






点击下方卡片,关注“CVer”公众号
AI/CV重磅干货,第一时间送达
添加微信号:CVer2233,小助手会拉你进群!
扫描下方二维码,加入CVer学术星球!可以获得最新顶会/顶刊上的论文idea和CV从入门到精通资料,及最前沿应用!发论文/搞科研/涨薪,强烈推荐!



论文:https://arxiv.org/abs/2504.11455
代码:https://github.com/wdrink/SimpleAR
序言
基于Transformer的自回归架构在语言建模上取得了显著成功,但在图像生成领域,扩散模型凭借强大的生成质量和可控性占据了主导地位。虽然也有一些早期工作如Parti[1]、LlamaGen[2],尝试用更强的视觉tokenizer和Transformer架构来提升自回归生成的效果,但他们论文中的结果表明,只有更多的参数量才能让自回归模型勉强和扩散模型“掰掰手腕”。
这也让越来越多的研究者质疑自回归视觉生成是否是一条可行、值得探索的路径。通常来说,大家的担忧集中在三个方面:
1)离散的token必然带来更多的信息损失:当下改进视觉tokenizer也是一个备受关注的方向,最新的方法无论是离散或连续都可以取得非常好的重建效果(至少不会制约生成模型),因此相信这一点不会是制约两条路线的核心原因;
2)视觉token序列往往较长、因此很难建模token间的关系:对于一个512分辨率的图像来说,16倍压缩比的tokenizer意味着视觉token序列的长度是1024。对于采用因果掩码(causal mask)的自回归模型来说,建模这么长的序列无疑是很有挑战性的;
3)下一个token预测的效率太低:相比于扩散模型或MaskGIT[3]那样一步出整图或多个token,自回归模型串行预测token的方式在生成速度方面存在明显劣势。
近些时间,也有一些工作如VAR[4]和MAR[5]尝试重新定义视觉里自回归的形式,比如下一个尺度预测、或用连续token做自回归。这些方法在ImageNet这样的学术数据集上取得了不错的效果,但是也潜在地破坏了视觉模态和语言模型的对齐性。
带着好奇的心态,来自复旦视觉与学习实验室和字节Seed的研究者们希望“验一验”自回归视觉生成模型的能力,他们保持“Next-token prediction”这样简洁优美的形式,而通过优化训练和推理过程来探究自回归视觉生成是否可以像扩散模型一样取得不错的文生图效果。
方法
先说结论!这篇工作有三点惊艳的发现:
1)在0.5B的参数规模下,纯自回归模型可以生成1024分辨率的高质量图像,且在常用文生图基准上取得了非常有竞争力的结果,例如在GenEval上取得了0.59, 是1B以内模型的SOTA;
2)通过“预训练-有监督微调-强化学习”这样的三阶段训练,模型可以生成出具有很高美学性的图像,且有监督微调(SFT)和基于GRPO[6]的强化学习可以持续提升模型的指令跟随能力以及生成效果;
3)当用vLLM[7]进行部署时,0.5B的模型可以在14秒以内生成1024分辨率的图像。
性能比较
本文提出的SimpleAR在GenEval和DPG上都取得了不错的结果,其中0.5B模型显著超越了SDv2.1和LlamaGen。值得一提的是,扩散模型和Infinity这类方法都依赖于外挂的文本编码器,如Infinity [7]使用了3B的FlanT5-XL[8],而本文提出的自回归模型则将文本(prompt)编码和视觉生成集成在了一个decoder-only的Transformer里,不仅可以更好地学习跨模态对齐,也能更加高效地利用参数。
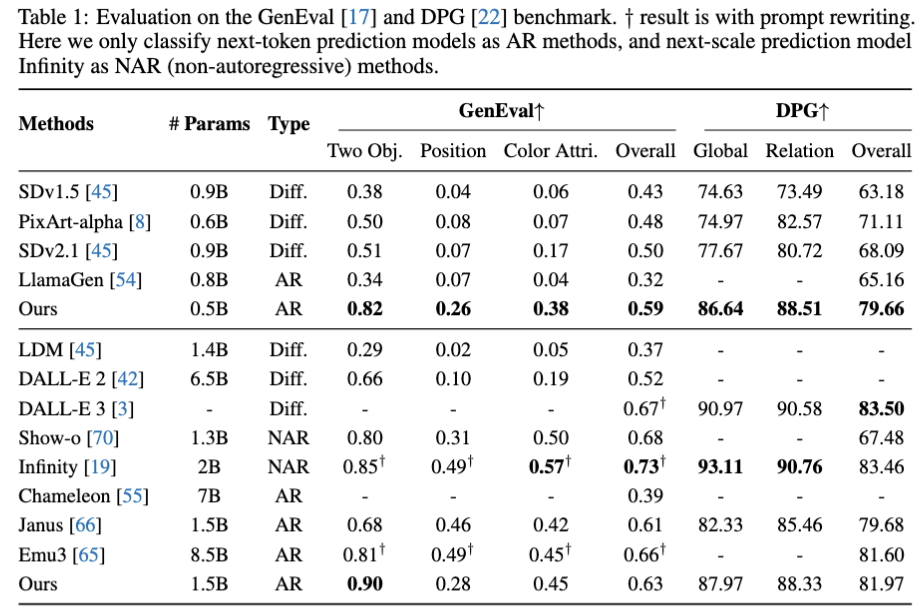
1.5B模型的性能距离Infinity[7]还有差距,但本文相信这主要是由数据规模导致的,当用更多的高质量数据训练时,模型的性能还可以被进一步提升。此外,本文选择了Cosmos[9]作为视觉tokenizer,其在重建低分辨率图像和人脸等细节上十分有限,因此生成能力还有充分被改进的空间。
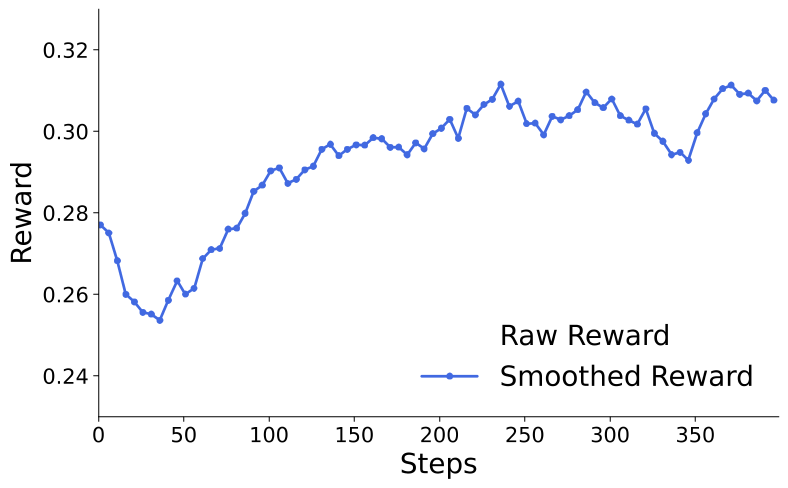
本文还首次在文生图上成功应用了GRPO进行后训练,结果表明:利用CLIP这样非常简单的reward函数,也依然可以观察到非常有潜力的reward曲线、并在GenEval上了取得了显著的性能提升:
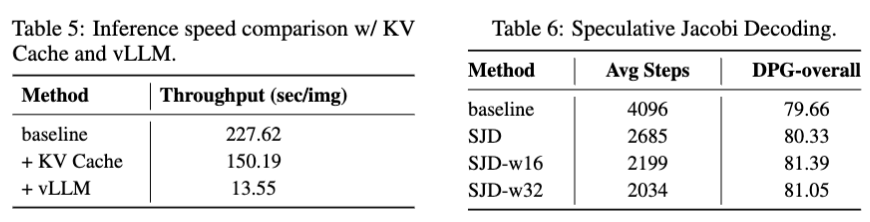
最后是关于效率问题。本文首先尝试了用vLLM[10]将模型部署到A100上,结果表明其可以显著地提升模型的推理速度:仅需13.55秒就能生成1024分辨率的高质量图像,这显著缩小了和扩散模型的差距,并由于可以使用KV Cache技术而相比于MaskGIT更有优势。本文也实现了推断采样,其可以有效降低2倍的自回归推理步数。
可视化结果

总结和几点思考
顾名思义,SimpleAR只是团队关于自回归视觉生成的一次简单尝试,但从中可以看到自回归模型相较于扩散模型的几点优势:
1)将文本和视觉token摆上平等的地位,更好地支持不同模态之间的建模学习,从而有利于构建原生的多模态理解和生成模型;
2)与现有支持语言模型后训练和推理加速的技术兼容性高:通过强化学习可以显著提升模型的文本跟随能力和生成效果、通过vLLM可以有效降低模型的推理时间;
本文训练及测试代码以及模型权重均已开源,希望鼓励更多的人参与到自回归视觉生成的探索中。
引用
[1] Scaling Autoregressive Models for Content-Rich Text-to-Image Generation.
[2] Autoregressive Model Beats Diffusion: Llama for Scalable Image Generation.
[3] MaskGIT: Masked Generative Image Transformer.
[4] Visual Autoregressive Modeling: Scalable Image Generation via Next-Scale Prediction.
[5] Autoregressive Image Generation without Vector Quantization.
[6] DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models.
[7] Infinity: Scaling Bitwise AutoRegressive Modeling for High-Resolution Image Synthesis.
[8] Scaling Instruction-Finetuned Language Models.
[9] https://github.com/NVIDIA/Cosmos-Tokenizer
[10]https://github.com/vllm-project/vllm
何恺明在MIT授课的课件PPT下载
在CVer公众号后台回复:何恺明,即可下载本课程的所有566页课件PPT!赶紧学起来!
CVPR 2025 论文和代码下载
在CVer公众号后台回复:CVPR2025,即可下载CVPR 2025论文和代码开源的论文合集ECCV 2024 论文和代码下载
在CVer公众号后台回复:ECCV2024,即可下载ECCV 2024论文和代码开源的论文合集CV垂直方向和论文投稿交流群成立
扫描下方二维码,或者添加微信号:CVer2233,即可添加CVer小助手微信,便可申请加入CVer-垂直方向和论文投稿微信交流群。另外其他垂直方向已涵盖:目标检测、图像分割、目标跟踪、人脸检测&识别、OCR、姿态估计、超分辨率、SLAM、医疗影像、Re-ID、GAN、NAS、深度估计、自动驾驶、强化学习、车道线检测、模型剪枝&压缩、去噪、去雾、去雨、风格迁移、遥感图像、行为识别、视频理解、图像融合、图像检索、论文投稿&交流、PyTorch、TensorFlow和Transformer、NeRF、3DGS、Mamba等。 一定要备注:研究方向+地点+学校/公司+昵称(如Mamba、多模态学习或者论文投稿+上海+上交+卡卡),根据格式备注,可更快被通过且邀请进群
▲扫码或加微信号: CVer2233,进交流群
CVer计算机视觉(知识星球)来了!想要了解最新最快最好的CV/DL/AI论文速递、优质实战项目、AI行业前沿、从入门到精通学习教程等资料,欢迎扫描下方二维码,加入CVer计算机视觉(知识星球),已汇集上万人!
▲扫码加入星球学习
▲扫码或加微信号: CVer2233,进交流群
CVer计算机视觉(知识星球)来了!想要了解最新最快最好的CV/DL/AI论文速递、优质实战项目、AI行业前沿、从入门到精通学习教程等资料,欢迎扫描下方二维码,加入CVer计算机视觉(知识星球),已汇集上万人!
▲扫码加入星球学习▲点击上方卡片,关注CVer公众号 整理不易,请点赞和在看


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









