论文idea和CV从入门到精通资料,及最前沿应用!发论文/搞科研/涨薪,强烈推荐!


Q-Insight: Understanding Image Quality via Visual Reinforcement Learning
·论文作者: Weiqi Li(李玮琦), Xuanyu Zhang(张轩宇), Shijie Zhao†(赵世杰), Yabin Zhang(张亚彬), Junlin Li(李军林), Li Zhang(张莉) and Jian Zhang†(张健)(†通讯作者)
单位:北京大学信息工程学院、字节跳动
论文:https://arxiv.org/abs/2503.22679
https://github.com/lwq20020127/Q-Insight
任务背景:画质理解需求的新挑战与机遇
近年来,随着智能手机摄影、视频流媒体和AI生成内容(AIGC)的快速发展,人们对图像画质的要求持续攀升,图像质量评估(Image Quality Assessment, IQA)任务的重要性日益凸显。以往的IQA方法主要分为两类:(1)评分型方法,这类方法通常只能提供单一的数值评分,缺乏明确的解释性,难以深入理解图像质量背后的原因;(2)描述型方法,这类方法严重依赖于大规模文本描述数据进行监督微调,对标注数据的需求巨大,泛化能力和灵活性不足。针对上述问题,北大与字节跳动联合提出了基于强化学习的图像质量理解新模型—Q-Insight。与以往方法不同的是,Q-Insight不再简单地让模型拟合真实评分(GT),而是将评分视作一种引导信号,促使模型深入思考、推理图像质量的本质原因。通过这种创新思路,Q-Insight在质量评分、退化感知、多图比较、原因解释等多个任务上均达到业界领先水平,具备出色的准确性和泛化推理能力,有望为图像画质增强、AI内容生成等多个领域提供强有力的技术支撑。
主要贡献
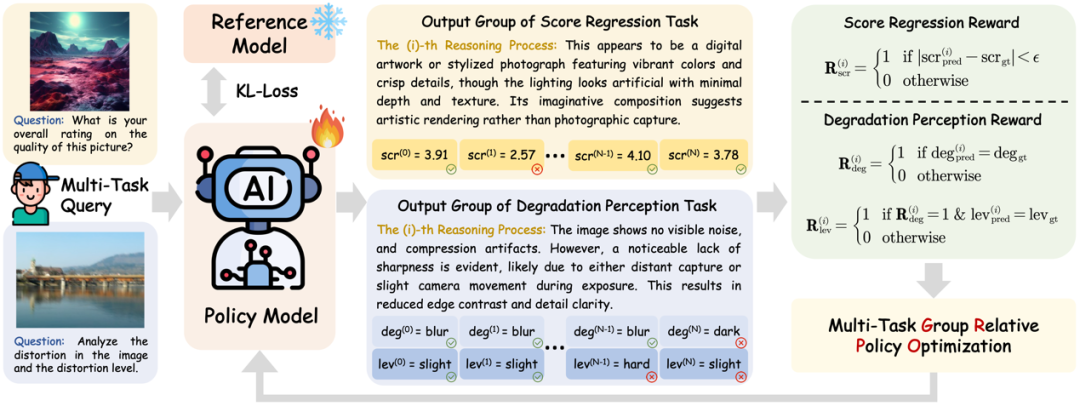
Q-Insight首次将强化学习引入图像质量评估任务,创造性地运用了“群组相对策略优化”(GRPO)算法,不再依赖大量的文本监督标注,而是挖掘大模型自身的推理潜力,实现对图像质量的深度理解。如图所示,Q-Insight不仅输出单纯的得分、退化类型或者比较结果,而是提供了从多个角度综合评估画质的详细推理过程。

在实际训练过程中,我们发现单独以评分作为引导无法充分实现良好的画质理解,原因是模型对图像退化现象不够敏感。为了解决这一问题,我们创新性地引入了多任务GRPO优化,设计了可验证的评分奖励、退化分类奖励和强度感知奖励,联合训练评分回归与退化感知任务。这种多任务联合训练的策略,显著提高了各个任务的表现,证明了任务之间存在的强互补关系。
实验结果
实验结果充分验证了Q-Insight在图像质量评分、退化检测和零样本推理任务中的卓越表现:
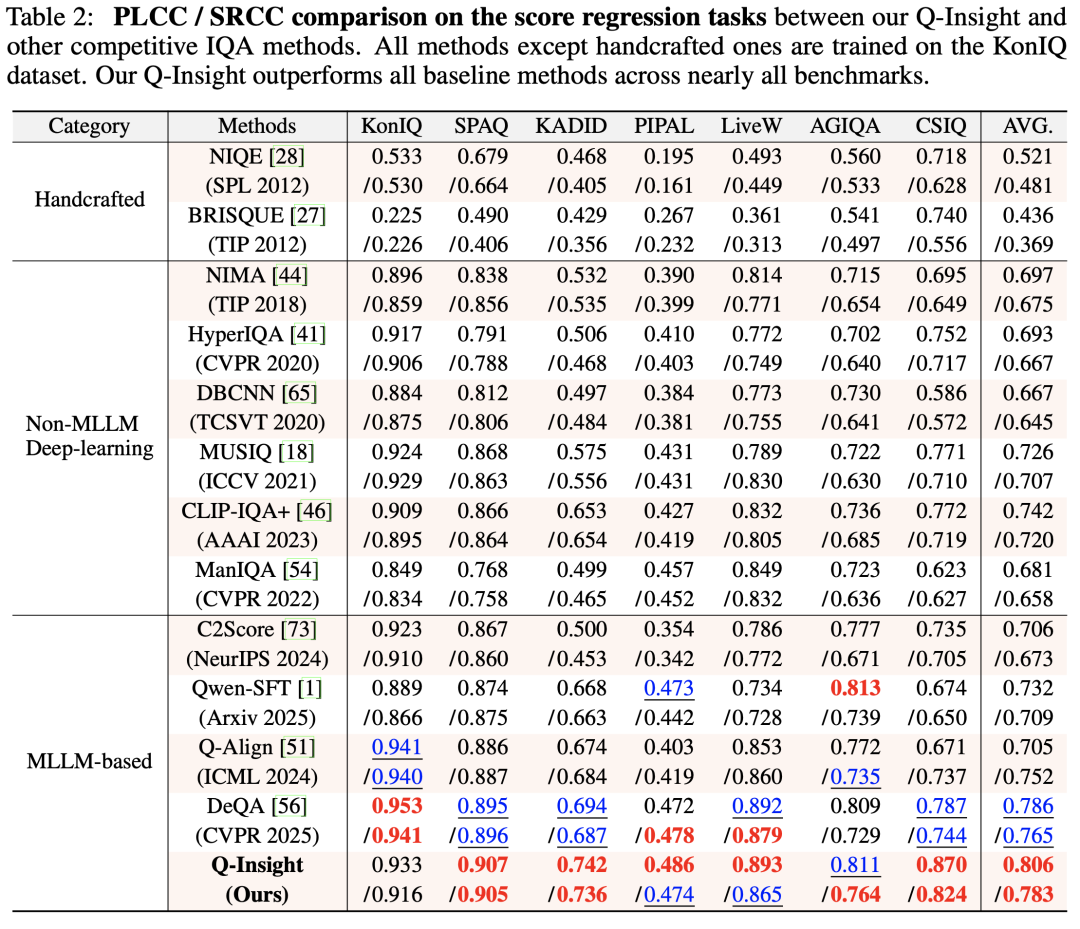
在图像质量评分任务上,Q-Insight在多个公开数据集上的表现均超过当前最先进的方法,特别是在域外数据上的泛化能力突出,并能够提供完整详细的推理过程。
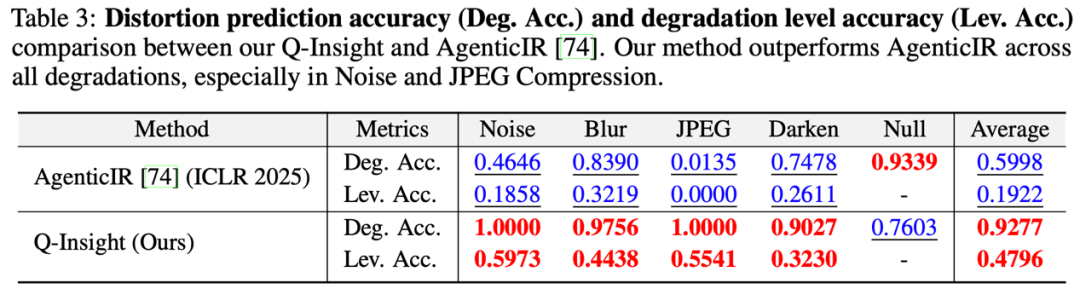
在退化感知任务上,Q-Insight的表现显著优于现有的退化感知模型,尤其是在噪声(Noise)和JPEG压缩退化类型识别的准确性上。
在零样本图像比较推理任务上,Q-Insight无需额外监督微调,即可准确、细致地分析和比较图像质量,展示出强大的泛化推理能力。

VILLA实验室简介
视觉信息智能学习实验室(VILLA)由北京大学长聘副教授张健于2019年创立,致力于视觉重建与生成、AIGC内容安全等前沿领域的研究,成立以来已在TPAMI、TIP、IJCV、CVPR、ICCV、NeurIPS等顶级期刊会议上发表论文100余篇,其开源项目在GitHub平台获得广泛关注,累计star数超过10k。实验室负责人张健副教授谷歌学术引用逾1.1万次,h-index达52,其单篇一作论文最高被引超1300次,累计荣获国际期刊/会议最佳论文奖6项及全球挑战赛冠军1项。近期代表工作包括:图像条件可控生成模型T2I-Adapter、拖拽式细粒度图像/视频编辑DragonDiffusion/ReVideo、全景视频生成模型360DVD、全景内容处理/增强方案ResVR/OmniSSR、零值域扩散重建模型DDNM、高效扩散超分方案AdcSR、动态场景重建框架HiCoM/OpenGaussian、实用图像压缩感知重建PCNet、多模态篡改检测大模型FakeShield、支持AIGC篡改定位与版权保护水印技术OmniGuard/EditGuard、多模态画质理解大模型Q-Insight等。多项技术已成功应用于产业界,获得国内外知名企业的产品化落地。实验室动态可通过官网(https://villa.jianzhang.tech/)或张健老师个人主页(https://jianzhang.tech/)查看。
何恺明在MIT授课的课件PPT下载
在CVer公众号后台回复:何恺明,即可下载本课程的所有566页课件PPT!赶紧学起来!
CVPR 2025 论文和代码下载
在CVer公众号后台回复:CVPR2025,即可下载CVPR 2025论文和代码开源的论文合集ECCV 2024 论文和代码下载
在CVer公众号后台回复:ECCV2024,即可下载ECCV 2024论文和代码开源的论文合集CV垂直方向和论文投稿交流群成立
扫描下方二维码,或者添加微信号:CVer2233,即可添加CVer小助手微信,便可申请加入CVer-垂直方向和论文投稿微信交流群。另外其他垂直方向已涵盖:目标检测、图像分割、目标跟踪、人脸检测&识别、OCR、姿态估计、超分辨率、SLAM、医疗影像、Re-ID、GAN、NAS、深度估计、自动驾驶、强化学习、车道线检测、模型剪枝&压缩、去噪、去雾、去雨、风格迁移、遥感图像、行为识别、视频理解、图像融合、图像检索、论文投稿&交流、PyTorch、TensorFlow和Transformer、NeRF、3DGS、Mamba等。 一定要备注:研究方向+地点+学校/公司+昵称(如Mamba、多模态学习或者论文投稿+上海+上交+卡卡),根据格式备注,可更快被通过且邀请进群
▲扫码或加微信号: CVer2233,进交流群
CVer计算机视觉(知识星球)来了!想要了解最新最快最好的CV/DL/AI论文速递、优质实战项目、AI行业前沿、从入门到精通学习教程等资料,欢迎扫描下方二维码,加入CVer计算机视觉(知识星球),已汇集上万人!
▲扫码加入星球学习
▲扫码或加微信号: CVer2233,进交流群
CVer计算机视觉(知识星球)来了!想要了解最新最快最好的CV/DL/AI论文速递、优质实战项目、AI行业前沿、从入门到精通学习教程等资料,欢迎扫描下方二维码,加入CVer计算机视觉(知识星球),已汇集上万人!
▲扫码加入星球学习▲点击上方卡片,关注CVer公众号 整理不易,请点赞和在看


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









