






点击下方卡片,关注“CVer”公众号
AI/CV重磅干货,第一时间送达
点击进入—>【扩散模型】投稿交流群
添加微信号:CVer2233,小助手会拉你进群!
扫描下方二维码,加入CVer学术星球!可以获得最新顶会/顶刊上的论文idea和CV从入门到精通资料,及最前沿应用!发论文/搞科研/涨薪,强烈推荐!


论文链接(已中 ACM MM 2024)
http://arxiv.org/abs/2404.09831
代码链接
https://github.com/wangjiyuan9/D4RD
WeatherKITTI数据集链接
https://wangjiyuan9.github.io/project/weatherkitti/
研究背景与问题
问题: 基于扩散模型的单目深度估计方法虽然性能优越,但在现实世界常见的恶劣条件下(如雨、雪等)通常表现不可靠。提高模型在这些挑战性环境下的鲁棒性 (robustness) 是一个关键问题。
现有挑战: 传统的鲁棒单目深度估计 (RMDE) 方法主要分为两类:
基于对比学习的对齐方法(下图b): 强制模型对清晰图像 及其增强版本 预测一致的深度 ,但容易陷入“坍塌解(全估计为0)”,缺乏完美的引导信号。
基于知识蒸馏的伪监督方法(下图a): 使用在清晰图像上训练的教师模型 估计深度 作为伪标签,来监督在恶劣条件下(输入 )的学生模型 ,但学生模型的性能受限于教师模型的准确性(存在性能上限)且在有巨大域差异时出错。
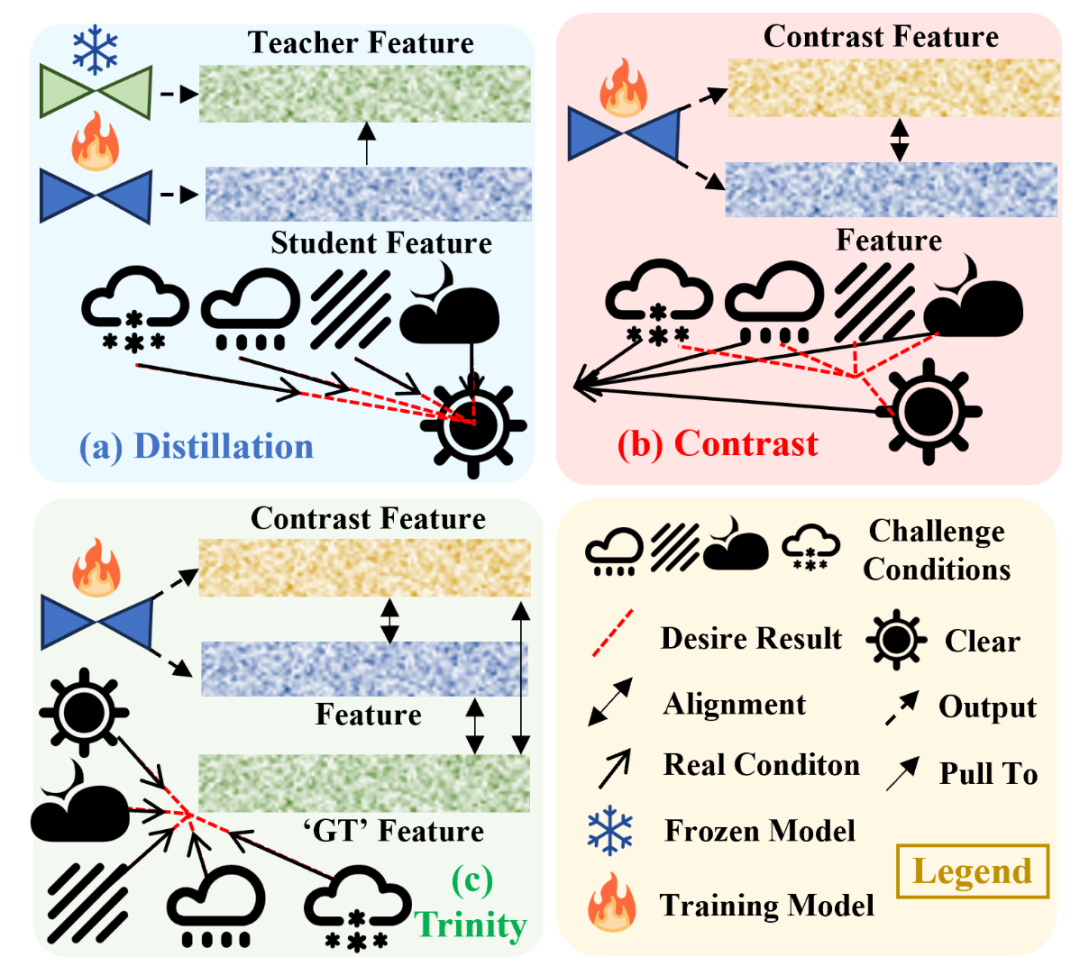
论文提出的方法 (D4RD)
核心思想: 提出了一种名为 D4RD (Diffusion for Robust Depth) 的新型鲁棒深度估计框架,该框架专门为扩散模型设计了一种定制化的对比学习模式。
“三位一体”对比方案 ('Trinity' Contrastive Scheme):
我们巧妙地利用了扩散模型前向过程中采样得到的真实高斯噪声 (见下公式) 作为一种**天然的、完美的锚点 **。
将知识蒸馏的思路与对比学习相结合:不仅要求模型对清晰图像 预测的噪声 和对增强图像 预测的噪声 尽可能一致,还引导它们共同趋近于前向过程采样的真实噪声 。这种包含三者对齐的模式通过噪声级三位一体对比损失 (noise-level trinity contrast loss, ) 实现:
优势: 相比传统对比学习(如 $ L_cst} =)| \epsilon L_dis} =) – F_T(I)| $),没有教师模型带来的性能瓶颈。
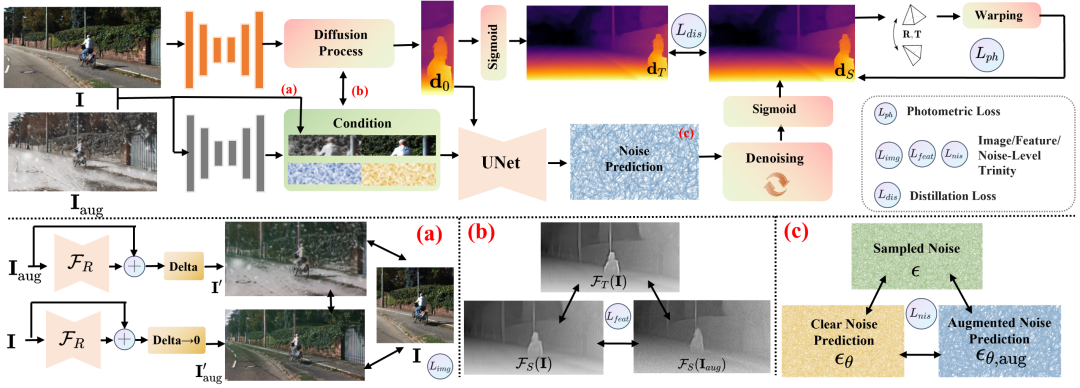
多层级对比扩展 (Multi-level Contrast):
将“三位一体”的思想从噪声预测层面 ( ) 扩展到了更通用的特征层面 (feature level) 和**图像层面 (image level)**。
在特征层面,引入**特征级三位一体损失 ( )**,利用教师模型 提取的特征 作为次优引导,对比学生模型 提取的特征 和 :
在图像层面,设计了一个简单的 CNN 网络 来增强清晰图像 得到 和增强图像 得到 $ I'{aug}* L{img} $)** 对比:
目的: 将鲁棒性感知的“压力”均匀分布到网络的多个组件(不同层级)上,从而提升整体潜力。

基线模型稳定性增强 (Baseline Stability Enhancement): 在引入核心的对比学习方案之前,本文还对作为基础的扩散模型进行了三项简单而有效的改进,以增强其稳定性和收敛性:
伪深度知识蒸馏增强: 使用动态加权的 BerHu 损失代替 L1 损失,并用自适应阈值代替固定阈值过滤伪标签。
深度值异常点移除: 使用 Sigmoid 激活函数及其逆函数处理深度值,将其约束在 [0, 1] 范围内,有效移除负值等异常点,且比 VAE 潜空间扩散更简单。
特征-图像联合条件: 将输入图像与其提取的深度相关特征进行拼接,作为扩散模型的条件输入,提供更丰富的上下文信息。
实验与结果
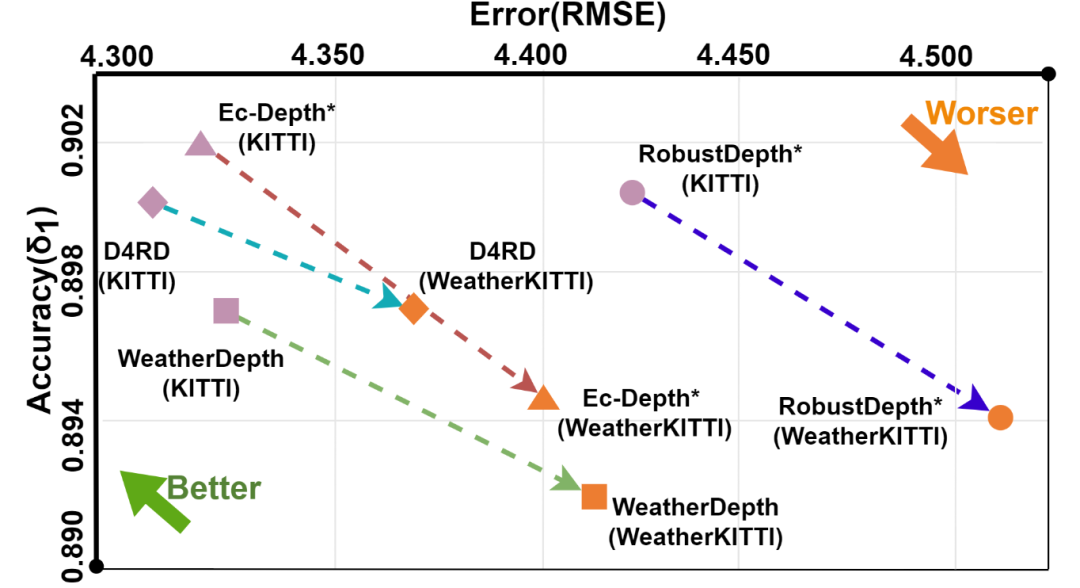
数据集: 主要在 WeatherKITTI 上训练,并在 KITTI, KITTI-C, DrivingStereo, Dense 等7个场景数据集上进行评估,均为SoTA:
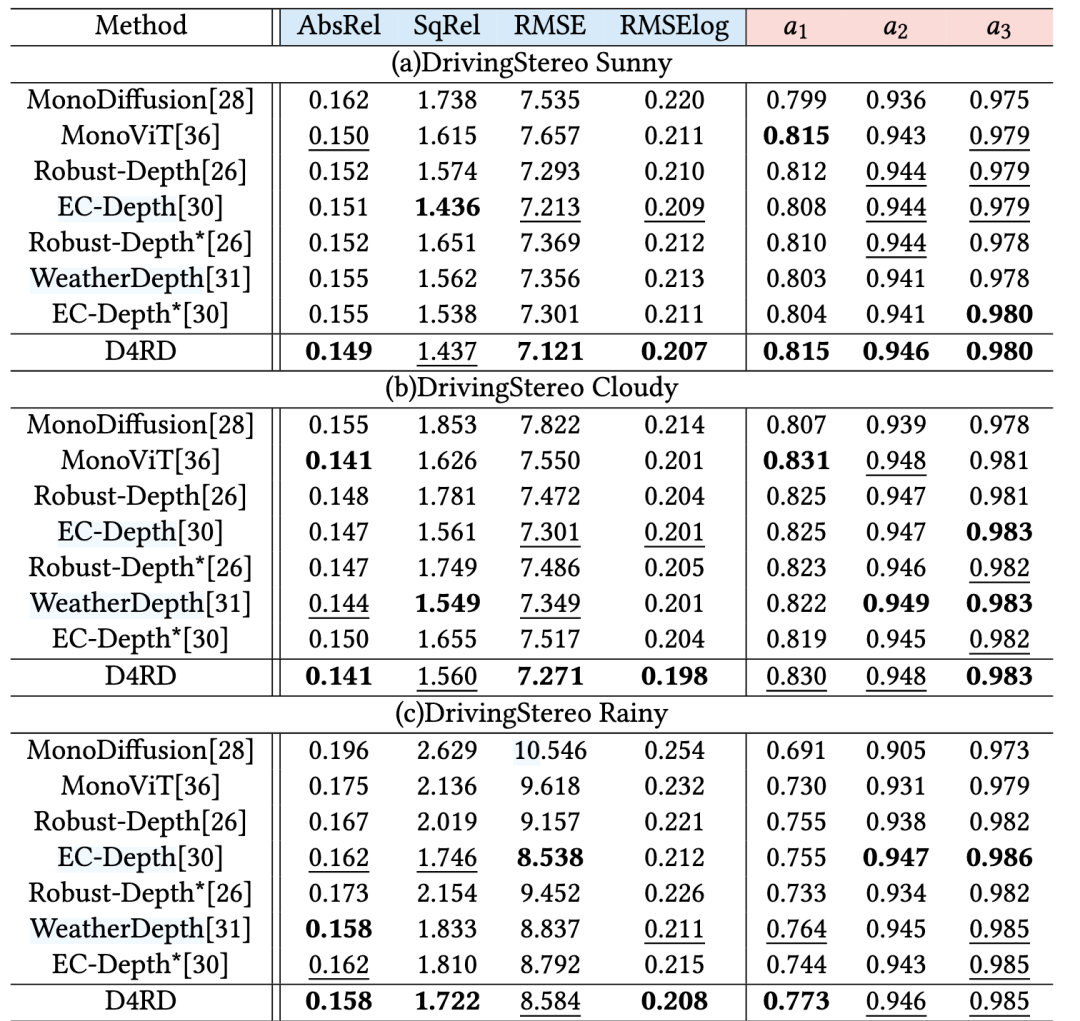
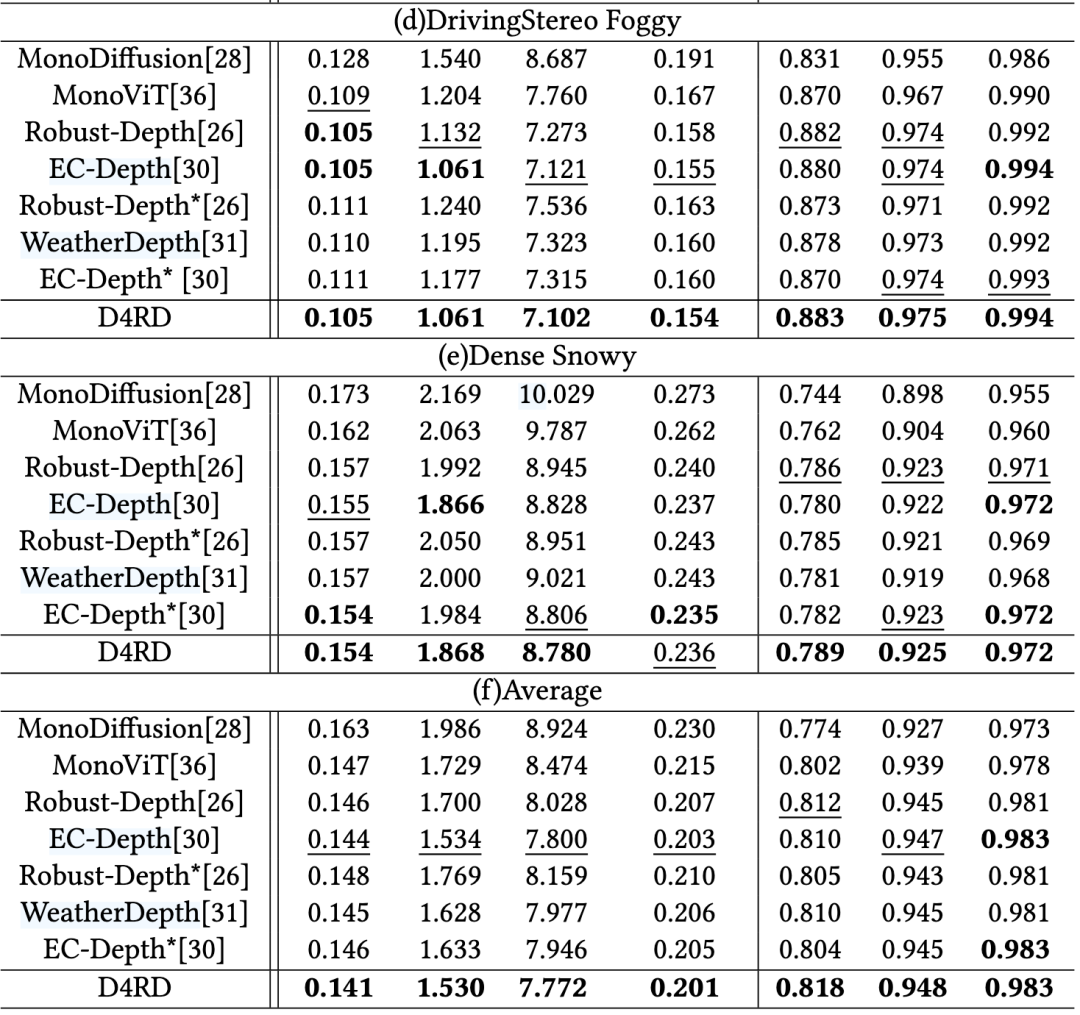
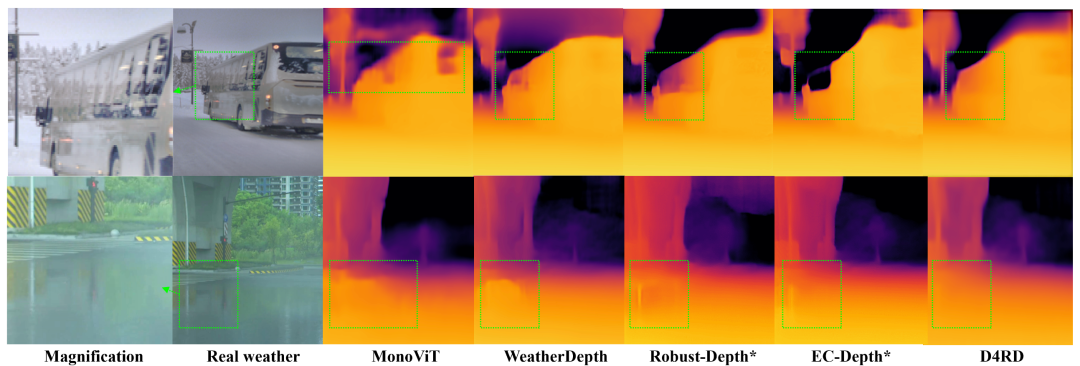
性能: D4RD 在各种合成损坏和真实世界恶劣天气条件下的定量(如 AbsRel, SqRel, RMSE 等指标)和定性评估中,均显著优于现有的 SOTA 方法。
拓展方向
计算机视觉发展到现在,越来越卷,涌入的人越来越多,很多经典领域的主赛道近乎于做无可做。Diffusion,作为从2023年火爆至今顶会依然活跃的方案,似乎前景无量但又几乎做无可做。
现有的视觉问题往往热衷于在晴朗的、清晰的数据集上钻研、改进、刷点。而在现实世界中,诸如黑夜、雨雪雾等外界因素和图像失焦、压缩等内部因素导致的图像退化,会极大的影响各任务的性能。时至今日,在许多视觉子领域,这个方向远没有到红海。而利用Diffusion内在鲁棒性赋能,更是几乎没有人关注到了这一点(本文paper关注较低)
本文方案采用了一种扩散噪声对比方案,在许多部分对深度估计任务本身做了契合性设计。但尝试迁移到其他任务上会非常有前景!(语义分割/目标检测/法线估计/光流估计等)
因此,非常欢迎其他CV子领域的学者尝试将本文的方案进行修改!
何恺明在MIT授课的课件PPT下载
在CVer公众号后台回复:何恺明,即可下载本课程的所有566页课件PPT!赶紧学起来!
CVPR 2025 论文和代码下载
在CVer公众号后台回复:CVPR2025,即可下载CVPR 2025论文和代码开源的论文合集ECCV 2024 论文和代码下载
在CVer公众号后台回复:ECCV2024,即可下载ECCV 2024论文和代码开源的论文合集扩散模型交流群成立
扫描下方二维码,或者添加微信号:CVer2233,即可添加CVer小助手微信,便可申请加入CVer-垂直方向和论文投稿微信交流群。另外其他垂直方向已涵盖:目标检测、图像分割、目标跟踪、人脸检测&识别、OCR、姿态估计、超分辨率、SLAM、医疗影像、Re-ID、GAN、NAS、深度估计、自动驾驶、强化学习、车道线检测、模型剪枝&压缩、去噪、去雾、去雨、风格迁移、遥感图像、行为识别、视频理解、图像融合、图像检索、论文投稿&交流、PyTorch、TensorFlow和Transformer、NeRF、3DGS、Mamba等。 一定要备注:研究方向+地点+学校/公司+昵称(如Mamba、多模态学习或者论文投稿+上海+上交+卡卡),根据格式备注,可更快被通过且邀请进群
▲扫码或加微信号: CVer2233,进交流群
CVer计算机视觉(知识星球)来了!想要了解最新最快最好的CV/DL/AI论文速递、优质实战项目、AI行业前沿、从入门到精通学习教程等资料,欢迎扫描下方二维码,加入CVer计算机视觉(知识星球),已汇集上万人!
▲扫码加入星球学习
▲扫码或加微信号: CVer2233,进交流群
CVer计算机视觉(知识星球)来了!想要了解最新最快最好的CV/DL/AI论文速递、优质实战项目、AI行业前沿、从入门到精通学习教程等资料,欢迎扫描下方二维码,加入CVer计算机视觉(知识星球),已汇集上万人!
▲扫码加入星球学习▲点击上方卡片,关注CVer公众号 整理不易,请点赞和在看


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









